[논문리뷰] Language-Image Models with 3D Understanding
ICLR 2025. [Paper] [Page]
Jang Hyun Cho, Boris Ivanovic, Yulong Cao, Edward Schmerling, Yue Wang, Xinshuo Weng, Boyi Li, Yurong You, Philipp Krähenbühl, Yan Wang, Marco Pavone
UT Austin | NVIDIA Research
6 May 2024
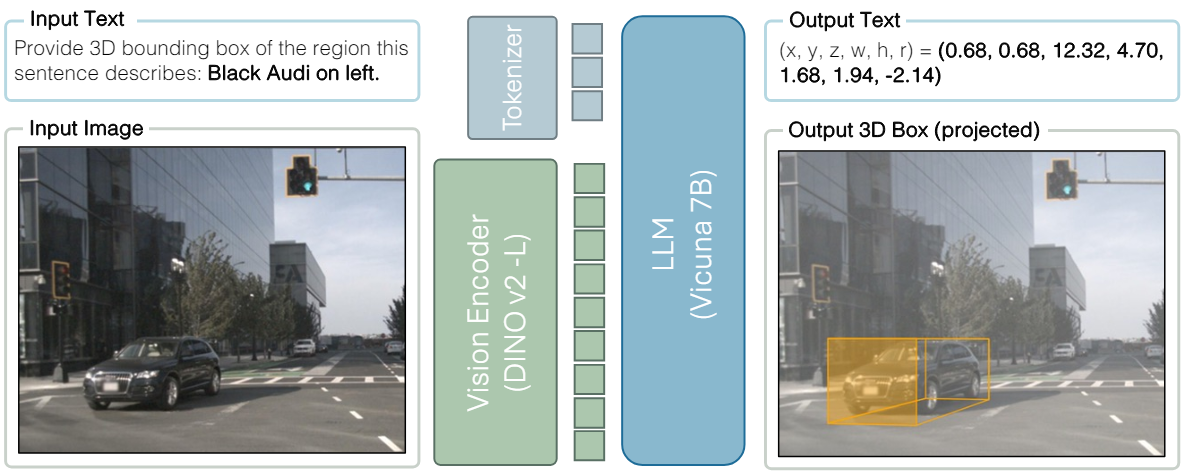
Introduction
인터넷 규모의 시각적 데이터로 인해 Large Multimodal Model (LMM)이 출현했다. 풍부하고 다양한 비전 데이터는 사전 학습된 LLM을 시각적 modality와 일치시킨다. 최고의 LMM은 특별히 설계된 아키텍처 및 알고리즘보다 이미지와 동영상을 훨씬 더 잘 인식하고 이해하고 추론할 수 있다. 방대한 비전 데이터셋은 “다음 토큰 예측” task로 공동 학습을 통해 LMM을 강화한다. 2D grounding 능력을 도입하면 시각적 입력에 대한 낮은 수준의 인식과 높은 수준의 추론이 연결된다. 그러나 인간은 세상을 3D 공간에서 인식한다. 따라서 3D grounding을 통해 LMM이 실제 세계에 더 가까운 시각적 입력에 대해 인식하고 추론할 수 있도록 할 수 있다.
grounding: 모델의 이해를 실제 세계와 연결하는 프로세스
본 논문의 목표는 2D와 3D 공간 모두에서 추론할 수 있는 LMM을 학습시키기 위한 프레임워크를 개발하는 것이다. 본 논문은 3D 전용 아키텍처 설계나 목적 함수 없이도 순수한 데이터 확장을 통해 이 목표를 달성할 수 있음을 보여준다. 저자들은 task를 2D에서 3D로 일반화하기 위해 신중한 데이터 선별에 중점을 두었으며, LV3D라고 하는 2D 및 3D용 대규모 언어-이미지 사전 학습 데이터셋을 도입하였다.
저자들은 실내 및 실외에 대한 다양한 2D 및 3D 비전 데이터셋을 결합하고 데이터셋 전체에서 일관된 형식을 따르도록 레이블을 표준화하였다. 또한 비전 데이터셋을 일련의 질문-답변 쌍으로 LMM 학습에 사용되는 instruction-following 데이터와 혼합하였다. 다음으로, 비전 레이블을 더 쉬운 task로 분해하여 혼합 데이터셋을 augment한다. 이를 통해 다양한 입출력 형식에 적응하도록 모델을 학습시키고 2D 구조와 3D 구조를 연결한다. 가장 중요한 것은 더 쉬운 task부터 어려운 task까지의 단계별 추론을 위해 객체에 대한 일련의 질문-답변 쌍을 혼합한다는 것이다. 이를 통해 LMM의 autoregressive 특성으로 2D에서 3D로의 일반화를 직접 유도한다. 마지막으로 Cube-LLM이라는 하나의 “다음 토큰 예측” task로 LV3D에서 LMM을 학습시킨다.
Cube-LLM은 여러 가지 흥미로운 속성을 보여준다.
- Cube-LLM은 자체적인 2D 예측을 통해 3D 추론 성능을 자체적으로 향상시킬 수 있다. 이러한 visual chain-of-thought 추론은 LLM의 행동과 유사하다.
- Cube-LLM은 LLM의 instruction following 능력을 따라 다양한 입출력 형식과 질문에 적응할 수 있다.
- Cube-LLM은 질문에 예측을 추가하기만 하면 다른 modality에 대한 전문 모델을 사용할 수 있다. (ex. LiDAR)
Cube-LLM은 복잡한 추론 task에 대해 2D 및 3D 모두에서 데이터 스케일링을 통해 괄목할 만한 향상을 보여주었다.
Unified Language-Image Pretraining for 2D and 3D
1. 이미지 기반 3D 추론을 위한 데이터 확장
본 논문의 목표는 사용 가능한 모든 데이터 소스에서 하나의 2D + 3D LMM을 학습시키는 것이다. 다양한 2D 및 3D grounding task를 하나로 표준화하기 위해 데이터를 표준화하고 모든 task를 “다음 토큰 예측”으로 표현하며 3D 추론을 multi-turn conversation으로 형식화하였다.
데이터 표준화
점과 박스를 2D 및 3D 추론을 위한 주요 표현으로 간주한다. 모든 레이블을 점 \(o_\textrm{point}^\textrm{2D}\) 또는 bounding box \(o_\textrm{box}^\textrm{2D}\)로 변환한다. 마찬가지로 모든 3D 레이블을 점 \(o_\textrm{point}^\textrm{3D}\) 또는 \(o_\textrm{box}^\textrm{3D}\)로 변환한다.
저자들은 먼저 Omni3D의 절차를 따라 카메라 파라미터를 통합하여 이미지 기반 3D 데이터셋을 표준화하였다. 고정 초점 거리 $f$로 가상 카메라를 정의하고 원래 카메라 파라미터와 타겟 이미지 크기에 따라 깊이 $z$를 변환한다. 모든 3D 레이블은 일관된 intrinsic으로 통합되므로 모든 $x$ 및 $y$ 좌표를 projection된 2D 좌표 $(\hat{x}, \hat{y})$로 변환할 수 있다. 결과적으로 모든 레이블 형식을 토큰 시퀀스로 표현할 수 있다.
\[\begin{aligned} o_\textrm{point}^\textrm{2D} &= [\hat{x}, \hat{y}] \\ o_\textrm{box}^\textrm{2D} &= [\hat{x}, \hat{y}, \hat{x}^\prime, \hat{y}^\prime] \\ o_\textrm{point}^\textrm{3D} &= [\hat{x}, \hat{y}, z] \\ o_\textrm{box}^\textrm{3D} &= [\hat{x}, \hat{y}, z, w, h, l, r_1, r_2, r_3] \end{aligned}\]여기서 $r_1$, $r_2$, $r_3$는 Euler angle이다. 각 값은 짧은 텍스트 토큰 시퀀스로 표시된다. 이를 통해 모델은 2D에서 3D로 토큰 시퀀스의 일관된 순서를 예측할 수 있어 기본 구조에 대한 이해가 향상된다. Autoregressive 모델을 사용하면 먼저 이미지 좌표 $(\hat{x}, \hat{y})$에서 객체의 위치를 파악한 다음 깊이 $z$를 추론하고 크기와 방향 $w$, $h$, $l$, $r_1$, $r_2$, $r_3$을 추론한다.
다단계 대화로서의 3D 추론
2D 및 3D 데이터를 VLM의 언어-이미지 명령어 튜닝 데이터와 결합한다. 각 이미지와 일련의 객체 레이블 쌍에 대해 multi-turn 대화형 질문-답변 데이터 $(\textbf{Q}_1, \textbf{A}_1, \textbf{Q}_2, \textbf{A}_2, \ldots, \textbf{Q}_n, \textbf{A}_n)$을 구성한다. 각 질문은 하나의 속성 $b_q$를 가진 객체를 참조하고 $b_a$를 물어본다.
\[\begin{equation} b_q, b_a \in \{\textrm{box}_\textrm{2D}, \textrm{caption}, \textrm{box}_\textrm{3D}\} \end{equation}\]각 객체 속성에는 사전 정의된 프롬프트 세트가 있다. 예를 들어, $b_q = \textrm{caption}$, $b_a = \textrm{box}_\textrm{3D}$인 경우
Provide the 3D bounding box of the region this sentence describes: 〈caption〈
과 같은 프롬프트가 있다. 객체의 정보(ex. 속성, 물리적 상태 등)를 클래스 이름과 결합하여 텍스트 정보를 풍부하게 한다.
2. 다양한 입출력 형식을 위한 task 확장
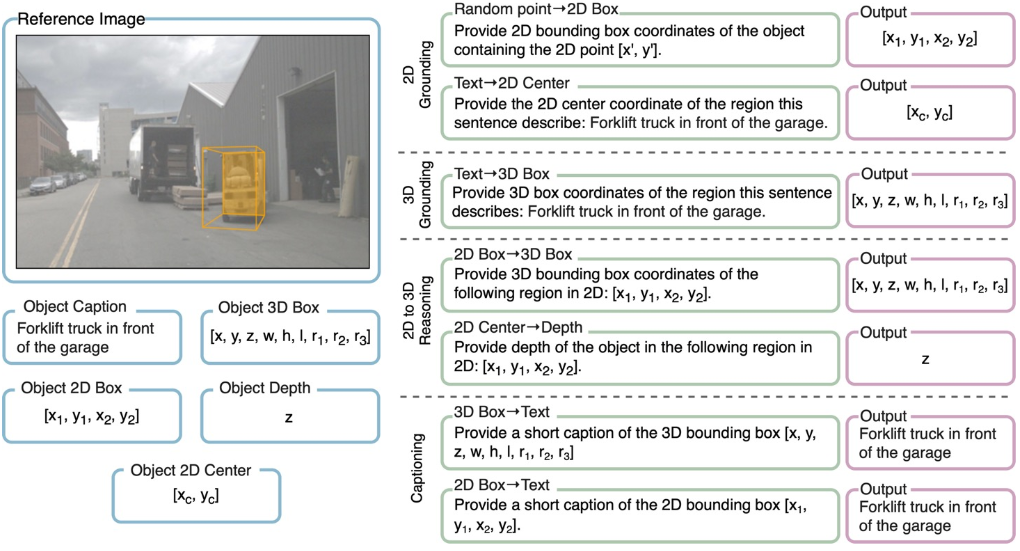
사용자는 추론 중에 비주얼 프롬프트로 2D 점이나 박스를 보완하거나 완전한 3D 위치 대신 객체의 깊이만 원할 수 있다. 이는 2D 기반 VLM의 instruction tuning과 동일하다. 이를 위해 저자들은 2D와 3D에서 더 넓은 범위의 유사한 task에 적응할 수 있도록 모델에 대한 여러 관련 task를 정의하였다. 위 그림과 같이 기존 레이블 형식을 더 쉬운 task로 분해하는 것부터 시작한다. 그런 다음 질문-답변 쌍을 구성하기 위해 객체 속성 집합을 다음과 같이 확장했다.
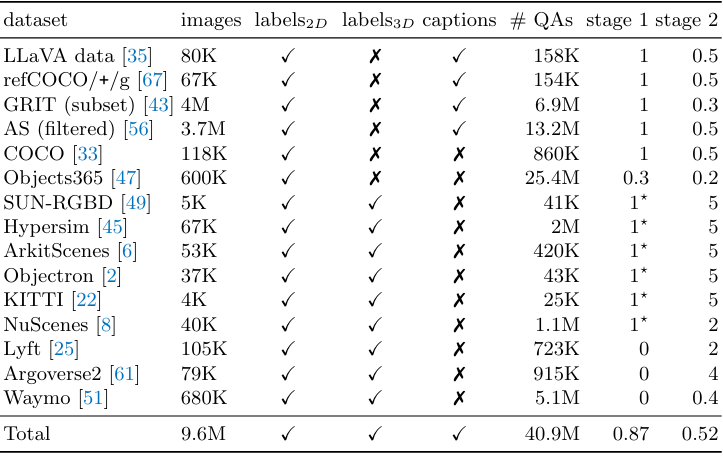
각 데이터에 대해 무작위로 샘플링된 최대 30개의 질문-답변 쌍 \((\textbf{Q}_{b_a}^{b_q}, \textbf{A}_{b_a})\)를 구성한다. 저자들은 아래 표에 요약된 2D 및 3D 비전 데이터셋의 컬렉션(LV3D)을 결합하고 이 확장된 task 집합을 공동으로 학습시킨다.
3. Visual Chain-of-Thought Prompting

LLM의 가장 흥미로운 속성 중 하나는 중간 단계를 통해 추론을 향상시키는 능력이다. 이는 주로 수많은 단계별 질문-답변 샘플과 함께 방대한 텍스트 데이터 모음에 기인한다. 저자들은 동일한 객체에 대한 여러 질문을 쉬운 순서부터 어려운 순서로 인터리브하여 3D의 단계별 추론을 인위적으로 보완하였다.
또한 후보 객체를 시스템 프롬프트로 혼합하여 모든 전문 모델에 대한 test-time 적응을 허용한다. 이를 통해 “후보 중에서 적절한 상자를 선택”하는 3D에서 localize하는 문제를 효과적으로 완화한다.
\[\begin{equation} \textrm{maximize} \; p(\textbf{A}_{\textrm{box}_\textrm{3D}} \vert \textrm{S}_{\textrm{box}_\textrm{3D}}, \textbf{Q}_{\textrm{box}_\textrm{3D}}^\textrm{caption}) \end{equation}\]여기서 \(\textrm{S}_{\textrm{box}_\textrm{3D}}\)는 추론 시 모든 전문 모델에서 제공할 수 있는 후보 박스 집합이다. 학습 중에
“Here is the list of 3D bounding boxes of all objects around the camera:”
라는 프롬프트와 함께 ground truth 박스를 사용한다. 또한 모델은 특정 전문 모델과 바인딩되지 않는다.
4. Cube-LLM
Cube-LLM은 2D와 3D 모두에서 추론하도록 학습된 LLaVA-1.5 아키텍처를 기반으로 하는 LMM이다. 원본 LLaVA에서 CLIP visual encoder를 ViT-L/14 기반의 DINOv2로 교체하고 원래 LLaVA와 동일한 정렬 단계를 거친다. DINOv2는 CLIP과 같이 텍스트와 정렬된 visual encoder는 아니지만 표준 VLM 벤치마크에서 성능 저하가 최소화되는 동시에 3D 관련 task에서 성능이 크게 향상된다. 전체 학습 과정은 다음과 같다.
- Visual encoder를 고정하고 LLaVA instruction-following 데이터와 LV3D의 2D 부분을 함께 사용하여 언어 모델인 Vicuna-7B를 fine-tuning한다.
- 이미지 해상도: 336$\times$336
- batch size: 1024
- learning rate: $2 \times 10^{-5}$
- 전체 LV3D를 사용하여 비전 모델과 언어 모델 모두에 대하여 추가로 fine-tuning을 한다. 2D의 경우 0에서 999 사이로 이미지 좌표를 정규화한다. 3D의 경우 \(X_\textrm{min}\)과 \(X_\textrm{max}\) 밖의 모든 주석을 필터링하고 0에서 999 사이로 정규화한다. 깊이는 로그 스케일을 사용한다.
- 이미지 해상도: 672$\times$672
- batch size: 256
- gradient accumulation step: 4
- learning rate: $2 \times 10^{-5}$
모든 학습은 64개의 A100 GPU에서 진행되었다고 한다.
Experiments
1. 3D-Grounded Reasoning
다음은 Talk2Car 벤치마크에서의 결과이다.
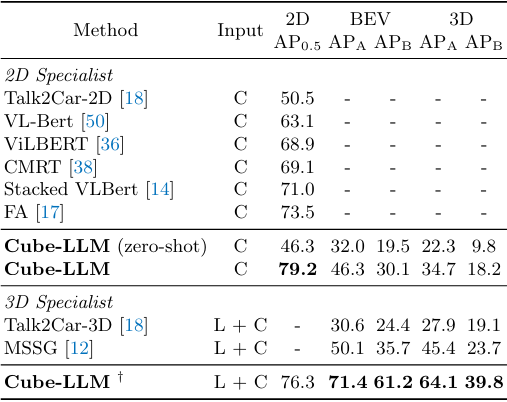
다음은 DriveLM-Grounding 벤치마크에서의 결과이다.
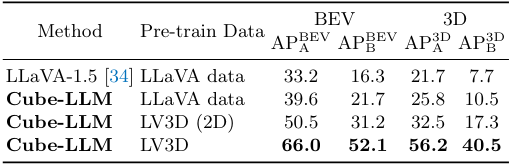
2. Complex Reasoning in 3D
다음은 실내 3D grounding 벤치마크에서의 Cube-LLM의 결과이다.

3. General LMM Benchmarks
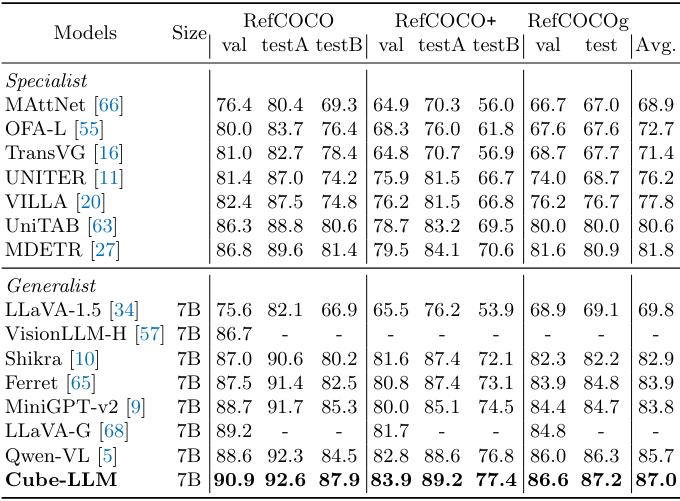
다음은 RefCOCO 벤치마크에서 다른 LMM들과 2D grounding task 성능을 비교한 표이다.
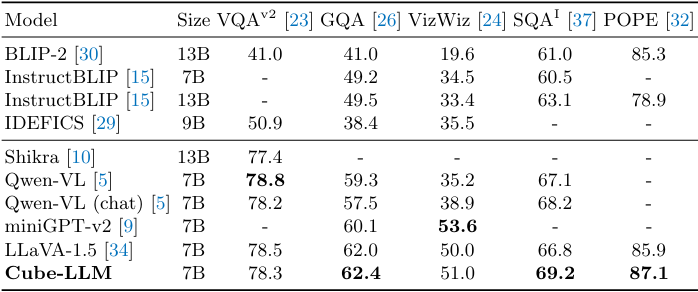
다음은 여러 VQA task들에서 다른 LMM들과 성능을 비교한 표이다.
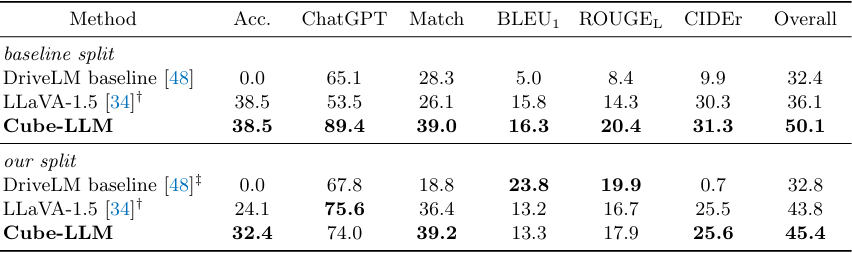
다음은 DriveLM QA 벤치마크에서 성능을 비교한 표이다.
4. Ablation Study
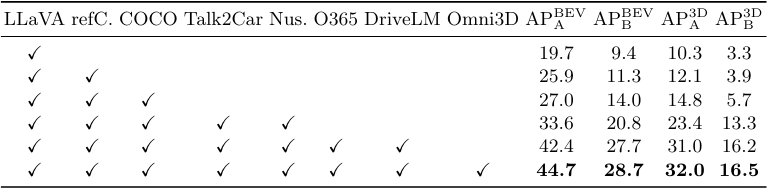
다음은 데이터 스케일링에 따른 성능을 비교한 표이다.
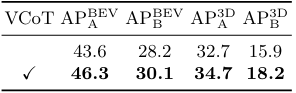
다음은 visual chain-of-thoughts (VCoT) 사용 유무에 따른 성능을 비교한 표이다.
다음은 (위) VCoT 프롬프팅과 (아래) 전문 모델을 사용한 프롬프팅의 예시이다.
