[논문리뷰] D²USt3R: Enhancing 3D Reconstruction for Dynamic Scenes
NeurIPS 2025. [Paper] [Page]
Jisang Han, Honggyu An, Jaewoo Jung, Takuya Narihira, Junyoung Seo, Kazumi Fukuda, Chaehyun Kim, Sunghwan Hong, Yuki Mitsufuji, Seungryong Kim
KAIST AI | ETH Zürich | Sony AI | Sony Group Corporation
8 Apr 2025
Introduction
DUSt3R는 장면의 geometry, 픽셀과 장면 간의 대응 관계, 그리고 뷰 간의 관계를 인코딩하는 3D pointmap을 직접 예측하여, 다단계 파이프라인에서 흔히 발생하는 오차 누적을 줄였다. DUSt3R는 정적 시나리오에서는 강점을 보이지만, rigidity 가정으로 인해 동적 장면에서는 상당한 어려움을 겪는다.
본 논문에서는 Static-Dynamic Aligned Pointmaps (SDAP)을 직접 예측하는 새로운 feed-forward 프레임워크인 Dynamic Dense Unconstrained Stereo 3D Reconstruction (D²USt3R)을 제안하였다. 이 프레임워크는 공간 구조와 시간적 움직임을 동시에 고려하여 정적 및 동적 영역 모두에 대해 보다 안정적인 3D 재구성을 가능하게 한다. 움직이는 object의 correspondence들을 간과하는 MonST3R와 달리, D²USt3R는 동적 장면에서 correspondence와 재구성을 통합된 문제로 처리함으로써 프레임 간의 dense match들을 포착한다. 이를 위해 정적 영역과 동적 영역에 각각 다른 학습 신호를 적용하는 새로운 학습 방식을 채택했다. 이러한 신호는 occlusion mask와 dynamic mask를 통해 관심 영역으로 안정화된다.
Method
1. Static-Dynamic Aligned Pointmap
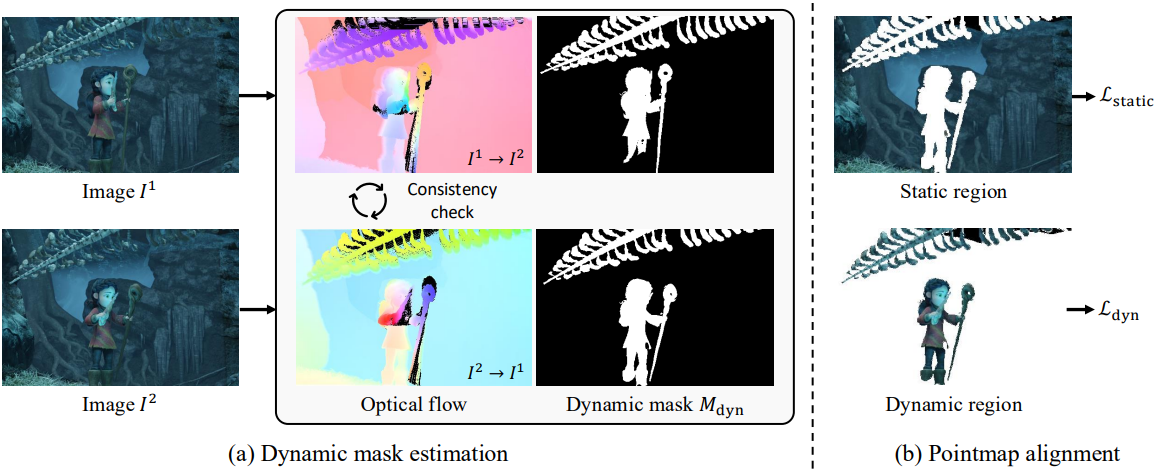
3D pointmap은 정적인 3D 구조를 인코딩하는 데 탁월하지만, 시간적 불일치로 인해 움직이는 object에서는 한계를 보인다. 이러한 문제를 해결하기 위해 공간적 일관성을 유지하면서 시간에 따른 픽셀 움직임을 포착하는 Static-Dynamic Aligned Pointmap (SDAP)을 제안하였다. SDAP의 핵심 아이디어는 모든 픽셀을 각 timestep에서 위치가 정렬되는 통합된 월드 좌표계로 표현하여 동적인 장면을 일관성 있게 재구성하는 것이다. 그러나 동적인 움직임은 종종 가려짐(occlusion)을 유발하는데, 이는 일부 픽셀이 한 프레임에만 나타나는 현상을 의미한다. 이러한 occlusion은 불완전한 정렬을 초래하여 궁극적으로 3D 재구성 품질을 저하시킨다.
Occlusion Masks
SDAP 표현에서 가려진 영역을 제거하기 위해, 먼저 optical flow estimator인 SEA-RAFT를 사용하여 각 이미지 쌍 간의 dense 2D correspondence를 얻는다. 데이터셋에 실제 optical flow 데이터가 있는 경우, 해당 데이터를 대신 사용한다. 카메라 baseline이 커서 occlusion이 빈번하게 발생하는 시나리오에서는, 정확한 occlusion mask를 도출하기 위해 forward–backward 일관성 검사를 추가로 수행한다.
\[\begin{equation} p_2^\prime = p_1 + \textbf{f}(p_1), \quad p_1^\prime = p_2^\prime + \textbf{b}(p_2^\prime) \\ M_\textrm{occ} = [\vert p_1^\prime - p_1 \vert > t] \end{equation}\]($p_i$는 이미지 $I^i$의 픽셀, $\textbf{f}$와 $\textbf{b}$는 forward/backward optical flow, $t$는 occlusion threshold)
Dynamic Masks
동적 영역은 카메라 모션과 object에서는 고유의 움직임 간의 불일치로 인해 pointmap을 정확하게 정렬하는 데 상당한 어려움을 야기한다. 이러한 동적 모션을 명시적으로 고려하지 않으면 네트워크는 동적 영역을 정적 영역처럼 잘못 맞추려고 시도하여 재구성 정확도를 저하시킬 수 있다.
이를 해결하기 위해 움직이는 영역을 명시적으로 강조하는 dynamic mask \(M_\textrm{dyn}\)을 도입하여 네트워크가 보다 안정적인 학습 과정을 수행하도록 유도한다. 구체적으로, \(M_\textrm{dyn}\)은 optical flow $\textbf{f}$를 카메라 모션에 의해서만 발생하는 예상 flow \(\textbf{f}_\textrm{cam}\)과 비교하여 계산된다.
\[\begin{equation} \textbf{f}_\textrm{cam} = \pi (DKRK^{-1}p + KT) - p, \quad M_\textrm{dyn} = [\| \textbf{f}_\textrm{cam} - \textbf{f} \| > \tau] \end{equation}\]($\pi$는 projection 연산, $D$는 depth map, $K$는 intrinsic, $[R \vert T]$는 extrinsic, $p$는 픽셀 좌표, $\tau$는 dynamic threshold)
2. Objective Function
본 논문에서는 occlusion mask와 dynamic mask가 적용된 SDAP 표현을 기반으로, 이러한 마스크를 활용하여 안정성을 향상시킨 confidence-aware 3D regression을 학습 loss로 설정하였다. 정적 영역과 동적 영역의 서로 다른 특성을 효과적으로 고려하기 위해, 각각의 시나리오를 명확하게 처리하고 두 경우 모두에서 정확한 재구성을 보장하도록 설계된 두 개의 별도 loss function을 도입하였다.
정적 영역에 대한 pointmap 정렬
DUSt3R의 regression loss는 본질적으로 카메라 포즈만을 사용하여 3D pointmap을 정렬한다. 정렬이 이미지 $I^2$ 내의 정적 영역에만 집중되도록 하기 위해 dynamic mask \(M_\textrm{dyn}\)을 사용하고 regression loss 계산을 그에 따라 제한한다. 따라서 regression loss \(\mathcal{L}_\textrm{regr}\)를 다음과 같이 수정한다.
\[\begin{aligned} \mathcal{L}_\textrm{regr}(1, i) &= \| \frac{1}{z} X_i^{1,1} - \frac{1}{\bar{z}} \bar{X}_i^{1,1} \| \\ \mathcal{L}_\textrm{regr}(2, i) &= (1 - M_{\textrm{dyn}, i}^2) \| \frac{1}{z} X_i^{2,1} - \frac{1}{\bar{z}} \bar{X}_i^{2,1} \| \end{aligned}\]불확실성을 정렬 과정에 통합하기 위해 정적 영역에 대한 confidence-aware loss인 \(\mathcal{L}_\textrm{static}\)을 추가로 도입한다.
\[\begin{equation} \mathcal{L}_\textrm{static} = \sum_{v \in \{1,2\}} \sum_{i \in \mathcal{D}^v} C_i^{v,1} \mathcal{L}_\textrm{regr} (v, i) - \alpha \log C_i^{v,1} \end{equation}\](\(\mathcal{D}^v\)는 뷰 $v$에 대한 유효한 픽셀 위치)
동적 영역에 대한 pointmap 정렬
저자들은 $I^2$의 동적 영역을 $I^1$에 정렬하기 위해, occlusion mask와 dynamic mask를 모두 활용하는 동적 정렬 loss를 도입하였다. 구체적으로, 두 번째 시점 $I^2$의 점들이 $I^1$의 좌표계로 변환될 때, 첫 번째 시점의 시간적 상태와 정확하게 대응하도록 한다. Regression loss와 마찬가지로, 신뢰도 추정치를 추가하여 confidence-aware loss를 다음과 같이 정의한다.
\[\begin{aligned} \mathcal{L}_\textrm{dyn} &= \sum_{i \in \mathcal{D}^2} M_{\textrm{dyn}, i}^2 (1 - M_{\textrm{occ}, i}^2) C_i^{2,1} \| \frac{1}{\bar{z}_1} \bar{X}_{i + \textbf{b}(i)}^{1,1} - \frac{1}{z_1} \bar{X}_i^{2,1} \| - \alpha \log C_i^{2,1} \\ &+ \sum_{i \in \mathcal{D}^1} M_{\textrm{dyn}, i}^1 (1 - M_{\textrm{occ}, i}^1) C_i^{1,2} \| \frac{1}{\bar{z}_2} \bar{X}_{i + \textbf{f}(i)}^{2,2} - \frac{1}{z_2} \bar{X}_i^{1,2} \| - \alpha \log C_i^{1,2} \\ \end{aligned}\]Loss function의 첫 번째 항은 $I^1$과 관련된 카메라 시스템의 좌표 공간에서 pointmap의 정렬을 강제하고, 두 번째 항은 시점의 역할이 바뀔 때 점들을 정렬함으로써 대칭적인 제약을 도입한다.
최종 loss
최종 loss는 다음과 같이 정의된다.
\[\begin{equation} \mathcal{L}_\textrm{total} = \mathcal{L}_\textrm{static} + \mathcal{L}_\textrm{dyn} \end{equation}\]이 loss function을 통해 모델은 동적 장면에서 정확한 3D geometry와 robust한 correspondence를 포착하는 동시에 정적 영역에서 DUSt3R의 장점을 유지할 수 있다.
3. Additional heads for downstream task
저자들은 SDAP 프레임워크의 기능과 해석 가능성을 더욱 향상시키기 위해, dynamic mask와 optical flow를 명시적으로 모델링하는 데 특화된 두 개의 추가 downstream head를 도입했다.
Dynamic mask head
모델은 동적 움직임에 해당하는 영역을 암시적으로 인코딩하므로, 추가적인 head를 사용하여 dynamic mask를 명시적으로 예측한다. 구체적으로, pointmap regression head와 유사한 구조를 가진 DPT head를 사용하여 1채널 logit map \(\hat{M}_\textrm{dyn}\)을 예측한다. 이 head는 다음과 같이 정의된 binary cross-entropy loss를 사용하여 학습된다.
\[\begin{equation} \mathcal{L}_\textrm{mask} = - \frac{1}{\vert \mathcal{D}_\textrm{all} \vert} \sum_{i \in \mathcal{D}_\textrm{all}} \left[ M_{\textrm{dyn}, i} \log (\sigma (\hat{M}_{\textrm{dyn}, i})) + (1 - M_{\textrm{dyn}, i}) \log (1 - \sigma (\hat{M}_{\textrm{dyn}, i})) \right] \end{equation}\]($\sigma$는 sigmoid function, \(\mathcal{D}_\textrm{all}\)은 모든 픽셀의 집합)
Optical flow head
Optical flow를 정확하게 추정하기 위해 RAFT 아키텍처 기반의 추가 head를 통합했다. ZeroCo에서 영감을 받아, optical flow head는 4D correlation volume 대신 cross-attention map을 활용한다. 이 optical flow head는 SEA-RAFT의 Mixture-of-Laplace loss를 사용하여 학습된다.
Experiments
- 구현 디테일
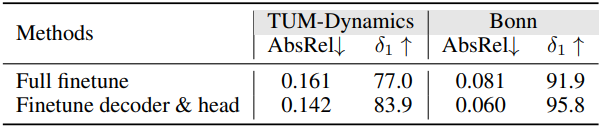
- 인코더는 고정, 디코더와 DPT head만 fine-tuning
- epochs: 50
- 각 epoch마다 이미지 쌍 2만 개를 샘플링
- optimizer: AdamW
- learning rate: $5 \times 10^{-5}$
- 총 batch size: 16
- gradient accumulation step: 2
- GPU: NVIDIA RTX 6000 4개

1. Experimental results
Depth estimation
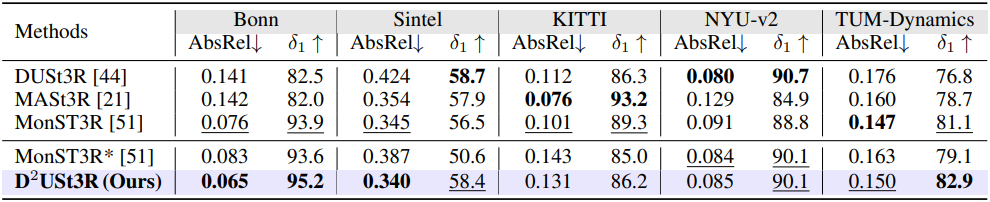
다음은 multi-frame depth 추정 결과를 비교한 것이다.

다음은 single-frame depth 추정 결과를 비교한 것이다.
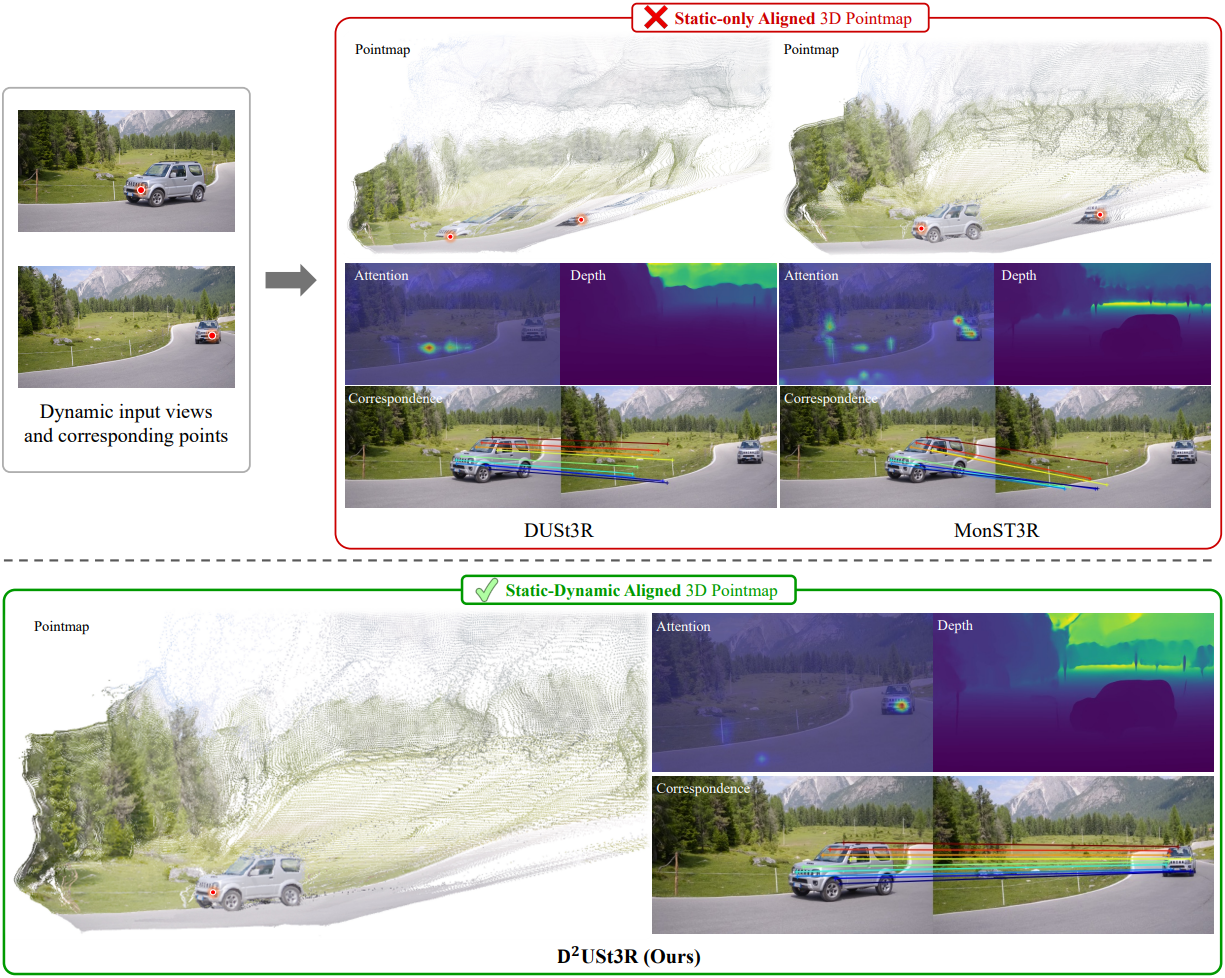
다음은 MonST3R와 재구성된 pointmap을 비교한 결과이다.

다음은 깊이 추정 결과를 비교한 것이다.

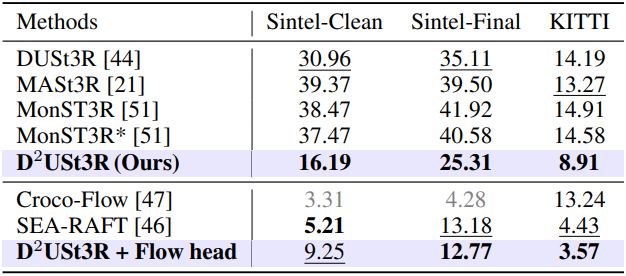
Camera pose estimation
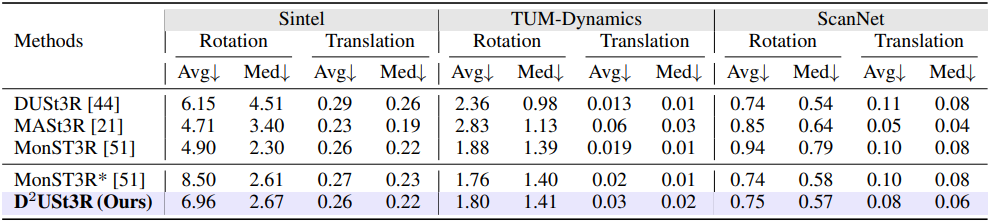
다음은 카메라 포즈 추정 결과를 비교한 것이다.
Dynamic alignment
다음은 동적 물체에 대한 pointmap 정렬 정확도를 비교한 결과이다.
다음은 주어진 이미지 쌍에 대한 correspondence들을 시각화한 것이다.

다음은 optical flow head의 예측 결과이다.

Dynamic mask
다음은 dynamic mask head의 예측 결과이다.

2. Robustness analysis on frame intervals
다음은 프레임 간격에 대한 robustness를 분석한 결과이다.

3. Ablation study
다음은 학습 전략에 대한 ablation study 결과이다.