[논문리뷰] Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
NeurIPS 2022. [Paper]
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed Chi, Quoc Le, Denny Zhou
Google Research, Brain Team
28 Jan 2022
Introduction
언어 모델의 크기를 확장하면 성능과 샘플 효율성이 개선되는 등 다양한 이점이 있는 것으로 나타났다. 그러나 모델 크기를 확장하는 것만으로는 산술적, 상식적, 기호적 추론과 같은 어려운 task에서 높은 성능을 달성하기에 충분하지 않은 것으로 입증되었다.
본 논문은 두 가지 아이디어에서 동기를 얻은 간단한 방법으로 LLM의 추론 능력을 어떻게 해제할 수 있는지 연구하였다.
- 산술적 추론을 위한 기술은 최종 답으로 이어지는 자연어 근거를 생성하는 데 도움이 될 수 있다.
- 새 task에 대해 별도의 LLM을 fine-tuning하는 대신 task를 보여주는 몇 가지 입출력 예시로 모델을 간단히 “프롬프팅”할 수 있다.
그러나 위의 두 가지 아이디어는 모두 핵심적인 한계가 있다. Rationale-augmented training과 fine-tuning 방법들의 경우, 높은 품질의 이유(rationale) 세트를 대량으로 생성하는 것에 비용이 많이 들며, 이는 일반적으로 사용되는 단순한 입력-출력 쌍보다 훨씬 더 복잡하다. 기존의 few-shot prompting의 경우 추론 능력이 필요한 task에서는 효과가 좋지 않으며 언어 모델 규모가 커져도 크게 개선되지 않는 경우가 많다.
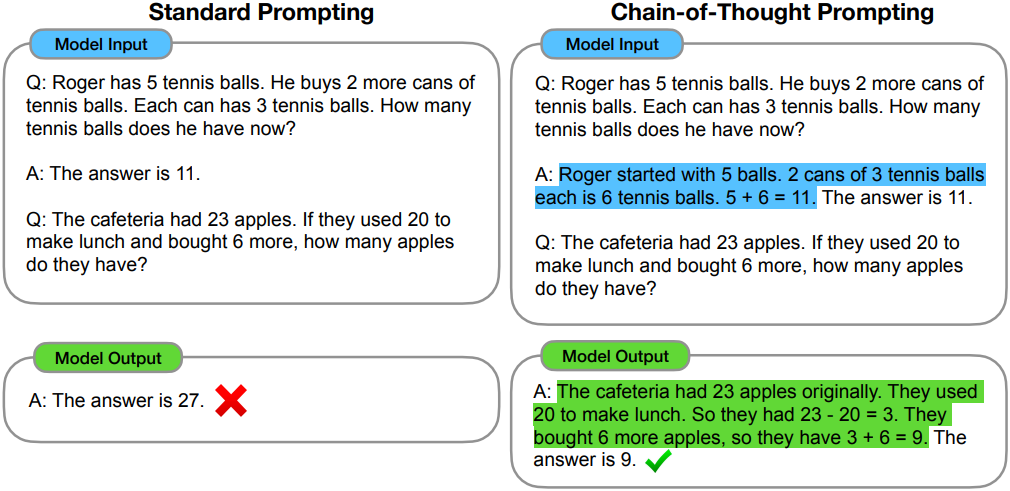
본 논문에서는 이 두 가지 아이디어의 장점을 결합하여 한계를 피하였다. 구체적으로, 언어 모델이 추론 task에 few-shot prompting을 수행하는 능력을 탐구한다. 이 프롬프트는 (입력, chain-of-thought, 출력)의 triplet으로 구성된다. Chain-of-thought은 최종 출력으로 이어지는 일련의 중간 추론 단계이며, 이 접근 방식을 chain-of-thought prompting이라고 한다.
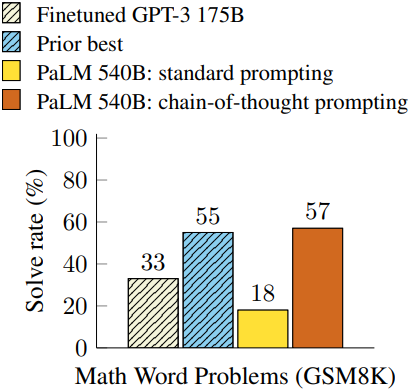
저자들은 산술적, 상식적, 기호적 추론 벤치마크에 대하여 chain-of-thought를 평가하였다. Chain-of-thought prompting은 표준 프롬프팅보다 성능이 뛰어나며, 때로는 놀라울 정도로 뛰어나다. GSM8K 벤치마크에서 PaLM 540B를 사용한 chain-of-thought prompting은 새로운 SOTA 성능을 달성하였다. 프롬프트 전용 접근 방식은 대규모 학습 데이터셋이 필요하지 않고 하나의 학습된 모델에서 많은 task를 수행할 수 있기 때문에 중요하다.
Chain-of-Thought Prompting
복잡한 추론을 해야할 때 문제를 중간 단계로 분해하여 각각을 풀고 최종 답을 내는 것이 일반적이다. 본 논문의 목표는 언어 모델에 유사한 사고의 사슬을 생성할 수 있는 능력을 부여하는 것이다. 즉, 모델은 최종 답으로 이어지는 일관된 일련의 중간 추론 단계를 생성해야 한다.
Chain-of-thought prompting은 언어 모델에서 추론을 용이하게 하는 접근법으로서 여러 가지 매력적인 속성을 갖고 있다.
- Chain-of-thought은 모델이 여러 단계 문제를 중간 단계로 분해할 수 있게 하며, 이는 더 많은 추론 단계가 필요한 문제에 추가 계산을 할당할 수 있다는 것을 의미한다.
- Chain-of-thought은 모델의 행동에 대한 해석 가능한 창을 제공하여 특정 답에 도달한 방식을 제안하고 추론 경로가 잘못된 곳을 디버깅할 수 있는 기회를 제공한다.
- Chain-of-thought 추론은 수학 문제, 상식적 추론, 기호 조작과 같은 task에 사용될 수 있으며, 이론적으로는 인간이 언어를 통해 해결할 수 있는 모든 task에 잠재적으로 적용될 수 있다.
- 몇 개의 간단한 프롬프트 예시에 chain-of-thought 시퀀스를 포함시키는 것만으로 학습이 끝난 LLM에서 chain-of-thought 추론을 쉽게 이끌어낼 수 있다.
Experiments
다음은 산술적, 상식적, 기호적 추론을 위한 (입력, chain-of-thought, 출력) triplet의 예시이다.

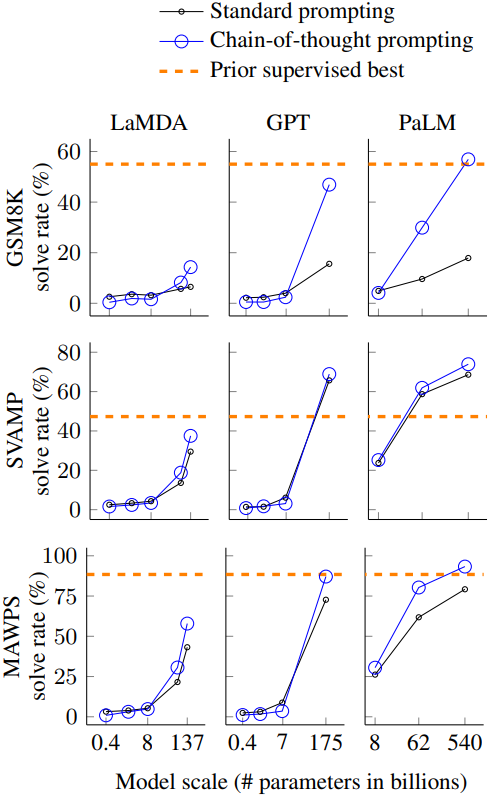
1. Arithmetic Reasoning
- 벤치마크: GSM8K. SVAMP, ASDiv, AQuA, MAWPS
다음은 모델 크기에 따른 산술적 추론 성능을 비교한 그래프이다.
다음은 (왼쪽) 프롬프팅 방법과 (오른쪽) 프롬프트 예시에 따른 성능을 비교한 그래프이다.
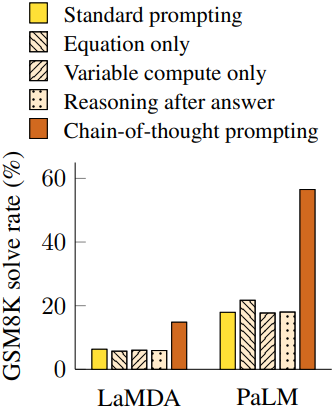
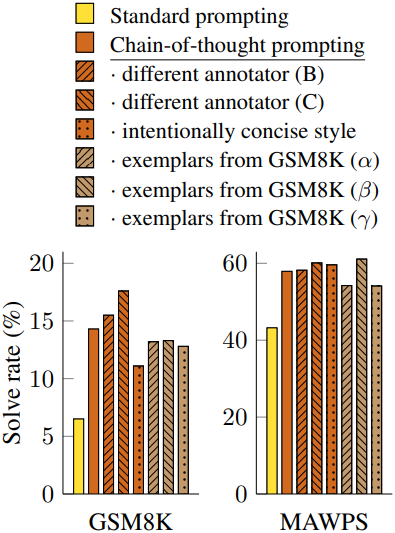
2. Commonsense Reasoning
- 벤치마크
- CSQA: 사전 지식이 필요한 복잡한 의미를 포함하는 세상에 대한 상식적인 질문
- StrategyQA: 모델이 질문에 답하기 위해 다양한 맥락 간의 논리적 연결을 만드는 multi-hop 전략을 추론하도록 요구
- BIG-bench
- Date Understanding: 주어진 맥락에서 날짜를 추론
- Sports Understanding: 스포츠와 관련된 문장이 타당한지 타당하지 않은지 판단
- SayCan: 자연어 명령을 discrete한 집합에서 로봇 동작 시퀀스에 매핑
다음은 모델 크기에 따른 상식적 추론 성능을 비교한 그래프이다.
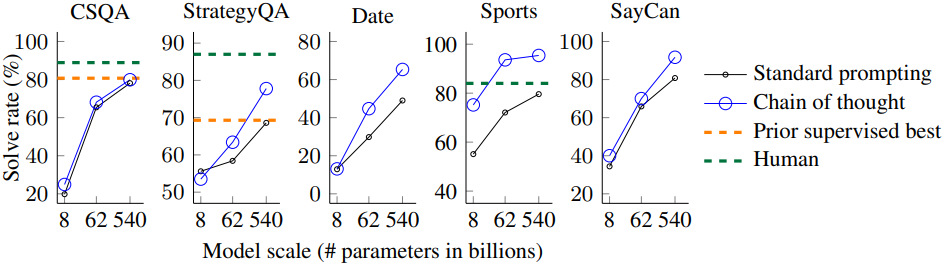
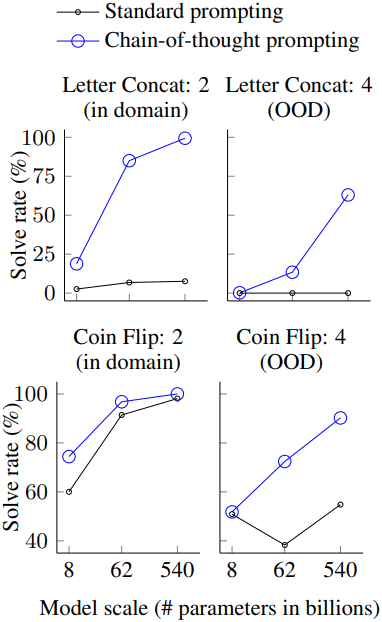
3. Symbolic Reasoning
- Tasks
- Last letter concatenation: 단어들의 끝 문자만 모아서 출력하는 task
- Coin flip: 동전의 초기 상태와 몇 번 뒤집어졌는지 정보를 준 뒤, 마지막 동전의 상태를 맞추는 task
다음은 모델 크기에 따른 기호적 추론 성능을 비교한 그래프이다.