[논문리뷰] DDP: Diffusion Model for Dense Visual Prediction
arXiv 2023. [Paper] [Github]
Yuanfeng Ji, Zhe Chen, Enze Xie, Lanqing Hong, Xihui Liu, Zhaoqiang Liu, Tong Lu, Zhenguo Li, Ping Luo
The University of Hong Kong | Huawei Noah’s Ark Lab | Nanjing University
30 Mar 2023
Introduction
Dense prediction task는 semantic segmentation, 깊이 추정, optical flow와 같은 광범위한 지각적 task를 포함하여 컴퓨터 비전 연구의 기초이다. 이러한 task에는 이미지의 모든 픽셀에 대한 불연속 레이블 또는 연속 값을 정확하게 예측해야 한다. 이를 통해 상황에 대한 자세한 이해를 제공하고 다양한 애플리케이션을 사용할 수 있다.
수많은 방법이 단기간에 이 task의 결과를 빠르게 개선했다. 일반적으로 이러한 방법은 판별 기반과 생성 기반의 두 가지 패러다임으로 나눌 수 있다. 판별 기반 접근 방식은 입력-출력 쌍 간의 매핑을 직접 학습하고 한 번의 forward step으로 예측하며, 단순성과 효율성 때문에 현재 사실상의 선택이 되었다. 반면 생성 모델은 데이터의 기본 분포를 모델링하는 것을 목표로 하며 개념적으로 어려운 task를 처리할 수 있는 더 큰 capacity를 갖는다. 그러나 복잡한 아키텍처와 다양한 학습 어려움으로 인해 제한되는 경우가 많다.
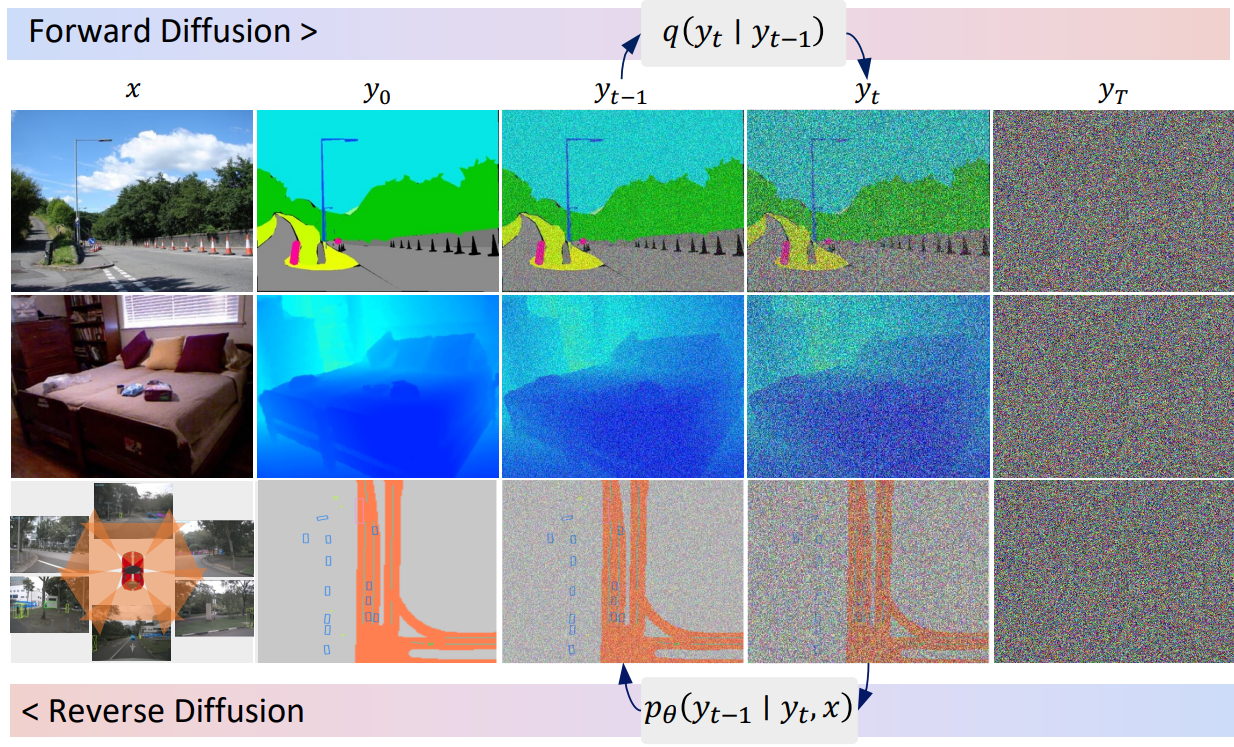
이러한 문제는 주로 diffusion model과 score 기반 모델에 의해 해결되었다. Denosing diffusion process를 기반으로 하는 솔루션은 개념적으로 간단하다. 지속적인 diffusion process를 적용하여 데이터를 noise로 변환하고 reverse process를 시뮬레이션하여 새 샘플을 생성한다. 이러한 방법은 이제 쉽게 학습할 수 있고 다양한 생성 task에서 우수한 결과를 얻을 수 있다. 이러한 큰 성공을 목격하면서 최근 semantic segmentation과 깊이 추정을 포함한 dense prediction task에 diffusion process를 도입하는 데 관심이 급증했다. 그러나 단순히 무거운 프레임워크를 이미지 생성 task에서 dense prediction task로 이전하므로 효율성이 낮고 수렴이 느리며 성능이 최적화되지 않는다.
본 논문에서는 dense prediction task를 위한 일반적이고 단순하지만 효과적인 diffusion 프레임워크를 소개한다. Denosing diffusion process를 현대 perception 파이프라인으로 효과적으로 확장하는 본 논문의 방법을 DDP라고 부른다. 학습하는 동안 noise schedule에 의해 제어되는 Gaussian noise가 noisy한 map을 얻기 위해 인코딩된 ground-truth에 추가된다. 그런 다음 이러한 noise map은 이미지 인코더(ex. Swin Transformer)의 조건부 feature와 융합된다. 마지막으로 이러한 융합된 feature는 가벼운 map decoder에 공급되어 noise 없이 예측을 생성한다. Inference 단계에서 DDP는 테스트 이미지의 guidance에 따라 noisy한 가우시안 분포를 학습된 map 분포로 조정하는 학습된 diffusion process를 reverse하여 예측을 생성한다.
이전의 번거로운 diffusion perception model과 비교하여 DDP는 이미지 인코더와 map decoder를 분리한다. 이미지 인코더는 한 번만 실행되는 반면 diffusion process는 가벼운 디코더 헤드에서만 수행된다. 이 효율적인 설계를 통해 현대 perception task에 쉽게 적용될 수 있다. 또한 이전의 단일 단계 판별 모델과 달리 DDP는 공유 파라미터를 사용하여 반복 inference를 여러 번 수행할 수 있으며 다음과 같은 매력적인 속성을 가진다.
- 계산 및 예측 품질을 절충하기 위한 동적 inference
- 예측 불확실성에 대한 자연스러운 인식
Methodology
1. Preliminaries
Dense Prediction
Dense prediction task의 목적은 입력 이미지 $x \in \mathbb{R}^{3 \times h \times w}$에 있는 모든 픽셀에 대해 불연속 레이블 또는 연속 값 $y$를 예측하는 것이다.
Conditional Diffusion Model
Diffusion model의 확장인 조건부 diffusion model은 likelihood 기반 모델의 카테고리에 속한다. 조건부 diffusion model은 데이터 샘플에 점진적으로 noise를 추가하여 forward noising process를 다음과 같이 가정한다.
\[\begin{equation} q(z_t \vert z_0) = \mathcal{N} (z_t; \sqrt{\vphantom{1} \bar{\alpha}_t} z_0, (1 - \bar{\alpha}_t) I) \\ \bar{\alpha}_t := \prod_{s=0}^t \alpha_s = \prod_{s=0}^t (1 - \beta_s) \end{equation}\]여기서 데이터 샘플은 $z_0$, noisy한 샘플은 $z_t$이며, $\beta_s$는 noise schedule을 나타낸다. 학습 중에 reverse process model $f_\theta (z_t, x, t)$는 목적 함수를 최소화하여 조건 $x$의 guidance 하에서 $z_t$에서 $z_0$를 예측하도록 학습된다. Inference 단계에서는 예측 데이터 샘플 $z_0$는 모델 $f_\theta$, 조건부 입력 $x$, Markovian 방식의 transition 규칙을 사용하여 랜덤 noise $z_T$로부터 재구성된다.
\[\begin{equation} p_\theta (z_{0:T} \vert x) = p(z_T) \prod_{t=1}^T p_\theta (z_{t-1} \vert z_t, x) \end{equation}\]본 논문의 목표는 조건부 diffusion model을 통해 dense prediction task를 해결하는 것이다. 데이터 샘플은 ground truth map $z_0 = y$이고, 신경망 $f_\theta$는 해당 이미지 $x$를 조건으로 랜덤 noise $z_t \sim \mathcal{N}(0, I)$에서 $z_0$를 예측하도록 학습된다.
2. Architecture
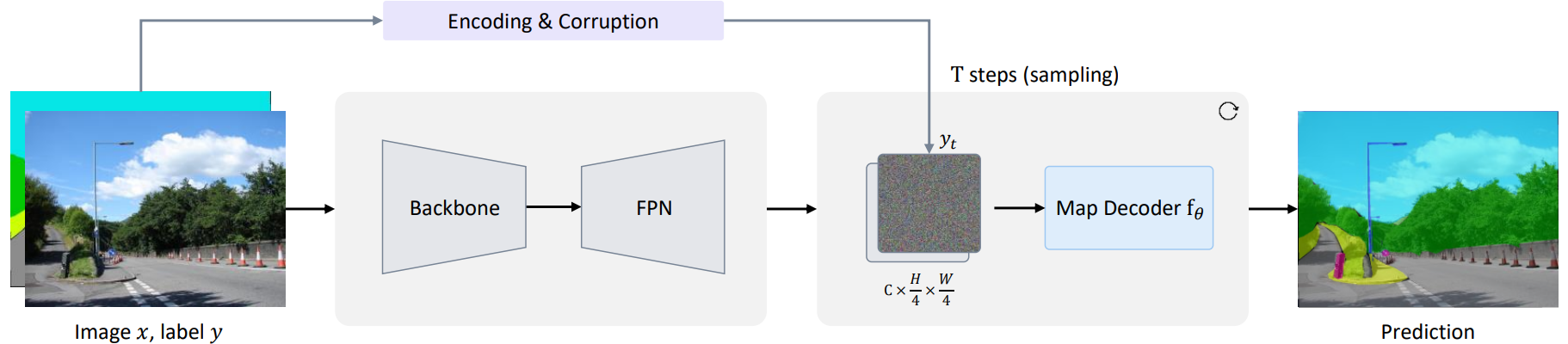
Diffusion model은 샘플을 점진적으로 생성하므로 inference 단계에서 모델을 여러 번 실행해야 한다. 이전 방법은 이미지 $x$에 여러 단계로 모델 $f_\theta$를 적용하여 계산 오버헤드를 크게 증가시킨다. 이 문제를 완화하기 위해 위 그림과 같이 전체 모델을 이미지 인코더와 맵 디코더의 두 부분으로 분리한다. 이미지 인코더는 입력 이미지 $x$에서 feature map을 추출하기 위해 한 번만 실행된다. 그런 다음 map decoder는 이미지 $x$를 조건으로 사용하여 noisy한 맵 $y_t$에서 예측을 점차 구체화한다.
Image Encoder
이미지 인코더는 이미지 $x$를 입력으로 받고 4가지 해상도에서 멀티스케일 feature를 생성한다. 그 후, 멀티스케일 feature는 FPN을 사용하여 융합되고 1$\times$1 convolution으로 집계된다. $256 \times \frac{h}{4} \times \frac{w}{4}$의 해상도로 생성된 feature map을 map decoder의 조건으로 사용한다. 이전 방법과 달리 DDP는 ConvNext와 Swin Transformer와 같은 최신 네트워크 아키텍처와 함께 작동할 수 있다.
Map Decoder
Map decoder $f_\theta$는 concatenation을 통해 noisy map $y_t$와 이미지 인코더의 feature map을 입력으로 사용하고 픽셀마다 분류 또는 회귀를 수행한다. 최신 perception 파이프라인의 일반적인 관행에 따라 map decoder로 deformable attention의 레이어 6개를 간단히 쌓는다. 파라미터 집약적인 U-Net을 사용하는 이전 연구들과 비교하여 본 논문의 map decoder는 가볍고 컴팩트하여 여러 step의 reverse process에서 공유 파라미터를 효율적으로 재사용할 수 있다.
3. Training
학습하는 동안 먼저 ground truth $y$에서 noise map $y_t$까지의 diffusion process를 구성한 다음 모델을 학습시켜 이 과정을 reverse시킨다. DDP에 대한 학습 절차는 Algorithm 1과 같다.

Label Encoding
표준 diffusion model은 연속 데이터를 가정하므로 연속 값이 있는 regression task (ex. 깊이 추정)에 편리한 선택이다. 그러나 기존 연구에 따르면 불연속 레이블(ex. semantic segmentation)에는 적합하지 않다. 따라서 다음과 같은 불연속 레이블에 대한 몇 가지 인코딩 전략을 탐색한다.
- 카테고리 레이블을 0과 1의 이진 벡터로 나타내는 one-hot 인코딩
- 먼저 정수를 비트 문자열로 변환한 다음 이를 실수로 변환하는 아날로그 비트 인코딩
- 정규화를 위 sigmoid 함수를 사용하여 학습 가능한 임베딩 레이어를 사용하여 불연속 레이블을 고차원 연속 space에 project하는 클래스 임베딩.
이러한 모든 전략에 대해 Algorithm 1과 같이 인코딩된 레이블의 범위를 정규화하고 확장한다. 특히 스케일링 계수 스케일은 신호 대 잡음비(SNR)를 제어하며 이는 diffusion model에 중요한 hyperparameter이다.
Map Corruption
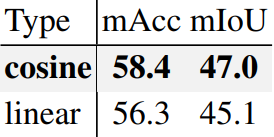
Gaussian noise를 추가하여 인코딩된 ground truth 정보를 손상시켜 noisy map $y_t$를 얻는다. Noise의 강도는 $\alpha_t$에 의해 제어되며, 이는 서로 다른 timestep $t \in [0, 1]$에서 $\alpha_t$에 대해 단조 감소하는 schedule을 채택한다. Cosine schedule과 linear schedule을 포함한 다양한 noise scheduling 전략을 비교한 결과 cosine schedule이 일반적으로 벤치마크 task에서 가장 잘 작동하였다고 한다.
Objective Function
표준 diffusion model은 dense prediction task에 적합한 $l_2$ loss로 학습되지만 task별 loss를 채택하는 것이 supervision (ex. semantic segmentation을 위한 cross entropy loss, 깊이 추정을 위한 sigloss)을 채택하는 것이 더 효과적이라고 한다.
4. Inference
테스트 이미지가 조건 입력으로 주어지면 모델은 가우시안 분포에서 샘플링된 랜덤 noisy map으로 시작하여 점진적으로 예측을 세분화한다. Algorithm 2의 inference 절차를 요약한다.

Sampling Rule
샘플링을 위해 DDIM 업데이트 규칙을 선택한다. 각 샘플링 step $t$에서 랜덤 noise $y_T$ 또는 마지막 step에서 예측된 noisy map $y_{t+1}$은 조건부 feature map과 융합되어 map 예측을 위해 map decoder $f_\theta$로 전송된다. 현재 step의 예측 결과를 얻은 후 reparameterization trick을 사용하여 다음 step에 대한 noisy map $y_t$를 계산한다. Inference step에서 비대칭 시간 간격(hyperparameter $td$에 의해 제어됨)을 사용하고 $td = 1$이 가장 잘 작동한다고 한다.
Sampling Drift
저자들은 몇 가지 샘플링 step에서 모델 성능이 향상되고 step 수가 증가함에 따라 약간 감소하는 것을 경험적으로 관찰하였다. 이러한 성능 저하는 sampling drift 문제에 기인할 수 있다. 이는 학습 분포와 샘플링 데이터 간의 불일치를 나타낸다. 학습하는 동안 모델은 noisy한 ground-truth를 reverse하도록 학습되는 반면, 테스트하는 동안 모델은 “불완전한” 예측에서 noise를 제거하기 위해 추론되며, 이는 근본적인 손상된 분포에서 멀어진다. 이 drift는 복합 오차로 인해 더 작은 timestep $t$로 뚜렷해지고 샘플이 ground-truth 분포에서 더 많이 벗어날 때 더욱 심해진다.
저자들은 가설을 검증하기 위해 마지막 5,000 iteration 학습에서 ground-truth 정보가 아닌 모델의 예측을 사용하여 $y_t$를 구성하였다. 이 접근 방식은 학습 타겟을 변환하여 자체 예측에 추가된 noise를 제거함으로써 학습 및 테스트의 데이터 분포를 일치시킨다. 이 접근 방식을 self-aligned denoising이라고 한다. 이 접근 방식은 성능 저하 대신 포화 상태를 생성하는 경향이 있다. 이 결과는 perception task에 diffusion process를 통합하면 이미지 생성에 비해 효율성을 향상시킬 수 있음을 시사한다. 즉, 제안된 DDP는 diffusion model의 이점을 유지하면서 효율성을 개선할 수 있다.
Multiple Inference
여러 step의 샘플링 절차 덕분에 본 논문의 방법은 예측 품질을 위해 컴퓨팅을 교환할 수 있는 유연성이 있는 dynamic inference를 지원한다. 게다가 자연스럽게 모델 예측의 신뢰성과 불확실성을 평가할 수 있다.
Experiment
1. Main Properties
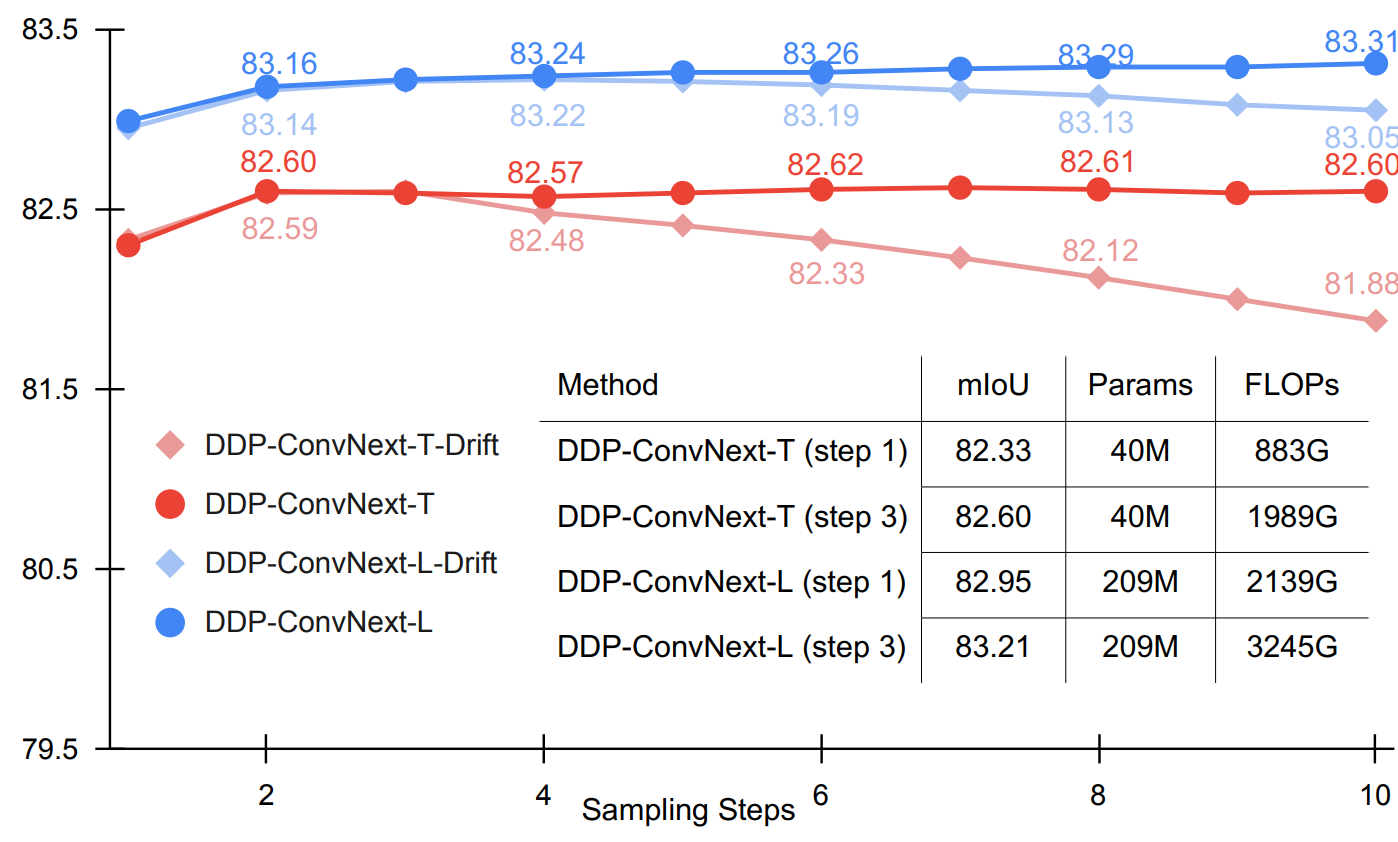
Dynamic Inference
다음은 Cityscapes 데이터셋에서 multiple inference의 결과를 나타낸 그래프이다.
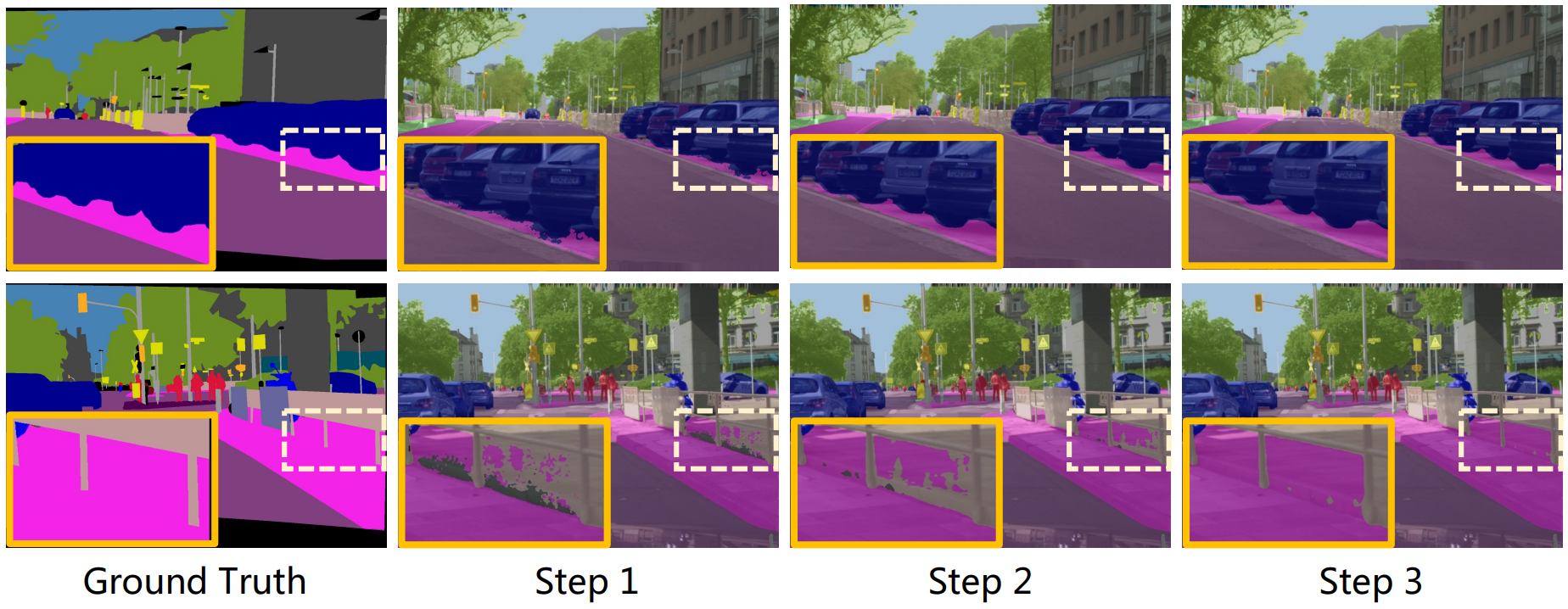
다음은 여러 timestep에서의 예측된 mask 결과이다.
Uncertainty Awareness
성능 향상 외에도 DDP는 자연스럽게 불확실성 추정치를 제공할 수 있다. 여러 step의 샘플링 프로세스에서 각 step의 예측 결과가 이전 step의 결과와 다른 픽셀을 간단히 셀 수 있으며 이 변경을 카운트한 map을 0-1로 정규화하고 uncertainty map을 얻는다. 이전 방법들은 Bayesian network와 같은 복잡한 모델링이 필요한 반면, DDP는 자연스럽고 쉽게 불확실성을 추정할 수 있다.
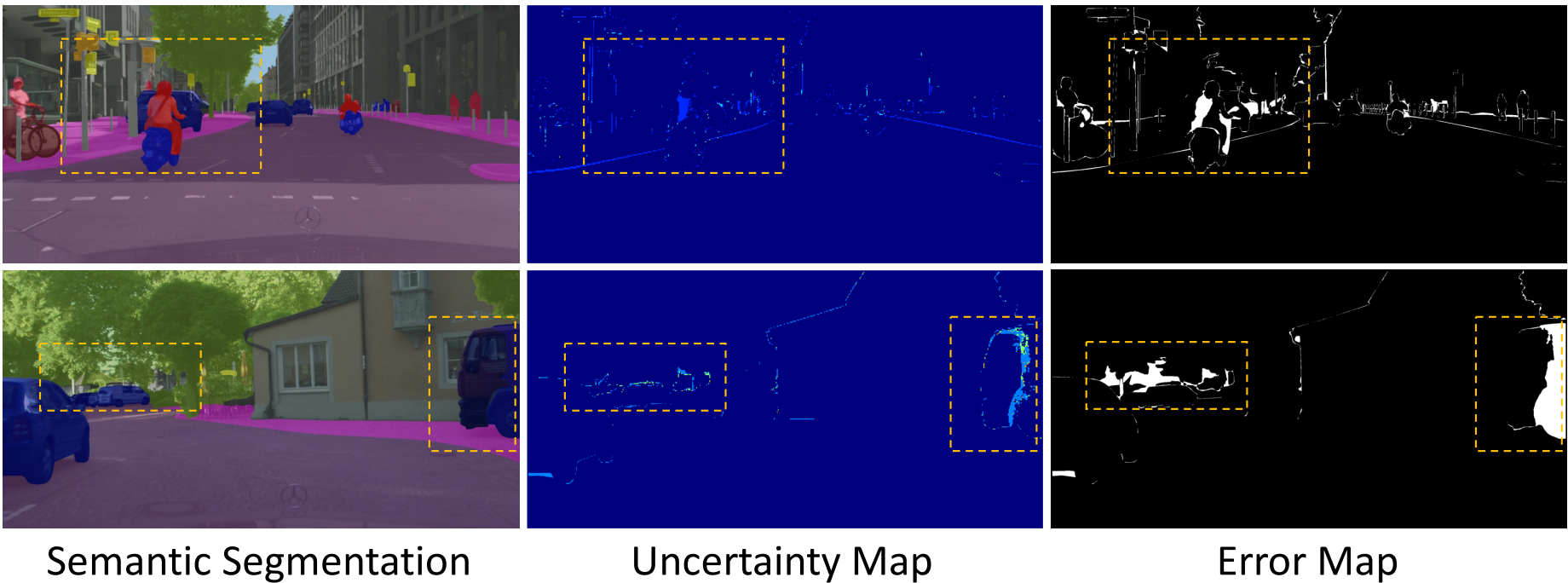
Uncertainty map의 응답이 높은 영역은 예상 불확실성이 높음을 나타내며 잘못 분류된 지점을 나타내는 error map의 흰색 영역과 높은 양의 상관관계가 있다.
2. Semantic Segmentation
- 데이터셋: ADE20K, Cityscapes
- Settings
- crop size: ADE20K는 512$\times$512, Cityscapes는 512$\times$1024
- optimizer: AdamW
- learning rate: $6 \times 10^{-5}$
- weight decay: 0.01
- iteration: 160,000
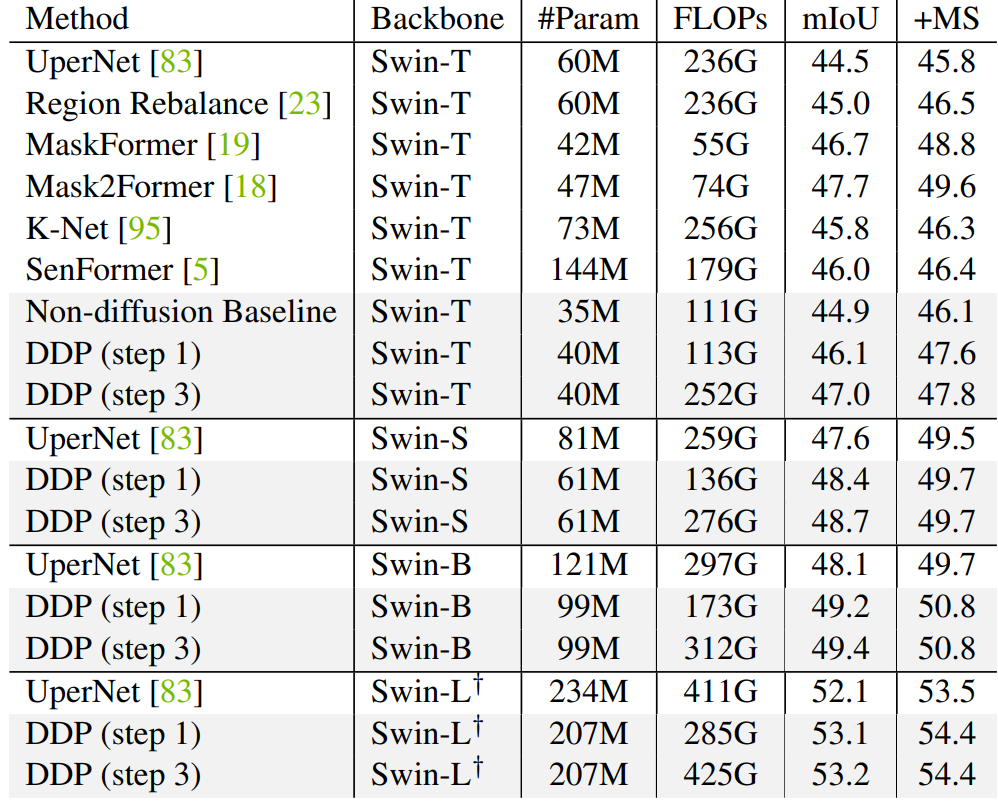
다음은 ADE20K validation set에서의 semantic segmentation 결과이다.
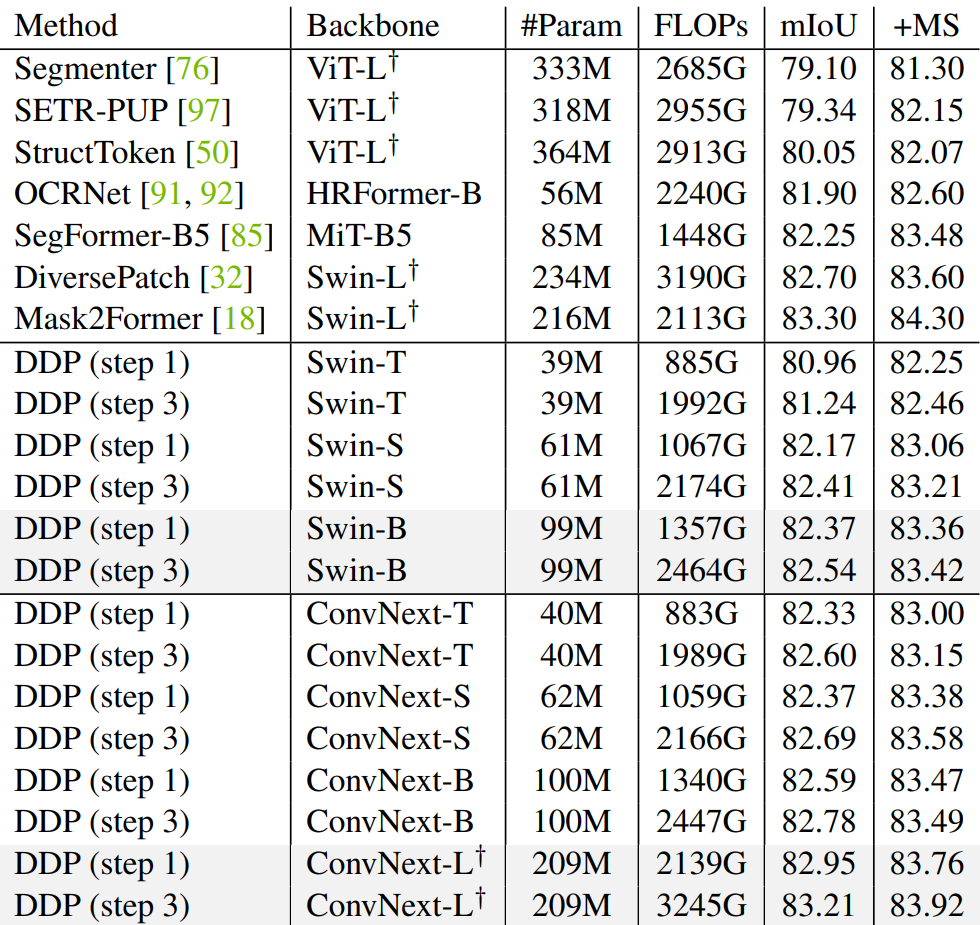
다음은 Cityscapes validation set에서의 semantic segmentation 결과이다.
3. BEV Map Segmentation
- 데이터셋: nuScenes
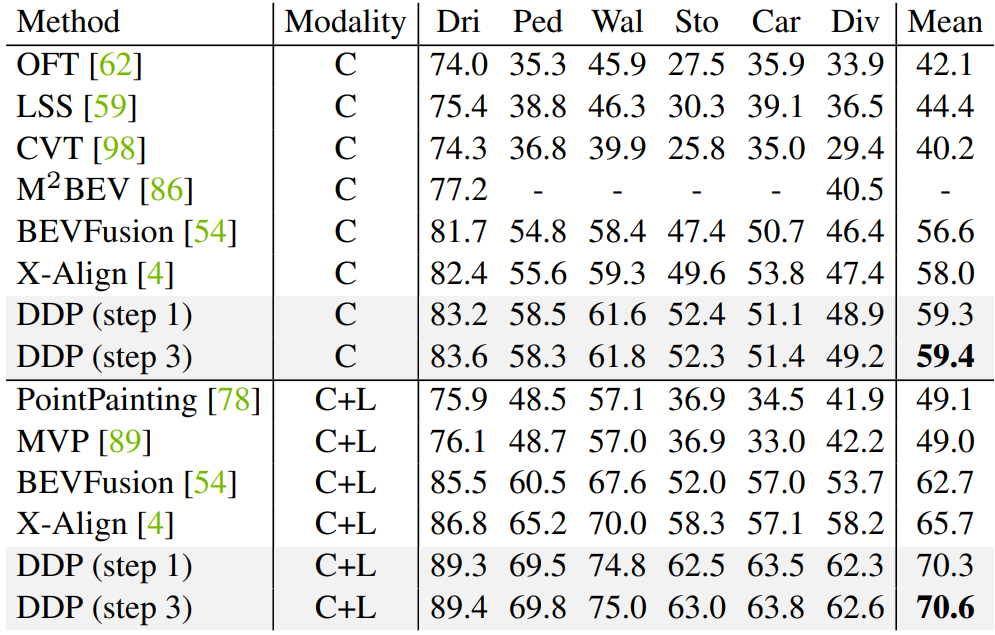
다음은 nuScenes validation set에서의 BEV map segmentation 결과이다.
4. Depth Estimation
- 데이터셋: KITTI, NYU-DepthV2, SUN RGB-D
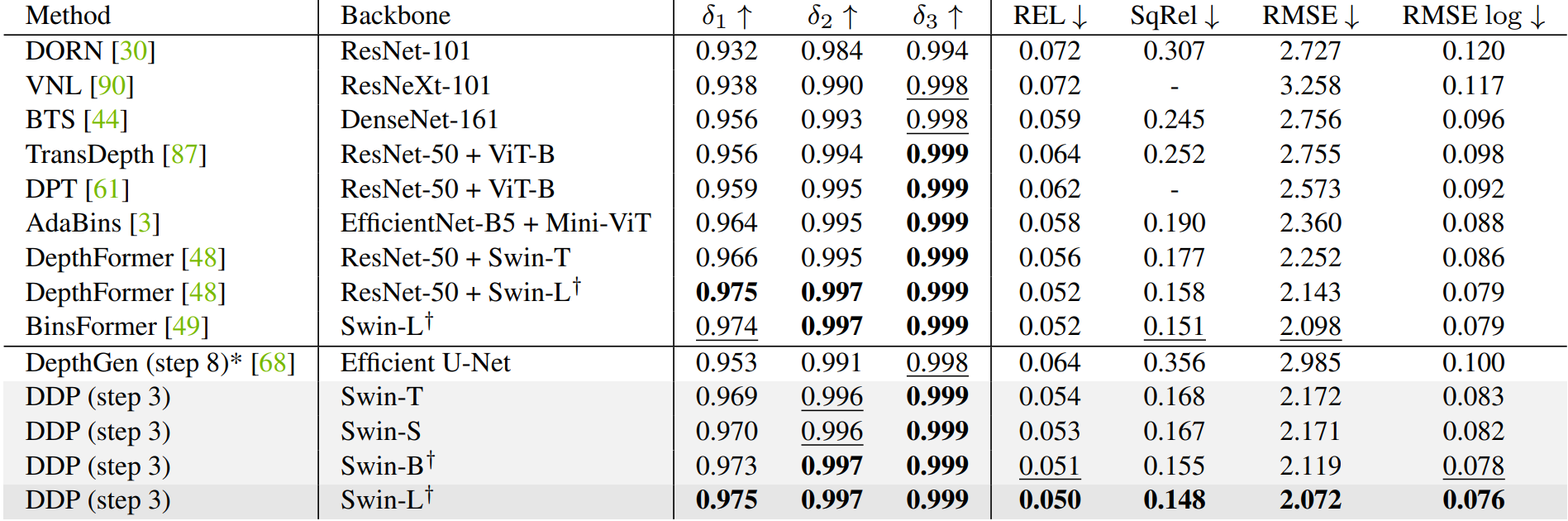
다음은 KITTI validation set에서의 깊이 추정 결과이다.
5. Ablation Study
다음은 레이블 인코딩 방법에 대한 ablation 실험 결과이다.

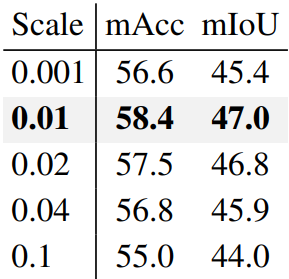
다음은 scaling factor에 대한 ablation 실험 결과이다.
다음은 noise schedule에 대한 ablation 실험 결과이다.
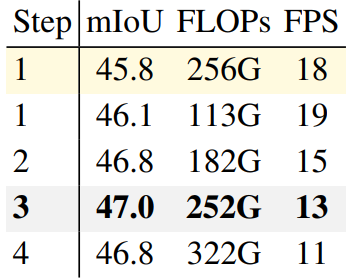
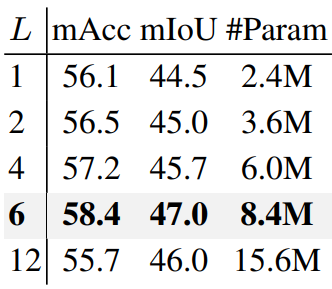
다음은 decoder 깊이 $L$에 대한 ablation 실험 결과이다.
다음은 정확도와 효율성 사이의 trade-off를 나타낸 ablation 실험 결과이다. (노란색은 K-Net)