[논문리뷰] DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Introduction
최근, post-training이 LLM의 학습 파이프라인의 중요한 구성 요소로 부상했다. 추론 능력의 맥락에서 OpenAI의 o1 시리즈 모델은 Chain-of-Thought (CoT) 추론 프로세스의 길이를 늘려 inference-time scaling을 도입한 최초의 모델이었다. 이 접근 방식은 수학, 코딩, 과학적 추론과 같은 다양한 추론 task에서 상당한 개선을 이루었지만, 효과적인 test-time scaling은 여전히 미해결 문제로 남아 있다. 여러 연구들에서 다양한 접근 방식을 탐구했지만, 어느 것도 OpenAI의 o1 시리즈 모델과 비교할 수 있는 추론 성능을 달성하지 못했다.
본 논문에서는 순수한 강화 학습(RL)을 사용하여 언어 모델 추론 능력을 개선하기 위한 첫 걸음을 내딛었다. 본 논문의 목표는 순수한 RL 프로세스를 통한 self-evolution에 초점을 맞춰 LLM이 어떠한 supervised 데이터 없이 추론 능력을 개발할 수 있는 잠재력을 탐구하는 것이다. 구체적으로, 저자들은 DeepSeek-V3-Base를 base model로 사용하고 GRPO를 RL 프레임워크로 사용하여 추론에서 모델 성능을 개선하였다. 학습하는 동안 DeepSeek-R1-Zero는 자연스럽게 수많은 강력하고 흥미로운 추론 행동을 보였다.
수천 개의 RL 단계 후, DeepSeek-R1-Zero는 추론 벤치마크에서 뛰어난 성능을 보여주었다. 예를 들어, AIME 2024의 pass@1 score는 15.6%에서 71.0%로 증가하고 다수결 투표를 통해 점수는 86.7%로 더욱 향상되어 OpenAI-o1-0912의 성능과 비슷한 성능을 보였다.
그러나 DeepSeek-R1-Zero는 가독성이 낮고 언어 혼합이 심한 문제에 부딪힌다. 이러한 문제를 해결하고 추론 성능을 더욱 향상시키기 위해 소량의 cold start 데이터와 다단계 학습 파이프라인을 통합한 DeepSeek-R1을 도입하였다.
구체적으로, 먼저 수천 개의 cold start 데이터를 수집하여 DeepSeek-V3-Base 모델을 fine-tuning한다. 그런 다음 DeepSeek-R1-Zero와 같은 추론 지향 RL을 수행한다. RL 프로세스에서 수렴에 가까워지면 RL 체크포인트에서 기각 샘플링(rejection sampling)을 통해 새로운 supervised fine-tuning (SFT) 데이터를 만들고 DeepSeek-V3의 supervised 데이터와 결합한 다음 DeepSeek-V3-Base 모델을 다시 학습시킨다. 새 데이터로 fine-tuning한 후 체크포인트는 모든 시나리오의 프롬프트를 고려하여 추가 RL 프로세스를 거친다. 이러한 단계들을 거쳐, OpenAI-o1-1217과 동등한 성능을 달성하는 DeepSeek-R1이라는 체크포인트를 얻었다.
저자들은 DeepSeek-R1에서 더 작은 모델로의 distillation을 더 탐구하였다. Qwen2.5-32B를 base model로 사용하여 DeepSeek-R1에서 직접 distillation하는 것이 RL을 적용하는 것보다 성능이 우수하였다. 이는 더 큰 base model에서 발견한 추론 패턴이 추론 능력을 개선하는 데 필수적임을 보여준다. 저자들은 distillation된 Qwen과 Llama 시리즈를 오픈 소스로 공개하였으며, distillation된 14B 모델은 QwQ-32B-Preview보다 큰 차이로 성능이 우수하고, distillation된 32B와 70B 모델은 추론 벤치마크에서 새로운 기록을 세웠다.
DeepSeek-R1-Zero: Reinforcement Learning on the Base Model
강화 학습(RL)은 추론 task에서 상당한 효과를 보였지만, 기존 연구들은 수집하는 데 시간이 많이 걸리는 supervised 데이터에 크게 의존했다. 저자들은 순수한 강화 학습 프로세스를 통한 self-evolution에 초점을 맞춰 supervised 데이터 없이도 추론 능력을 개발할 수 있는 LLM의 잠재력을 살펴보았다.
1. Reinforcement Learning Algorithm
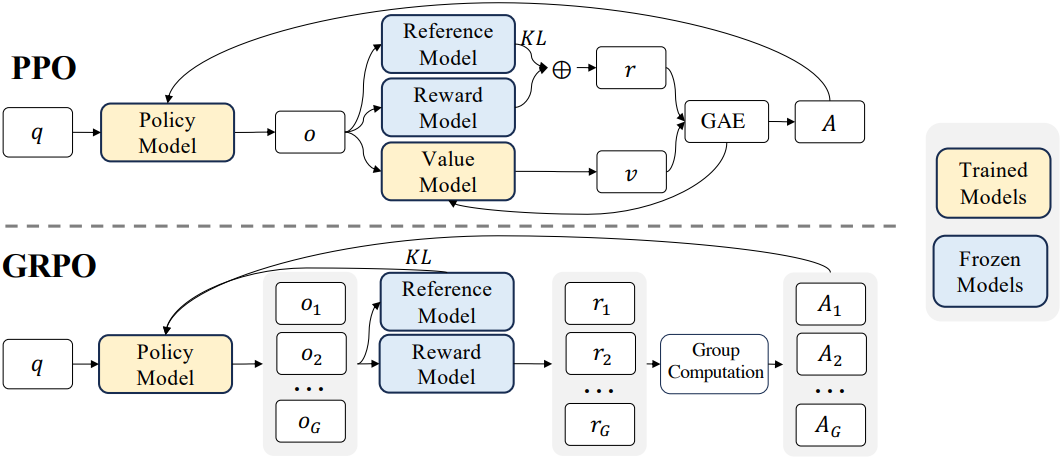
RL의 학습 비용을 절약하기 위해, 일반적으로 policy 모델과 같은 크기인 value 모델을 포기하고 대신 그룹 점수에서 기준선을 추정하는 Group Relative Policy Optimization (GRPO)를 채택한다. 구체적으로, 각 질문 $q$에 대해 GRPO는 이전 policy \(\pi_{\theta_\textrm{old}}\)에서 출력 그룹 \(\{o_i\}_{i=1}^G\)를 샘플링한 다음, 다음 목적 함수를 최대화하여 policy 모델 \(\pi_\theta\)를 최적화한다.
여기서 $\epsilon$과 $\beta$는 hyperparameter이고, $A_i$는 각 그룹 내의 출력에 대한 reward 그룹 \(\{r_i\}_{i=1}^G\)를 사용하여 계산된 advantage이다.
\[\begin{equation} A_i = \frac{r_i - \textrm{mean} (\{r_i\}_{i=1}^G)}{\textrm{std} (\{r_i\}_{i=1}^G)} \end{equation}\]2. Reward Modeling
저자들은 DeepSeek-R1-Zero를 학습시키기 위해 주로 두 가지 유형의 reward로 구성된 규칙 기반 reward 시스템을 채택하였다.
- Accuracy reward: 응답이 올바른지 평가하는 reward model
- Format reward: 사고 과정을 <think>와 </think> 태그 사이에 두도록 하는 reward model
저자들은 DeepSeek-R1-Zero를 개발할 때 결과나 과정의 neural reward model을 적용하지 않았다. 왜냐하면 neural reward model은 대규모 강화 학습 과정에서 reward hacking의 피해를 입을 수 있고, reward model을 재학습하는 데 추가적인 학습 리소스가 필요하며 전체 학습 파이프라인을 복잡하게 만들기 때문이다.
3. Training Template
DeepSeek-R1-Zero를 학습시키기 위해, 저자들은 base model이 지정된 명령을 준수하도록 가이드하는 간단한 템플릿을 설계하였다.
A conversation between User and Assistant. The user asks a question, and the Assistant solves it. The assistant first thinks about the reasoning process in the mind and then provides the user with the answer. The reasoning process and answer are enclosed within <think> </think> and <answer> </answer> tags, respectively, i.e., <think> reasoning process here </think> <answer> answer here </answer>. User: prompt. Assistant:
이 템플릿은 DeepSeek-R1-Zero가 먼저 추론 과정을 생성한 다음 최종 답을 생성하도록 요구한다. 저자들은 의도적으로 이 템플릿을 사용하도록 제한하여, 특정 문제 해결 전략을 촉진하는 것과 같은 컨텐츠별 편향을 피함으로써 RL 과정 동안 모델의 자연스러운 진행을 정확하게 관찰할 수 있도록 하였다.
4. Performance, Self-evolution Process and Aha Moment of DeepSeek-R1-Zero
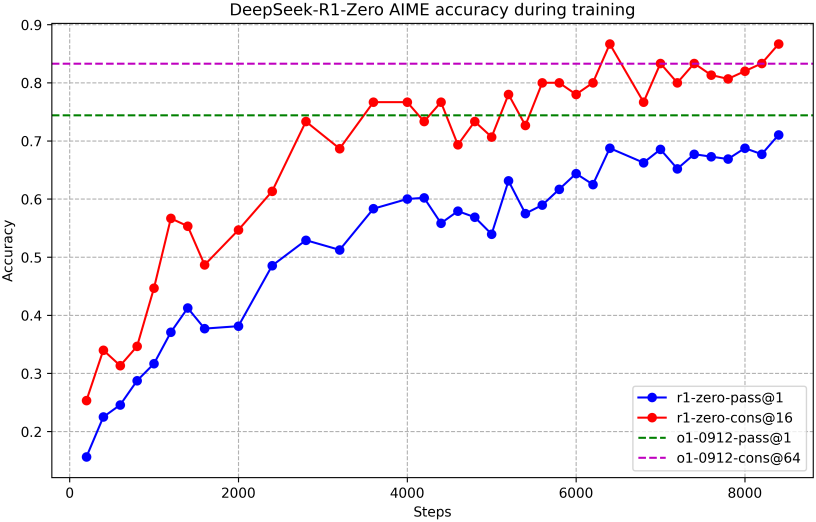
다음은 DeepSeek-R1-Zero와 OpenAI의 o1-0912 모델을 다양한 추론 벤치마크에서 비교한 표이다.
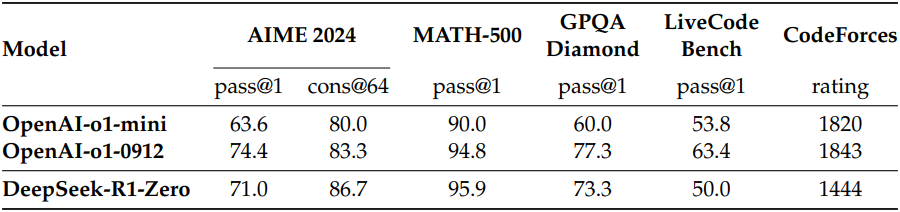
다음은 학습이 진행됨에 따라 DeepSeek-R1-Zero의 AIME 정확도의 변화를 나타낸 그래프이다.
다음은 학습이 진행됨에 따라 DeepSeek-R1-Zero의 응답 길이의 변화를 나타낸 그래프이다.

DeepSeek-R1-Zero는 더 많은 시간동안 생각하여 추론 task를 해결하는 방법을 자연스럽게 학습한다.
다음은 DeepSeek-R1-Zero의 중간 버전에서 나온 흥미로운 “aha moment”이다.

DeepSeek-R1-Zero는 초기 접근 방식을 재평가하여 문제에 더 많은 사고 시간을 할당하는 법을 배운다. 이러한 행동은 모델의 추론 능력이 향상되고 있다는 증거일 뿐만 아니라 강화 학습이 어떻게 예상치 못한 정교한 결과를 가져올 수 있는지에 대한 예시이기도 하다.
DeepSeek-R1: Reinforcement Learning with Cold Start
DeepSeek-R1-Zero에 자연스럽게 두 가지 의문이 생긴다.
- 소량의 고품질 데이터를 cold start로 통합하여 추론 성능을 더욱 개선하거나 수렴을 가속화할 수 있을까?
- 명확하고 일관된 chain-of-thought (CoT)을 생성할 뿐만 아니라 강력한 일반 역량을 보여주는 사용자 친화적인 모델을 어떻게 학습시킬 수 있을까?
저자들은 이러한 의문에 답하기 위해 DeepSeek-R1을 학습시키는 파이프라인을 설계하였으며, 파이프라인은 다음과 같은 4단계로 구성된다.
1. Cold Start
DeepSeek-R1-Zero와 달리, base model에서 RL 학습의 초기 불안정한 cold start 단계를 방지하기 위해, DeepSeek-R1의 경우 소량의 긴 CoT 데이터를 수집하여 모델을 fine-tuning하였다. 이러한 데이터를 수집하기 위해 긴 CoT를 예시로 하는 few-shot prompting을 사용하고, 모델에 직접 프롬프팅하여 자세한 답변을 생성하고, DeepSeek-R1-Zero 출력을 읽을 수 있는 형식으로 수집하고, 사람이 직접 후처리를 통해 결과를 정제하였다.
저자들은 수천 개의 cold start 데이터를 수집하여 RL의 시작점으로 DeepSeek-V3-Base를 fine-tuning하였다. DeepSeek-R1-Zero와 비교했을 때 cold start 데이터의 장점은 다음과 같다.
- 가독성: DeepSeek-R1-Zero의 주요 한계점은 종종 가독성이 떨어진다는 것이다. 응답은 여러 언어를 혼합하거나 사용자에게 답변을 강조하기 위한 markdown 형식이 부족할 수 있다. 반면 DeepSeek-R1에 대한 cold start 데이터를 생성할 때, 저자들은 각 응답의 끝에 요약을 포함하고 사용자에게 친숙하지 않은 응답을 필터링하는 읽기 쉬운 패턴을 설계하였다.
- 잠재력: 인간의 사전 지식으로 cold start 데이터에 대한 패턴을 신중하게 설계함으로써 DeepSeek-R1-Zero보다 더 나은 성능을 낼 수 있다.
2. Reasoning-oriented Reinforcement Learning
DeepSeek-V3-Base를 cold start 데이터에서 fine-tuning한 후, DeepSeek-R1-Zero에서 사용한 것과 동일한 대규모 RL 학습 프로세스를 적용한다. 이 단계는 모델의 추론 능력을 향상시키는 데 중점을 두며, 특히 명확한 답이 있는 코딩, 수학, 과학 및 논리적 추론과 같은 추론 집약적인 task에서 그렇다.
학습 프로세스 동안 CoT가 종종 여러 언어를 혼합하는 것이 관찰되었다. 특히 RL 프롬프트에 여러 언어가 포함될 때 그렇다. 언어 혼합 문제를 완화하기 위해 RL 학습 중에 언어 일관성 reward를 도입한다. 이는 CoT에서 대상 언어 단어의 비율로 계산된다. 이러한 reward의 도입이 모델의 성능을 약간 저하시키지만, 인간의 선호도와 더 일치하며 더 읽기 쉽다. 최종 reward는 추론 task에 대한 정확도와 언어 일관성에 대한 reward를 합산한 것이며, 추론 task에서 fine-tuning된 모델이 수렴할 때까지 RL 학습을 적용한다.
3. Rejection Sampling and Supervised Fine-Tuning
RL이 수렴하면, 결과 체크포인트를 활용하여 후속 라운드를 위한 SFT 데이터를 수집한다. 주로 추론에 초점을 맞춘 초기 cold start 데이터와 달리, 이 단계는 다른 도메인의 데이터를 통합하여 쓰기, 롤플레잉, 기타 범용 task들에서 모델의 역량을 향상시킨다. 구체적으로, 아래에 설명된 대로 데이터를 생성하고 모델을 fine-tuning하였다.
추론 데이터
위의 RL 학습의 체크포인트에서 기각 샘플링(rejection sampling)을 수행하여 추론 프롬프트를 큐레이션하고 추론 궤적을 생성한다. 이전 단계에서는 규칙 기반 reward를 사용하여 평가할 수 있는 데이터만 포함했지만, 이 단계에서는 추가 데이터를 통합하여 데이터셋을 확장한다. 이 중 일부는 판단을 위해 DeepSeek-V3에 ground-truth와 모델 예측을 입력하여 reward를 생성한다. 또한 모델 출력이 때때로 혼란스럽고 읽기 어렵기 때문에 여러 언어가 혼합되어 있거나, 긴 단락 및 코드 블록이 있는 CoT를 필터링했다. 각 프롬프트에 대해 여러 응답을 샘플링하고 올바른 응답만 사용한다. 저자들은 총 약 60만 개의 추론 관련 학습 샘플을 수집하였다.
추론과 관련 없는 데이터
쓰기, 사실적 QA, 자기 인지, 번역과 같은 추론과 관련 없는 데이터의 경우, DeepSeek-V3 파이프라인을 채택하고 DeepSeek-V3의 SFT 데이터셋의 일부를 재사용한다. 특정 task들의 경우, DeepSeek-V3를 호출하여 프롬프트를 통해 질문에 답하기 전에 잠재적인 chain-of-thought을 생성한다. “안녕하세요”와 같은 더 간단한 질문의 경우 응답으로 CoT를 제공하지 않는다. 저자들은 추론과 관련 없는 총 약 20만 개의 학습 샘플을 수집했다.
저자들은 약 80만 개의 샘플로 구성된 데이터셋을 사용하여 두 epoch에 걸쳐 DeepSeek-V3-Base를 fine-tuning하였다.
4. Reinforcement Learning for all Scenarios
저자들은 모델을 인간의 선호도에 더욱 맞추기 위해 모델의 유용성과 무해성을 개선하는 동시에 추론 능력을 개선하는 것을 목표로 하는 2차 RL 단계를 구현하였다.
추론 데이터의 경우, DeepSeek-R1-Zero와 동일한 방법을 따르며, 이는 규칙 기반 reward를 활용하여 수학, 코딩 및 논리적 추론 도메인에서 학습 프로세스를 가이드한다. 일반 데이터의 경우, DeepSeek-V3 파이프라인을 기반으로 하여 유사한 선호도 쌍과 학습 프롬프트 분포를 채택하였다.
유용성의 경우 최종 요약에만 집중하여 평가가 기본 추론 프로세스에 대한 간섭을 최소화하면서 사용자에 대한 응답의 유용성과 관련성을 강조하도록 한다. 무해성의 경우 추론 프로세스와 요약을 포함하여 모델의 전체 응답을 평가하여 생성 프로세스 중에 발생할 수 있는 잠재적 위험, 편향, 유해한 콘텐츠를 식별하고 완화한다.
궁극적으로 reward 신호와 다양한 데이터 분포를 통합하면 유용성과 무해성을 우선시하면서 추론 능력이 뛰어난 모델을 학습시킬 수 있다.
Distillation: Empower Small Models with Reasoning Capability
저자들은 DeepSeek-R1과 같은 추론 능력을 갖춘 더 효율적인 소규모 모델을 갖추기 위해, 앞서 큐레이팅한 80만 개의 샘플을 사용하여 Qwen, Llama와 같은 오픈소스 모델을 직접 fine-tuning했다. 이 간단한 distillation 방법은 소규모 모델의 추론 능력을 크게 향상시킨다. 사용되는 base model은 Qwen2.5-Math-1.5B, Qwen2.5-Math-7B, Qwen2.5-14B, Qwen2.5-32B, Llama-3.1-8B, Llama-3.3-70B-Instruct이다.
Distillation된 모델의 경우, SFT만 적용하고 RL 단계는 포함하지 않는다. RL을 통합하면 모델 성능이 상당히 향상될 수 있지만, 여기서 주요 목표는 distillation 기술의 효과를 입증하는 것이기 때문이다.
Experiment
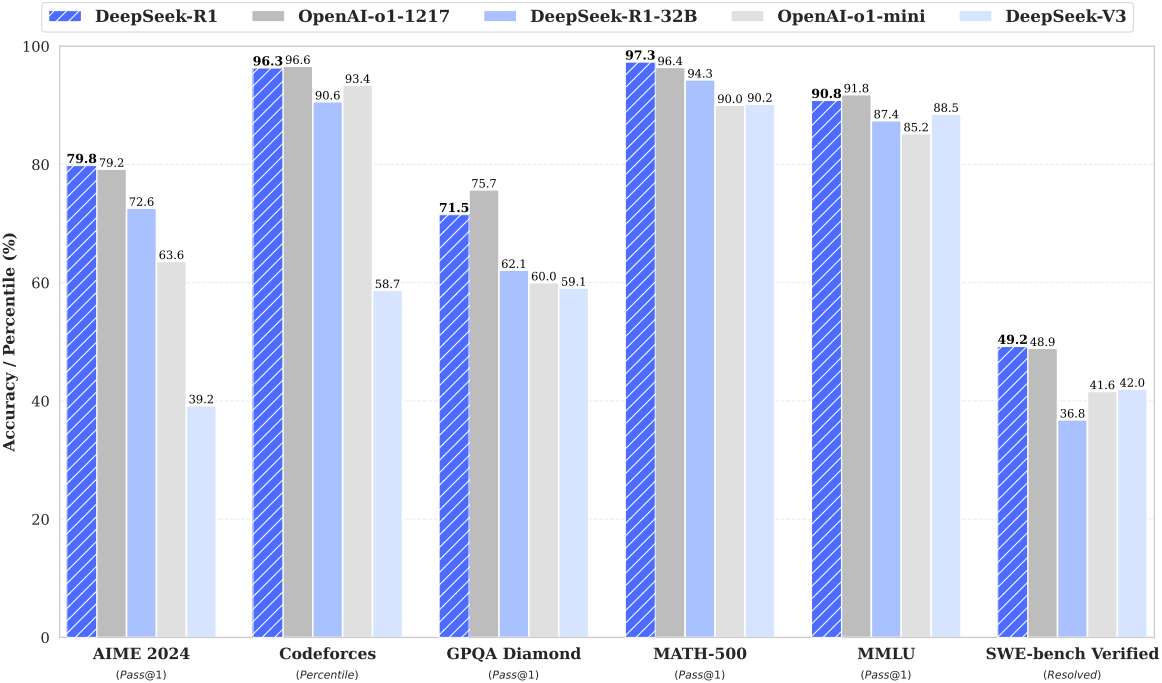
1. DeepSeek-R1 Evaluation
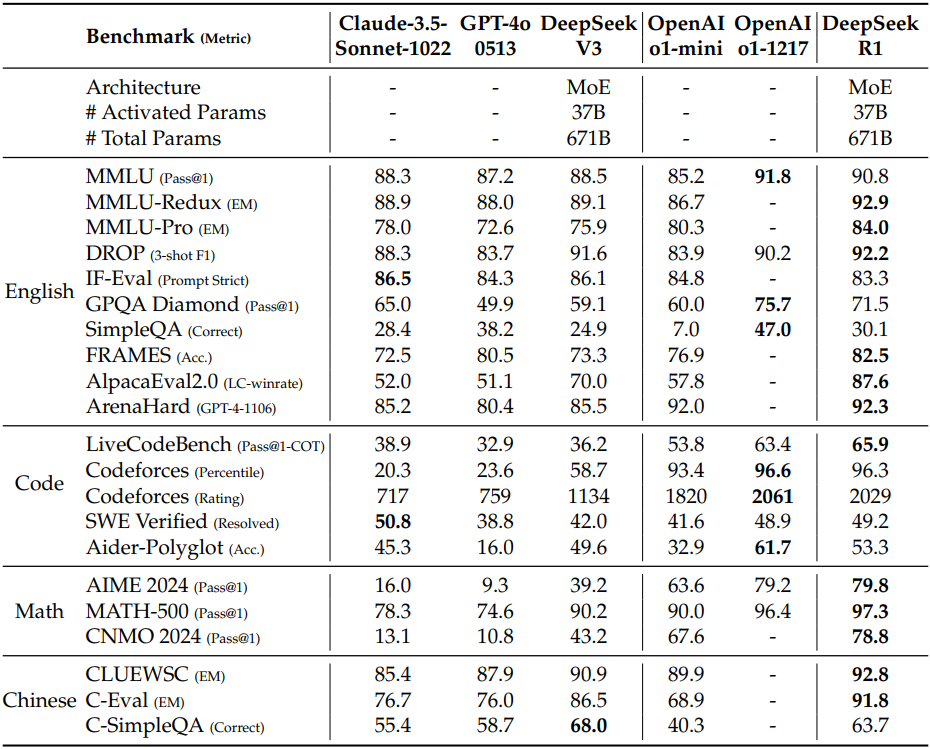
다음은 DeepSeek-R1을 다른 모델들과 비교한 결과이다.
2. Distilled Model Evaluation
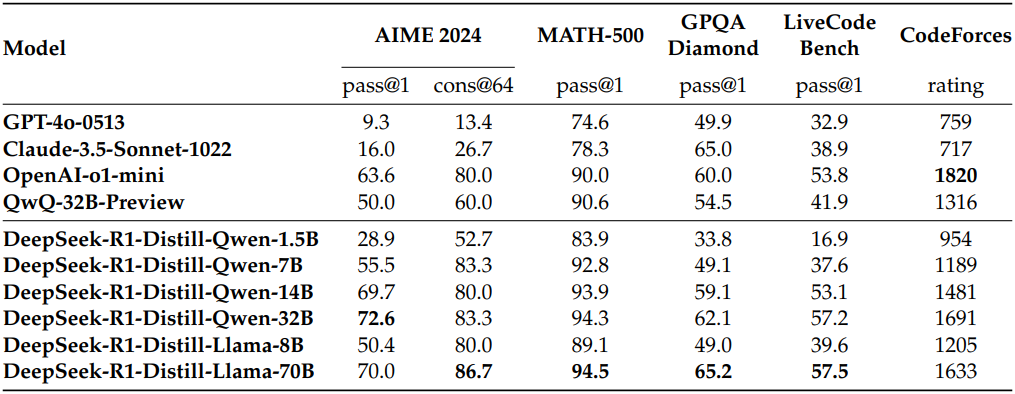
다음은 DeepSeek-R1에서 distillation된 모델들을 다른 모델들과 비교한 결과이다.
3. Distillation vs. Reinforcement Learning
다음은 추론 벤치마크들에서 distillation된 모델과 RL 모델을 비교한 결과이다.

Limitations
- 일반적인 능력: DeepSeek-R1은 함수 호출, 멀티턴 대화, 복잡한 역할 수행, JSON 출력 등의 task에서 DeepSeek-V3보다 성능이 떨어진다.
- 언어 혼합 문제: DeepSeek-R1은 현재 중국어와 영어에 최적화되어 있어, 다른 언어의 질문을 처리할 때 언어 혼합 문제가 발생할 수 있다. 즉, 영어와 중국어가 아닌 언어로 질문해도 DeepSeek-R1이 영어로 추론 및 응답할 가능성이 있다.
- 프롬프트 엔지니어링: DeepSeek-R1은 프롬프트에 민감하게 반응하는 경향이 있다. 특히, few-shot 프롬프트를 사용할 경우 성능이 저하된다. 따라서, 문제를 직접 설명하고 출력 형식을 지정하는 zero-shot 설정을 활용하는 것이 최적의 결과를 얻는 방법이다.
- 소프트웨어 엔지니어링 task: 소프트웨어 엔지니어링 task의 경우, 평가 시간이 길어 대규모 RL이 충분히 적용되지 않았다. 이로 인해 DeepSeek-R1은 소프트웨어 엔지니어링 벤치마크에서 DeepSeek-V3 대비 큰 성능 향상을 보이지 못했다.