[논문리뷰] DDDM-VC: Decoupled Denoising Diffusion Models with Disentangled Representation and Prior Mixup for Verified Robust Voice Conversion
AAAI 2024. [Paper] [Page] [Github]
Ha-Yeong Choi, Sang-Hoon Lee, Seong-Whan Lee
Korea University
25 May 2023
Introduction
Diffusion model은 이미지 생성 task에서 상당한 성공을 거두었다. 또한 고품질 음성을 합성할 수 있는 능력으로 인해 최근 몇 년 동안 오디오 도메인에서 점점 더 많은 관심을 끌었다. TTS, neural vocoder, 음성 향상, 음성 변환 (VC)과 같은 다양한 애플리케이션에서 diffusion model을 사용한다.
Diffusion model은 강력한 생성 성능으로 인해 대부분의 음성 애플리케이션에서 성공을 거두었지만 기존 diffusion model에는 개선의 여지가 남아 있다. 데이터에 많은 속성이 포함되어 있기 때문에 모든 수준의 생성 프로세스에서 모델 파라미터를 공유하는 단일 denoiser로 각 속성에 대한 특정 스타일을 제어하기 어렵다. 이미지 생성 도메인에서 이러한 부담을 줄이기 위해 eDiff-i는 단일 denoiser를 특정 반복 step에 따라 점진적으로 단일 denoiser에서 비롯된 여러 특수 denoiser로 나눈다. 그러나 모든 반복에 대해 완전히 동일한 컨디셔닝 프레임워크 내에서 각 속성을 제어하는 데 여전히 제한이 존재하므로 제어 가능성이 부족하다.
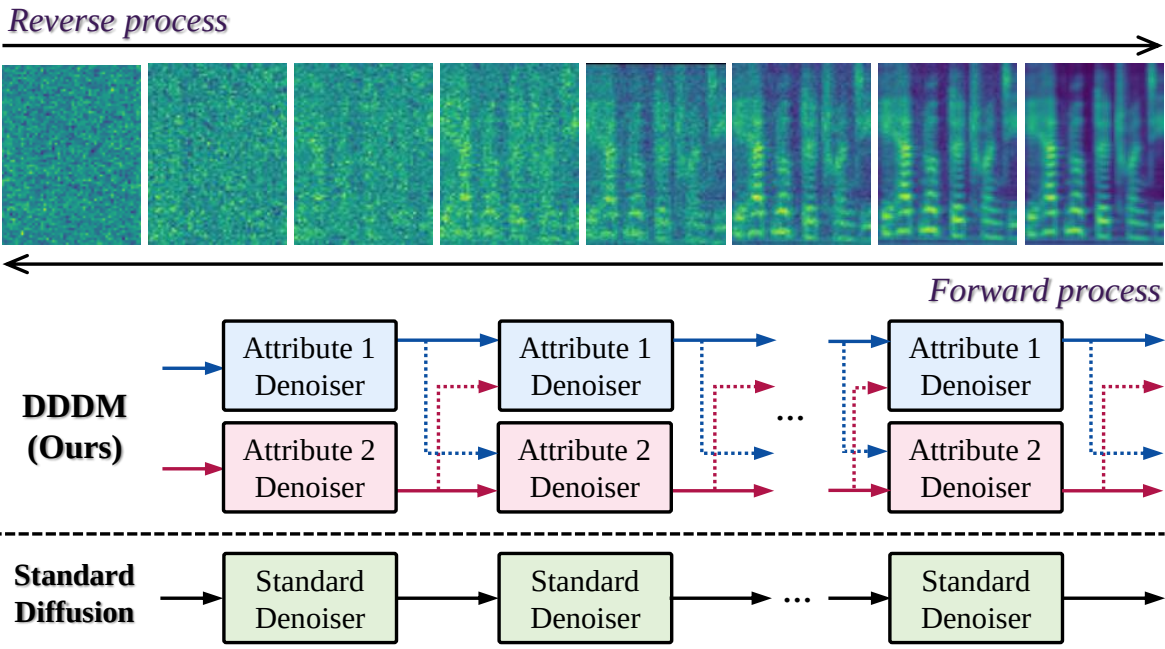
본 논문은 위의 문제를 해결하기 위해 먼저 분리된 표현을 사용한 decoupled denoising diffusion model (DDDM)을 제시한다. 위 그림에서 볼 수 있듯이 denoiser를 특정 속성 조건 denoiser로 분리하여 각 속성에 대한 모델 제어 가능성을 개선한다. 그 후 각 denoiser는 동일한 noise level에서 자체 특성의 noise에 초점을 맞추고 각 중간 timestep에서 noise를 제거한다. 본 논문은 DDDM의 효과를 입증하기 위해 각 음성 속성을 풀고 제어하는 데 여전히 어려움을 겪고 있는 VC task에 초점을 맞추었다. VC는 언어 정보를 유지하면서 음성 스타일을 전송하거나 제어하는 task이다. 음성은 언어 정보, 억양, 리듬, 음색과 같은 다양한 속성으로 구성되기 때문에 zero-shot 또는 few-shot 시나리오에서 음성 스타일을 전달하는 것은 여전히 어려운 일이다.
본 논문은 DDDM을 기반으로 속성별 음성 스타일을 효과적으로 전달하고 제어할 수 있는 DDDM-VC를 제시한다. 먼저 self-supervised 표현을 활용하여 소스 필터 이론을 기반으로 음성 표현을 분리한다. 그런 다음 DDDM을 사용하여 분리된 표현에서 각 속성에 대한 음성을 다시 합성한다. 또한 혼합 음성 표현에서 생성된 diffusion model에 대한 prior 분포로 변환된 음성을 사용하고 원본 음성을 복원하는 새로운 음성 style transfer 학습 시나리오인 prior mixup을 제안한다. 따라서 DDDM-VC는 소스 음성을 재구성하여 학습되지만 prior mixup은 VC task에 대한 학습-inference 불일치 문제를 줄일 수 있다.
Decoupled Denoising Diffusion Models
1. Background: Diffusion Models
Diffusion model은 일반적으로 랜덤 noise를 점진적으로 추가하는 forward process와 랜덤 noise를 점진적으로 제거하고 원래 샘플을 복원하는 reverse process로 구성된다.
Markov chain에 의한 이산 시간 diffusion process를 사용하는 기존 diffusion model과 달리 score 기반 생성 모델은 확률적 미분 방정식 (SDE) 기반 연속 시간 diffusion process를 사용한다. Forward process는 다음과 같이 정의된다.
\[\begin{equation} dx = f(x, t) dt + g(t) dw \end{equation}\]여기서 $f(\cdot, t)$는 $x(t)$의 drift coefficient, $g(t)$는 diffusion coefficient, $w$는 브라운 운동을 나타낸다. 역시간 SDE는 다음과 같이 표현할 수 있다.
\[\begin{equation} dx = [f(x, t) - g^2 (t) \nabla_x \log p_t (x)] dt + g(t) d \bar{W} \end{equation}\]여기서 $\bar{W}$는 뒤로 흐르는 시간에 대한 브라운 운동이고 $\nabla_x \log p_t (x)$는 score function을 나타낸다. $s_\theta (x, t) \approx \nabla_x \log p_t (x)$를 추정하기 위해 score 기반 diffusion model은 score matching 목적 함수로 학습된다.
\[\begin{equation} \theta^\ast = \underset{\theta}{\arg \min} \mathbb{E}_t \{ \lambda_t \mathbb{E}_{x_0} \mathbb{E}_{x_t \vert x_0} [\| s_\theta (x_t, t) - \nabla_{x_t} \log p_{t \vert 0} (x_t \vert x_0) \|_2^2 ] \} \end{equation}\]2. Disentangled Denoiser
본 논문은 생성 모델의 각 속성에 대한 스타일을 효과적으로 제어하기 위해 여러 개의 분리된 denoiser가 있는 decoupled denoising diffusion model (DDDM)을 제안한다. eDiff-I에서 diffusion model의 앙상블이 제시되었지만 이 방법에서는 특정 denoising step에서 하나의 denoiser만 사용된다. 대조적으로, 저자들은 하나의 denoising step에서 diffusion model의 분해를 조사하였다. 특히 특정 지점에서 둘 이상의 특성 denoiser가 사용된다. 단일 denoiser를 사용하는 일반적인 diffusion process와 달리 denoiser를 분리된 표현의 $N$개의 denoiser로 나눈다. DiffVC를 따라 데이터 기반 prior를 사용하며, 속성 $Z_n$의 분리된 표현을 각 속성 denoiser에 대한 prior로 사용한다. 따라서 forward process는 다음과 같이 표현할 수 있다.
\[\begin{equation} dX_{n, t} = \frac{1}{2} \beta_t (Z_n - X_{n,t}) dt + \sqrt{\beta_t} dW_t \\ \textrm{where} \quad n \in [1, N] \end{equation}\]$n$은 각 속성을 나타내며, $N$은 총 속성 수이다. $\beta_t$는 noise의 양을 조절하고 $W_t$는 순방향 브라운 운동이다. 각 속성의 주어진 forward SDE에 대해 역방향 궤적이 존재한다. 각 분리된 denoiser의 reverse process는 다음과 같이 정의할 수 있다.
\[\begin{equation} d \hat{X}_{n,t} = \bigg( \frac{1}{2} (Z_n - \hat{X}_{n,t}) - \sum_{n=1}^N s_{\theta_n} (\hat{X}_{n,t}, Z_n, t) \bigg) \beta_t dt + \sqrt{\beta_t} d \bar{W}_t \\ \textrm{where} \quad t \in [0, 1] \end{equation}\]$s_{\theta_n}$은 $\theta_n$으로 parameterize된 각 속성 $n$의 score function을 나타내고 \(\bar{W}_t\)는 역방향 브라운 운동을 나타낸다. 각각의 prior 속성 $n$을 갖는 noisy한 샘플 $X_{n,t}$를 생성하는 forward process는 다음과 같다.
\[\begin{equation} p_{t \vert 0} (X_{n,t} \vert X_0) = \mathcal{N} (e^{- \frac{1}{2} \int_0^t \beta_s ds} X_0 + (1 - e^{- \frac{1}{2} \int_0^t \beta_s ds}) Z_n, (1 - e^{- \int_0^t \beta_s ds}) I) \end{equation}\]위 식의 분포는 가우시안이므로 다음 식을 유도할 수 있다.
\[\begin{equation} \nabla \log p_{t \vert 0} (X_{n,t} \vert X_0) = - \frac{X_{n,t} - X_0 (e^{- \frac{1}{2} \int_0^t \beta_s ds}) - Z_n (1 - e^{- \frac{1}{2} \int_0^t \beta_s ds})}{1 - e^{- \int_0^t \beta_s ds}} \end{equation}\]Reverse process는 다음 목적 함수를 사용하여 파라미터 $\theta_n$을 최적화하여 학습된다.
\[\begin{equation} \theta_n^\ast = \underset{\theta_n}{\arg \min} \int_0^1 \lambda_t \mathbb{E}_{X_0, X_{n,t}} \bigg\| \sum_{n=1}^N s_{\theta_n} (X_{n,t}, Z_n, s, t) - \nabla \log p_{t \vert 0} (X_{n,t} \vert X_0) \bigg\|_2^2 dt \\ \textrm{where} \quad \lambda_t = 1 - e^{- \int_0^t \beta_s ds} \end{equation}\]또한 ML-SDE solver를 사용하여 빠른 샘플링을 유도하며, reverse SDE solver로 forward diffusion의 log-likelihood를 최대화한다. DDDM을 DDDM-VC로 확장하여 각 속성에 대한 음성 스타일을 제어한다. 또한 사운드와 음성을 원하는 균형으로 혼합하기 위해 여러 denoiser를 활용하여 오디오 믹싱에 DDDM을 적용할 수 있다.
DDDM-VC
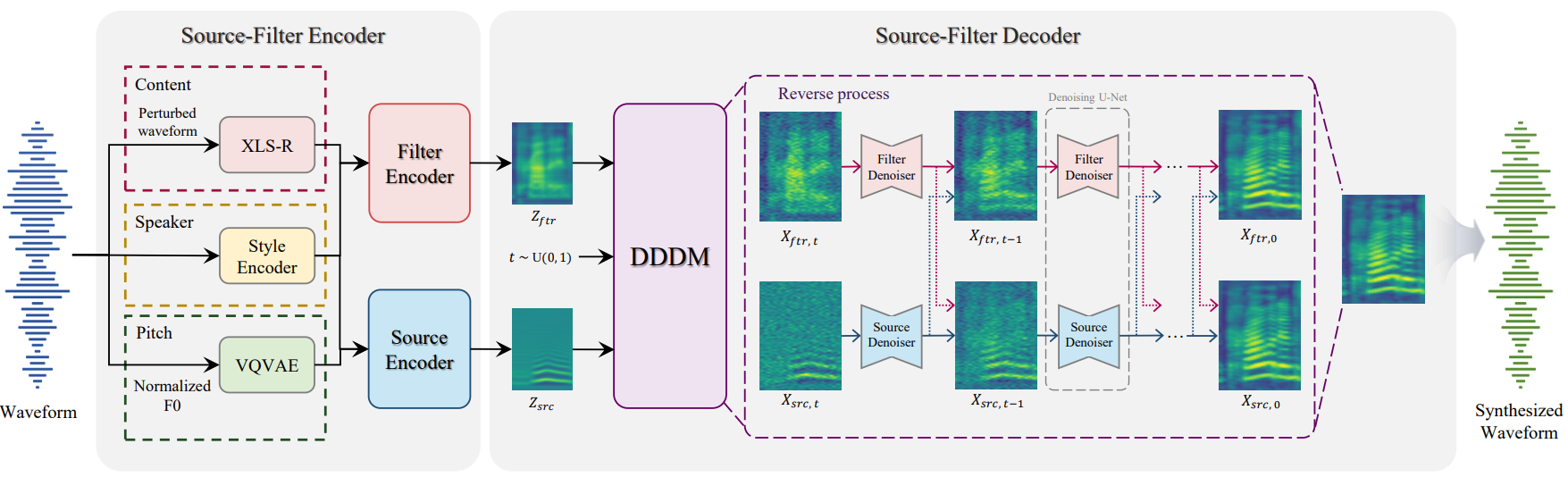
DDDM-VC는 위 그림과 같이 소스 필터 인코더와 소스 필터 디코더로 구성된다. 먼저 self-supervised 음성 표현을 사용하여 음성을 분리한다. 그 후, 이러한 분리된 음성 표현을 사용하여 각 속성을 제어하고 제안된 disentangled denoiser로 고품질 음성을 생성한다. 또한 강력한 음성 변환 시나리오를 위한 prior mixup을 제안한다.
1. Speech Disentanglement
Content Representation
음성 정보와 관련된 콘텐츠 표현을 추출하기 위해 self-supervised 음성 표현을 활용한다. HuBERT의 이산 오디오 표현을 활용하는 것과 달리 대규모 교차 언어 음성 데이터셋로 학습된 Wav2Vec 2.0인 XLS-R의 오디오 연속 표현을 사용한다. 또한 필터 인코더에 입력되기 전에 오디오가 섭동되어 콘텐츠에 독립적인 정보가 제거된다. XLS-R의 중간 레이어의 표현이 상당한 언어 정보를 포함하고 있기 때문에 이 표현을 콘텐츠 표현으로 채택한다.
Pitch Representation
YAPPT 알고리즘을 사용하여 오디오에서 기본 주파수 (F0)를 추출하여 화자와 무관한 말하기 스타일과 같은 억양을 인코딩한다. 각 샘플의 F0는 화자에 독립적인 피치 정보를 위해 각 화자에 대해 정규화되며 VQ-VAE는 vector-quantize된 pitch 표현을 추출하는 데 사용된다. 공정한 비교를 위해 inference하는 동안 화자가 아닌 각 문장에 대해 F0을 정규화한다.
Speaker Representation
VC는 음성 스타일을 전송하며 새로운 화자로부터 강력한 zero-shot 음성 스타일 전송을 달성하는 것이 목표이다. 이를 위해 타겟 음성의 mel-spectrogram에서 화자 표현을 추출할 수 있는 스타일 인코더를 사용한다. 추출된 화자 표현은 글로벌 화자 표현을 위해 문장당 평균화되고 화자 적응을 위해 모든 인코더와 디코더에 공급된다.
2. Speech Resynthesis
Source-filter Encoder
본 논문에서는 단순히 소스 필터 이론에 따라 음성 속성을 정의한다. 필터 인코더는 콘텐츠와 화자 표현을 취하는 반면 소스 인코더는 피치와 화자 표현을 취한다. PriorGrad 논문은 diffusion process에서 데이터 중심의 prior가 단순히 reverse process의 시작점을 가이드할 수 있음을 입증했다. 데이터 기반 prior를 사용한 음성 변환을 위해 평균 음소 레벨의 mel encoder를 채택하는 경우, 음소 레벨의 평균 mel-spectrogram과 사전 학습된 평균 mel-encoder를 추출하기 위해 텍스트 전사가 필요하며 평활화된 mel 표현은 잘못된 발음을 초래한다. 훨씬 더 상세한 prior를 위해 다음과 같이 타겟 mel-spectrogram $X_\textrm{mel}$에 의해 정규화되는 완전히 재구성된 소스 및 필터 mel-spectrogram $Z_\textrm{src}$와 $Z_\textrm{ftr}$를 사용한다.
\[\begin{equation} \mathcal{L}_\textrm{rec} = \| X_\textrm{mel} - (Z_\textrm{src} + Z_\textrm{ftr}) \|_1 \\ Z_\textrm{src} = E_\textrm{src} (\textrm{pitch}, s) \\ Z_\textrm{ftr} = E_\textrm{ftr} (\textrm{content}, s) \end{equation}\]분리된 표현의 소스 및 필터 mel-spectrogram은 단순히 다른 화자 표현으로 변환된다는 점은 주목할 가치가 있다. 따라서 변환된 소스 및 필터 mel-spectrogram을 VC를 위한 각 denoiser에서 prior로 활용한다.
Source-filter Decoder
DDDM을 기반으로 소스 및 필터 표현을 위해 분리된 denoiser를 활용한다. 소스 디코더는 소스 표현 $Z_\textrm{src}$를 prior로 취하고 필터 디코더는 필터 표현 $Z_\textrm{ftr}$을 prior로 취한다. 그 후, 각 denoiser는 동일한 noise로 각 prior에서 타겟 mel-spectrogram을 생성하도록 학습되며, 화자 표현으로 컨디셔닝된다. 각 denoiser는 자체 속성에서 하나의 noise를 제거하는 데 집중할 수 있다. Forward process는 다음과 같이 표현된다.
\[\begin{equation} dX_{\textrm{src}, t} = \frac{1}{2} \beta_t (Z_\textrm{src} - X_{\textrm{src}, t}) dt = \sqrt{\beta_t} dW_t \\ dX_{\textrm{ftr}, t} = \frac{1}{2} \beta_t (Z_\textrm{ftr} - X_{\textrm{ftr}, t}) dt = \sqrt{\beta_t} dW_t \end{equation}\]여기서 $X_{\textrm{src}, t}$와 $X_{\textrm{ftr}, t}$는 각각의 prior 속성을 가진 생성된 noise 샘플이다. 각 속성의 주어진 forward SDE에 대해 역방향 궤적이 존재한다. Reverse process는 다음과 같이 표현된다.
\[\begin{equation} d \hat{X}_{\textrm{src}, t} = \bigg( \frac{1}{2} (Z_\textrm{src} - \hat{X}_{\textrm{src}, t}) - s_{\theta_\textrm{src}} (\hat{X}_{\textrm{src}, t}, Z_\textrm{src}, s, t) - s_{\theta_\textrm{ftr}} (\hat{X}_{\textrm{ftr}, t}, Z_\textrm{ftr}, s, t) \bigg) \beta_t dt + \sqrt{\beta_t} d \bar{W}_t \\ d \hat{X}_{\textrm{ftr}, t} = \bigg( \frac{1}{2} (Z_\textrm{ftr} - \hat{X}_{\textrm{ftr}, t}) - s_{\theta_\textrm{ftr}} (\hat{X}_{\textrm{ftr}, t}, Z_\textrm{ftr}, s, t) - s_{\theta_\textrm{ftr}} (\hat{X}_{\textrm{src}, t}, Z_\textrm{src}, s, t) \bigg) \beta_t dt + \sqrt{\beta_t} d \bar{W}_t \end{equation}\]여기서 \(s_{\theta_\textrm{src}}\)와 \(s_{\theta_\textrm{ftr}}\)은 각각 $\theta_\textrm{src}$와 $\theta_\textrm{ftr}$로 parameterize된 score function을 나타낸다.
3. Prior Mixup
Self-supervised 표현과 diffusion process를 통해 음성을 여러 속성으로 분리하고 고품질로 재합성할 수 있지만, 재구성과 diffusion process 모두에서 입력 음성을 타겟 음성으로 재구성하거나 사용하여 모델을 학습하며, 이는 학습-inference 불일치 문제를 유발한다. 병렬이 아닌 음성 변환 시나리오에서는 변환된 음성의 ground-truth 정보가 존재하지 않는다. 따라서 모델은 소스 음성을 재구성해야만 학습된다. 그러나 VC에 대해 다른 음성 스타일로 소스 음성을 변환함에 따라 학습 시나리오에서도 재구성에서 변환으로 초점이 이동한다.
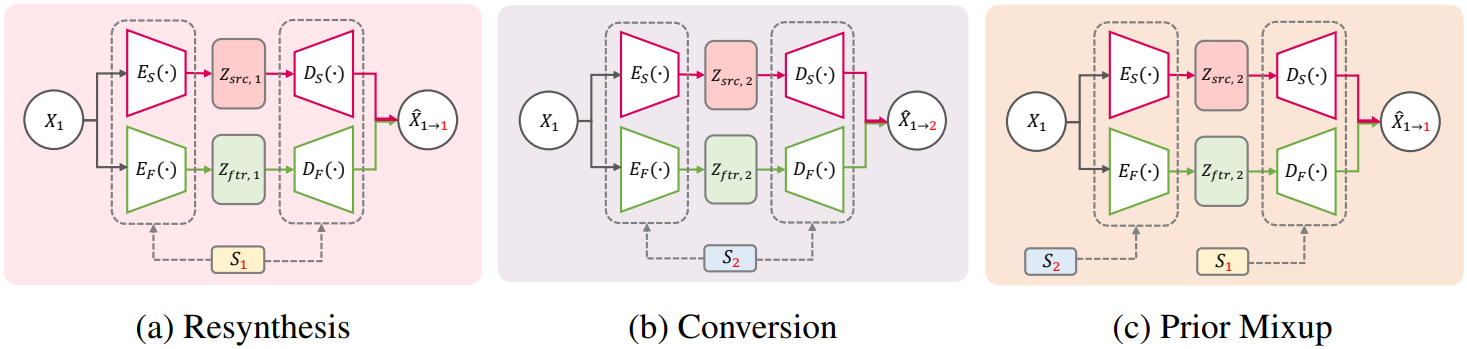
본 논문은 이를 위해 위 그림과 같이 prior 분포로 재구성된 표현 대신 무작위로 변환된 표현을 사용하는 prior mixup을 diffusion process에서 사용할 것을 제안한다. 구체적으로 소스 필터 인코더는 분리된 표현에서 음성의 소스와 필터를 재구성하도록 학습될 수 있기 때문에 변환된 소스와 필터는 다음과 같이 무작위로 선택된 화자 스타일 $s_r$로 얻을 수 있다.
이어서 무작위로 변환된 소스 및 필터 $Z_{\textrm{src}, r}$와 $Z_{\textrm{ftr}, r}$은 다음과 같이 각 denoiser에 대한 prior로 사용된다.
\[\begin{equation} dX_{\textrm{src}, t} = \frac{1}{2} \beta_t (Z_{\textrm{src}, r} - X_{\textrm{src}, t}) dt + \sqrt{\beta_t} dW_t \\ dX_{\textrm{ftr}, t} = \frac{1}{2} \beta_t (Z_{\textrm{ftr}, r} - X_{\textrm{ftr}, t}) dt + \sqrt{\beta_t} dW_t \end{equation}\]각 속성의 주어진 forward SDE에 대한 reverse process는 다음과 같이 표현된다.
\[\begin{equation} d \hat{X}_{\textrm{src}, t} = \bigg( \frac{1}{2} (Z_{\textrm{src}, r} - \hat{X}_{\textrm{src}, t}) - s_{\theta_\textrm{src}} (\hat{X}_{\textrm{src}, t}, Z_{\textrm{src}, r}, s, t) - s_{\theta_\textrm{ftr}} (\hat{X}_{\textrm{ftr}, t}, Z_{\textrm{ftr}, r}, s, t) \bigg) \beta_t dt + \sqrt{\beta_t} d \bar{W}_t \\ d \hat{X}_{\textrm{ftr}, t} = \bigg( \frac{1}{2} (Z_{\textrm{ftr}, r} - \hat{X}_{\textrm{ftr}, t}) - s_{\theta_\textrm{ftr}} (\hat{X}_{\textrm{ftr}, t}, Z_{\textrm{ftr}, r}, s, t) - s_{\theta_\textrm{ftr}} (\hat{X}_{\textrm{src}, t}, Z_{\textrm{src}, r}, s, t) \bigg) \beta_t dt + \sqrt{\beta_t} d \bar{W}_t \end{equation}\]따라서 prior mixup은 소스 음성을 재구성할 때에도 변환된 음성을 소스 음성으로 변환하도록 모델을 학습하므로 학습-inference 불일치 문제를 완화할 수 있다. 또한, 소스 필터 인코더가 inference 중에 VC를 효과적으로 실행하지 못할 수 있는 경우 소스 필터 디코더에서 음성 스타일을 조정할 수 있다. 스타일 인코더, 소스-필터 인코더, 사전 학습된 XLS-R과 F0 VQ-VAE가 없는 디코더를 포함한 전체 모델은 end-to-end 방식으로 공동 학습된다.
Training Objectives
재구성 손실 \(\mathcal{L}_\textrm{rec}\)는 diffusion model의 데이터 기반 prior에 대한 인코더 출력을 조절하는 데 사용된다. 소스 속성과 필터 속성의 reverse SDE는 신경망 $\theta_\textrm{src}$와 $\theta_\textrm{ftr}$로 학습되어 $X_t$의 로그 밀도 기울기를 근사화한다. 각 속성 네트워크는 다음 목적 함수를 사용하여 parameterize된다.
\[\begin{equation} \theta^\ast = \underset{\theta}{\arg \min} \int_0^1 \lambda_t \mathbb{E}_{X_0, X_t} \| & (s_{\theta_\textrm{src}} (X_{\textrm{src}, t}, Z_{\textrm{src}, r}, s, t) + s_{\theta_\textrm{ftr}} (X_{\textrm{ftr}, t}, Z_{\textrm{ftr}, r}, s, t)) - \nabla p_{t \vert 0} (X_t \vert X_0) \|_2^2 dt \end{equation}\]따라서 diffusion loss는 다음과 같이 나타낼 수 있다.
\[\begin{equation} \mathcal{L}_\textrm{diff} = \mathbb{E}_{X_0, X_t} \lambda_t [ \| (s_{\theta_\textrm{src}} (X_{\textrm{src}, t}, Z_{\textrm{src}, r}, s, t) + s_{\theta_\textrm{ftr}} (X_{\textrm{ftr}, t}, Z_{\textrm{ftr}, r}, s, t)) - \nabla p_{t \vert 0} (X_t \vert X_0) \|_2^2 ] \end{equation}\]DDDM-VC의 최종 목적 함수는 다음과 같이 정의할 수 있다.
\[\begin{equation} \mathcal{L}_\textrm{total} = \mathcal{L}_\textrm{diff} + \lambda_\textrm{rec} \mathcal{L}_\textrm{rec} \end{equation}\]여기서 $\lambda_\textrm{rec}$를 1로 설정했다.
Experiment and Result
- 데이터셋: LibriTTS
- 전처리
- Kaiser-best 알고리즘을 사용하여 24kHz에서 16kHz로 오디오를 다운샘플링
- 다운샘플링한 오디오 파형을 XLS-R의 입력으로 사용하여 self-supervised 음성 표현을 추출
- 타겟 음성과 화자 인코더의 입력을 위해 80개의 bin을 가진 로그 스케일 mel-spectrogram을 사용
- mel-spectrogram은 hop size 320, window 크기 1280, 1280 포인트의 푸리에 변환으로 변환됨
- 학습
- optimizer: AdamW ($\beta_1$ = 0.8, $\beta_2$ = 0.99, weight decay = 0.01)
- learning rate: 초기에 $5 \times 10^{-5}$, decay $0.999^{1/8}$
- batch size = 64, epoch = 200
- prior mixup의 경우 동일한 배치에서 원본과 셔플된 표현 간에 이진 선택을 사용하여 화자 표현을 혼합
- zero-shot VC의 경우 모델을 fine-tuning하지 않음
- one-shot 화자 적응의 경우 learning rate $2 \times 10^{-5}$과 500 step으로 fine-tuning
- vocoder의 경우 HiFi-GAN V1을 generator로 사용하고 MS-STFTD를 discriminator로 사용
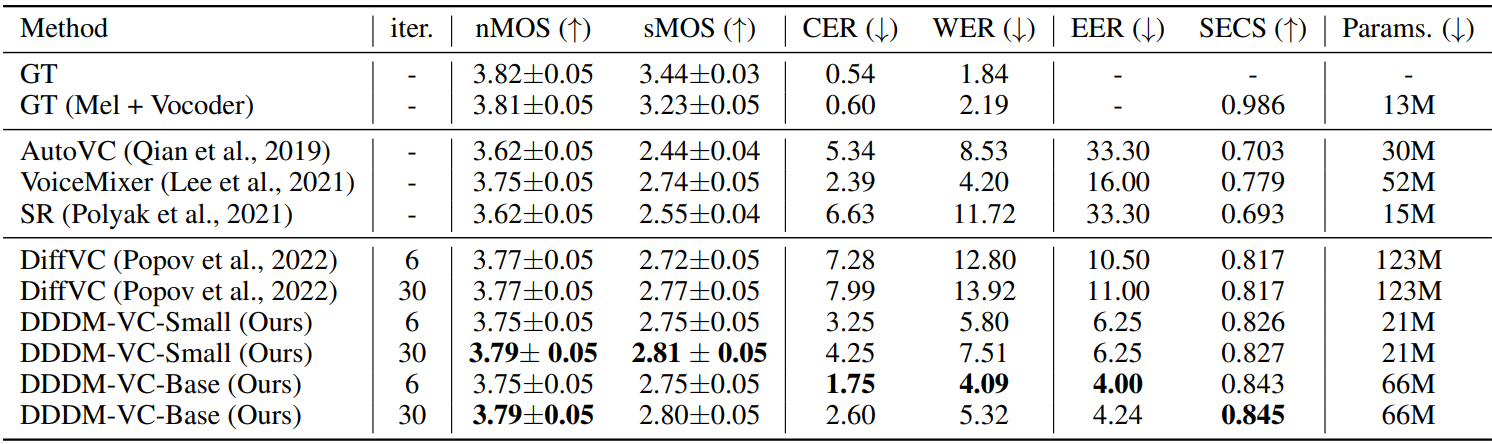
다음은 학습 중에 본 LibriTTS의 화자에 대한 다대다 VC 결과이다.
다음은 처음 보는 VCTK의 화자에 대한 zero-shot VC 결과이다. 또한 500 step동안 화자당 하나의 샘플로만 fine-tuning된 DDDM-VC 모델 (DDDM-VC-Fine-tuning)의 one-shot 화자 적응 결과를 추가로 포함한다.
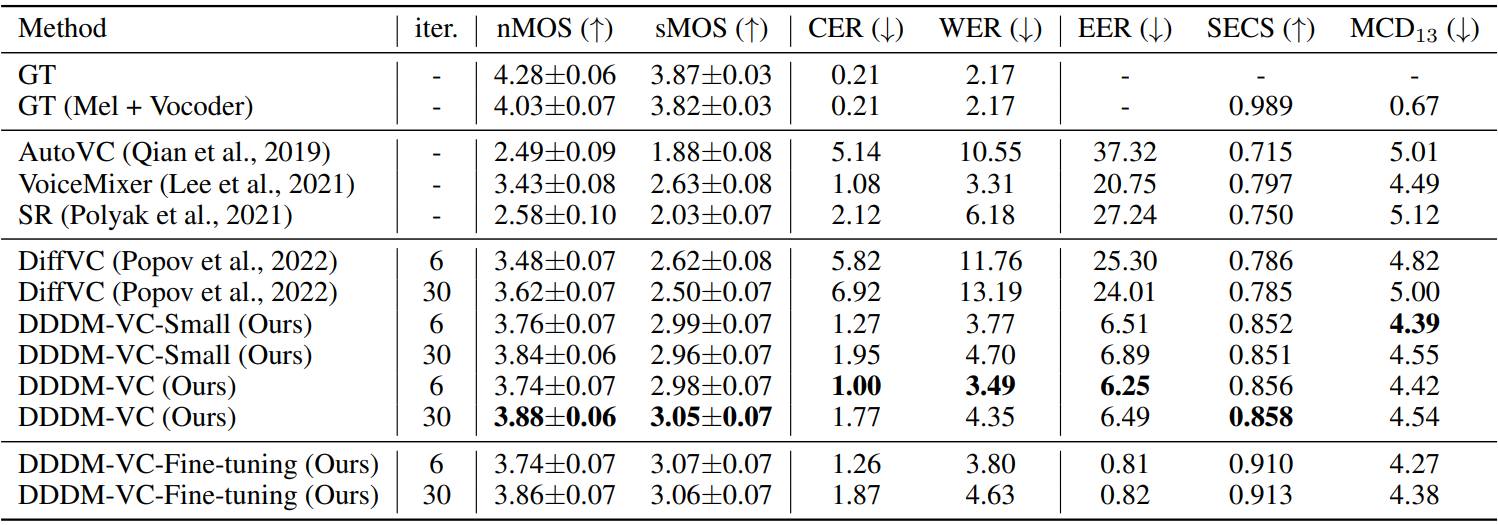
다음은 CSS10 다국어 데이터셋에서 처음 보는 언어에 대한 zero-shot 교차 언어 VC에 대한 CER (character error rate) 결과이다.
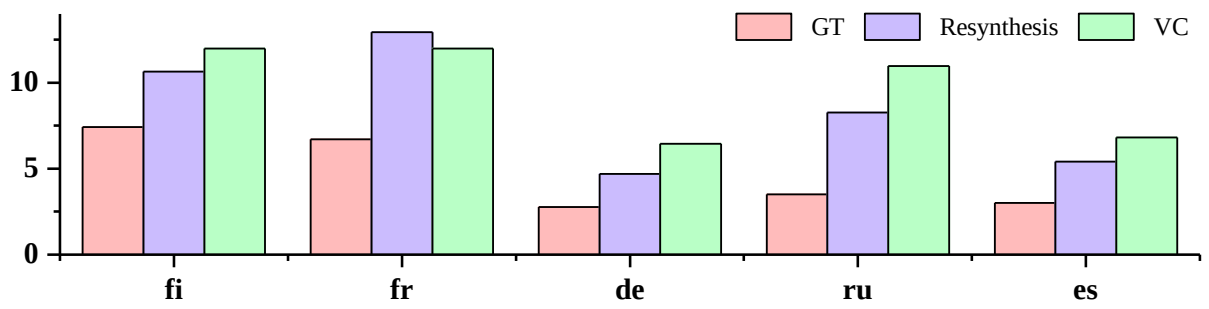
다음은 다대다 VC task에 대한 ablation study 결과이다. (LibriTTS)
