[논문리뷰] Deformable DETR: Deformable Transformers for End-to-End Object Detection
ICLR 2021. [Paper] [Github]
Xizhou Zhu, Weijie Su, Lewei Lu, Bin Li, Xiaogang Wang, Jifeng Dai
SenseTime Research | University of Science and Technology of China | The Chinese University of Hong Kong
8 Oct 2020
Introduction
최신 object detector는 앵커 생성, 규칙 기반 학습 대상 할당, Non-Maximum Suppression (NMS) 후처리와 같은 많은 수작업 구성 요소를 사용한다. DETR은 이러한 수작업 구성 요소의 필요성을 없애기 위해 최초의 완전 end-to-end object detector를 구축하여 매우 경쟁력 있는 성능을 달성했다. DETR은 CNN과 Transformer 인코더-디코더를 결합하여 간단한 아키텍처를 활용한다. 적절하게 디자인된 학습 신호에 따라 수작업 규칙을 대체하기 위해 transformer의 다재다능하고 강력한 관계 모델링 능력을 활용한다.
흥미로운 디자인과 우수한 성능에도 불구하고 DETR에는 다음과 같은 고유한 문제가 있다.
- 기존 object detector보다 수렴하는 데 훨씬 더 긴 학습 기간이 필요하다. 예를 들어, COCO 벤치마크에서 DETR은 수렴하는 데 500 epochs가 필요하며 이는 Faster R-CNN보다 약 10~20배 느리다.
- DETR은 작은 물체를 감지할 때 상대적으로 낮은 성능을 제공한다. 최신 object detector는 일반적으로 고해상도 feature map에서 작은 개체가 감지되는 멀티스케일 feature를 활용한다. 한편, 고해상도 feature map은 DETR에 허용할 수 없는 복잡도를 초래한다.
위에서 언급한 문제는 주로 이미지 feature map을 처리하는 Transformer 구성 요소의 부족에 기인할 수 있다. 초기화 시 attention 모듈은 feature map의 모든 픽셀에 거의 균일한 attention 가중치를 적용한다. 의미 있는 몇몇 위치에 집중하기 위해 attention 가중치를 학습하려면 긴 학습이 필요하다. 반면에 Transformer 인코더의 attention 가중치 계산은 픽셀 수의 제곱에 비례한다. 따라서 고해상도 feature map을 처리하는 것은 계산 및 메모리 복잡도가 매우 높다.
이미지 도메인에서 deformable convolution은 몇몇 공간적 위치에만 주의를 기울이는 강력하고 효율적인 메커니즘이다. 자연스럽게 위에서 언급한 문제를 피할 수 있다. 반면 DETR 성공의 열쇠인 관계 모델링 메커니즘이 부족하다.
본 논문에서는 DETR의 느린 수렴과 높은 복잡도 문제를 완화하는 Deformable DETR을 제안한다. Deformable convolution의 sparse spatial sampling과 Transformer의 관계 모델링 능력을 결합한다. 모든 feature map 픽셀에서 눈에 띄는 핵심 요소에 대한 사전 필터로 작은 샘플링 위치 집합에만 attention을 연산하는 deformable attention module을 제안한다. 이 모듈은 FPN의 도움 없이 멀티스케일 feature를 집계하도록 자연스럽게 확장될 수 있다. Deformable DETR에서는 아래 그림과 같이 Transformer attention 모듈로 처리한 feature map을 대체하기 위해 멀티스케일 deformable attention module을 활용한다.
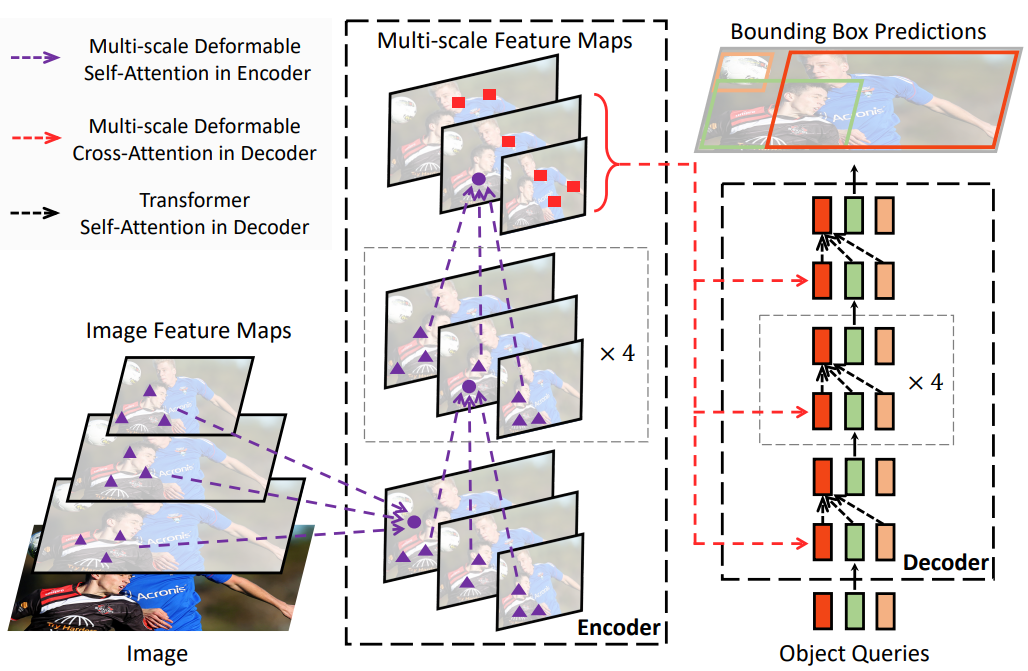
Deformable DETR은 빠른 수렴, 계산 및 메모리 효율성 덕분에 end-to-end object detector의 변형을 활용할 수 있는 가능성을 열어준다. 저자들은 detection 성능을 향상시키기 위해 간단하고 효과적인 boundary box 반복 개선 메커니즘을 탐색하였다. 또한 저자들은 2-stage Deformable DETR을 시도하였다. 2-stage Deformable DETR에서 region proposal은 Deformable DETR의 변형에 의해 생성되며 반복적인 boundary box 개선을 위해 디코더에 추가로 공급된다.
Transformers and DETR
Multi-Head Attention in Transformers
Transformer는 attention 메커니즘을 기반으로 하는 네트워크 아키텍처이다. Query element 세트 (ex. 출력 문장의 타겟 단어)와 key element 세트 (ex. 입력 문장의 소스 단어)가 주어지면 multi-head attention module은 query-key 쌍의 호환성을 측정하는 attention 가중치에 따라 key 콘텐츠를 적응적으로 집계한다. 모델이 다양한 representation subspace와 다양한 위치의 콘텐츠에 초점을 맞출 수 있도록 다양한 attention head의 출력이 학습 가능한 가중치로 선형으로 집계된다.
$q \in \Omega_q$가 representation feature $z_q \in \mathbb{R}^C$로 query element를 인덱싱하고 $k \in \Omega_k$가 representation feature $x_k \in \mathbb{R}^C$로 key element를 인덱싱한다고 하자. 여기서 $C$는 feature 차원이고 $\Omega_q$와 $\Omega_k$는 각각 query element 세트와 key element 세트이다. 그러면 multi-head attention feature는 다음과 같이 계산된다.
\[\begin{equation} \textrm{MultiHeadAttn} (z_q, x) = \sum_{m=1}^M W_m [\sum_{k \in \Omega_k} A_{mqk \cdot W'_m x_k}] \end{equation}\]여기서 $m$은 attention head를 인덱싱하고 \(W'_m \in \mathbb{R}^{C_v \times C}\)와 $W_m \in \mathbb{R}^{C \times C_v}$는 학습 가능한 가중치이다. 서로 다른 공간적 위치를 명확히 하기 위해 representation feature $z_q$와 $x_k$는 일반적으로 element 콘텐츠와 위치 임베딩의 concatenation 또는 합계이다.
Transformer에는 두 가지 알려진 문제가 있다. 하나는 Transformer가 수렴되기 전에 긴 학습이 필요하다는 것이다. Query element와 key element의 수가 각각 $N_q$와 $N_k$라고 하자. 일반적으로 적절한 파라미터 초기화를 통해 $U_m z_q$와 $V_m x_k$는 평균이 0이고 분산이 1인 분포를 따르므로 $N_k$가 클 때 attention 가중치 $A_{mqk} \approx 1 / N_k$가 된다. 이는 입력 feature에 대해 모호한 기울기를 발생시킨다. 따라서 attention 가중치가 특정 key에 집중할 수 있도록 긴 학습 일정이 필요하다. 핵심 element가 일반적으로 이미지 픽셀인 이미지 도메인에서 $N_k$는 매우 클 수 있으며 수렴이 오래 걸린다.
한편 multi-head attention을 위한 계산 및 메모리 복잡도는 수많은 query element와 key element로 인해 매우 높을 수 있다. $\textrm{MultiHeadAttn}$의 계산 복잡도는 $O(N_q C^2 + N_k C^2 + N_q N_k C)$이다. Query element와 key element가 모두 픽셀인 이미지 도메인에서 $N_q = N_k \gg C$이므로 복잡도는 세 번째 항인 $O(N_q N_k C)$에 의해 지배된다. 따라서 multi-head attention 모듈은 feature map 크기에 따라 제곱으로 복잡도가 증가하는 문제를 겪는다.
DETR
DETR은 Transformer 인코더-디코더 아키텍처를 기반으로 하며 이분 매칭을 통해 각 ground-truth boundary box에 대한 고유한 예측을 강제하는 집합 기반 Hungarian loss와 결합된다.
CNN backbone (ex. ResNet)에서 추출한 입력 feature map $x \in \mathbb{R}^{C \times H \times W}$가 주어지면 DETR은 표준 Transformer 인코더-디코더 아키텍처를 활용하여 입력 feature map을 object query들의 집합의 feature로 변환한다. 3-layer 피드포워드 신경망(FFN)과 linear projection이 detection head로 object query feature (디코더에서 생성됨) 위에 추가된다. FFN은 boundary box 좌표 $b \in [0, 1]^4$를 예측하는 회귀 분기 역할을 한다. 여기서 \(b = \{b_x, b_y, b_w, b_h\}\)는 정규화된 박스 중심 좌표, 박스 높이 및 너비 (이미지 크기 기준)를 인코딩한다. Linear projection은 분류 결과를 생성하는 분류 분기 역할을 한다.
DETR의 Transformer 인코더의 경우 query element와 key element는 모두 feature map의 픽셀이다. 입력은 ResNet feature map이다. $H$와 $W$는 각각 feature map의 높이와 너비라고 하자. 그러면 self-attention의 계산 복잡도는 $O(H^2 W^2 C)$이며 공간 크기에 따라 2차적으로 증가한다.
DETR의 Transformer 디코더의 경우 입력에는 인코더의 feature map과 학습 가능한 위치 임베딩으로 표시되는 $N$개의 object query가 모두 포함된다. 디코더에는 두 가지 유형의 attention 모듈, 즉 cross-attention 모듈과 self-attention 모듈이 있다. Cross-attention 모듈에서 object query는 feature map에서 feature를 추출한다. Query element는 object query에 대한 것이고 key element는 인코더의 출력 feature map에 대한 것이다. 여기에서 $N_q = N, N_k = H \times W$이고 cross-attention 복잡도는 $O (H W C^2 + NHWC)$이다. 복잡도는 feature map의 공간 크기에 따라 선형적으로 증가한다. Self-attention 모듈에서 object query는 서로 상호 작용하여 관계를 캡처한다. Query element와 key element는 모두 object query이다. 여기서 $N_q = N_k = N$이고 self-attention 모듈의 복잡도는 $O(2NC^2 + N^2 C)$이다. Object query 수가 적당하면 복잡도가 허용된다.
DETR은 object detection을 위한 매력적인 디자인으로 수작업으로 디자인된 많은 구성 요소가 필요하지 않다. 그러나 자체적 문제도 있다. 이러한 문제는 주로 이미지 feature map을 핵심 요소로 처리할 때 Transformer attention이 부족하기 때문일 수 있다.
- DETR은 작은 물체를 감지하는 성능이 상대적으로 낮다. 최신 object detector는 고해상도 feature map을 사용하여 작은 물체를 더 잘 감지한다. 그러나 고해상도 feature map은 입력 feature map의 공간 크기와 2차 복잡도를 갖는 DETR의 Transformer 인코더의 self-attention 모듈에 허용할 수 없는 복잡도를 초래할 수 있다.
- 최신 object detector와 비교할 때 DETR은 수렴하는 데 더 많은 학습 기간이 필요하다. 이것은 주로 이미지 feature를 처리하는 attention 모듈이 학습하기 어렵기 때문이다. 초기화 시 cross-attention 모듈은 전체 feature map에서 거의 평균 수준이다. 반면 학습이 끝나면 attention map은 물체의 말단에만 초점을 맞추는 매우 드문 것으로 학습된다. DETR은 attention map에서 이러한 중요한 변화를 학습하기 위해 긴 학습이 필요하다.
Method
1. Deformable Transformers for End-to-End Object Detection
Deformable Attention Module
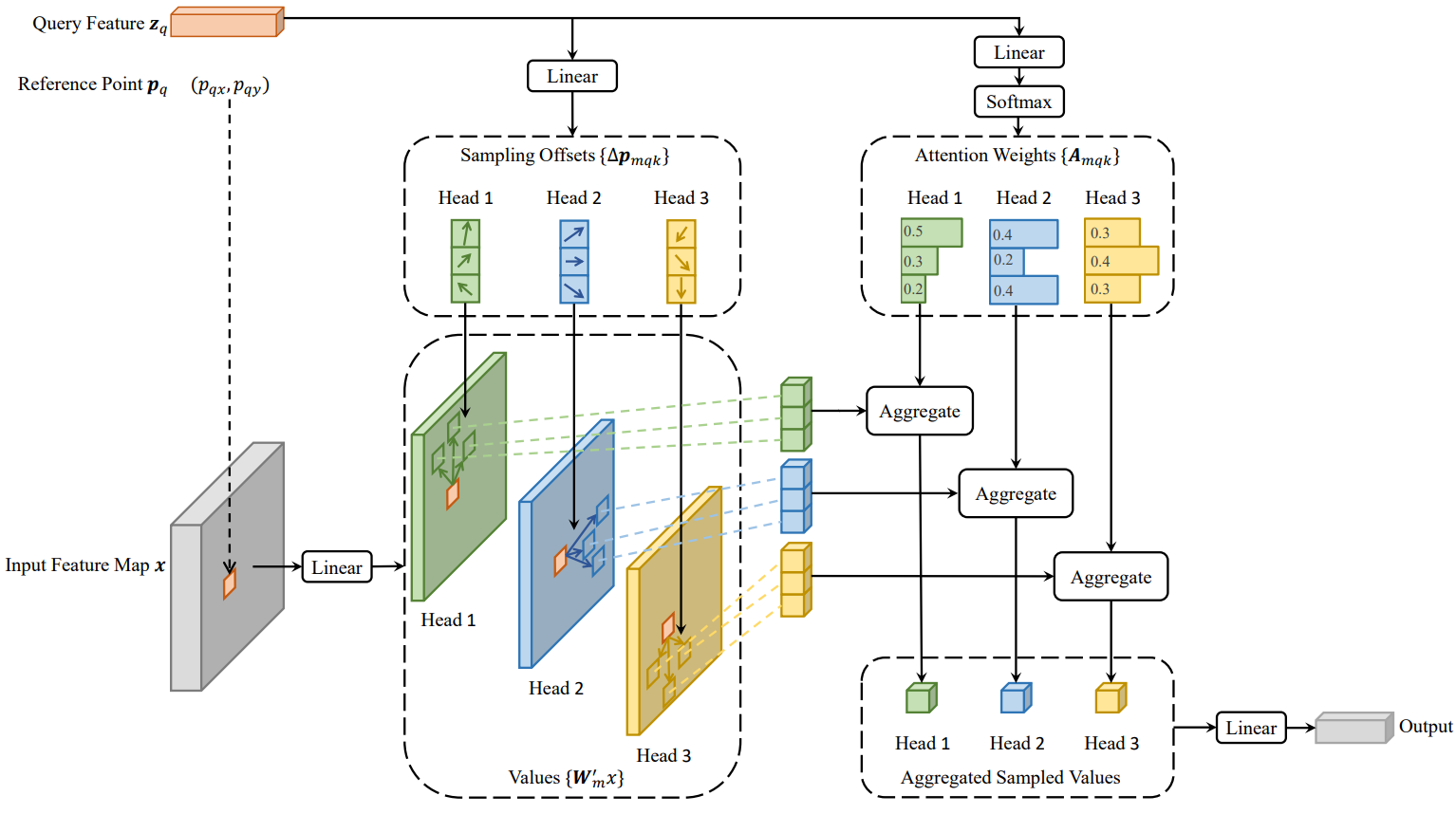
이미지 feature map에 Transformer attention을 적용하는 핵심 문제는 가능한 모든 공간 위치를 살펴본다는 점이다. 이를 해결하기 위해 본 논문은 deformable attention module을 제시한다. Deformable convolution에서 영감을 받은 deformable attention module은 위 그림과 같이 feature map의 공간 크기에 관계없이 기준점 주변의 작은 key 샘플링 지점 집합에만 주의를 기울인다. 각 query에 대해 수렴 및 feature space 해상도 문제를 완화할 수 있다.
입력 feature map $x \in \mathbb{R}^{C \times H \times W}$가 주어지면 $q$가 콘텐츠 feature $z_q$와 2D 기준점 $p_q$를 포함하는 query element를 인덱싱한다고 하자. Deformable attention feature는 다음과 같이 계산된다.
\[\begin{equation} \textrm{DeformAttn} (z_q, p_q, x) = \sum_{m=1}^M W_m [\sum_{k=1}^K A_{mqk} \cdot W'_m x (p_q + \Delta p_{mqk})] \end{equation}\]여기서 $m$은 attention head를 인덱싱하고 $k$는 샘플링된 key를 인덱싱하고며 $K$는 총 샘플링된 key의 수이다 ($K \ll HW$). $\Delta p_{mqk}$와 $A_{mqk}$는 각각 $m$번째 attention head에서 k번째 샘플링 포인트의 샘플링 오프셋과 attention 가중치를 나타낸다. Attention 가중치 $A_{mqk}$는
\[\begin{equation} \sum_{k=1}^K A_{mqk} = 1 \end{equation}\]로 정규화되며, $[0, 1]$ 범위에 있다. $p_q + \Delta p_{mqk}$는 분수이므로 bilinear interpolation이 적용된다. $\Delta p_{mqk}$와 $A_{mqk}$는 모두 query feature $z_q$에 대한 linear projection을 통해 얻는다. 구현에서 $z_q$는 $3MK$개의 채널의 linear projection 연산자에 공급된다. 여기서 처음 $2MK$개의 채널은 샘플링 오프셋 $\Delta p_{mqk}$를 인코딩하고 나머지 $MK$개의 채널은 softmax 연산자에 공급되어 attention 가중치 $A_{mqk}$를 얻는다.
Deformable attention module은 convolution feature map을 핵심 요소로 처리하도록 설계되었다. $N_q$를 query element의 수라고 하면 $MK$가 상대적으로 작을 때 deformable attention module의 복잡도는
\[\begin{equation} O(2N_q C^2 + \min( HW C^2 , N_q K C^2 )) \end{equation}\]이다. $N_q = HW$인 DETR 인코더에 적용하면 복잡도는 $O(HW C^2)$가 되어 공간 크기에 선형 복잡도가 된다. DETR 디코더에서 cross-attention 모듈로 적용하면 $N_q = N$ ($N$은 object query의수), 복잡도는 $O(NKC^2)$가 되어 공간 크기 $HW$와 무관하다.
Multi-scale Deformable Attention Module
대부분의 최신 object detection 프레임워크는 멀티스케일 feature map의 이점을 얻는다. Deformable attention module은 멀티스케일 feature map을 위해 자연스럽게 확장될 수 있다.
\(\{x^l\}_{l=1}^L\)을 입력 멀티스케일 feature map이라고 하자. 여기서 $x^l \in \mathbb{R}^{C \times H_l \times W_l}$이다. \(\hat{p}_q \in [0, 1]^2\)를 각 query element $q$에 대한 기준점의 정규화된 좌표라고 하면 멀티스케일 deformable attention module은 다음과 같이 적용된다.
\[\begin{equation} \textrm{MSDeformAttn} (z_q, \hat{p}_q, \{x^l\}_{l=1}^L) = \sum_{m=1}^M W_m [\sum_{l=1}^L \sum_{k=1}^K A_{mlqk} \cdot W'_m x^l (\phi_l (\hat{p}_q) + \Delta p_{mlqk})] \end{equation}\]여기서 $m$은 attention head를 인덱싱하고 $l$은 입력 feature 레벨을 인덱싱하며 $k$는 샘플링 포인트를 인덱싱한다. $\Delta p_{mlqk}$와 $A_{mlqk}$는 각각 $l$번째 feature 레벨고 $m$번째 attention head에서 $k$번째 샘플링 포인트의 샘플링 오프셋과 attention 가중치를 나타낸다. Attention 가중치 $A_{mlqk}$는
\[\begin{equation} \sum_{l=1}^L \sum_{k=1}^K A_{mlqk} = 1 \end{equation}\]로 정규화된다. 여기서 정규화 좌표 \(\hat{p}_q \in [0, 1]^2\)를 사용하며, 정규화 좌표 $(0, 0)$와 $(1, 1)$은 이미지의 왼쪽 상단과 오른쪽 하단을 각각 나타낸다. 함수 \(\phi_l (\hat{p}_q)\)는 정규화된 좌표 \(\hat{p}_q\)를 $l$번째 레벨의 입력 feature map으로 재조정한다. 멀티스케일 deformable attention은 단일 스케일 feature map의 $K$개 포인트 대신 멀티스케일 feature map의 $LK$개의 포인트를 샘플링한다는 점을 제외하면 단일 스케일 버전과 매우 유사하다.
Deformable attention module은 $L = 1$이고 $K = 1$이며 \(W'_m \in \mathbb{R}^{C_v \times C}\)가 항등 행렬로 고정되면 deformable convolution과 동일해진다. Deformable convolution은 각 attention head에 대해 하나의 샘플링 포인트에만 초점을 맞추는 단일 스케일 입력용으로 설계되었다. 그러나 멀티스케일 deformable attention은 멀티스케일 입력에서 여러 샘플링 지점을 살펴본다. 멀티스케일 deformable attention module은 변형 가능한 샘플링 위치에 의해 사전 필터링 메커니즘이 도입되는 Transformer attention의 효율적인 변형으로도 인식될 수 있다. 샘플링 포인트가 가능한 모든 위치를 통과할 때 deformable attention module은 Transformer attention과 동일하다.
Deformable Transformer Encoder
DETR에서 feature map을 처리하는 Transformer attention 모듈을 멀티스케일 deformable attention module로 대체한다. 인코더의 입력과 출력은 모두 동일한 해상도를 가진 멀티스케일 feature map이다. 인코더에서 ResNet (1$\times$1 convolution으로 변환됨)의 $C_3$ ~ $C_5$ stage의 출력 feature map에서 멀티스케일 feature map \(\{x^l\}_{l=1}^{L-1}\) $(L = 4)$을 추출한다. 여기서 $C_l$은 입력 이미지보다 $2^l$ 낮은 해상도를 가진다. 가장 낮은 해상도의 feature map $x^L$은 최종 $C_5$ stage에서 3$\times$3 stride 2 convolution을 통해 얻으며, $C_6$으로 표시된다. 모든 멀티스케일 feature map은 $C = 256$ 채널이다. FPN의 하향식 구조는 멀티스케일 deformable attention 자체가 멀티스케일 feature map 간에 정보를 교환할 수 있기 때문에 사용되지 않는다.
인코더의 멀티스케일 deformable attention module을 적용하면 출력은 입력과 동일한 해상도를 가진 멀티스케일 feature map이다. Key element와 query element는 모두 멀티스케일 feature map의 픽셀이다. 각 query 픽셀에 대해 기준점는 그 자체이다. 각 query 픽셀이 어떤 feature 레벨에 있는지 식별하기 위해 위치 임베딩 외에도 feature 표현에 스케일 레벨 임베딩 $e_l$을 추가한다. 고정 인코딩을 사용한 위치 임베딩과 달리 스케일 레벨 임베딩 \(\{e_l\}_{l=1}^L\)은 랜덤하게 초기화되고 네트워크와 공동으로 학습된다.
Deformable Transformer Decoder
디코더에는 cross-attention 모듈과 self-attention 모듈이 있다. Attention 모듈의 두 가지 유형에 대한 query element는 object query이다. Cross-attention 모듈에서 object query는 feature map에서 feature를 추출한다. 여기서 핵심 요소는 인코더의 출력 feature map이다. Self-attention 모듈에서 object query는 서로 상호 작용하며 여기서 핵심 요소는 object query이다. Deformable attention module은 convolution feature map을 핵심 요소로 처리하도록 설계되었으므로 각 cross-attention 모듈만 멀티스케일 deformable attention module로 교체하고 self-attention 모듈은 변경하지 않는다. 각 object query에 대해 기준점 \(\hat{p}_q\)의 2D 정규화 좌표는 시그모이드 함수가 뒤따르는 학습 가능한 linear projection을 통해 object query 임베딩에서 예측된다.
멀티스케일 deformable attention module이 기준점 주변의 이미지 feature를 추출하기 때문에 detection head가 boundary box를 기준점에 대한 상대적인 오프셋으로 예측하여 최적화 난이도를 더 줄이도록 한다. 기준점은 박스 중심의 초기 추측으로 사용된다. Detection head는 기준점에 대한 상대적인 오프셋을 예측한다. 이러한 방식으로 학습된 디코더 attention은 예측된 boundary box와 강한 상관관계를 갖게 되며, 이는 학습 수렴도 가속화한다. Transformer attention 모듈을 DETR의 deformable attention module로 교체함으로써 Deformable DETR이라는 효율적이고 수렴이 빠른 object detection 시스템을 구축한다.
2. Additional Improvements and Variants for Deformable DETR
Deformable DETR은 빠른 수렴, 계산 및 메모리 효율성 덕분에 end-to-end object detector의 다양한 변형을 활용할 수 있는 가능성을 열어준다.
Iterative Bounding Box Refinement
이것은 optical flow 추정에서 개발된 iterative refinement에서 영감을 받았다. Detection 성능을 향상시키기 위해 간단하고 효과적인 boundary box 반복 개선 메커니즘을 설정한다. 여기에서 각 디코더 레이어는 이전 레이어의 예측을 기반으로 boundary box를 세분화한다.
Two-Stage Deformable DETR
오리지널 DETR에서 디코더의 object query는 현재 이미지와 관련이 없다. 저자들은 2-stage object detector에서 영감을 받아 첫 번째 stage로 region proposal을 생성하기 위한 Deformable DETR 변형을 탐색하였다. 생성된 region proposal은 추가 개선을 위한 object query로 디코더에 공급되어 2-stage Deformable DETR을 형성한다.
첫 번째 stage에서는 높은 recall의 proposal을 위해 멀티스케일 feature map의 각 픽셀이 object query 역할을 한다. 그러나 object query를 픽셀로 직접 설정하면 디코더의 self-attention 모듈에 허용할 수 없는 계산 및 메모리 비용이 발생하며 복잡도는 query 수에 따라 2차적으로 증가한다. 이 문제를 피하기 위해 디코더를 제거하고 로컬한 proposal 생성을 위해 인코더 전용 Deformable DETR을 형성한다. 여기에서 각 픽셀은 boundary box를 직접 예측하는 object query로 할당된다. 가장 점수가 높은 boundary box가 region proposal로 선택된다. Region proposal을 두 번째 stage에 공급하기 전에는 NMS가 적용되지 않는다.
Experiment
- 데이터셋: COCO 2017
- 구현 디테일
- Backbone: ImageNet에서 사전 학습된 ResNet-50
- 멀티스케일 feature map은 FPN 없이 추출됨
- Deformable attention에서 $M = 8$, $K = 4$로 설정
- Deformable Transformer 인코더의 파라미터는 여러 feature 레벨에서 공유됨
- 대부분의 hyperparameter 세팅은 DETR을 따름
- 가중치 2의 Focal Loss를 boundary box classification에 사용, object query의 수도 100에서 300으로 변경
- Epoch: 50
- Learning rate: 초기에 $2 \times 10^{-4}$, 40 epochs마다 0.1로 decay
- $\beta_1 = 0.9$, $\beta_2 = 0.999$, weight decay = $10^{-4}$
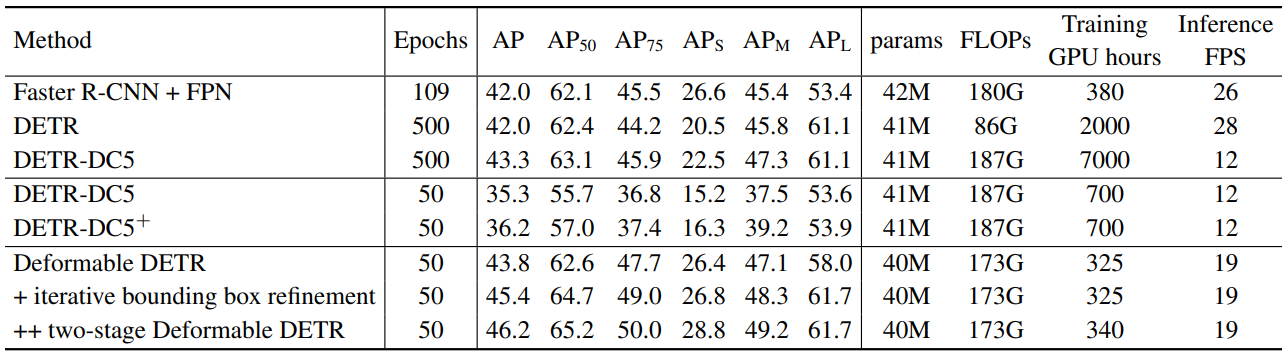
1. Comparison with DETR
다음은 COCO 2017 val set에서의 성능을 DETR과 비교한 표이다. DETR-DC5+는 공정한 비교를 위해 DETR-DC5에 Focal Loss를 추가하고 object query의 수를 300으로 늘린 버전이다.
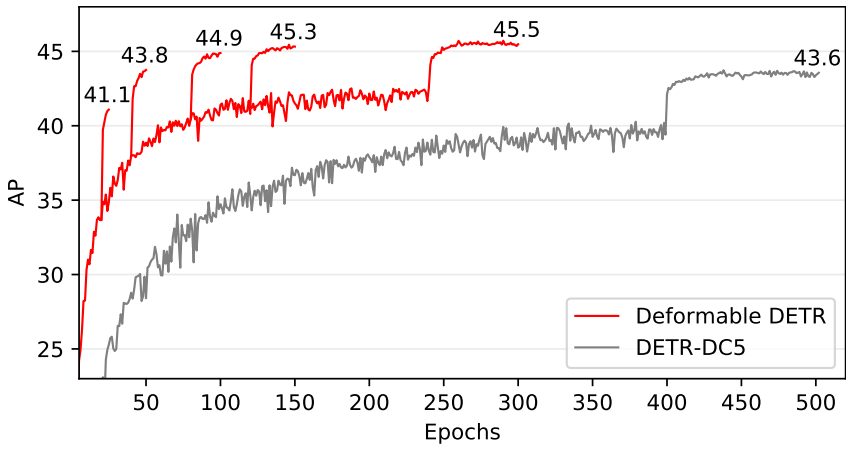
다음은 Deformable DETR과 DETR-DC5의 수렴 곡선이다.
2. Ablation Study on Deformable Attention
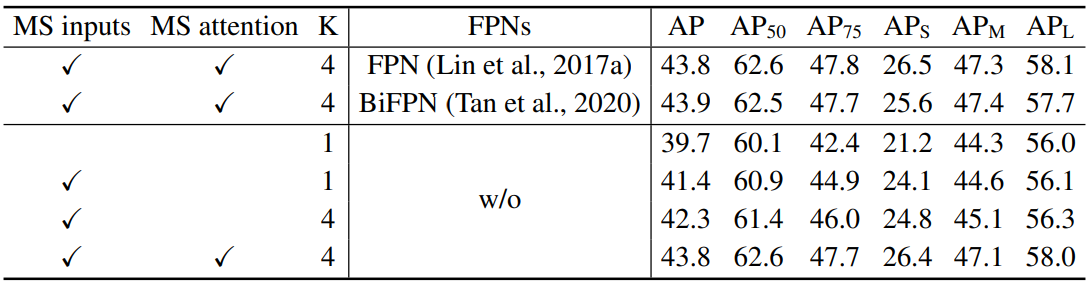
다음은 COCO 2017 val set에서 수행한 deformable attention의 ablation study 결과이다. MS는 멀티스케일을 뜻한다.
3. Comparison with State-of-the-art Methods
다음은 COCO 2017 test-dev set에서 Deformable DETR을 다른 SOTA 방법들과 비교한 표이다.
