[논문리뷰] Label-Efficient Semantic Segmentation with Diffusion Models
ICLR 2022. [Paper] [Page] [Github]
Dmitry Baranchuk, Ivan Rubachev, Andrey Voynov, Valentin Khrulkov, Artem Babenko
Yandex Research
6 Dec 2021
Introduction
DDPM은 최근 개별 샘플의 사실성과 다양성 모두에서 자연 이미지의 분포를 모델링하는 다른 접근 방식들을 능가했다. DDPM의 이러한 장점은 DDPM이 종종 GAN에 비해 더 인상적인 결과를 달성하는 colorization, inpainting, super-resolution, semantic editing과 같은 애플리케이션에서 성공적으로 활용된다.
그러나 지금까지 DDPM은 discriminative한 컴퓨터 비전 문제에 대한 효과적인 이미지 표현의 소스로 활용되지 않았다. 이전 연구들에서는 GAN 또는 autoregressive model과 같은 다양한 생성 모델을 사용하여 일반적인 비전 task에 대한 표현을 추출할 수 있음을 보여 주었지만 DDPM이 표현 학습자 역할을 할 수 있는지는 확실하지 않다. 본 논문에서는 semantic segmentation의 맥락에서 이 질문에 대한 긍정적인 답을 제공한다.
특히 DDPM에서 reverse diffusion process의 Markov step에 근접한 U-Net 네트워크의 중간 activation을 조사한다. 직관적으로 이 네트워크는 입력의 noise를 제거하는 방법을 학습하며 중간 activation이 높은 수준의 비전 문제에 필요한 semantic 정보를 캡처해야 하는 이유가 명확하지 않다. 그럼에도 불구하고 저자들은 특정 diffusion step에서 activation이 그러한 정보를 캡처하므로 잠재적으로 downstream task에 대한 이미지 표현으로 사용될 수 있음을 보여준다. 이러한 관찰을 감안할 때, 저자들은 이러한 표현을 활용하고 레이블이 지정된 이미지가 몇 개만 제공되는 경우에도 성공적으로 작동하는 간단한 semantic segmentation 방법을 제안한다.
Representations from Diffusion Models
Background
자세한 내용은 DDPM 논문리뷰 참고
Forward diffusion process:
\[\begin{equation} q(x_t \vert x_{t-1}) := \mathcal{N} (x_t; \sqrt{1 - \beta_t} x_{t-1}, \beta_t I) \\ q(x_t \vert x_0) := \mathcal{N} (x_t; \sqrt{\vphantom{1} \bar{\alpha}_t} x_0, (1 - \bar{\alpha}_t) I), \\ x_t = \sqrt{\vphantom{1} \bar{\alpha}_t} x_0 + \sqrt{1 - \bar{\alpha}_t} \epsilon, \quad \epsilon \sim \mathcal{N}(0, I), \\ \textrm{where} \quad \alpha_t := 1 - \beta_t, \; \bar{\alpha}_t := \prod_{s=1}^t \alpha_s \end{equation}\]Reverse process:
\[\begin{equation} p_\theta (x_{t-1}, x_t) := \mathcal{N} (x_{t-1}; \mu_\theta (x_t, t) \Sigma_\theta (x_t, t)) \end{equation}\]Extracting representations
주어진 실제 이미지 $x_0 \in \mathbb{R}^{H \times W \times 3}$에 대해 noise 예측 네트워크 $\epsilon_\theta (x_t, t)$에서 activation 텐서의 집합 $T$개를 계산할 수 있다. 먼저 forward process 식에 따라 Gaussian noise를 추가하여 $x_0$를 손상시킨다. Noisy한 $x_t$는 UNet 모델에 의해 parameterize된 $\epsilon_\theta (x_t, t)$의 입력으로 사용된다. 그런 다음 UNet의 중간 activation은 bilinear interpolation을 사용하여 $H \times W$로 upsampling된다. 이를 통해 $x_0$의 픽셀 레벨 표현으로 처리할 수 있다.
1. Representation Analysis
저자들은 서로 다른 $t$에 대해 $\epsilon_\theta (x_t, t)$에 의해 생성된 표현을 분석하였으며, LSUN-Horse과 FFHQ-256 데이터 셋에서 학습된 state-of-the-art DDPM 체크포인트를 사용한다.
이 실험을 위해 LSUN-Horse와 FFHQ 데이터셋에서 몇 개의 이미지를 가져오고 각 픽셀을 각각 21과 34 semantic class 중 하나에 수동으로 할당한다. 저자들의 목표는 DDPM에서 생성된 픽셀 레벨 표현이 semantic 정보를 효과적으로 캡처하는지 여부를 이해하는 것이다. 이를 위해 특정 diffusion step $t$에서 18개의 UNet 디코더 블록 중 하나에 의해 생성된 feature에서 픽셀 semantic label을 예측하도록 MLP를 학습시킨다. Skip connection을 통해 인코더 activation도 집계하기 때문에 디코더 activation만 고려한다. MLP는 20개의 이미지로 학습되고 20개의 hold-out 이미지로 평가된다. 예측 성능은 평균 IoU로 측정된다.
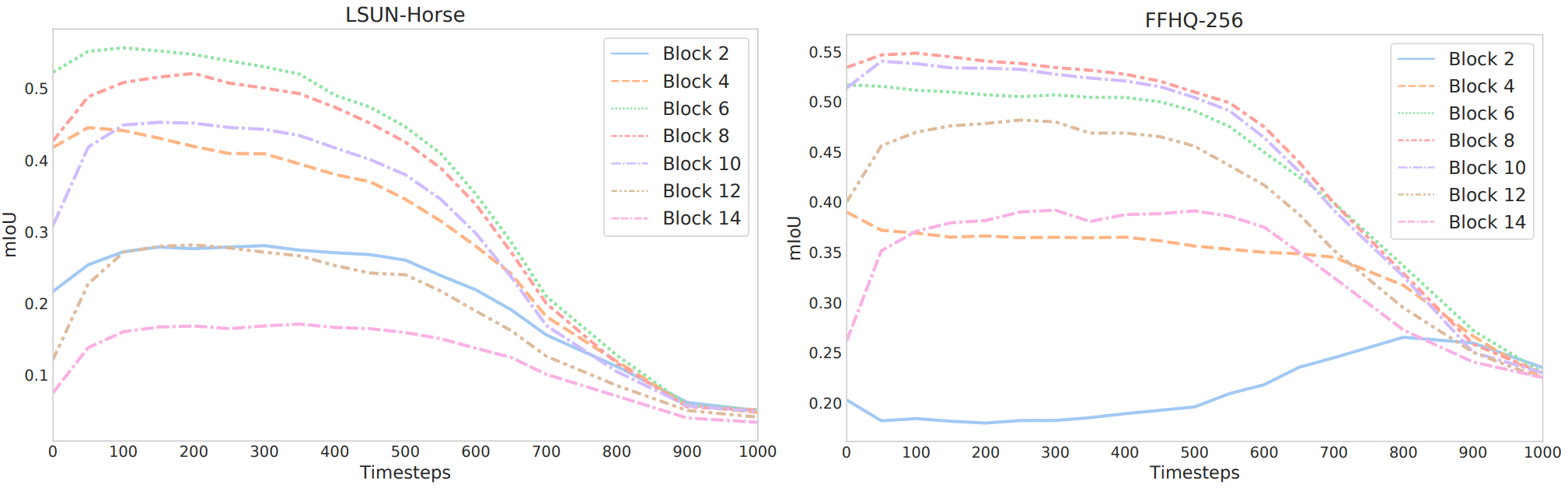
서로 다른 블록과 $t$에 따른 예측 성능의 진화는 위 그래프에 나와 있다. 블록은 깊은 것부터 얕은 것까지 번호가 매겨져 있다. 위 그래프는 $\epsilon_\theta (x_t, t)$에 의해 생성된 feature의 식별 가능성이 블록과 $t$에 따라 달라지는 것을 보여준다. 특히, reverse diffusion process의 나중 step에 해당하는 feature는 일반적으로 semantic 정보를 보다 효과적으로 캡처한다. 대조적으로 초기 step에 해당하는 것은 일반적으로 정보가 없다. 여러 블록에서 UNet 디코더 중간에 있는 layer에서 생성된 feature는 모든 diffusion step에서 가장 유익한 것으로 보인다.
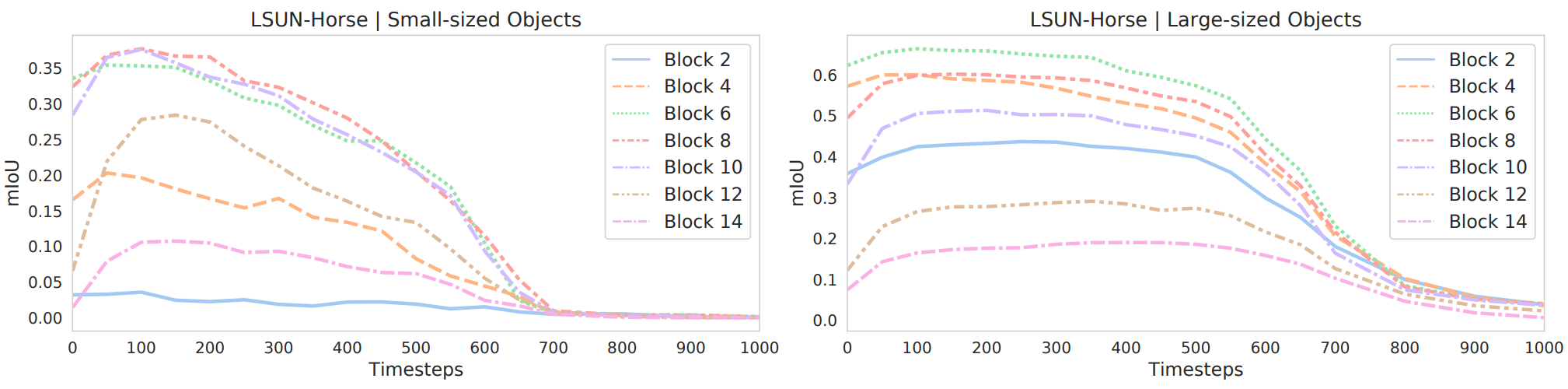
또한 주석이 달린 데이터셋의 평균 면적을 기준으로 소형 semantic class와 대형 semantic class를 구분하여 고려한다. 그런 다음 서로 다른 UNet 블록과 diffusion step에서 이러한 클래스에 대한 평균 IoU를 독립적으로 평가한다. LSUN-Horse에 대한 결과는 위 그래프에 나와 있다. 예상대로 대형 객체에 대한 예측 성능은 reverse process에서 더 일찍 증가하기 시작한다. 더 얕은 블록은 더 작은 객체에 대해 더 많은 정보를 제공하는 반면, 더 깊은 블록은 더 큰 객체에 대해 더 많은 정보를 제공한다. 두 경우 모두 가장 구별되는 feature은 여전히 중간 블록에 해당한다.

특정 UNet 블록과 diffusion step에 대해 유사한 DDPM 기반 표현이 동일한 semantic의 픽셀에 해당함을 의미한다. 위 그림은 diffusion step {50, 200, 400, 600, 800}에서 블록 {6, 8, 10, 12}의 FFHQ 체크포인트에 의해 추출된 feature에 의해 형성된 k-means clusters ($k=5$)를 보여준다. 클러스터가 일관된 semantic 객체와 객체 부분을 포괄할 수 있음을 확인할 수 있다. 블록 $B=6$에서 feature는 대략적인 semantic mask에 해당한다. 반면, $B=12$의 feature는 세밀한 얼굴 부분을 구별할 수 있지만 거친 조각에 대한 semantic 의미는 덜 나타난다.
다양한 diffusion step에서 가장 의미 있는 feature는 나중의 feature에 해당한다. 이 동작은 reverse process의 초기 step에서 DDPM 샘플의 글로벌한 구조가 아직 나타나지 않았기 때문에 이 step에서 segmentation mask를 예측하는 것이 거의 불가능하다는 사실에 기인한다. 이 직관은 위 그림의 마스크에 의해 정성적으로 확인된다. $t=800$의 경우 마스크는 실제 이미지의 내용을 제대로 반영하지 못하는 반면 $t$의 값이 더 작은 경우 마스크와 이미지는 의미론적으로 일관성이 있다.
2. DDPM-Based Representations for Few-Shot Semantic Segmentation
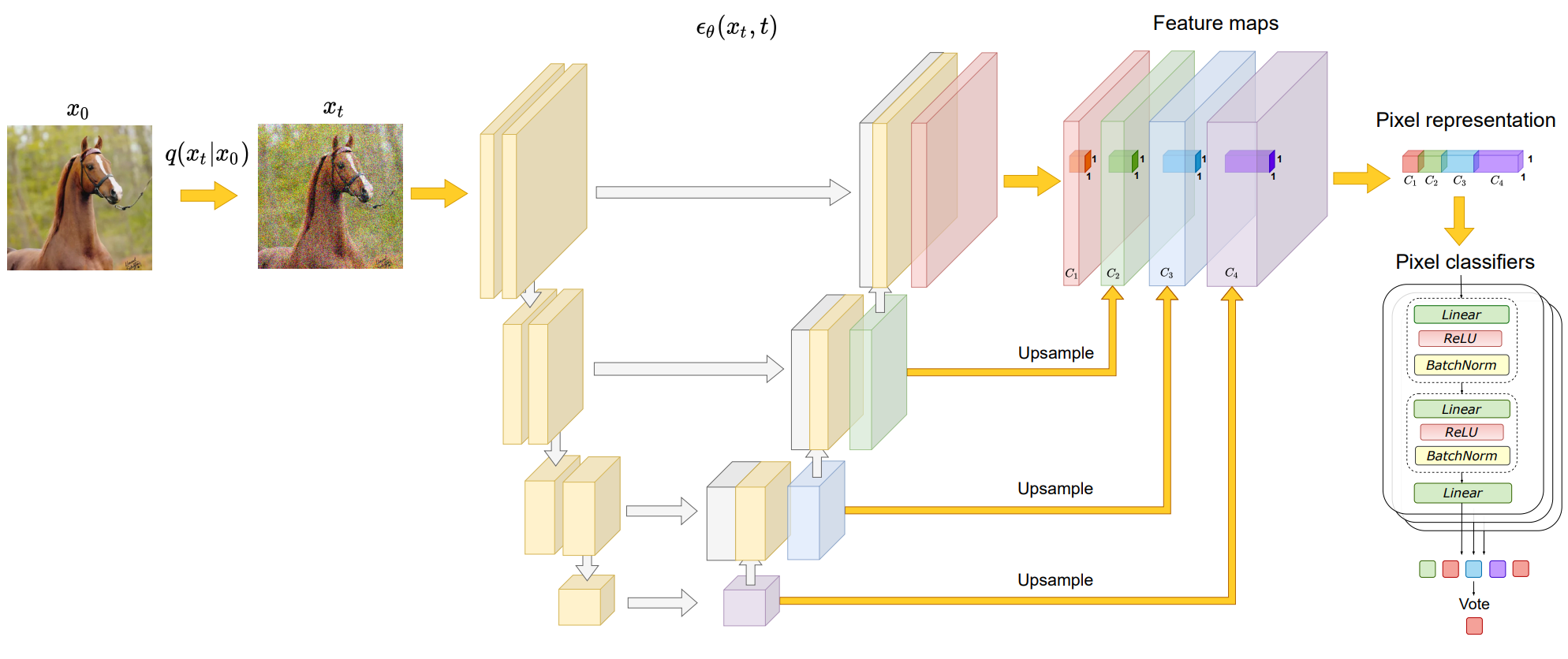
위에서 관찰된 중간 DDPM activation의 잠재적 효과는 조밀한 예측 task을 위한 이미지 표현으로 사용됨을 의미한다. 위 그림은 이러한 표현의 식별성을 활용하는 image segmentation에 대한 전반적인 접근 방식을 개략적으로 보여준다.
특정 도메인에서 레이블이 지정되지 않은 많은 수의 이미지 \(\{X_1, \cdots, X_N\} \subset \mathbb{R}^{H \times W \times 3}\)을 사용할 수 있으며, $n$ 개의 학습 이미지 \(\{X_1, \cdots, X_n\} \subset \mathbb{R}^{H \times W \times 3}\)에 대해서만 ground-truth $K$-class semantic masks \(\{Y_1, \cdots, Y_n\} \subset \mathbb{R}^{H \times W \times \{1, \cdots, K\}}\)가 제공된다.
첫 번째 단계로 전체 \(\{X_1, \cdots, X_N\}\)에서 unsupervised 방식으로 diffusion model을 학습 시킨다. 그런 다음 이 diffusion model은 UNet 블록의 부분 집합과 $t$를 사용하여 레이블이 지정된 이미지의 픽셀 레벨 표현을 추출하는 데 사용된다. 본 논문에서는 UNet 디코더의 중간 블록 \(B = \{5, 6, 7, 8, 12\}\)와 reverse diffusion process의 나중 step \(t = \{50, 150, 250\}\)의 표현을 사용한다.
특정 timestep에서의 feature 추출은 확률적이지만 모든 timestep에 대한 noise를 고정하고 제거한다. 모든 $B$와 $t$에서 추출된 표현은 이미지 크기로 upsampling되고 concat되어 학습 이미지의 모든 픽셀에 대한 feature vector를 형성한다. 픽셀 레벨 표현의 전체 차원은 8448이다.
그런 다음, DatasetGAN을 따라 이미지 학습에 사용할 수 있는 각 픽셀의 semantic label을 예측하는 것을 목표로 하는 이러한 feature vector에 대해 독립적인 MLP의 앙상블을 학습시킨다. 저자들은 DatasetGAN의 앙상블 구성 및 학습 설정을 채택하고 실험의 모든 방법에서 활용한다.
테스트 이미지를 분할하기 위해 DDPM 기반 pixel-wise 표현을 추출하고 이를 사용하여 앙상블에 의한 픽셀 label을 예측한다. 최종 예측은 앙상블의 다수결로 결정된다.
Experiments
- 데이터셋
- LSUN (bedroom, cat, horse) $\rightarrow$ Bedroom-28, Cat-15, Horse-21
- FFHQ-256 $\rightarrow$ FFHQ-34
- ADE-Bedroom-30 (ADE20K의 부분 집합)
- CelebA-19 (CelebAMask-HQ의 부분 집합)
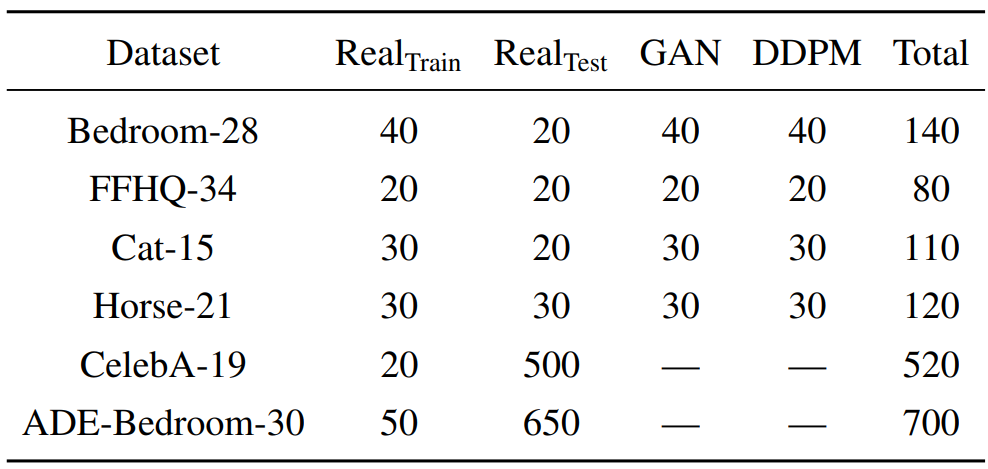
각 데이터셋에 대한 주석이 달린 이미지의 수는 아래 표와 같다.
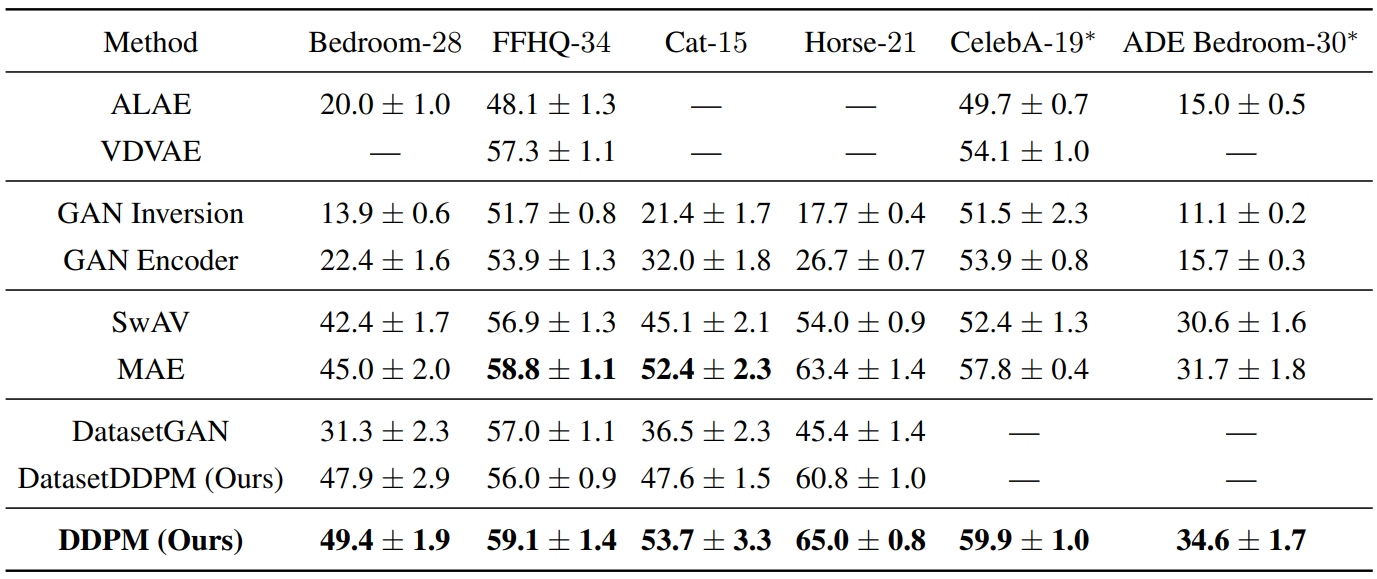
1. Main results
다음은 segmentation 방법을 평균 IoU로 비교한 표이다.
다음은 ground-truth 주석이 달린 마스크와 함께 테스트 이미지에서 본 논문의 방법으로 예측한 segmentation mask의 예시이다.

2. The effect of training on real data
다음은 실제 이미지와 합성된 이미지로 학습되었을 때 DDPM 기반 segmentation의 성능을 비교한 표이다.

실제 이미지에 대한 학습은 생성 모델의 fidelity가 여전히 상대적으로 낮은 도메인(ex. LSUN-Cat)에서 매우 유익하며 주석이 달린 실제 이미지가 보다 신뢰할 수 있는 supervision 소스임을 나타낸다. 또한 DDPM 방법을 합성 이미지로 학습하면 성능이 DatasetDDPM과 동등해진다. 반면에 GAN으로 생성된 샘플을 학습할 때 DDPM은 DatasetGAN보다 훨씬 뛰어난 성능을 보인다. 저자들은 이것이 DDPM이 GAN에 비해 더 의미론적으로 가치 있는 픽셀 단위 표현을 제공한다는 사실 때문이라고 생각한다.
3. Sample-efficiency
다음은 서로 다른 수의 레이블링된 학습 데이터로 본 논문의 방법을 평가한 표이다.

4. The effect of stochastic feature extraction
다음은 다양한 feature 추출 변형에 대한 DDPM 기반 방법의 성능을 나타낸 표이다.
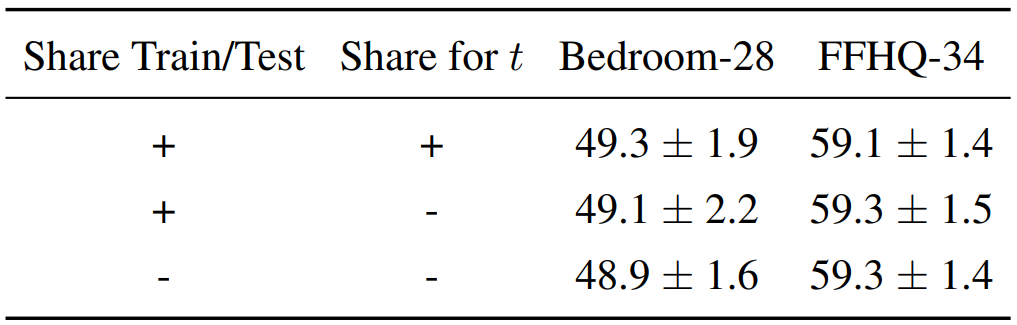
성능의 차이는 미미하다. 다음과 같은 이유로 이러한 동작이 발생한다.
- 본 논문의 방법은 noise 크기가 낮은 reverse diffusion process의 나중의 $t$를 사용한다.
- UNet 모델의 layer를 활용하기 때문에 noise가 layer의 activation에 크게 영향을 미치지 않을 수 있다.
5. Robustness to input corruptions
다음은 Bedroom-28과 Horse-21 데이터셋에서 다양한 이미지 손상 레벨에 대한 mIoU 저하를 나타낸 표이다.
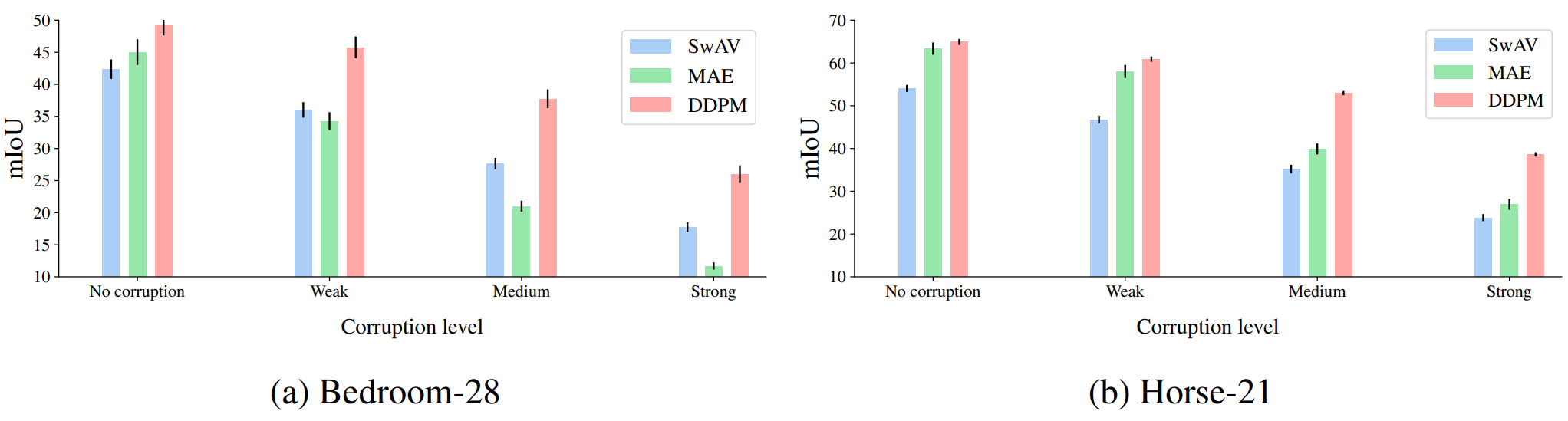
제안된 DDPM 기반 방법은 심한 이미지 왜곡에도 SwAV와 MAE 모델보다 더 높은 견고성과 이점을 유지함을 관찰할 수 있다.