[논문리뷰] DC-AE 1.5: Accelerating Diffusion Model Convergence with Structured Latent Space
ICCV 2025. [Paper] [Github]
Junyu Chen, Dongyun Zou, Wenkun He, Junsong Chen, Enze Xie, Song Han, Han Cai
NVIDIA
1 Aug 2025
Introduction
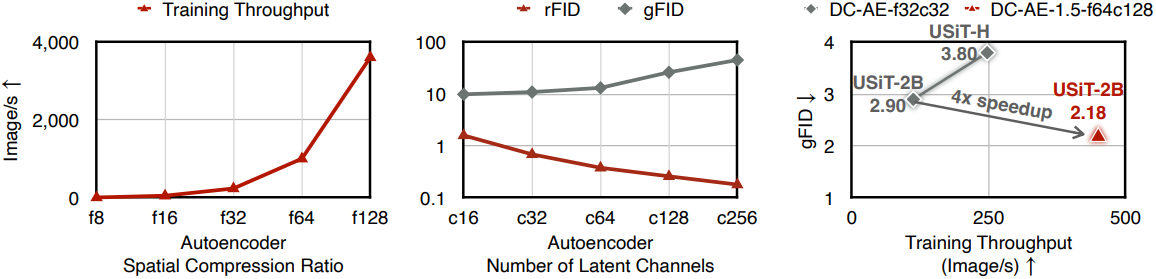
오토인코더 재구성의 품질을 개선하는 일반적인 방법은 latent 채널 수를 늘리는 것이다. 예를 들어, DiT-XL의 경우 latent 채널 수가 증가함에 따라 재구성 FID (rFID)가 지속적으로 향상되며, c16에서 c128로 전환하면 rFID가 1.60에서 0.26으로 감소한다.
Latent 채널 수 확장은 특히 Deep Compression Autoencoder (DC-AE)에서 매우 중요한데, 이는 오토인코더의 공간 압축률을 높여 latent diffusion model (LDM)을 가속화하기 때문이다. 높은 공간 압축률(ex. f64)에서 DC-AE는 만족스러운 복원 품질을 유지하기 위해 큰 latent 채널 수(ex. c128)를 사용해야 한다.
그러나 큰 latent 채널 수를 사용하면 diffusion model의 수렴 속도가 크게 느려져 생성 FID (gFID) 결과가 더 나빠진다. 이 문제는 LDM의 품질 상한선을 제한할 뿐만 아니라, 높은 공간 압축률(ex. f64)을 가진 오토인코더의 사용을 방해하여 효율성을 저하시킨다.
본 논문에서는 앞서 언급한 과제를 해결하기 위해 DC-AE 1.5를 제시하였다. 먼저 저자들은 다양한 latent 채널 수에서 오토인코더의 latent space를 분석하였다. Latent 채널 수가 많을 때 latent space에 sparsity 문제가 있음을 발견했다. 대부분의 latent 채널을 이미지 디테일 캡처에 할당하는 반면, object의 구조를 캡처하는 latent 채널은 전체 latent space에서 sparse해진다. 이 sparsity 문제로 인해 diffusion model이 object의 구조를 학습하기가 더 어려워져 수렴 속도가 느려진다. 따라서 latent 채널 수를 늘리면 이미지 디테일은 양호하게 유지되지만 object의 구조는 상당한 왜곡이 발생한다.
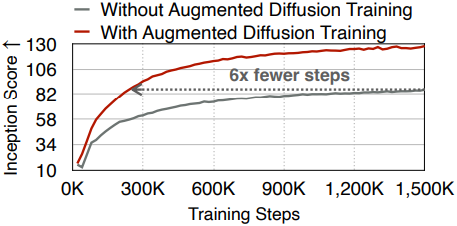
저자들은 sparsity 문제를 완화하기 위해 Structured Latent Space를 제안하였다. 이는 latent space에 특정 구조를 부여하는 학습 기반 접근법을 도입한다. 즉, 앞쪽 latent 채널은 object의 구조 캡처에 집중하고, 뒤쪽 latent 채널은 이미지 디테일 포착에 집중한다. 또한, 저자들은 structured latent space를 기반으로 느린 수렴 문제를 해결하기 위해 Augmented Diffusion Training을 제안하였다. 이는 object latent 채널에 추가적인 diffusion loss를 도입하여 object 구조 포착에 대한 diffusion model의 학습 속도를 높인다.
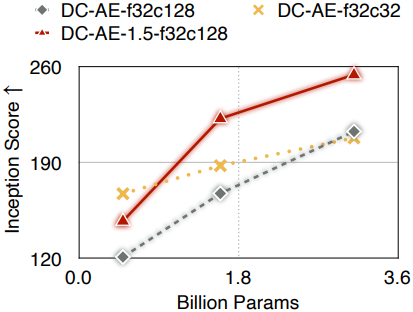
저자들은 이러한 기법을 통해 큰 latent 채널 수를 사용할 때 diffusion model의 수렴 속도를 크게 높여 더 나은 gFID 결과를 얻었다. 또한, 기존 오토인코더(ex. DC-AE-f32c32)보다 diffusion model scaling 결과가 더 우수했다.
Method
1. Analysis and Motivation

저자들은 DC-AE-f32의 latent space를 다양한 latent 채널 수를 사용하여 시각화하여, diffusion model이 큰 latent 채널 수를 사용할 때 수렴 속도가 느린 이유를 분석하였다. 위 그림은 latent space의 채널별 평균 feature를 시각화한 것이다.
Latent 채널 수를 c32에서 c256으로 증가시키면 object 구조에 대한 정보가 더 sparse해지는 것을 볼 수 있다. 이러한 현상은 f32c256 오토인코더가 이미지 디테일을 포착하기 위한 많은 latent 채널을 포함하고 있기 때문이다. 반면, object 구조 포착에는 소수의 latent 채널만 사용된다.

좋은 재구성 품질을 얻으려면 더 많은 이미지 디테일을 확보하는 것이 중요하므로 이는 타당하다. 그러나 모든 latent 채널을 동등하게 처리하기 때문에 diffusion model이 전체 object 구조와 고주파 디테일을 구분하기 어려워 object 구조를 효율적으로 학습할 수 없다. 예를 들어, 위 그림에서 볼 수 있듯이 latent 채널 수가 증가함에 따라 diffusion model이 구조적 일관성에 대한 제어력을 점차 잃는 것을 볼 수 있다. 반면, 이미지 디테일은 양호하게 유지된다.
이러한 결과를 바탕으로, 오토인코더의 latent space는 큰 latent 채널 수를 사용할 때 object 정보 sparsity 문제를 겪는 것으로 추측할 수 있다. 이러한 sparsity 문제로 인해 diffusion model은 object 구조를 효율적으로 학습할 수 없어 수렴 속도가 느려진다.
2. Structured Latent Space
위 분석에 기반하여, 본 논문에서는 Structured Latent Space를 도입하여 diffusion model이 object latent 채널과 디테일 latent 채널을 구분할 수 있도록 함으로써 latent space sparsity 문제를 해결하였다. Latent 채널 차원에 구조가 없는 기존 오토인코더와 달리, 본 논문에서는 latent space에 채널별 구조를 설계하고 추가하였다.

구체적으로, DC-AE 1.5는 부분 latent 채널로부터 이미지를 재구성하는 추가적인 기능을 제공한다. 예를 들어, 위 그림에서 볼 수 있듯이, 먼저 처음 16개 latent 채널로부터 object 구조를 재구성하는 데 집중하고, latent 채널이 더 많아질수록 이미지 디테일을 점진적으로 개선한다. 반면, 부분 latent 채널이 주어졌을 때, DC-AE는 object 구조를 잘 재구성할 수 없다.
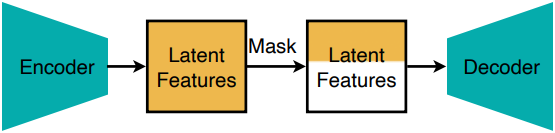
위 그림은 원하는 채널별 latent space 구조를 달성하기 위한 오토인코더 학습 전략을 보여준다. 직관적인 원리는 latent 채널 수가 적을 때 오토인코더의 latent space가 자연스럽게 object 구조에 더 집중한다는 사실에 기반한다. 따라서, 기존 오토인코더 학습 loss를 부분적인 latent 채널로부터 입력 이미지를 재구성하도록 수정했다.
구체적으로, 오토인코더는 입력 이미지 $x \in \mathbb{R}^{H \times W \times 3}$을 latent feature $z = E(x) \in \mathbb{R}^{\frac{H}{f} \times \frac{W}{f} \times c}$에 매핑하는 인코더 $E$와 latent feature에서 이미지 $y = D(z) \in \mathbb{R}^{H \times W \times 3}$을 예측하는 디코더 $D$로 구성된다. 오토인코더의 학습을 위해 loss $l(x, y) = l(x, D(z))$가 사용되는데, 이는 L1 loss, perceptual loss, GAN loss의 가중 평균이다.
본 논문의 디자인에서는 처음 몇 개의 채널만 선택되었을 때에도 오토인코더가 이미지를 재구성하도록 요구한다. 실제로는 각 학습 step에서 latent 채널 번호 $c^\prime < c$를 무작위로 샘플링하고 마스크를 생성하여 이를 구현한다.
\[\begin{equation} \textrm{mask}_{c, c^\prime} = (\underbrace{1, 1, \ldots, 1}_{c^\prime}, \underbrace{0, 0, \ldots, 0}_{c-c^\prime}) \end{equation}\]그런 다음, 수정된 loss $l(x, D(z \cdot \textrm{mask}_{c, c^\prime}))$을 사용하여 오토인코더를 업데이트한다.
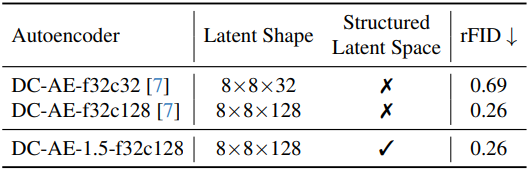
이 학습 전략을 통해 오토인코더는 임의의 latent 채널 번호 $c^\prime$에 대해 이미지를 재구성할 수 있는 능력을 얻게 되며, latent space는 자연스럽게 원하는 채널별 구조를 갖게 된다. 또한, 이 학습 전략은 오토인코더의 재구성 품질에 거의 영향을 미치지 않는다. 위 표는 DC-AE와 DC-AE 1.5의 rFID를 비교한 것이다. DC-AE 1.5는 동일한 설정에서 추가적인 latent space 구조를 가지면서도 DC-AE와 동일한 rFID를 달성하였다.
3. Augmented Diffusion Training
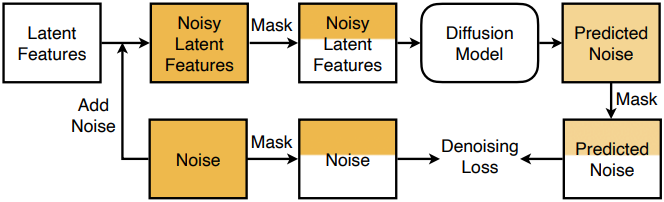
Structured latent space가 주어졌을 때, 다음 단계는 이 구조를 활용하여 object 구조에 대한 diffusion model의 학습 효율을 높이고 수렴성을 높이는 것이다. 위 그림에서 볼 수 있듯이, Augmented Diffusion Training을 통해 이를 달성한다. 핵심 아이디어는 object latent 채널에 대한 loss를 통해 diffusion 학습을 명시적으로 augmentation하는 것이다.
예를 들어, noise 예측 loss에 의해 학습되는 LDM \(\epsilon_\theta\)를 고려해 보자. Latent feature $x_0$와 이에 대응하는 noisy latent feature \(x_t = \alpha_t x_0 + \beta_t \epsilon\)이 주어지면, denoising loss는 다음과 같이 정의된다.
\[\begin{equation} \| \epsilon - \epsilon_\theta (x_t, t) \|^2 \end{equation}\]각 diffusion 학습 step에서 latent 채널 번호 $c^\prime$을 무작위로 샘플링하고 마스크 \(\textrm{mask}_{c, c^\prime}\)을 활용하여 diffusion loss를 수정한다.
\[\begin{equation} \| \epsilon \cdot \textrm{mask}_{c, c^\prime} - \epsilon_\theta (x_t \cdot \textrm{mask}_{c, c^\prime}, t) \cdot \textrm{mask}_{c, c^\prime} \|^2 \end{equation}\]Experiments
1. Main Results
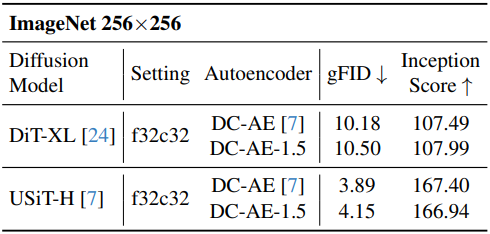
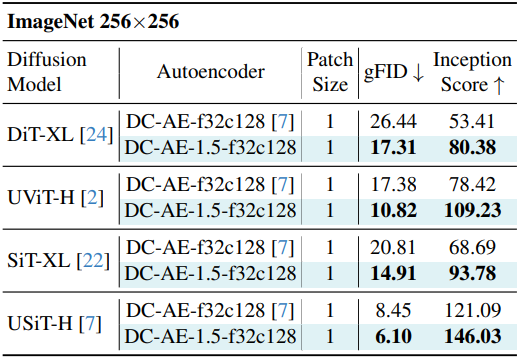
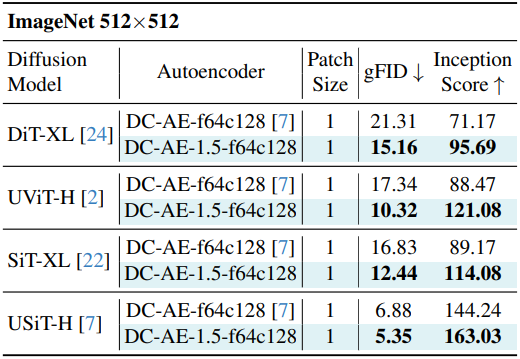
다음은 ImageNet에서의 이미지 생성 품질을 DC-AE와 비교한 결과이다.
다음은 DC-AE와 scaling curve를 비교한 것이다.
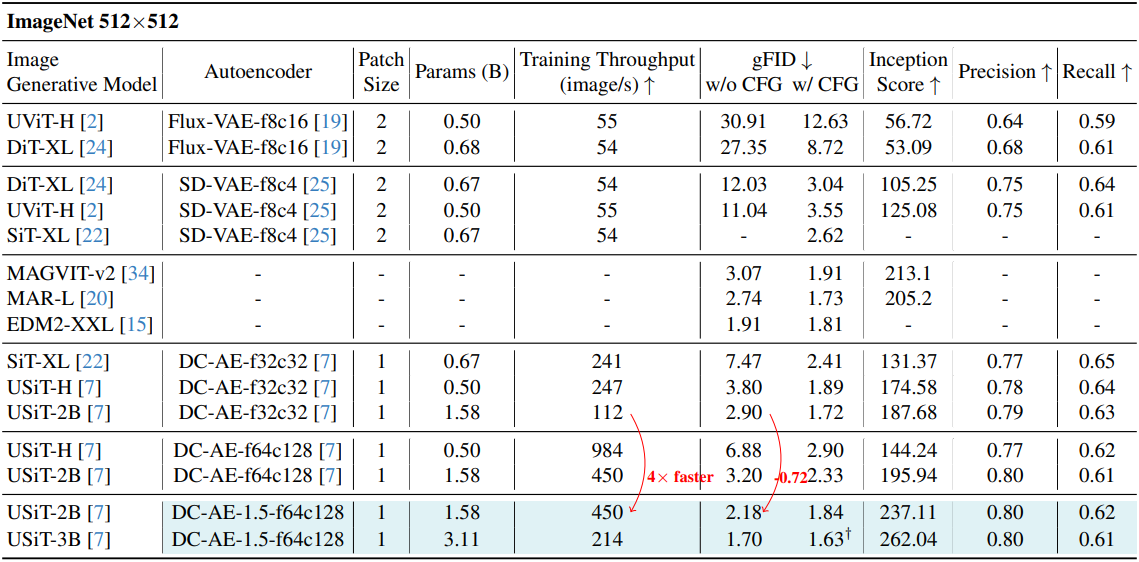
다음은 SOTA 이미지 생성 모델들과 클래스 조건부 이미지 생성 결과를 비교한 것이다.
2. Ablation Study
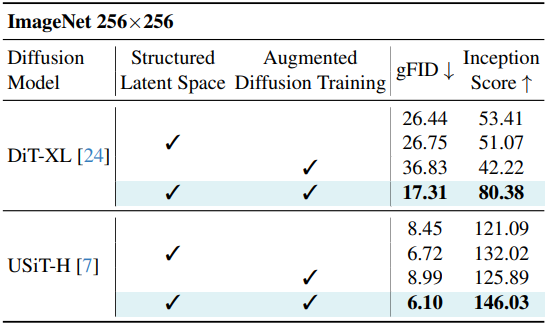
다음은 ablation study 결과이다.
다음은 적은 수의 latent 채널에 대하여 DC-AE와 비교한 결과이다. (f32c32)