[논문리뷰] Continuous 3D Perception Model with Persistent State
CVPR 2025. [Paper] [Page]
Qianqian Wang, Yifei Zhang, Aleksander Holynski, Alexei A. Efros, Angjoo Kanazawa
University of California | Berkeley 2Google DeepMind
21 Jan 2025

Introduction
본 논문은 세 가지 핵심 기능을 통합하는 온라인 3D 인식 프레임워크인 CUT3R를 소개한다.
- 적은 수의 관찰에서 3D 장면 재구성
- 더 많은 관찰로 재구성을 지속적으로 개선
- 관찰되지 않은 장면 영역의 3D 속성 추론
저자들은 데이터 기반 prior를 반복적 업데이트 메커니즘과 통합하였다. 학습된 prior를 통해 기존 방법에서 발생하는 문제 (ex. 동적 물체, sparse한 관찰)를 해결할 수 있으며, 지속적으로 업데이트할 수 있는 능력을 통해 새롭게 관찰된 영역을 온라인에서 처리하고 시간이 지남에 따라 재구성을 지속적으로 개선할 수 있다.
구체적으로, 이미지 스트림이 주어지면, CUT3R은 장면 콘텐츠를 인코딩하는 지속적인 내부 state를 유지하고 점진적으로 업데이트한다. 각각의 새로운 관찰에서, 모델은 이 state를 동시에 업데이트하고 이를 읽어 현재 뷰의 3D 속성, 즉 해당 뷰의 pointmap과 카메라 파라미터(intrinsic, extrinsic)를 예측한다. Pointmap을 누적하면 온라인으로 dense한 장면 재구성을 할 수 있다.
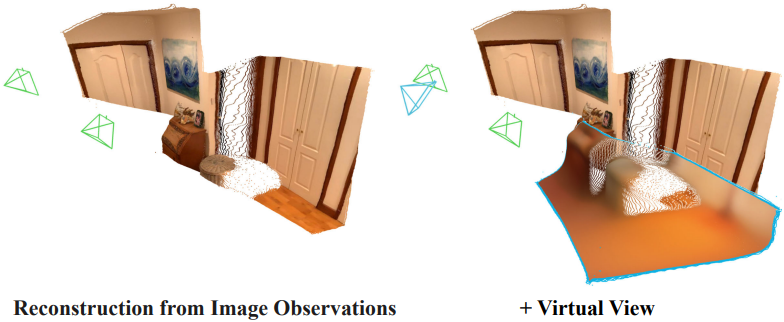
또한, CUT3R는 장면의 관찰되지 않은 부분을 추론하는 것을 지원한다. 처음 보는 가상 뷰를 raymap으로 만들고, raymap으로 내부 state를 쿼리하면 쿼리 뷰에 대한 해당 pointmap과 색상을 추출할 수 있다.
CUT3R는 일반적이고 유연하게 설계되어 광범위한 데이터셋에 대한 학습에 적합하고 다양한 추론 시나리오에 적응할 수 있다. 학습 시에는 단일 이미지, 동영상, 3D 주석이 있는 사진 컬렉션을 포함한 광범위한 3D 데이터를 활용한다. 이러한 데이터셋은 정적/동적, 실내/실외, 실제/합성과 같은 광범위한 장면 유형과 컨텍스트에 걸쳐 있어 모델이 robust하고 일반화 가능한 prior를 얻을 수 있다.
Inference 시에는 다양한 수의 이미지를 허용하고 광범위한 입력 데이터를 지원한다. 정적 장면을 넘어 동적 장면의 동영상을 원활하게 처리하여 장면의 움직이는 부분에 대한 정확한 카메라 파라미터와 dense한 포인트 클라우드를 추정한다.
Method
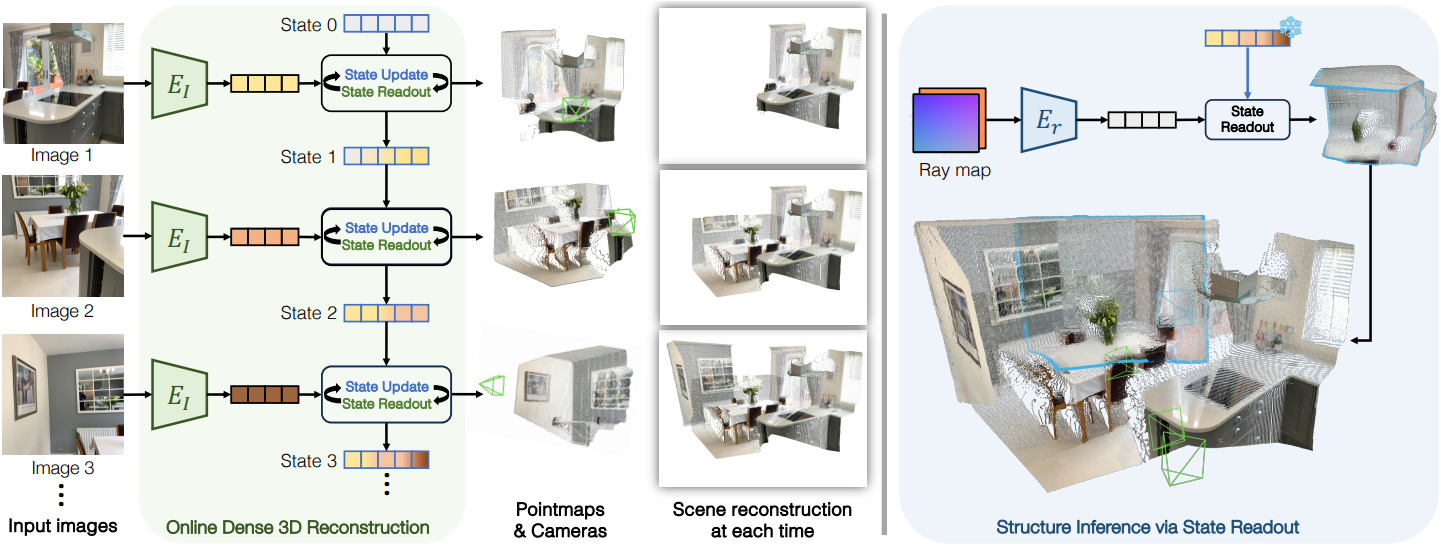
CUT3R는 카메라 정보가 없는 이미지 스트림을 입력으로 받는다. 이미지 스트림은 동영상 또는 이미지 컬렉션에서 나올 수 있다. 새 이미지가 들어오면 현재 3D 장면에 대한 이해를 인코딩하는 state 표현과 상호 작용한다. 구체적으로 이미지는 state를 새 정보로 업데이트하는 동시에 state에 저장된 정보를 검색한다. State-이미지 상호 작용에 따라 각 뷰에 대한 명시적 3D pointmap과 카메라 포즈가 추출된다. 임의의 뷰로 state를 쿼리하여 대응되는 pointmap을 예측하고 장면의 보이지 않는 부분을 캡처할 수도 있다.
1. State-Input Interaction Mechanism
CUT3R는 이미지 스트림을 입력으로 받는다. 먼저 ViT 인코더가 현재 이미지 $I_t$를 토큰 표현으로 인코딩한다.
\[\begin{equation} F_t = \textrm{Encoder}_i (I_t) \end{equation}\]State를 토큰 세트로 표현한다. 입력 이미지를 보기 전에 state 토큰은 모든 장면에서 공유하는 학습 가능한 토큰 세트로 초기화된다. 이미지 토큰은 두 가지 방식으로 state와 상호 작용한다.
- State-update: 현재 이미지의 정보로 state를 업데이트
- State-readout: 저장된 과거 정보를 통합하여 state에서 컨텍스트를 읽음
이 양방향 상호 작용은 이미지와 state 토큰 모두에서 공동으로 작동하는 두 개의 상호 연결된 transformer 디코더로 구현된다.
\[\begin{equation} [z_t^\prime, F_t^\prime], s_t = \textrm{Decoders} ([z, F_t], s_{t-1}) \end{equation}\]($s_{t-1}$과 $s_t$는 이미지 토큰과 상호 작용하기 전과 후의 state 토큰, $F_t^\prime$는 state 정보로 강화된 이미지 토큰, $z$는 학습 가능한 포즈 토큰)
디코더 내에서 양쪽의 출력은 각 디코더 블록에서 서로 교차하여 효과적인 정보 전송을 보장한다.
이 상호 작용 후, $F_t^\prime$와 $z_t^\prime$에서 명시적인 3D 표현을 추출할 수 있다. 구체적으로, 신뢰도 맵을 갖는 두 개의 pointmap \((\hat{X}_t^\textrm{self}, C_t^\textrm{self})\)와 \((\hat{X}_t^\textrm{world}, C_t^\textrm{world})\)을 예측한다. 이러한 맵은 두 개의 좌표 프레임, 즉 입력 이미지의 자체 좌표 프레임과 월드 프레임에서 각각 정의된다. 여기서 월드 프레임은 초기 이미지의 좌표 프레임으로 정의된다. 또한, 두 좌표 프레임 간의 상대적 변환인 6-DoF 포즈 \(\hat{P}_t\)를 예측한다.
\[\begin{aligned} \hat{X}_t^\textrm{self}, C_t^\textrm{self} &= \textrm{Head}_\textrm{self} (F_t^\prime) \\ \hat{X}_t^\textrm{world}, C_t^\textrm{world} &= \textrm{Head}_\textrm{world} (F_t^\prime, z_t^\prime) \\ \hat{P}_t &= \textrm{Head}_\textrm{pose} (z_t^\prime) \end{aligned}\]여기서 \(\textrm{Head}_\textrm{self}\)와 \(\textrm{Head}_\textrm{world}\)는 각각 DPT로 구현되고 \(\textrm{Head}_\textrm{pose}\)는 MLP 네트워크로 구현된다.
\(\hat{X}_t^\textrm{self}\), \(\hat{X}_t^\textrm{world}\), \(\hat{P}_t\)를 예측하는 것이 중복되는 것처럼 보일 수 있지만, 이 중복성이 학습을 간소화한다. 이를 통해 각 출력에 대해 직접 학습할 수 있으며, 부분적으로 주석이 있는 데이터셋에 대한 학습을 용이하게 하여 사용 가능한 데이터의 범위를 넓힌다.
2. Querying the State with Unseen Views
State-readout 연산을 확장하여 가상 카메라 뷰에서 장면의 보이지 않는 부분을 예측한다. 구체적으로, 가상 카메라를 쿼리로 사용하여 state에서 정보를 추출한다. 가상 카메라의 intrinsic과 extrinsic은 각 픽셀에서 광선의 원점과 방향을 인코딩하는 6채널 이미지인 raymap $R$로 표현된다.
쿼리 raymap $R$이 주어지면 먼저 별도의 transformer \(\textrm{Encoder}_r\)을 사용하여 토큰 표현 $F_r$로 인코딩한다.
\[\begin{equation} F_r = \textrm{Encoder}_r (R) \end{equation}\]그런 다음 나머지 프로세스는 위에서 설명한 내용과 크게 일치한다. 구체적으로, $F_r$을 동일한 디코더 모듈에 입력하여 현재 state와 상호 작용시키고 state에서 $F_r^\prime$을 읽는다. State-이미지 상호 작용과 달리 여기서는 raymap이 새로운 장면 콘텐츠를 도입하지 않고 쿼리로만 사용되므로 state가 업데이트되지 않는다. 마지막으로 동일한 head 네트워크를 적용하여 $F_r^\prime$을 명시적 표현으로 파싱한다. 또한 색상 정보를 디코딩하기 위해 또 다른 head \(\textrm{Head}_\textrm{color}\)를 도입한다.
\[\begin{equation} \hat{I}_r = \textrm{Head}_\textrm{color} (F_r^\prime) \end{equation}\]\(\hat{I}_r\)은 raymap $R$의 각 광선의 색상에 해당한다.
3. Training Objective
학습하는 동안 모델에 $N$개의 이미지 시퀀스를 제공한다. Raymap 모드는 metric-scale의 3D 주석이 있는 학습 데이터에 대해서만 활성화된다. 이러한 경우 특정 확률로 각 이미지를 해당 raymap으로 무작위로 대체하고 첫 번째 뷰는 제외한다. 3D 주석의 스케일을 알 수 없는 경우, raymap 쿼리가 비활성화되어 주석의 스케일과 state에 표현된 장면 스케일 간의 불일치를 방지한다.
3D regression loss
MASt3R를 따라 pointmap에 confidence-aware regression loss를 적용한다.
\[\begin{equation} \mathcal{L}_\textrm{conf} = \sum_{(\hat{x}, c) \in (\hat{\mathcal{X}}, \mathcal{C})} \left( c \cdot \| \frac{\hat{x}}{\hat{s}} - \frac{x}{s} \|_2 - \alpha \log c \right) \\ \textrm{where} \quad \hat{\mathcal{X}} = \left\{\{\hat{X}_t^\textrm{self}\}_{t=1}^N, \{\hat{X}_t^\textrm{world}\}_{t=1}^N \right\} \end{equation}\]$\hat{s}$와 $s$는 각각 $\hat{\mathcal{X}}$와 $\mathcal{X}$에 대한 scale normalization factor이다. MASt3R와 유사하게, 실제 pointmap이 metric일 때 $\hat{s} = s$로 설정하여 모델이 metric-scale의 pointmap을 학습할 수 있도록 한다.
Pose loss
포즈 \(\hat{P}_t\)를 quaternion \(\hat{q}_t\)와 translation \(\hat{\tau}_t\)로 나누고 예측과 ground-truth 사이의 L2 norm을 최소화한다.
\[\begin{equation} \mathcal{L}_\textrm{pose} = \sum_{i=1}^N \left( \| \hat{q}_t - q_t \|_2 + \| \frac{\hat{\tau}_t}{\hat{s}} - \frac{\tau_t}{s} \|_2 \right) \end{equation}\]RGB loss
입력이 raymap인 경우, 3D regression loss 외에도 MSE loss를 적용하여 예측된 픽셀 색상 \(\hat{I}_r\)이 ground-truth $I_r$과 일치하도록 한다.
\[\begin{equation} \mathcal{L}_\textrm{rgb} = \| \hat{I}_r - I_r \|_2^2 \end{equation}\]Experiments
학습에 사용한 데이터셋은 아래 표와 같다.
1. Monocular and Video Depth Estimation
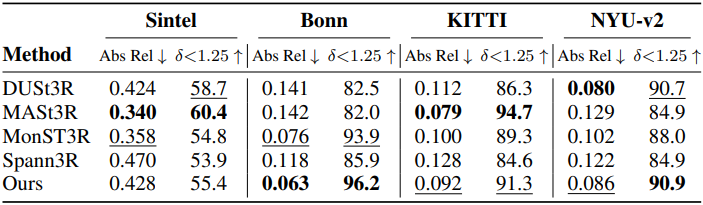
다음은 단일 프레임에 대한 깊이 추정 성능을 비교한 표이다.
다음은 동영상 깊이 추정 성능을 비교한 표이다.
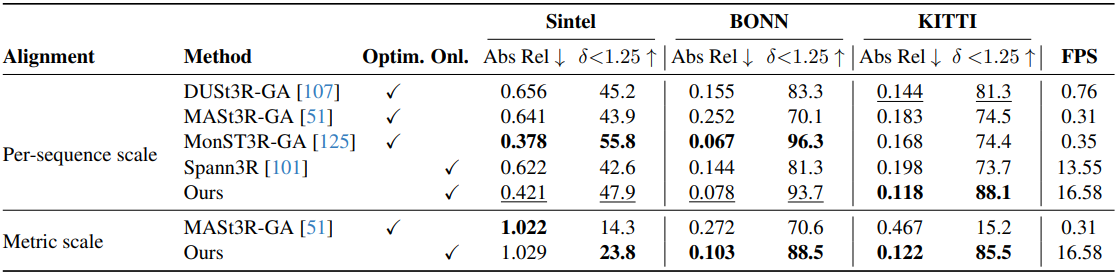
2. Camera Pose Estimation
다음은 카메라 포즈 추정 성능을 비교한 표이다.
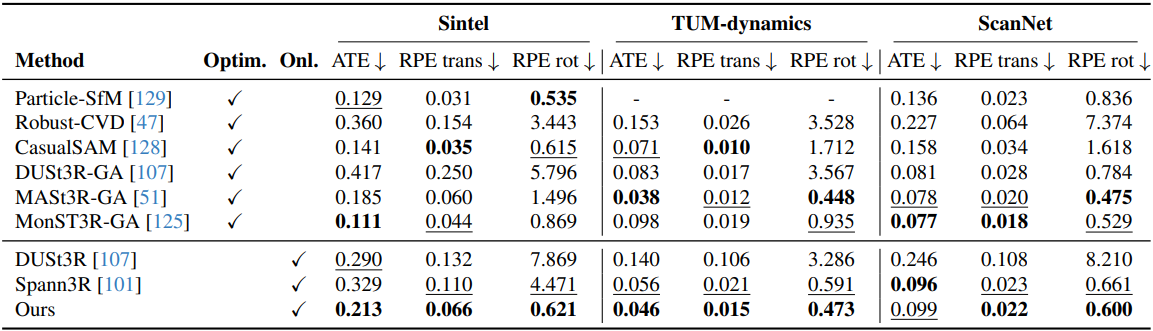
3. 3D Reconstruction
다음은 인터넷 동영상에 대한 재구성 결과를 비교한 것이다.

다음은 7-Scenes와 NRGBD에 대한 재구성 성능을 비교한 표이다.

4. Analysis
저자들은 “revisit”이라는 추가 버전의 접근 방식을 도입하였다. 이 버전은 먼저 온라인에서 CUT3R를 실행하여 모든 이미지를 본 최종 state를 얻은 다음, 이 state를 동결하고 동일한 이미지 세트를 다시 처리하여 예측을 생성하였다.
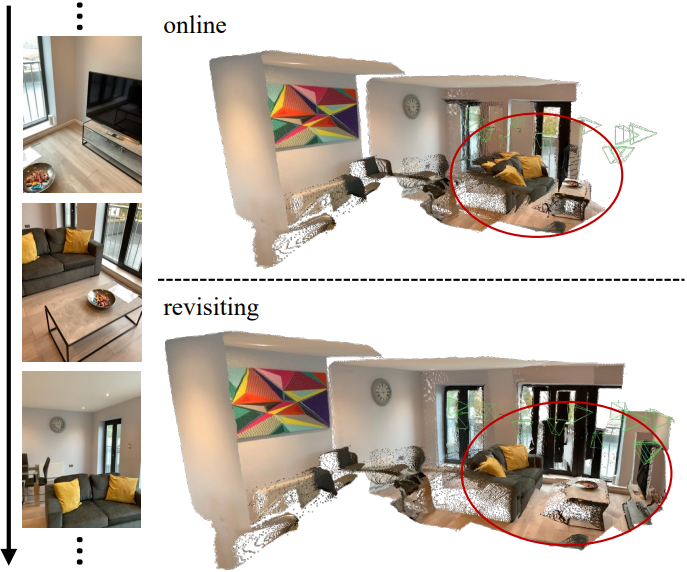
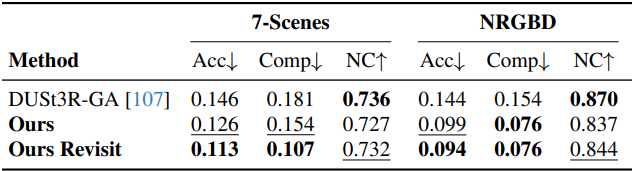
위 결과에서 볼 수 있듯이 revisit은 특히 정확도 측면에서 온라인 버전에 비해 성능이 개선되었다. 이는 state 표현이 추가 관찰을 통해 효과적으로 업데이트됨을 의미한다.
다음은 state-readout을 통해 새로운 구조를 추론한 예시이다. 위에서부터 입력 이미지, state를 쿼리하는 데 사용되는 GT 이미지 (모델에 제공되지 않음), 예측된 pointmap의 depth map, 입력 이미지만의 pointmap 예측, 예측된 pointmap과 결합된 pointmap이다.
