[논문리뷰] Denoising Diffusion Implicit Models (DDIM)
ICLR 2021. [Paper] [Github]
Jiaming Song, Chenlin Meng, Stefano Ermon
Stanford University
6 Oct 2020
Introduction
DDPM과 같은 diffusion model이 GAN과 비슷할 정도로 성능이 굉장히 좋지만 샘플링이 Markov chain에 의한 진행되기 때문에 고품질의 이미지를 생성하기 위해서는 많은 iteration이 필요하다. GAN이 모델을 1번만 통과시켜도 좋은 결과가 나오는 것과 비교하면 DDPM은 1000번 모델을 통과시켜야 하기 때문에 상대적으로 느리다는 단점이 있다. 예를 들어, DDPM의 경우 Nvidia 2080 Ti GPU로 32x32 크기의 이미지 5만장을 생성하는 데 20시간이 걸리는 반면 BigGAN은 1분도 걸리지 않는다. 이미지의 크기가 커질수록 차이가 심해지며 같은 GPU로 256x256 크기의 이미지 5만장을 생성하는데 1000시간이 걸린다.
DDPM과 GAN 사이의 효율 차이를 줄이기 위해서 DDIM이 제안되었다. DDIM은 implicit probabilistic model로 DDPM과 연관이 깊다. 저자들은 Markovian인 DDPM의 forward diffusion process를 non-Markovian process로 일반화하며, 여전히 적합한 reverse Markov chain을 설계할 수 있다. 또한 DDPM을 학습시키는 데 사용한 목적 함수와 같은 목적 함수를 사용한다. 따라서 기존과 동일한 신경망을 사용하면서 diffusion process만 non-Markovian process로 하여 학습할 수 있기 때문에 많은 생성 모델에서 자유롭게 신경망을 선택할 수 있다. 특히, non-Markovian process를 사용하기 때문에 적은 수의 step으로 시뮬레이션할 수 있는 짧은 generative Markov chain을 사용할 수 있어 거의 품질 손실 없이 샘플링 효율을 크게 높일 수 있다.
DDPM과 비교하였을 떄 DDIM은 몇가지 경험적 이점이 있는데
- 샘플링을 10배에서 100배까지 가속화해도 DDPM보다 우수한 생성 품질을 갖는다.
- 동일한 초기 latent 변수로 시작하여 다양한 길이의 Markov chain으로 여러 샘플을 생성하면 샘플들이 높은 일관성을 가진다.
- DDPM은 이미지 space 근처에서 보간해야 하지만 DDIM은 일관성이 높아 초기 latent 변수를 조작하여 의미적으로 유의미한 보간이 가능하다.
Background - DDPM
(자세한 내용은 논문리뷰 참고)
데이터의 분포 $q(x_0)$가 주어질 때 모델 분포 $p_\theta (x_0)$가 $q(x_0)$를 근사하도록 학습한다.
\[\begin{equation} p_\theta (x_0) = \int p_\theta (x_{0:T}) dx_{1:T}, \quad \quad p_\theta (x_{0:T}) := p_\theta (x_T) \prod_{t=1}^T p_\theta^{(t)} (x_{t-1} | x_t) \end{equation}\]파라미터 $\theta$는 variational lower bound
\[\begin{equation} \max_{\theta} \mathbb{E}_{q(x_0)} [\log p_\theta (x_0)] \le \max_{\theta} \mathbb{E}_{q(x_0, x_1, \cdots, x_T)} [\log p_\theta (x_{0:T}) - \log q(x_{1:T} | x_0)] \end{equation}\]을 최대화시키는 방향으로 학습된다. $q(x_{1:T} \vert x_0)$는 잠재 변수에 대한 inference distribution이며, DDPM은 $q(x_{1:T} \vert x_0)$을 고정시키고 학습을 진행한다. 또한 감소 수열 $\alpha_{1:T} \in (0,1]^T$로 매개변수화된 Gaussian transition이 있는 다음의 Markov chain을 사용하였다.
\[\begin{equation} q (x_{1:T} | x_0) := \prod_{t=1}^T q (x_t | x_{t-1}), \quad q (x_t | x_{t-1}) := \mathcal{N} \bigg(\sqrt{\frac{\alpha_t}{\alpha_{t-1}}} x_{t-1}, \bigg( 1 - \frac{\alpha_t}{\alpha_{t-1}} \bigg) I \bigg) \end{equation}\](실제 DDPM 논문에서는 $\alpha_t$대신 $\bar{\alpha}_t$로 표기)
$q (x_t \vert x_{t-1})$를 forward process라 한다. 또한, $x_T$에서 $x_0$로 샘플링하는 Markov chain $p_\theta (x_{0:T})$를 generative process라 하며 이는 reverse process $q(x_{t-1} \vert x_t)$로 근사된다. Forward process에 대하여
\[\begin{equation} q (x_t | x_0) := \int q(x_{1:t} | x_0) dx_{1:(t-1)} = \mathcal{N} (x_t ; \sqrt{\alpha_t} x_0, (1-\alpha_t)I) \end{equation}\]가 성립하기 때문에 $x_t$를 $x_0$와 noise 변수 $\epsilon$의 선형 결합
\[\begin{equation} x_t = \sqrt{\alpha_t} x_0 + \sqrt{1-\alpha_t} \epsilon, \quad \epsilon \sim \mathcal{N} (\textbf{0}, I) \end{equation}\]으로 표현할 수 있다. $\alpha_T$을 0에 충분히 가깝게 설정하면 임의의 $x_0$에 대하여 $q (x_T \vert x_0)$는 표준 가우시안 분포로 수렴한다. 따라서 $p_\theta (x_T) := \mathcal{N} (\textbf{0},I)$로 설정하는 것은 자연스럽다. 모든 조건문이 학습 가능한 평균 함수와 고정된 분산을 갖는 가우시안으로 모델링되면 다음 식으로 단순화할 수 있다.
\[\begin{equation} L_\gamma (\epsilon_\theta) := \sum_{t=1}^T \gamma_t \mathbb{E}_{x_0 \sim q(x_0), \epsilon_t \sim \mathcal{N} (\textbf{0}, I)} \bigg[ \| \epsilon_\theta^{(t)} (\sqrt{\alpha_t} x_0 + \sqrt{1-\alpha_t} \epsilon_t) - \epsilon_t \|_2^2 \bigg], \quad \epsilon_\theta := \{\epsilon_\theta^{(t)}\}_{t=1}^T \end{equation}\]$\gamma := [\gamma_1, \cdots, \gamma_T]$는 $\alpha_{1:T}$에 의존하는 양의 계수이다. DDPM은 생성 성능을 최대화하기 위해 $\gamma = \textbf{1}$로 두었다.
Variational Inference for non-Markovain Forward Processes

생성 모델이 inference process의 역과정으로 근사되므로 생성 모델에 필요한 iteration의 수를 줄이기 위해 inference process를 다시 생각해야 한다. 여기서 중요하는 것은 DDPM 목적 함수 $L_\gamma$가 주변 분포 $q(x_t \vert x_0)$에만 의존하며 결합 분포 $q(x_{1:T}\vert x_0)$에는 직접적으로 의존하지 않는다는 것이다. 같은 주변 분포에 대해서 수 많은 결합 분포가 존재하기 때문에 non-Markovian인 새로운 inference process가 필요하며 이에 대응되는 새로운 generative process가 필요하다. 또한 이 non-Markovian inference process는 DDPM의 목적 함수와 같은 목점 함수를 가진다는 것을 보일 수 있다.
1. Non-Markovian forward processes
실수 벡터 $\sigma \in \mathbb{R} _{\ge 0}^T$에 대한 inference distribution $q_\sigma (x_{1:T} \vert x_0)$은 다음과 같다.
\[\begin{equation} q_\sigma (x_{1:T} | x_0) := q_\sigma (x_T | x_0) \prod_{t=2}^T q_\sigma (x_{t-1} | x_t, x_0) \\ \textrm{where} \quad q_\sigma (x_T | x_0) = \mathcal{N} (\sqrt{\alpha_t} x_0, (1-\alpha_t)I) \end{equation}\]모든 $t>1$에 대하여
\[\begin{equation} q_\sigma (x_{t-1} | x_t, x_0) = \mathcal{N} \bigg( \sqrt{\alpha_{t-1}} x_0 + \sqrt{1 - \alpha_{t-1} - \sigma_t^2} \cdot \frac{x_t - \sqrt{\alpha_t} x_0}{\sqrt{1-\alpha_t}}, \sigma_t^2 I \bigg) \end{equation}\]이다. 모든 $t$에 대하여 $q_\sigma (x_t \vert x_0) = \mathcal{N} (\sqrt{\alpha_t} x_0, (1-\alpha_t)I)$를 보장하기 위하여 평균 함수가 위와 같이 선택되었다. 따라서 평균 함수는 의도한대로 주변 분포와 일치하는 결합 분포를 정의한다.
베이즈 정리에 의해 forward process는
\[\begin{equation} q_\sigma (x_t | x_{t-1}, x_0) = \frac{q_\sigma (x_{t-1} | x_t, x_0) q_\sigma (x_t | x_0)}{q_\sigma (x_{t-1} | x_0)} \end{equation}\]이며 이 또한 가우시안 분포이다. 각각의 $x_t$가 $x_{t-1}$과 $x_0$ 모두에 의존하므로 DDIM의 forward process는 더 이상 Markovian이 아니다. $\sigma$의 크기로 얼마나 forward process가 확률적인지를 조절할 수 있으며 $\sigma \rightarrow 0$일 때 어떤 $t$에 대해 $x_0$와 $x_t$를 알면 고정된 $x_{t-1}$를 알 수 있는 극단적인 경우에 도달한다.
2. Generative Process and Unified Variational Inference Objective
다음으로 각 $p_\theta^{(t)} (x_{t-1} \vert x_t)$가 $q_\sigma (x_{t-1} \vert x_t, x_0)$에 대한 지식을 활용하는 학습 가능한 generative process $p_\theta (x_{0:T})$를 정의한다. $x_t$가 주어지면 먼저 대응되는 $x_0$을 예측하고 이를 이용하여 $q_\sigma (x_{t-1} \vert x_t, x_0)$로 $x_{t-1}$을 샘플링한다.
$x_0 \sim q(x_0)$와 $\epsilon_t \sim \mathcal{N} (\textbf{0},I)$에 대하여 $x_t$는 $x_t = \sqrt{\alpha_t} x_0 + \sqrt{1-\alpha_t} \epsilon_t$로 계산할 수 있다. 그 다음 모델 $\epsilon_\theta^{(t)} (x_t)$가 $x_0$에 대한 정보 없이 $x_t$로부터 $\epsilon_t$를 예측한다. 식을 다음과 같이 다시 세우면 주어진 $x_t$에 대한 $x_0$의 예측인 denoised observation을 예측할 수 있다.
\[\begin{equation} f_\theta^{(t)} (x_t) := \frac{1}{\sqrt{\alpha_t}} (x_t - \sqrt{1-\alpha_t} \epsilon_\theta^{(t)}) \end{equation}\]그런 다음 고정된 prior $p_\theta (x_T) = \mathcal{N} (\textbf{0}, I)$에 대한 generative process를 다음과 같이 정의할 수 있다.
\[\begin{equation} p_\theta^{(t)} (x_{t-1} | x_t) = \cases{\mathcal{N}(f_\theta^{(t)} (x_1), \sigma_1^2 I) & t = 1 \\ q_\sigma (x_{t-1} | x_t, f_\theta^{(t)} (x_t)) & t > 1} \end{equation}\]$q_\sigma (x_{t-1} \vert x_t, f_\theta^{(t)} (x_t))$는 위에서 정의한 $q_\sigma (x_{t-1} \vert x_t, x_0)$ 식에 $x_0$ 대신 $f_\theta^{(t)} (x_t)$를 대입하여 정의할 수 있다. Generative process가 모든 $t$에서 성립하도록 $t = 1$인 경우에 약간의 Gaussian noise를 추가한다.
파라미터 $\theta$는 다음 목적 함수로 최적화된다.
\[\begin{aligned} J_\sigma (\epsilon_\theta) & := \mathbb{E}_{x_{0:T} \sim q_\sigma (x_{0:T})} [\log q_\sigma (x_{1:T} | x_0) - \log p_\theta (x_{0:T})] \\ &= \mathbb{E}_{x_{0:T} \sim q_\sigma (x_{0:T})} \bigg[ \log \bigg( q_\sigma (x_T | x_0) \prod_{t=2}^T q_\sigma (x_{t-1} | x_t, x_0) \bigg) - \log \bigg( p_\theta (x_T) \prod_{t=1}^T p_\theta^{(t)} (x_{t-1} | x_t) \bigg) \bigg] \\ &= \mathbb{E}_{x_{0:T} \sim q_\sigma (x_{0:T})} \bigg[ \log q_\sigma (x_T | x_0) + \sum_{t=2}^T \log q_\sigma (x_{t-1} | x_t, x_0) - \sum_{t=1}^T \log p_\theta^{(t)} (x_{t-1} | x_t) - \log p_\theta (x_T) \bigg] \end{aligned}\]$J_\sigma$의 정의를 보면 $\sigma$에 따라 목적 함수가 다르기 때문에 다른 모델이 필요하다는 것을 알 수 있다.
한편, 다음이 성립한다.
증명)
$$ \begin{aligned} J_\sigma (\epsilon_\theta) & \equiv \mathbb{E}_{x_{0:T} \sim q_\sigma (x_{0:T})} \bigg[ \log q_\sigma (x_T | x_0) + \sum_{t=2}^T \log q_\sigma (x_{t-1} | x_t, x_0) - \sum_{t=1}^T \log p_\theta^{(t)} (x_{t-1} | x_t) \bigg] \\ & \equiv \mathbb{E}_{x_{0:T} \sim q_\sigma (x_{0:T})} \bigg[ \sum_{t=2}^T \log \frac{q_\sigma (x_{t-1} | x_t, x_0)}{p_\theta^{(t)} (x_{t-1} | x_t)} - \log p_\theta^{(1)} (x_0 | x_1) \bigg] \\ &= \mathbb{E}_{x_{0:T} \sim q_\sigma (x_{0:T})} \bigg[ \sum_{t=2}^T D_{KL} (q_\sigma (x_{t-1} | x_t, x_0) || p_\theta^{(t)} (x_{t-1} | x_t)) - \log p_\theta^{(1)} (x_0 | x_1) \bigg] \\ \end{aligned} $$ $\equiv$는 "$\epsilon_\theta$에 독립적인 값과 같음"을 나타낸다. $t>1$일 때, $$ \begin{aligned} & \mathbb{E}_{x_0, x_t \sim q_\sigma (x_0, x_t)} [D_{KL} (q_\sigma (x_{t-1} | x_t, x_0) || p_\theta^{(t)} (x_{t-1} | x_t))] \\ &= \mathbb{E}_{x_0, x_t \sim q_\sigma (x_0, x_t)} [D_{KL} (q_\sigma (x_{t-1} | x_t, x_0) || q_\sigma (x_{t-1} | x_t, f_\theta^{(t)}(x_t)))] \\ & \equiv \mathbb{E}_{x_0, x_t \sim q_\sigma (x_0, x_t)} \bigg[ \frac{\| x_0 - f_\theta^{(t)} (x_t) \|_2^2}{2\sigma_t^2} \bigg] \\ &= \mathbb{E}_{x_0 \sim q(x_0), \epsilon \sim \mathcal{N}(\textbf{0},I), x_t=\sqrt{\alpha_t}x_0 + \sqrt{1-\alpha_t} \epsilon} \bigg[ \frac{ \bigg\| \frac{x_t - \sqrt{1-\alpha_t}\epsilon}{\sqrt{\alpha_t}} - \frac{x_t - \sqrt{1-\alpha_t} \epsilon_\theta^{(t)}(x_t)}{\sqrt{\alpha_t}} \bigg\|_2^2}{2\sigma_t^2} \bigg] \\ &= \mathbb{E}_{x_0 \sim q(x_0), \epsilon \sim \mathcal{N}(\textbf{0},I), x_t=\sqrt{\alpha_t}x_0 + \sqrt{1-\alpha_t} \epsilon} \bigg[ \frac{ \| \epsilon - \epsilon_\theta^{(t)} (x_t) \|_2^2}{2d \sigma_t^2 \alpha_t} \bigg] \\ \end{aligned} $$ $d$는 $x_0$의 차원이다. $t = 1$일 때, $$ \begin{aligned} & \mathbb{E}_{x_0, x_1 \sim q_\sigma (x_0, x_1)} \bigg[ -\log p_\theta^{(1)} (x_0 | x_1) \bigg] \equiv \mathbb{E}_{x_0, x_1 \sim q_\sigma (x_0, x_1)} \bigg[ \frac{\| x_0 - f_\theta^{(1)} (x_1) \|_2^2}{2\sigma_1^2} \bigg] \\ = \; & \mathbb{E}_{x_0 \sim q(x_0), \epsilon \sim \mathcal{N}(\textbf{0},I), x_1=\sqrt{\alpha_1}x_0 + \sqrt{1-\alpha_1} \epsilon} \bigg[ \frac{ \| \epsilon - \epsilon_\theta^{(1)} (x_1) \|_2^2}{2d \sigma_1^2 \alpha_1} \bigg] \\ \end{aligned} $$ 따라서, 모든 $t \in \{1,\cdots,T\}$에 대하여 $\gamma_t = 1/(2d \sigma_t^2 \alpha_t)$이면, 모든 $\epsilon_\theta$에 대하여 $$ \begin{equation} J_\sigma (\epsilon_\theta) \equiv \sum_{t=1}^T \frac{1}{2d \sigma_t^2 \alpha_t} \mathbb{E} \bigg[ \| \epsilon_\theta^{(t)} (x_t) - \epsilon_t \|_2^2 \bigg] = L_\gamma (\epsilon_\theta) \end{equation} $$ 이다. "$\equiv$"의 정의에 따라 $J_\sigma = L_\gamma + C$이다.
Variational objective $L_\gamma$의 특별한 점은 $\epsilon_\theta^{(t)}$가 다른 $t$에서 공유되지 않는 경우 $\epsilon_\theta^{(t)}$에 대한 최적해가 가중치 $\gamma$에 의존하지 않는다는 것이다. 이러한 성질은 두 가지 의미를 갖는다.
- DDPM의 variational lower bound에 대한 목적 함수로 $L_\textbf{1}$을 사용하는 것이 가능하다.
- $J_\sigma$가 일부 $L_\gamma$와 같이 때문에 $J_\sigma$의 최적해는 $L_\textbf{1}$의 해와 동일하다.
Sampling from Generalized Generative Processes
Markovian process를 위한 generative process뿐만 아니라 non-Markovian process를 위한 generative process도 $L_\textbf{1}$로 학습할 수 있다. 따라서 pre-trained DDPM을 새로운 목적 함수에 대한 해로 사용할 수 있으며 $\sigma$를 변경하여 필요에 따라 샘플을 더 잘 생성하는 generative process를 찾는 데 집중할 수 있다.
1. Denoising Diffusion Implicit Models
다음 식으로 $x_t$로부터 $x_{t-1}$를 생성할 수 있다.
\[\begin{aligned} x_{t-1} = \sqrt{\alpha_{t-1}} \underbrace{\bigg( \frac{x_t - \sqrt{1-\alpha_t} \epsilon_\theta^{(t)} (x_t)}{\sqrt{\alpha_t}} \bigg)}_{\textrm{predicted } x_0} + \underbrace{\sqrt{1-\alpha_{t-1} - \sigma_t^2} \cdot \epsilon_\theta^{(t)} (x_t)}_{\textrm{direction pointing to } x_t} + \underbrace{\sigma_t \epsilon_t}_{\textrm{random noise}} \end{aligned}\]$\epsilon_t \sim \mathcal{N} (0, I)$는 $x_t$에 독립적인 가우시안 noise이며, $\alpha_0 := 1$로 정의한다. $\sigma$를 변경하면 같은 모델 $\epsilon_\theta$를 사용하여도 generative process가 달라지기 때문에 모델을 다시 학습하지 않아도 된다. 모든 $t$에 대하여
\[\begin{equation} \sigma_t = \sqrt{\frac{1-\alpha_{t-1}}{1-\alpha_t}} \sqrt{1 - \frac{\alpha_t}{\alpha_{t-1}}} \end{equation}\]로 두면 forward process가 Markovian이 되며 generative process가 DDPM이 된다.
모든 $t$에 대하여 $\sigma_t = 0$으로 두면, 주어진 $x_{t-1}$와 $x_0$에 대하여 forward process가 deterministic해진다. 이 경우 $x_T$부터 $x_0$까지 모두 고정되어 샘플링되기 때문에 모델이 implicit probabilistic model이 된다. 이를 DDPM 목적 함수로 학습된 implicit probabilistic model이기 때문에 Denoising Diffusion Implicit Model (DDIM)이라 부른다.
2. Accelerated generation processes
DDPM의 경우 forward process가 $T$ step으로 고정되어 있기 때문에 generative process도 $T$ step으로 강제된다. 반면 $L_\textbf{1}$은 $q_\sigma (x_t \vert x_0)$가 고정되어 있는 한 특정 forward 방식에 의존하지 않으므로 $T$보다 작은 길이의 forward process들도 고려할 수 있다.
Forward process를 $x_{1:T}$로 정의하지 않고 부분 집합 \(\{ x_{\tau_1}, \cdots, x_{\tau_S} \}\)로 정의하는 방법을 생각해 볼 수 있다. 여기서 $\tau$는 길이가 $S$인 $[ 1,\cdots,T ]$의 부분 수열이다. 특히 $q(x_{\tau_i}) = \mathcal{N} (\sqrt{\alpha_{\tau_i}} x_0 , (1-\alpha_{\tau_i})I)$가 주변 분포에 일치하도록 $x_{\tau_1}, \cdots, x_{\tau_S}$에 대한 forward process 정의한다. 그러면 generative process는 $\tau$를 뒤집어 샘플링하며 이를 샘플링 궤적(trajectory)이라 한다. 샘플링 궤적의 길이가 $T$보다 많이 짧다면 샘플링 과정의 계산 효율이 상당히 증가한다.
3. Relevance to Neural ODEs
DDIM 샘플링 식($\sigma_t = 0$)을 다음과 같이 다시 쓸 수 있으며, 상미분방정식(ODE)을 풀기 위한 Euler intergration과 비슷해진다.
\[\begin{aligned} x_{t-\Delta t} &= \sqrt{\alpha_{t-\Delta t}} \bigg( \frac{x_t - \sqrt{1-\alpha_t} \epsilon_\theta^{(t)} (x_t)}{\sqrt{\alpha_t}} \bigg) + \sqrt{1-\alpha_{t-\Delta t}} \cdot \epsilon_\theta^{(t)} (x_t) \\ &= \frac{\sqrt{\alpha_{t-\Delta t}}}{\sqrt{\alpha_t}} x_t + \sqrt{\alpha_{t-\Delta t}} \bigg( \sqrt{\frac{1 - \alpha_{t-\Delta t}}{\alpha_{t-\Delta t}}} - \sqrt{\frac{1-\alpha_t}{\alpha_t}} \bigg) \cdot \epsilon_\theta^{(t)} (x_t) \\ \frac{x_{t-\Delta t}}{\sqrt{\alpha_{t-\Delta t}}} &= \frac{x_t}{\sqrt{\alpha_t}} + \bigg( \sqrt{\frac{1 - \alpha_{t-\Delta t}}{\alpha_{t-\Delta t}}} - \sqrt{\frac{1-\alpha_t}{\alpha_t}} \bigg) \epsilon_\theta^{(t)} (x_t) \end{aligned}\]$\sqrt{(1-\alpha) / \alpha} = \sigma$, $x / \sqrt{\alpha} = \bar{x}$로 치환하면 ODE를 구할 수 있다.
\[\begin{equation} \bar{x}_{t-\Delta t} = \bar{x}_t + ( \sigma_{t-\Delta t} - \sigma_t ) \epsilon_\theta^{(t)} (x_t) \\ \bar{x}_t - \bar{x}_{t-\Delta t} = ( \sigma_t - \sigma_{t-\Delta t} ) \epsilon_\theta^{(t)} \bigg( \frac{\bar{x}_t}{\sqrt{1+\sigma_t^2}} \bigg) \\ \therefore d \bar{x} (t) = \epsilon_\theta^{(t)} \bigg( \frac{\bar{x} (t)}{\sqrt{\sigma^2 + 1}} \bigg) d \sigma (t) \end{equation}\]초기 조건은 $x(T) \sim \mathcal{N} (0, \sigma(T))$이다. 이를 통해 알 수 있는 것은 충분히 discretization steps을 거치면 ODE를 reverse해서 generation process의 reverse, 즉 encoding ($x_0 \rightarrow x_T$)도 가능하다는 것이다.
Experiments
- DDPM과 같은 모델을 같은 목적 함수로 $T = 1000$에 대하여 학습
- 학습 방법과 샘플링 방법만 다름
- $\tau$와 $\sigma$를 조절해가면 실험 진행
쉬운 비교를 위해 $\sigma$를 다음과 같이 정의
\[\begin{equation} \sigma_{\tau_i} (\eta) = \eta \sqrt{\frac{1-\alpha_{\tau_{i-1}}}{1-\alpha_{\tau_i}}} \sqrt{1 - \frac{\alpha_{\tau_i}}{\alpha_{\tau_{i-1}}}} \end{equation}\]$\eta = 0$이면 DDIM이고 $\eta = 1$이면 DDPM이다. 또한 표준편차가
\[\begin{equation} \hat{\sigma_{\tau_i}} = \sqrt{1 - \frac{\alpha_{\tau_i}}{\alpha_{\tau_{i-1}}}} \end{equation}\]인 DDPM에 대하여도 실험하였으며, 이는 random noise가 $\sigma(1)$보다 더 큰 표준편차를 갖는 경우이다.
1. Sample Quality and Efficiency
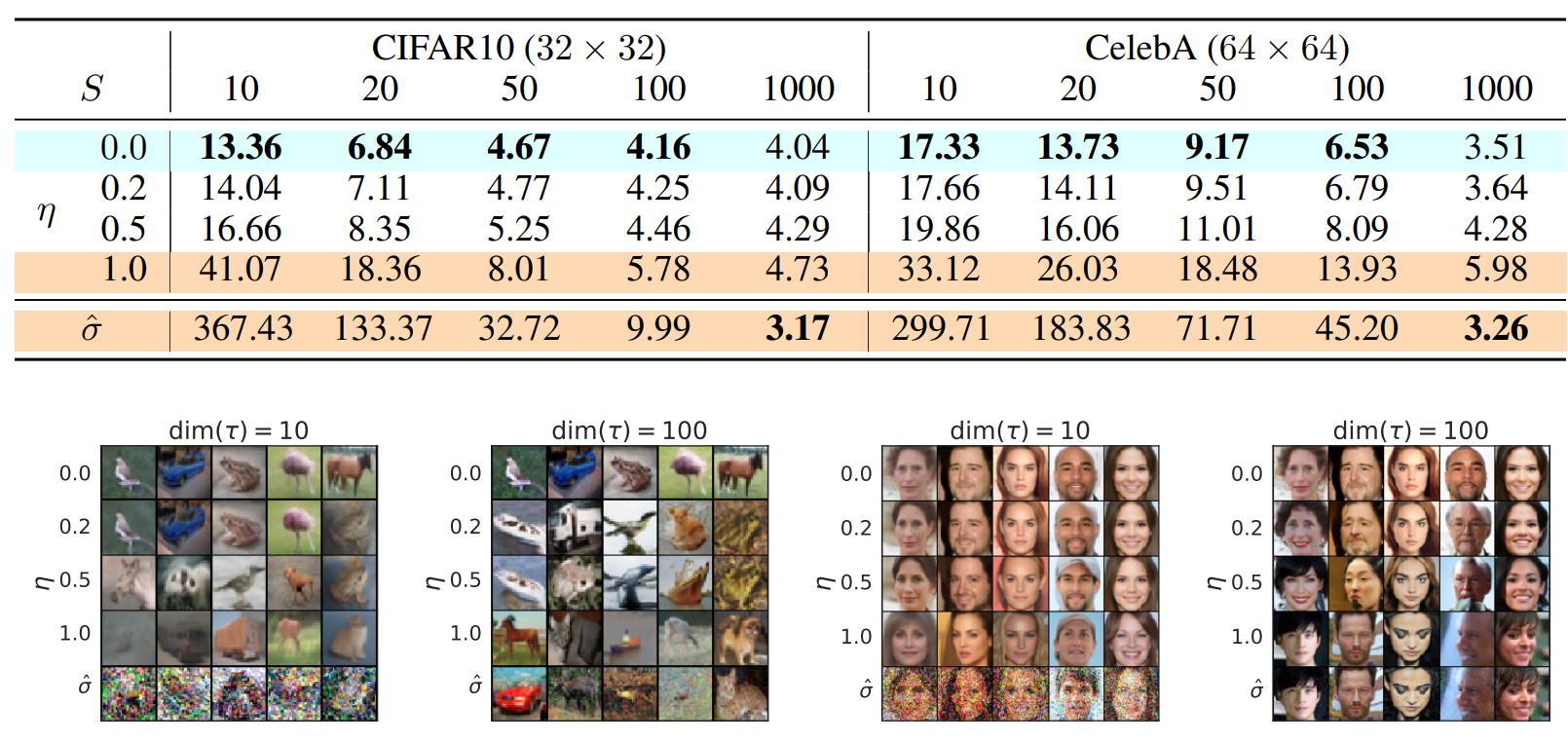
dim($\tau$)가 클수록 샘플의 품질이 좋아지지만 더 많은 계산이 필요하다. (trade-off)
샘플링 시간에 대한 비교는 다음과 같다.
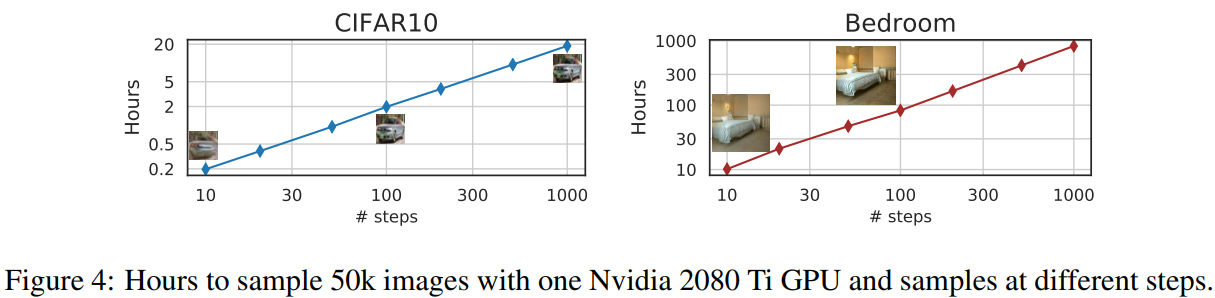
DDPM 대비 10~50배가 빨라졌다.
2. Sample Consistency in DDIMs
DDIM애서는 $x_0$가 초기 상태 $x_T$에만 의존하기 때문에 generative process가 deterministic하다.

Generative trajectory가 다르더라도 같은 $x_T$에 대하여 샘플의 결과가 거의 비슷하다. Generative trajectory가 길면 샘플의 품질이 더 좋지만 high-level feature에 큰 영향을 주지 않는다. 즉, $x_T$가 이미지의 latent encoding 역할을 한다고 생각할 수 있다.
3. Interpolation in Deterministic Generative Processes

DDPM은 stochastic하게 샘플링되기 때문에 interpolation이 불가능하지만 DDIM은 high-level feature가 $x_T$에 인코딩되기 때문에 interpolation이 가능하다.
4. Reconstruction from Latent Space

DDIM에서는 ODE로 Euler intergration하기 때문에 $x_0$를 $x_T$로 인코딩할 수 있으며, 다시 $x_0$로 복원할 수도 있다.