[논문리뷰] Chain-of-Thought Reasoning without Prompting
NeurIPS 2024. [Paper]
Xuezhi Wang, Denny Zhou
Google DeepMind
15 Feb 2024
Introduction
프롬프팅 기법들은 종종 task별 인간의 사전 지식을 인코딩하여 언어 모델의 내재적 추론 능력을 평가하기 어렵게 만든다. 이상적으로는 언어 모델이 독립적으로 추론하고 최적의 응답을 제공할 수 있어야 하며, 초기 응답이 만족스럽지 않은 경우 인간이 프롬프팅을 조정하거나 반복적으로 개선할 필요가 없다. 모델 튜닝은 비용이 많이 들 수 있으며 상당한 양의 학습 데이터가 필요하다.
본 논문에서는 다른 관점을 탐구하고 다음과 같은 질문을 던진다.
LLM은 프롬프팅 없이 효과적으로 추론할 수 있을까? 그리고 어느 정도 추론할 수 있을까?
놀랍게도 간단히 디코딩 절차를 변경하여 사전 학습된 LLM에서 Chain-of-Thought (CoT) 추론을 이끌어내는 task와 무관한 방법이 있다.
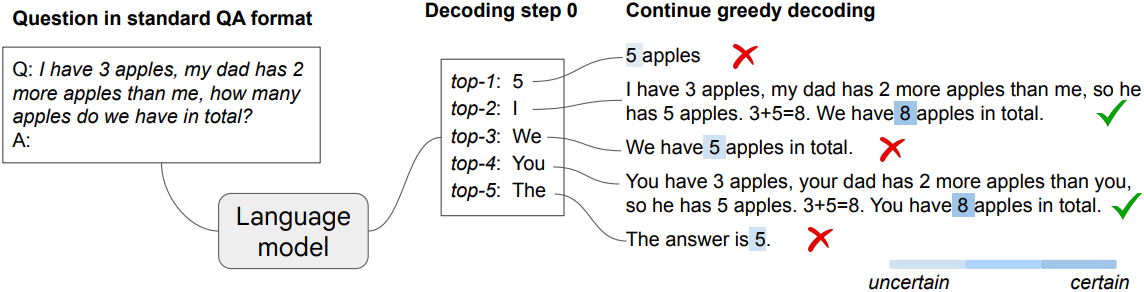
위 그림은 이러한 현상을 보여준다. 추론 질문이 주어지면 LLM은 표준 greedy decoding 경로를 통해 잘못된 답을 생성하지만, top-k 토큰 검사는 내재적인 CoT 경로를 밝혀내어 쿼리를 정확하게 해결했다. 이 디코딩 수정은 프롬프팅과 모델 튜닝 없이 완전히 unsupervised 방식으로 진행된다.
구체적으로, 표준 질문-답변(QA) 형식인 “Q:[question]\nA:”를 입력을 사용한다. 대부분의 기존 연구에서는 LLM이 이러한 직접적인 QA 시나리오에서 실패한다고 하였지만, 저자들은 LLM이 greedy decoding된 경로에만 의존할 때 추론에 어려움을 겪는다는 것을 관찰했다. 그러나 top-k 토큰 중에서 대체 경로를 고려할 때 CoT 추론 패턴은 LLM의 디코딩 궤적 내에서 자연스럽게 나타난다.
또한 저자들은 디코딩 프로세스에 CoT 추론 경로가 있을 때 최종 답에 대한 신뢰도가 높아짐을 발견했으며, 이 현상을 활용하여 top-k 디코딩을 걸러내는 방법을 개발하였다. 이를 CoT-decoding이라고 부르며, 모델 출력을 위한 가장 신뢰할 수 있는 경로를 분리한다.
Chain-of-Thought (CoT) Decoding
1. Pre-trained Language Models Can Reason without Prompting
저자들은 사전 학습된 언어 모델이 명시적 프롬프트나 인간의 개입 없이도 본질적으로 추론 능력을 가지고 있는지 조사하였다. 다음은 수학(GSM8K)과 상식적 추론(year parity)에 대한 예시 디코딩 경로이다.

저자들은 사전 학습된 PaLM-2 large 모델을 사용하여 greedy decoding 경로 $(k = 0)$와 다른 디코딩 경로 $(k > 0)$를 비교하였다. 여기서 $k$는 첫 번째 디코딩 단계에서 $k$번째 토큰의 선택을 나타낸다.
LLM은 greedy decoding 경로만 고려한다면 실제로 추론할 수 없다.
Greedy decoding을 사용하는 모델은 종종 CoT 경로를 포함하지 않고 문제를 직접 해결하기로 선택한다. 이러한 경향은 주로 간단한 질문에 대한 사전 학습으로 인해 형성된 모델의 문제 난이도에 대한 왜곡된 인식에서 비롯될 수 있다. 결과적으로 모델은 즉각적인 문제 해결에 취약하다.
LLM은 다른 디코딩 경로를 고려하면 추론할 수 있다.
첫 번째 디코딩 단계에서 상위 $k > 0$개의 토큰을 탐색할 때, 이 지점에서 greedy decoding을 계속하면 많은 경우 자연스러운 CoT 추론이 드러난다. 이러한 결과는 LLM이 사전 학습 후 수많은 task에 대한 고유한 추론 능력을 가지고 있지만, 이러한 능력은 greedy decoding의 우세한 사용으로 인해 가려져 있음을 시사한다. 이러한 추론 경로는 다른 디코딩 경로를 통합하면 쉽게 발견할 수 있다.
예를 들어, 예시의 GSM8K 문제에서 유효한 CoT는 $k = 9$에서 나타난다. 마찬가지로, year parity에서 greedy decoding은 홀짝 문제에 직접 답하려고 시도하여 짝수와 홀수 사이에서 무작위로 선택하게 되고, 이는 종종 잘못된 답으로 이어진다. 그러나 $k > 0$을 탐색할 때 모델은 자연스럽게 $k = 3$과 $k = 7$에서 CoT 경로를 생성하는데, 이 경우 홀짝 문제를 해결하기 전에 먼저 연도를 결정한다.
2. CoT-Decoding for Extracting CoT Paths
위 예시에서 볼 수 있듯이 모델의 확률 평가에서 CoT 경로가 CoT가 아닌 경로보다 일관되게 순위가 높지 않다. 게다가, 종종 모든 경로 중에서 우세한 답을 나타내지 않아 self-consistency와 같은 방법을 적용할 수 없다.
흥미롭게도 모델의 logit을 조사한 결과, CoT 경로가 있으면 일반적으로 최종 답변에 대한 보다 확실한 디코딩이 이루어지고, 상위 두 토큰 간에 상당한 확률 차이가 특징이다.
\[\begin{equation} \Delta_{k, \textrm{answer}} = \frac{1}{\vert \textrm{answer} \vert} \sum_{x_i \in \textrm{answer}} p (x_t^1 \, \vert \, x_{<t}) - p (x_t^2 \, \vert \, x_{<t}) \end{equation}\]여기서 $x_t^1$와 $x_t^2$는 $k$번째 디코딩 경로의 $t$번째 디코딩 단계에서 상위 두 토큰을 나타낸다. 전반적인 신뢰도는 모든 답변 토큰 $x_t$에 대한 이러한 확률 차이의 평균으로 근사화된다. 예를 들어, 답변이 “60”인 경우 해당 답변의 모든 토큰, 즉 “6”과 “0”에 대한 확률 차이의 평균을 구한다.
CoT-decoding이라고 하는 이 방법은 모델에서 디코딩된 경로 중에서 이러한 CoT 경로를 추출한다. 예시에서 답변 토큰은 굵게 표시되어 있으며, $\Delta$ 값은 파란색으로 표시되어 있다. CoT가 있는 경로는 CoT가 없는 경로와 달리 모델의 신뢰도가 상당히 높아지며 $\Delta$가 상당히 높다.
저자들은 GSM8K의 처음 100개 질문을 수동으로 검토하여 정량적 분석을 수행했으며, 그 결과 상위 10개 디코딩 경로 중에서 답변 신뢰도가 가장 높은 디코딩 경로를 선택하면 88%가 CoT 경로를 포함하는 것으로 나타났다. 이는 모델의 답변 신뢰도와 CoT 경로 사이에 압도적으로 높은 상관 관계가 있음을 보여준다.
다양한 CoT 경로 추출 접근 방식을 비교

위 표는 상위 10개의 디코딩된 경로에서 CoT 경로를 추출하는 다양한 방법을 비교한 것이다. 모델 자체의 확률 측정값은 신뢰할 수 있는 지표로 작용하지 않으며, 모델의 길이로 정규화된 확률도 신뢰할 수 있는 지표로 작용하지 않는다. 반면, CoT-decoding은 CoT 경로를 신뢰할 수 있게 추출하여 모델의 추론 성능을 크게 향상시킬 수 있다.
답변 범위를 식별
$\Delta$를 계산하려면 모델의 응답에서 답변 범위를 식별해야 한다. 공개 모델에 사용되는 일반적인 접근 방식 중 하나는 수학 추론 task에서 마지막 숫자 값을 추출하거나 집합 기반 추론 task에서 마지막 옵션을 답변으로 추출하는 것이다. 또는 모델의 출력을 “So the answer is”라는 프롬프트로 확장한 다음 모델의 디코딩 경로와 맞춰 답변으로 사용할 수도 있다.
표준 QA 형식에 따른 샘플링
샘플링이 비슷한 효과를 얻고 CoT 추론 경로를 밝힐 수 있을까?
저자들은 샘플링이 few-shot CoT 프롬프팅에서 잘 작동하지만 프롬프트 없이는 원하는 동작을 보이지 않는다는 것을 발견했다.

위 표는 GSM8K에서 CoT-decoding과 CoT 프롬프트를 사용하지 않은 self-consistency를 비교한 결과이다. 샘플링의 비효과성은 디코딩 중에 직접적인 답변을 제공하는 모델의 강한 경향에서 비롯되므로 첫 번째 토큰은 CoT-decoding에 비해 다양성이 적은 경향이 있다. 반면 CoT-decoding은 첫 번째 디코딩 단계에서 다양성을 명시적으로 장려하여 작동한다.
다른 디코딩 단계에서 분기
첫 번째 디코딩 단계에서만 분기하는 것과 비교하여 나중 디코딩 단계에서 분기하는 것이 좋은가?

위 그림은 후속 디코딩 단계에서 대체 토큰의 영향을 나타낸 것이다. 첫 번째 디코딩 단계에서 초기 분기가 잠재적 경로의 다양성을 크게 향상시킨다. 반대로 나중 단계 분기는 이전에 생성된 토큰의 영향을 크게 받는다. 그럼에도 불구하고 최적의 분기 지점은 task에 따라 달라질 수 있다. 예를 들어 year parity에서 중간 경로 분기는 올바른 CoT 경로를 효과적으로 생성할 수 있다.
디코딩 경로의 집계
이미 상위 $k$개의 경로를 디코딩했기 때문에 자연스러운 확장 중 하나는 self-consistency와 유사하지만 프롬프트를 사용하지 않고 모든 경로에 대한 답변을 집계하는 것이다. 이 집계의 근거는 특히 최대 $\Delta$를 가진 경로에만 의존할 때 모델의 logit에서 발생하는 작은 차이에 대한 민감도를 줄이기 위함이다.
위 예시에서 볼 수 있듯이 대부분의 답변이 정답일 가능성이 낮다. 따라서 저자들은 가중 집계 방법을 제안하였다. 즉, \(\tilde{\Delta}_a = \sum_k \Delta_{k,a}\)를 최대화하는 답변을 취한다. 여기서 \(\Delta_{k,a}\)는 답변이 $a$인 $k$번째 디코딩 경로이다. 이 방법을 채택하면 결과의 안정성이 향상된다.
Experiments
1. CoT-Decoding Effectively Elicits Reasoning from Language Models
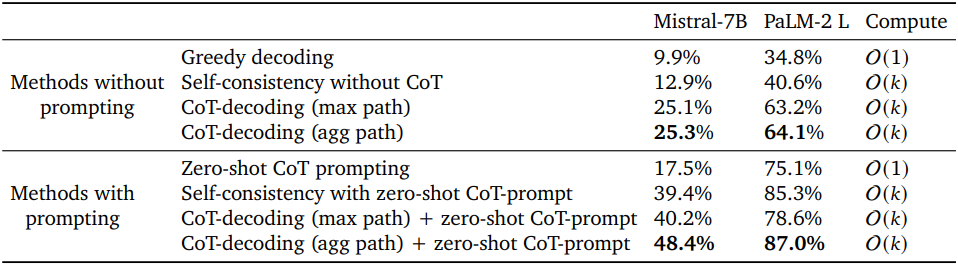
다음은 사전 학습된 Mistral-7B 모델에 대하여 여러 디코딩 방법들을 비교한 표이다.

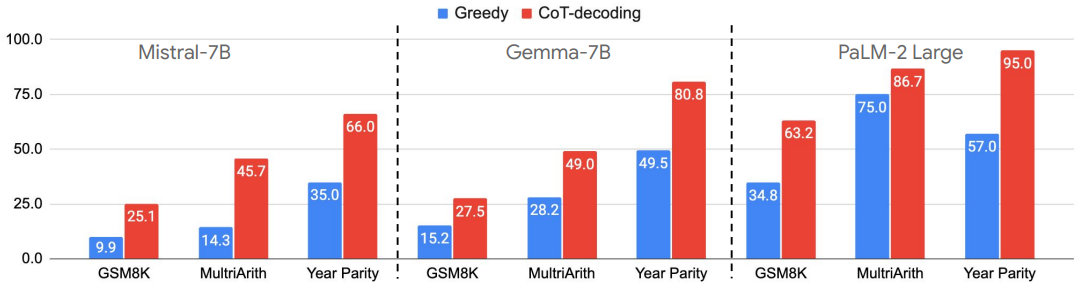
다음은 3가지 언어 모델에 대하여 greedy decoding과 CoT-decoding을 비교한 그래프이다.
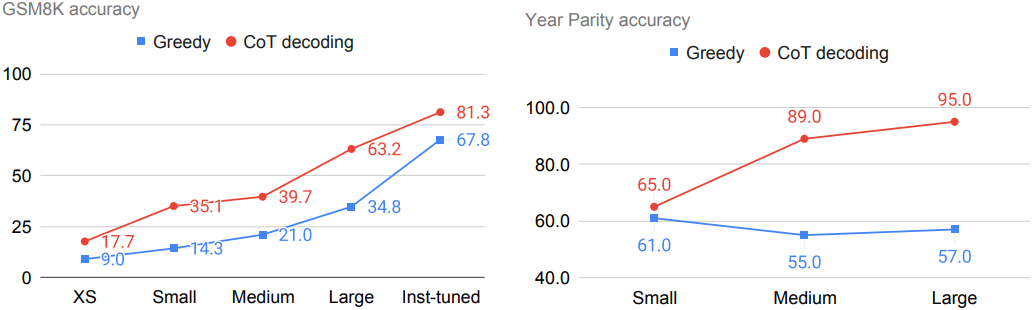
다음은 PaLM-2의 모델 크기에 따라 greedy decoding과 CoT-decoding을 비교한 그래프이다.
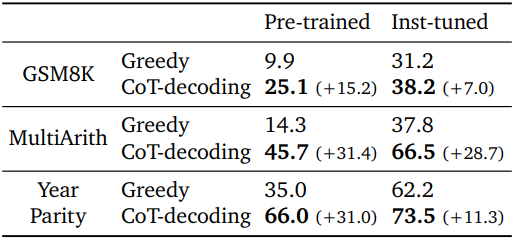
다음은 사전 학습된 모델과 instruction-tuning된 모델에 대하여 greedy decoding과 CoT-decoding을 비교한 표이다.
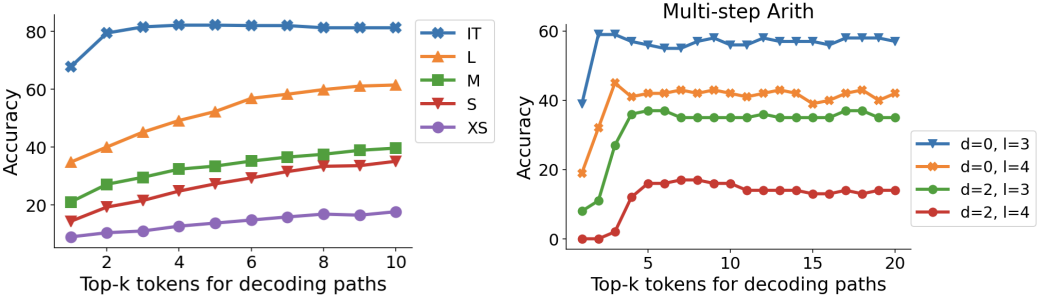
다음은 $k$가 (왼쪽) 모델 크기와 (오른쪽) task 난이도에 따른 추론 정확도에 미치는 영향을 나타낸 그래프이다.
2. CoT-decoding Enables a Better Understanding of Model’s Intrinsic Reasoning Abilities
다음은 여러 task 난이도에 대하여 greedy decoding과 CoT-decoding을 비교한 그래프이다.

3. Combining CoT-decoding with CoT-Prompting
다음은 CoT-decoding을 zero-shot CoT-prompting의 위에 더한 후 추론 성능을 비교한 표이다.