[논문리뷰] Deep Compression Autoencoder for Efficient High-Resolution Diffusion Models
ICLR 2025. [Paper] [Github]
Junyu Chen, Han Cai, Junsong Chen, Enze Xie, Shang Yang, Haotian Tang, Muyang Li, Yao Lu, Song Han
NVIDIA
14 Oct 2024

Introduction
Latent diffusion model은 diffusion model의 비용을 줄이기 위해 이미지를 latent space에 projection하는 데 오토인코더를 사용한다. 현재 주로 채택된 방법은 공간 압축률이 8인 오토인코더(f8)를 사용하는 것이며, 이는 $H \times W$의 이미지를 $\frac{H}{8} \times \frac{W}{8}$의 latent feature로 변환한다. 고해상도 이미지 합성(ex. 1024$\times$1024)의 경우 공간 압축률을 더욱 높이는 것이 중요하며, 특히 DiT는 토큰 수의 제곱에 비례한 계산 복잡도를 갖기 때문에 더욱 그렇다.
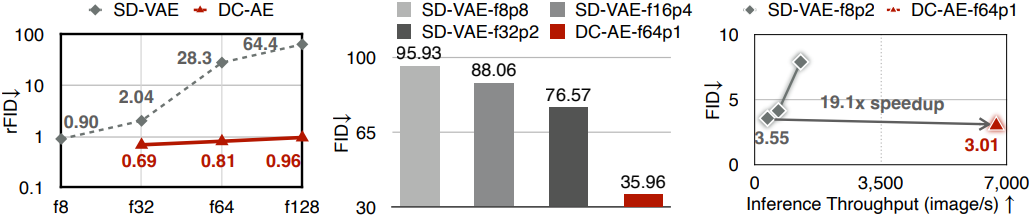
공간 압축률을 더욱 키우기 위한 현재의 일반적인 관행은 diffusion model 측에서 다운샘플링하는 것이다. 예를 들어, DiT에서는 패치 크기가 $p$인 patch embedding layer를 사용하여 latent feature를 $\frac{H}{8p} \times \frac{W}{8p}$로 압축한다. 하지만 오토인코더 측에서는 거의 노력이 이루어지지 않았으며, 주요 이유는 재구성 정확도 (rFID) 저하이다. 예를 들어, 256$\times$256 해상도에 대한 SD-VAE의 경우 f8에서 f64로 전환하면 rFID가 0.90에서 28.3으로 크게 저하된다.
본 논문에서는 효율적인 고해상도 이미지 합성을 위한 공간 압축률이 높은 오토인코더인 Deep Compression Autoencoder (DC-AE)를 제시하였다. 저자들이 정확도 저하의 근본 원인을 분석한 결과, 공간 압축률이 높은 오토인코더는 최적화가 더 어렵고 해상도 전반에 걸쳐 일반화 페널티를 겪는다. 이를 위해, 저자들은 두 가지 핵심 기법을 도입하였다.
- Residual Autoencoding: 오토인코더에 추가적인 shortcut을 도입하여 신경망 모듈이 공간-채널 연산을 기반으로 residual을 학습할 수 있도록 한다.
- Decoupled High-Resolution Adaptation: 일반화 페널티를 피하는 동시에 낮은 학습 비용을 유지하기 위해 고해상도 latent 적응 단계와 저해상도 로컬 정제 단계를 도입하였다.
저자들은 이러한 기법을 통해 우수한 재구성 정확도를 유지하면서 오토인코더의 공간 압축률을 32, 64, 128로 높였다. Diffusion model은 denoising에 완전히 집중할 수 있으며, DC-AE는 토큰 압축 전체를 담당하여 기존 방식보다 더 나은 이미지 생성 결과를 제공한다.
Method
1. Motivation
저자들은 공간 압축률이 높은 오토인코더와 낮은 오토인코더 간 정확도 차이의 근본 원인을 파악하기 위해 ablation study를 수행하였다. 구체적으로, f8에서 f64까지 공간 압축률이 점진적으로 증가하는 세 가지 설정을 고려하였다.
공간 압축률이 증가할 때마다 현재 오토인코더에 추가적인 인코더 및 디코더 단계를 쌓는다. 이렇게 하면 공간 압축률이 높은 오토인코더는 낮은 오토인코더를 하위 네트워크로 포함하게 되어 학습 용량이 더 높아진다.
또한, 다양한 설정에서 동일한 총 latent 크기를 유지하기 위해 latent 채널 수를 늘린다. 그런 다음 space-to-channel 연산을 적용하여 latent 채널을 더 높은 공간 압축률로 변환할 수 있다.
\[\begin{equation} H \times W \times C \rightarrow \frac{H}{p} \times \frac{W}{p} \times p^2 C \end{equation}\]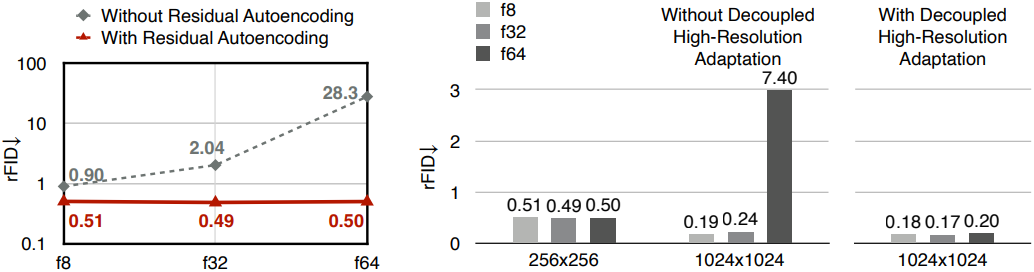
동일한 총 latent 크기와 더 강력한 학습 용량을 사용하더라도 공간 압축률이 증가하면 재구성 정확도가 여전히 저하되는 것이 관찰되었다. 이는 추가 인코더 및 디코더 단계가 단순한 space-to-channel 연산보다 성능이 떨어짐을 보여준다.
이러한 결과를 바탕으로 저자들은 정확도 차이가 모델 학습 과정에서 비롯된다고 추측하였다. 파라미터 공간에서 좋은 local optimum을 찾았지만, 최적화의 어려움으로 인해 공간 압축률이 높은 오토인코더가 그러한 local optimum에 도달하지 못한다.
2. Deep Compression Autoencoder
Residual Autoencoding
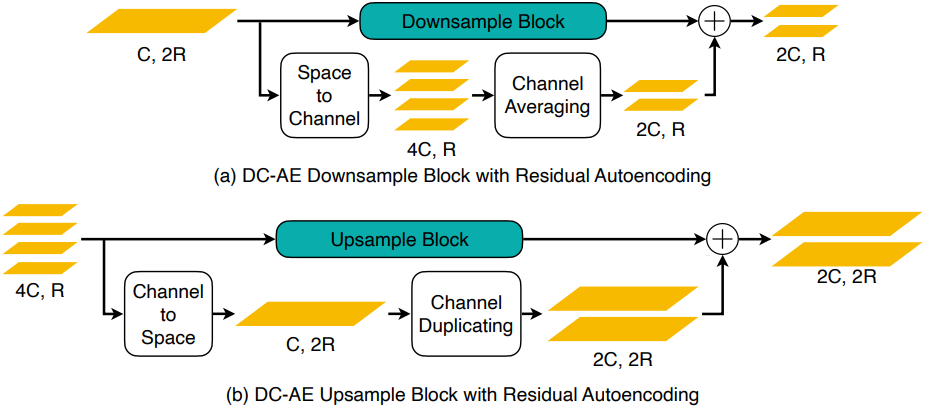
저자들은 분석 결과를 바탕으로 정확도 차이를 해소하기 위해 Residual Autoencoding을 도입했다. 기존 디자인과의 핵심적인 차이점은 최적화의 어려움을 완화하기 위해 space-to-channel 연산을 기반으로 신경망 모듈이 downsample residual을 명시적으로 학습하도록 한다는 것이다. ResNet과 달리, 여기서 residual은 identity mapping이 아니라 space-to-channel mapping이다.
실제로는 인코더의 다운샘플링 블록과 디코더의 업샘플링 블록에 추가적인 shortcut을 추가하여 구현된다. 구체적으로, 다운샘플링 블록의 경우, shortcut은 space-to-channel 연산 후 채널 수를 일치시키기 위한 channel 평균 연산을 수행한다. 예를 들어, 다운샘플링 블록의 입력 feature map 모양이 $H \times W \times C$이고 출력 feature map 모양이 $\frac{H}{2} \times \frac{W}{2} \times 2C$라고 가정하면, 추가된 shortcut은 다음과 같다.
\[\begin{aligned} H \times W \times C &\xrightarrow{\textrm{space-to-channel}} \frac{H}{2} \times \frac{W}{2} \times 4C \\ &\xrightarrow{\textrm{split}} [\frac{H}{2} \times \frac{W}{2} \times 2C, \frac{H}{2} \times \frac{W}{2} \times 2C] \\ &\xrightarrow{\textrm{average}} \frac{H}{2} \times \frac{W}{2} \times 2C \end{aligned}\]따라서 업샘플링 블록의 경우 shortcut은 channel-to-space 연산 후 channel 복제 연산이다.
\[\begin{aligned} \frac{H}{2} \times \frac{W}{2} \times 2C &\xrightarrow{\textrm{channel-to-space}} H \times W \times \frac{C}{2} \\ &\xrightarrow{\textrm{duplicate}} [H \times W \times \frac{C}{2}, H \times W \times \frac{C}{2}] \\ &\xrightarrow{\textrm{concat}} H \times W \times C \end{aligned}\]다운샘플링과 업샘플링 블록 외에도 동일한 원칙에 따라 중간 단계 디자인도 변경한다.
Decoupled High-Resolution Adaptation
Residual Autoencoding만으로 저해상도 이미지를 처리할 때 정확도 차이를 해결할 수 있지만, 고해상도 이미지로 확장하면 충분하지 않다. 고해상도 학습 비용이 많이 들기 때문에 고해상도 diffusion model의 일반적인 관행은 저해상도 이미지에서 학습된 오토인코더를 직접 사용하는 것이다. 이 전략은 공간 압축률이 낮은 오토인코더에 적합하다. 그러나 공간 압축률이 높은 오토인코더는 정확도가 크게 떨어지며, 더 높은 공간 압축률을 사용할 때 이 문제가 더 심각해진다.
본 논문에서는 이러한 현상을 일반화 페널티(generalization penalty)라고 부른다. 이 문제를 해결하는 간단한 해결책은 고해상도 이미지에 대한 학습을 수행하는 것이지만, 이 방법은 높은 학습 비용과 불안정한 고해상도 GAN loss 학습이라는 단점이 있다.
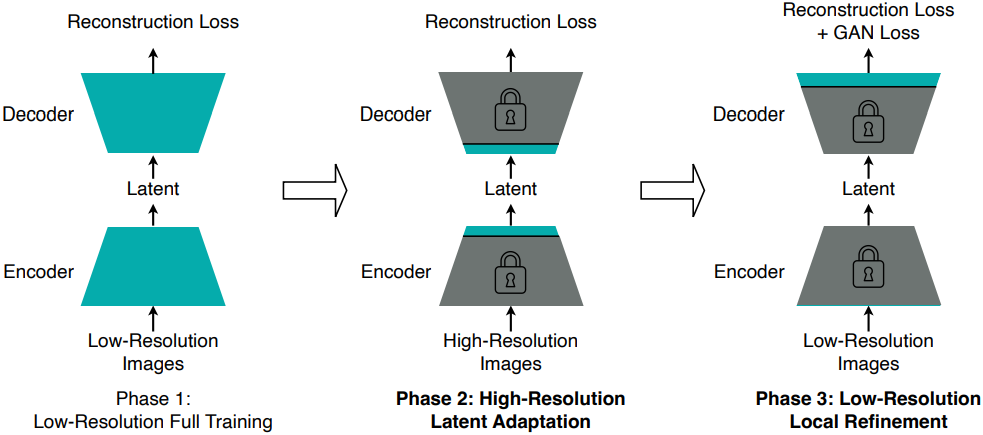
이러한 과제를 해결하기 위해, 저자들은 Decoupled High-Resolution Adaptation을 도입하였다. 기존의 단일 단계 학습 전략과 비교할 때 두 가지 주요 차이점이 있다.
첫째, GAN loss 학습을 전체 모델 학습에서 분리하고, GAN loss 학습을 위한 전용 로컬 정제 단계를 도입하였다. 로컬 정제 단계에서는 디코더의 head layer만 튜닝하고 나머지 layer는 모두 고정한다. 이 설계의 직관적인 원리는 재구성 loss만으로도 콘텐츠와 semantic을 재구성하는 학습에 충분하다는 것에 기반한다. 반면, GAN loss는 주로 로컬 디테일을 개선하고 로컬한 아티팩트를 제거한다. 로컬 정제라는 동일한 목표를 달성하기 위해, 디코더의 head layer만 튜닝하는 것이 전체 학습보다 학습 비용이 낮고 정확도가 더 높다.
또한, 분리는 GAN loss 학습이 latent space를 변화시키는 것을 방지한다. 이를 통해 일반화 페널티를 고려하지 않고 저해상도 이미지에 대한 로컬 정제 단계를 수행할 수 있다. 이를 통해 3단계의 학습 비용을 더욱 절감하고, 매우 불안정한 고해상도 GAN loss 학습을 피할 수 있다.
둘째, 일반화 페널티를 완화하기 위해 중간 레이어를 튜닝하여 latent space를 조정하는 추가적인 고해상도 latent 적응 단계를 도입하였다. 실험 결과, 중간 레이어만 튜닝하는 것만으로도 이 문제를 해결하는 데 충분하며, 고해상도 전체 학습보다 학습 비용이 낮다.

3. Application to Latent Diffusion Models
DC-AE를 latent diffusion model에 적용하는 것은 간단하다. 변경해야 할 유일한 hyperparamter는 패치 크기이다. DiT 모델의 경우, 토큰 수를 줄이기 위한 일반적인 방법은 패치 크기 $p$를 늘리는 것이다. 이는 먼저 space-to-channel 연산을 적용하여 주어진 latent diffusion model의 공간 크기를 $p$배 줄인 다음, 패치 크기가 1인 transformer 모델을 사용하는 것과 같다.
공간 압축률이 낮은 오토인코더(ex. f8)를 space-to-channel 연산과 결합하면 높은 공간 압축률을 달성할 수 있다. 저자들은 이 경우를 DC-AE와 비교한 ablation study를 수행하였다.
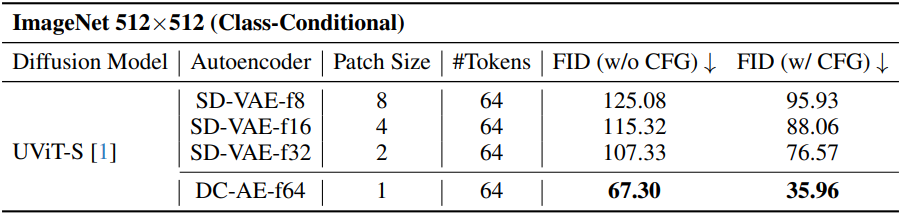
결과는 위 표와 같다. 오토인코더를 사용하여 목표 공간 압축률에 바로 도달하는 것이 모든 설정 중에서 가장 우수한 결과를 제공하는 것을 확인할 수 있다. 또한, 공간 압축을 diffusion model에서 오토인코더로 변경하면 FID가 지속적으로 향상된다.
Experiments
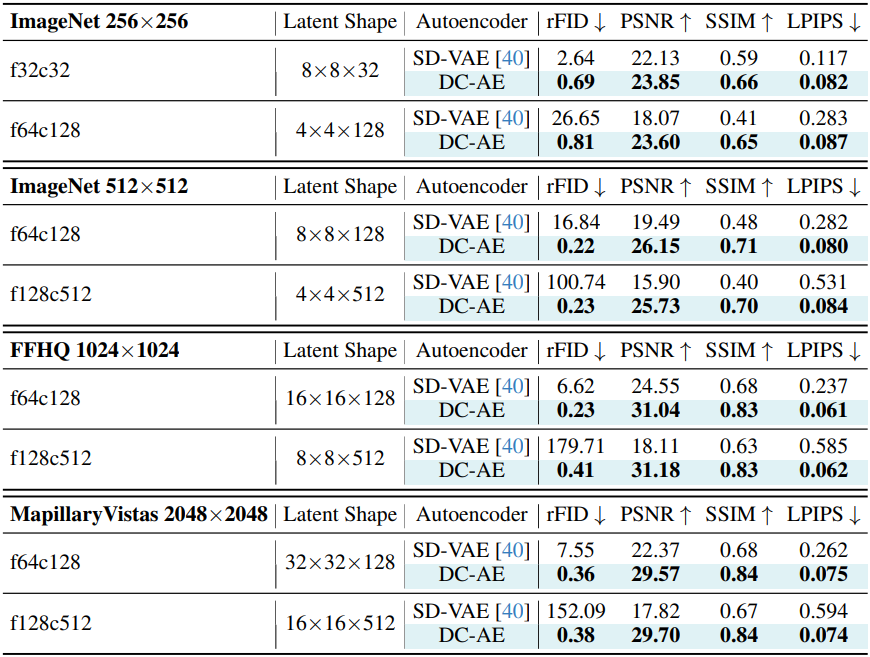
1. Image Compression and Reconstruction
다음은 SD-VAE와 오토인코더 재구성 성능을 비교한 결과이다.

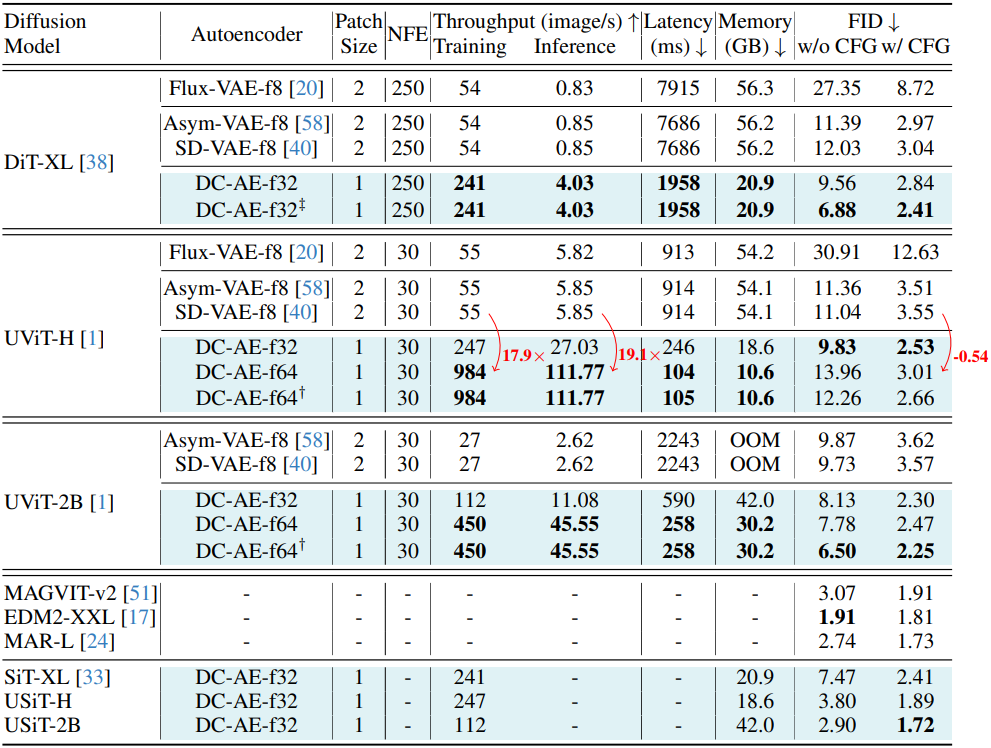
2. Latent Diffusion Models
다음은 ImageNet 512$\times$512에서의 클래스 조건부 이미지 생성 결과를 비교한 것이다.
다음은 text-to-image 생성 결과를 비교한 것이다.

다음은 text-to-image 생성 예시들이다.
