[논문리뷰] Efficiently Reconstructing Dynamic Scenes One D4RT at a Time
arXiv 2025. [Paper] [Page]
Chuhan Zhang, Guillaume Le Moing, Skanda Koppula, Ignacio Rocco, Liliane Momeni, Junyu Xie, Shuyang Sun, Rahul Sukthankar, Joëlle K. Barral, Raia Hadsell, Zoubin Ghahramani, Andrew Zisserman, Junlin Zhang, Mehdi S. M. Sajjadi
Google DeepMind | University College London | University of Oxford
9 Dec 2025
Introduction
기존의 3D 재구성 방식은 ‘모든 것의 geometry는 무엇이며, 모든 곳에서 동시에 어떻게 존재하는가?’라는 질문을 던진다. 저자들은 이러한 철저하고 경직된 접근 방식이 역동적인 세상에 적용하기에는 근본적으로 부적합하다고 주장한다. 통합된 4차원적 이해의 필요성이 분명함에도 불구하고, 기존의 접근 방식들은 종종 문제를 개별적인 task별 구성 요소로 나누어 해결하려 한다.
최근의 feed-forward 방식(ex. VGGT)은 서로 다른 모달리티에 대해 별도의 특수 디코더를 사용한다. 하지만 이러한 방법들은 모두 장면의 동적인 부분에 대한 correspondence를 설정할 수 없다는 것이 결정적인 문제이다. SpatialTrackerV2는 동적 요소를 통합했지만, 여전히 통합된 단일 단계 공식이 부족하여 비용이 많이 드는 반복적인 개선 방식에 의존한다.
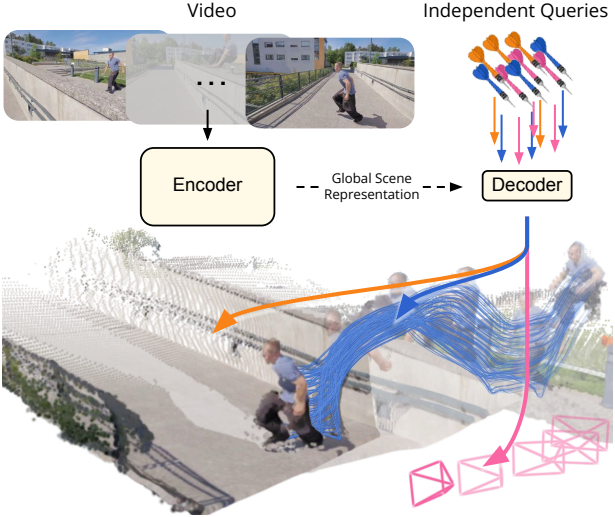
본 논문에서는 단편적인 프레임 단위 디코딩에서 효율적인 on-demand querying 방식으로의 패러다임 전환을 제안하였다. 유연하고 scalable한 아키텍처를 활용하여 완전한 4D 재구성을 구현하는 feed-forward 방식인 D4RT를 소개한다. 본 모델은 먼저 입력 동영상을 인코딩하여 잠재적인 장면 표현을 생성하고, 이 표현을 사용하여 시공간적 포인트 query를 독립적으로 디코딩한다. 이 간단하고 혁신적인 설계는 모든 4D 재구성 task를 단일 인터페이스로 통합하여 효율적인 학습 및 inference를 가능하게 한다.
Method
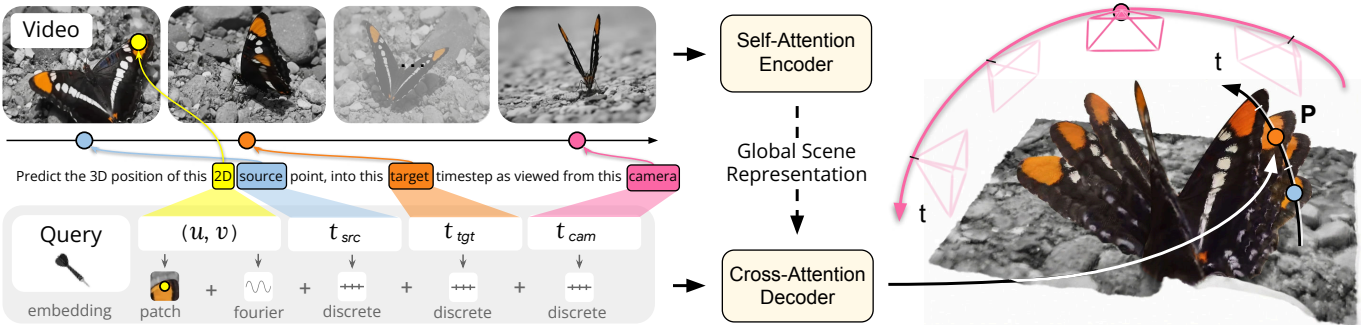
D4RT는 간단한 인코더-디코더 아키텍처를 기반으로 한다. 먼저 강력한 인코더가 동영상을 처리하여 글로벌 장면 표현 $F$를 생성한다. 인코더의 역할은 전체 환경에 대한 정보를 캡처하고, 모든 동영상 프레임 간의 밀접하게 연결된 관계를 식별하며, 시간의 흐름과 그것이 장면에 미치는 영향을 파악하는 것이다. 두 번째 단계에서는 가벼운 디코더가 간단한 저수준 인터페이스를 통해 $F$를 쿼리한다. 구체적으로, 소스 프레임의 2D 점이 주어지면, 디코더는 주어진 타겟 timestep(시간적 상태를 정의함)에서의 해당 점의 3D 위치를 예측하고, 이 위치는 주어진 카메라 레퍼런스를 기준으로 표현된다. 타겟 timestep은 시간적 상태를 정의하며, 카메라 레퍼런스는 카메라 시점이 해당 레퍼런스에 대응하는 프레임 timestep으로 정의된다.
이러한 구성은 세 가지 바람직한 특성을 가지고 있다.
- 인덱스가 일치할 필요가 없어 공간과 시간을 완전히 분리할 수 있다.
- 각 query가 독립적으로 디코딩되므로 효율적인 학습 및 inference는 물론 유연한 디코딩이 가능하다. (sparse 및 dense 디코딩 모두)
- 이 인터페이스는 통합되고 일관된 방식으로 다양한 하위 애플리케이션을 활용할 수 있도록 지원한다.
1. D4RT Framework
동영상 $V \in \mathbb{R}^{T \times H \times W \times 3}$가 주어지면, 인코더 $\mathcal{E}$는 글로벌한 latent 장면 표현 $F$를 추출한다.
\[\begin{equation} F = \mathcal{E} (V) \in \mathbb{R}^{N \times C} \end{equation}\]$F$가 계산되면 두 번째 단계 전체에서 고정된 상태로 유지되며, 디코더 $\mathcal{D}$는 $F$에 대한 여러 query에서 cross-attention을 수행한다. Query \(\textbf{q} = (u, v, t_\textrm{src}, t_\textrm{tgt}, t_\textrm{cam})\)으로 정의하는데, 여기서 \((u, v, t_\textrm{src})\)는 소스 파라미터에 해당하고 \((t_\textrm{tgt}, t_\textrm{cam})\)은 타겟 파라미터에 해당한다. $(u, v) \in [0, 1]^2$는 소스 프레임 \(t_\textrm{src}\)에서 관심 지점의 정규화된 2D 좌표를 나타내고, \((t_\textrm{tgt}, t_\textrm{cam}) \in [1, \ldots, T]\)는 각각 타겟 timestep과 레퍼런스 카메라 좌표계의 시간적 인덱스를 나타낸다. 각 query $\textbf{q}$는 동영상 feature $F$를 사용하여 완전히 독립적으로 처리되어 해당 3D 포인트 위치 $\textbf{P}$를 생성한다.
\[\begin{equation} \textbf{P} = \mathcal{D}(\textbf{q}, F) \in \mathbb{R}^3 \end{equation}\]Query애서 4D reconstruction까지
본 프레임워크는 간단한 query 변형을 통해 광범위한 4D task를 처리할 수 있도록 한다.
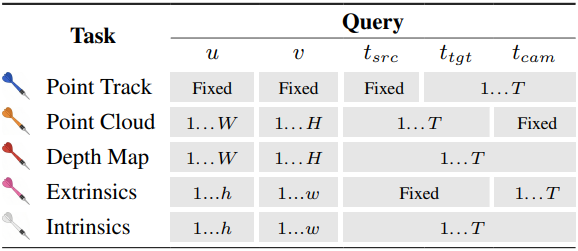
- 3D point track: 동영상의 소스 프레임 \(t_\textrm{src}\)에서 임의의 고정점 $(u, v)$을 선택하고 \(t_\textrm{tgt} = t_\textrm{cam} = \{1, \ldots, T\}\)를 변화시키면 된다.
- 전체 포인트 클라우드: 동영상의 모든 픽셀의 3D 위치를 공유 레퍼런스 프레임 \(t_\textrm{cam}\)에서 직접 예측하면 된다. 통합 좌표계로 매핑하기 위한 좌표 변환이 필요하지 않다.
- Depth map: \(t_\textrm{src} = t_\textrm{tgt} = t_\textrm{cam}\)으로 동영상의 임의의 픽셀을 쿼리하고 출력 $\textbf{P}$의 $Z$ 차원만 유지하면 된다.
카메라 extrinsic의 경우, 임의의 두 동영상 프레임 $i, j \in [1, \ldots, T]$ 사이의 상대적인 카메라 포즈를 도출하기 위해 두 레퍼런스 프레임 모두에서 $(h, w)$ 그리드에 샘플링된 소스 포인트 앙상블 \(\{(u_k, v_k)\}_k\)에 대한 query를 생성한다.
\[\begin{equation} \textbf{q}_{i,k} = (u_k, v_k, i, i, i), \quad \textbf{q}_{j,k} = (u_k, v_k, i, i, j) \end{equation}\]결과적으로 얻어진 집합 \(\{\mathcal{D}(\textbf{q}_{i,k}, F)\}_k\)와 \(\{\mathcal{D}(\textbf{q}_{j,k}, F)\}_k\)는 서로 다른 레퍼런스 좌표계에서 동일한 3D 점들을 나타낸다. 따라서 이들 사이의 rigid transformation만을 찾으면 되는데, 이는 3$\times$3 SVD를 푸는 Umeyama’s algorithm을 통해 효율적으로 도출할 수 있다.
프레임 $i \in [1, \ldots, T]$에 대한 intrinsic의 경우, $(h, w)$ 그리드에서 샘플링된 여러 소스 포인트에 대한 query 세트를 구성한다. 이에 해당하는 모든 3D 위치 $\textbf{P} = (p_x, p_y, p_z)$를 디코딩한다. principal point가 $(0.5, 0.5)$에 있는 핀홀 카메라 모델을 가정하면 초점 거리 파라미터는 다음과 같다.
\[\begin{equation} f_x = p_z (u - 0.5) / p_x, \quad f_y = p_z (v - 0.5) / p_y \end{equation}\]Robustness를 위해 $k$개의 추정치에 대한 중앙값을 취한다. 왜곡이 있는 카메라 모델 또한 초기 추정에 비선형 정제 단계를 추가함으로써 원활하게 통합할 수 있다.
2. Model Architecture
본 논문에서 사용하는 인코더 $\mathcal{E}$는 프레임별 로컬 self-attention layer와 글로벌 self-attention layer가 교차 배치된 ViT를 기반으로 한다. 임의의 화면비를 지원하기 위해 입력 동영상을 tokenize하기 전에 고정된 정사각형 해상도로 크기를 조정한다. 원래 화면비를 유지하기 위해, 이를 별도의 토큰에 포함시켜 메인 동영상 토큰과 함께 transformer에 전달한다.
Pointwise decoder
디코더 $\mathcal{D}$는 소형 cross-attention transformer이다. 먼저 2D 좌표 $(u, v)$의 Fourier feature embedding에 \(t_\textrm{src}\), \(t_\textrm{tgt}\), \(t_\textrm{cam}\)에 대해 학습된 discrete timestep embedding을 더하여 query 토큰을 구성한다. $(u, v)$를 중심으로 하는 9$\times$9 픽셀 크기의 RGB 패치 임베딩을 query에 추가하면 성능이 크게 향상된다.
각 query는 cross-attention을 통해 글로벌 장면 표현 $F$로 독립적으로 디코딩되어 query 간 상호 작용을 방지한다. 결과 feature는 간단한 학습된 projection을 통해 3D 포인트 위치 $\textbf{P}$에 매핑된다. Query를 독립적으로 디코딩하는 것은 주요 이점을 제공하는 의도적인 디자인 결정이다. 모델에 supervision 신호를 제공하기 위해 디코딩해야 하는 query 수가 적기 때문에 효율적인 학습이 가능하다. 또한 inference 시에는 모든 동영상 프레임에서 query를 자유롭게 선택할 수 있으며, out-of-distribution 효과를 방지하기 위해 query 간 상관 관계가 필요하지 않다. 실제로 query 간 self-attention을 활성화했을 때 성능이 크게 저하된다. 마지막으로, 이 디자인은 간단한 병렬 처리 덕분에 매우 효율적인 추론을 가능하게 한다.
3. Training and Inference
모델은 Kauldron으로 구현되었으며, $N$개의 샘플링된 query batch에 대해 계산된 loss의 가중 합을 최소화하는 방식으로 end-to-end 학습되었다. 주요 supervision 신호는 정규화된 3D 점 위치 $\textbf{P}$에 적용된 L1 loss에서 파생된다. 구체적으로, 타겟 점 집합과 추정된 점 집합 모두 각각의 평균 깊이로 정규화된 후, 멀리 떨어진 점들이 loss에 미치는 영향을 줄이기 위해 $\textrm{sign}(x) \cdot \log(1+ \vert x \vert)$ 변환을 거친다.
또한 디코더 출력에 대한 추가적인 linear projection을 통해 얻은 보조 예측값들로도 loss를 구성한다. 이러한 보조 예측값은 이미지 공간에서 점 위치의 2D 좌표에 대한 L1 loss, 3D 표면 normal에 대한 코사인 유사도, 타겟 점 visibility에 대한 binary cross entropy, 그리고 point motion 벡터에 대한 L1 loss다. 모든 loss 항은 GT supervision이 있는 경우에만 적용된다. 마지막으로, 3D 점 오차에 신뢰도 $c$를 가중치로 부여하고, 신뢰도 페널티인 $-\log(c)$를 추가한다.
효율적인 dense dynamic correspondence
본 query 기반 모델의 핵심 기능은 정적 및 동적 동영상을 포함한 동영상 내 모든 픽셀에 대한 dense correspondence를 효율적으로 계산할 수 있다는 것이다. 이러한 기능은 완전하고 전체적인 장면 재구성에 매우 중요하며, 이는 기존 연구에서 흔히 발생했던 가림 현상으로 인한 불연속성과 sparse 아티팩트를 제거하는 데 핵심적인 역할을 한다. 그러나 동영상 전체 픽셀에 대한 track을 재구성하는 단순한 접근 방식은 $O(T^2 HW)$번의 query를 필요로 하며, 이 중 대부분은 불필요하다.

본 논문에서는 occupancy grid \(G \in \{0, 1\}^{T \times H \times W}\)를 사용하여 시공간적 중복성을 활용하는 Algorithm 1을 도입하였다. 이 알고리즘은 방문하지 않은 픽셀에서만 새로운 track을 생성한다. 각 전체 동영상 track은 가시적으로 통과하는 모든 시공간 픽셀을 방문한 것으로 표시한다. 이 알고리즘을 사용하면 5~15배의 적응적 속도 향상을 얻을 수 있다. 이러한 dense하고 유연한 전략은 본 논문의 디코더가 sparse하고 가볍기 때문에 가능하다.
Experiments
1. Qualitative Analysis
다음은 재구성 결과를 비교한 것이다.
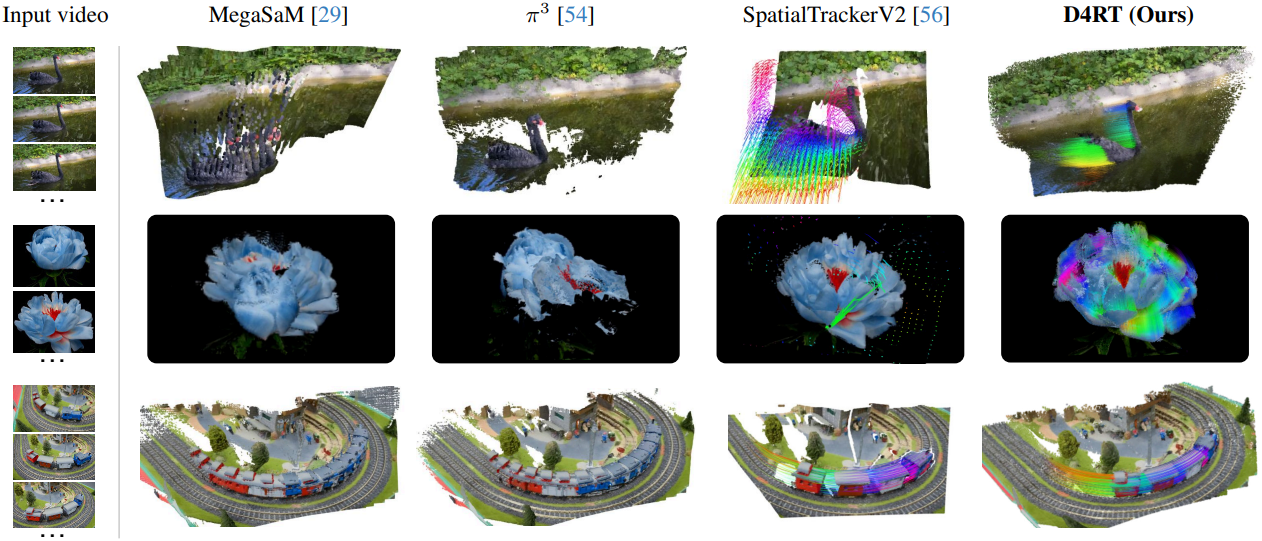
다음은 in-the-wild 동영상에 대한 결과이다. (위: 정적 장면, 아래: 동적 장면)

2. 4D Reconstruction and Tracking
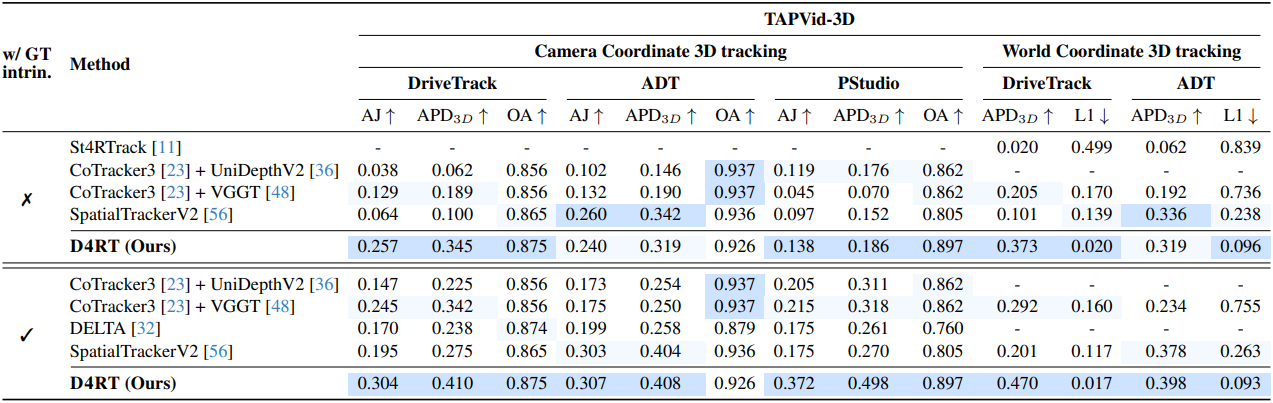
다음은 4D 재구성 및 tracking에 대한 비교 결과이다.
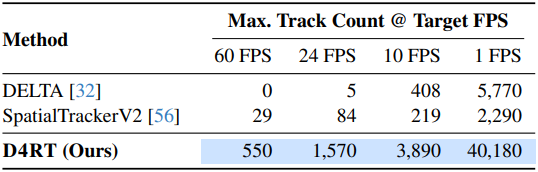
다음은 3D tracking에 대한 처리 속도를 비교한 결과이다.
3. 3D Reconstruction
다음은 동영상 depth map 및 point map 예측에 대한 비교 결과이다.

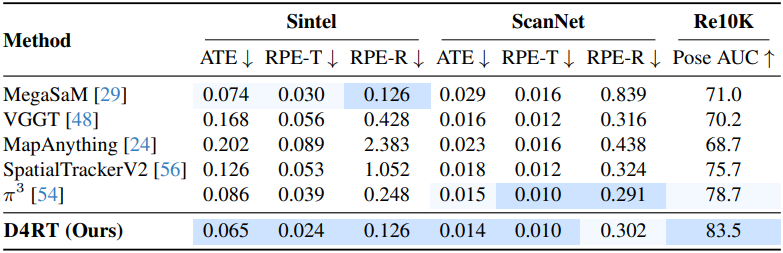
다음은 카메라 포즈 추정에 대한 비교 결과이다.
다음은 포즈 정확도와 inference 속도를 비교한 결과이다.

4. Ablation Studies
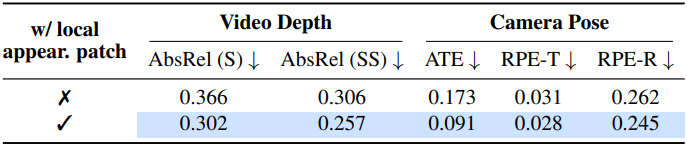
다음은 RGB 로컬 패치에 대한 ablation 결과이다.

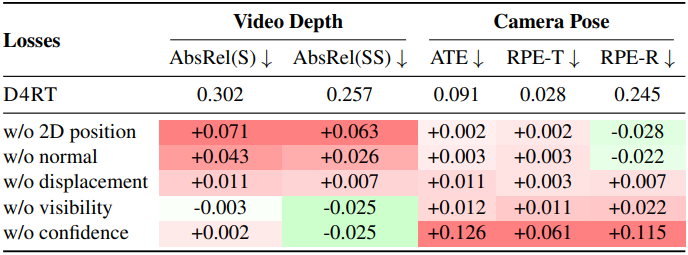
다음은 보도 loss들에 대한 ablation 결과이다.
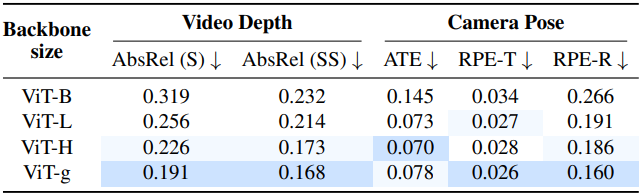
다음은 backbone 크기에 따른 성능을 비교한 결과이다.