[논문리뷰] ConvNeXt V2: Co-designing and Scaling ConvNets with Masked Autoencoders
CVPR 2023. [Paper] [Github]
Sanghyun Woo, Shoubhik Debnath, Ronghang Hu, Xinlei Chen, Zhuang Liu, In So Kweon, Saining Xie
KAIST | Meta AI, FAIR | New York University
2 Jan 2023
Introduction
지난 수십 년 동안의 연구 혁신을 바탕으로 시각적 인식 분야는 대규모 시각적 표현 학습의 새로운 시대를 열었다. 사전 학습된 대규모 비전 모델은 feature 학습과 광범위한 비전 애플리케이션을 위한 필수 도구가 되었다. 시각적 표현 학습 시스템의 성능은 선택한 신경망 아키텍처, 네트워크 학습에 사용되는 방법, 학습에 사용되는 데이터라는 세 가지 주요 요소에 의해 크게 영향을 받는다. 시각 인식 분야에서는 이러한 각 영역의 발전이 전반적인 성능 향상에 기여하였다.
신경망 아키텍처 설계의 혁신은 표현 학습 분야에서 지속적으로 중요한 역할을 해왔다. ConvNet(CNN)은 수동 feature 엔지니어링에 의존하기보다는 다양한 시각적 인식 task에 대한 일반적인 feature 학습 방법을 사용할 수 있도록 함으로써 컴퓨터 비전 연구에 상당한 영향을 미쳤다. 최근에는 원래 자연어 처리를 위해 개발된 transformer 아키텍처도 모델과 데이터셋 크기에 대한 강력한 확장 가능성으로 인해 인기를 얻었다. 최근에는 ConvNeXt 아키텍처가 기존 ConvNet을 현대화했으며 순수 convolutional model도 확장 가능한 아키텍처가 될 수 있음을 보여주었다. 그러나 신경망 아키텍처의 디자인을 탐색하는 가장 일반적인 방법은 여전히 ImageNet에서 supervised learning 성능을 벤치마킹하는 것이다.
시각적 표현 학습의 초점은 레이블을 사용한 supervised learning에서 pretext 목적 함수를 사용한 self-supervised 사전 학습으로 이동하고 있다. 다양한 self-supervised 알고리즘 중에서 masked autoencoder (MAE)는 최근 비전 도메인에서 masked language modeling의 성공을 가져왔고 빠르게 시각적 표현 학습을 위한 대중적인 접근 방식이 되었다. 그러나 self-supervised learning의 일반적인 관행은 supervised learning을 위해 설계된 미리 정의된 아키텍처를 사용하고 설계가 고정되어 있다고 가정하는 것이다. 예를 들어 MAE는 ViT 아키텍처를 사용하여 개발되었다.
아키텍처의 설계 요소와 self-supervised learning 프레임워크를 결합하는 것은 가능하지만 그렇게 하면 MAE와 함께 ConvNeXt를 사용할 때 문제가 발생할 수 있다. 한 가지 문제는 MAE가 transformer의 시퀀스 처리 능력에 최적화된 특정 인코더-디코더 디자인을 가지고 있다는 것이다. 이를 통해 계산량이 많은 인코더는 눈에 보이는 패치에 집중하여 사전 학습 비용을 줄일 수 있다. 이 디자인은 dense sliding window를 사용하는 표준 ConvNet과 호환되지 않을 수 있다. 또한 아키텍처와 목적 함수 간의 관계를 고려하지 않으면 최적의 성능을 달성할 수 있는지 여부가 불분명할 수 있다. 실제로 이전 연구에서는 마스크 기반 self-supervised learning으로 ConvNet을 학습하는 것이 어려울 수 있음을 보여 주었고, 경험적 증거에 따르면 transformer와 ConvNet은 표현 품질에 영향을 줄 수 있는 서로 다른 feature 학습 동작을 가질 수 있음이 나타났다.
이 문제를 해결하기 위해 본 논문은 ConvNeXt 모델에 마스크 기반 self-supervised learning을 효과적으로 만들고 transformer를 사용하여 얻은 결과와 유사한 결과를 달성하기 위해 동일한 프레임워크에서 네트워크 아키텍처와 MAE를 공동 설계할 것을 제안한다.
MAE를 설계할 때 마스킹된 입력을 sparse 패치 세트로 처리하고 sparse convolution을 사용하여 보이는 부분만 처리한다. 이 아이디어는 대규모 3D 포인트 클라우드를 처리할 때 sparse convolution을 사용하는 것에서 영감을 얻었다. 실제로는 sparse convolution을 사용하여 ConvNeXt를 구현할 수 있으며 fine-tuning 시 특별한 처리 없이 가중치가 표준 dense layer로 다시 변환된다. 사전 학습 효율성을 더욱 향상시키기 위해 transformer 디코더를 단일 ConvNeXt 블록으로 대체하여 전체 디자인을 fully convolutional로 만든다. 이러한 변경으로 인해 혼합된 결과가 관찰되었다. 학습된 feature는 유용하고 기본 결과를 개선하지만 fine-tuning 성능은 여전히 transformer 기반 모델만큼 좋지 않다.
그런 다음 저자들은 ConvNeXt에 대한 다양한 학습 구성의 feature space 분석을 수행하였다. 저자들은 마스킹된 입력에서 ConvNeXt를 직접 학습할 때 MLP layer에서 feature collapse의 잠재적인 문제를 발견하였다. 이 문제를 해결하기 위해 저자들은 채널 간 feature 경쟁을 강화하기 위해 Global Response Normalization (GRN) layer를 추가할 것을 제안하였다. 이 변화는 모델이 MAE로 사전 학습될 때 가장 효과적이다. 이는 supervised learning의 고정 아키텍처 디자인을 재사용하는 것이 최선이 아닐 수 있음을 시사한다.
Fully Convolutional Masked Autoencoder
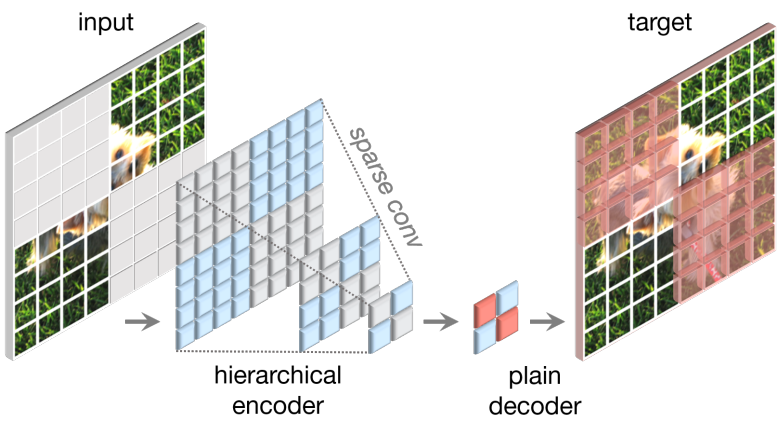
본 논문의 접근 방식은 개념적으로 간단하며 fully convolution으로 실행된다. 학습 신호는 입력 이미지를 높은 마스킹 비율로 무작위로 마스킹하고 모델이 나머지 컨텍스트를 고려하여 누락된 부분을 예측하도록 하여 생성된다. 본 논문의 프레임워크는 위 그림에 나와 있다.
Masking
저자들은 마스킹 비율이 0.6인 무작위 마스킹 전략을 사용하였다. Convolutional model은 feature가 여러 단계에서 다운샘플링되는 계층적 디자인을 가지므로 마스크는 마지막 단계에서 생성되고 가장 좋은 해상도까지 재귀적으로 업샘플링된다. 이를 실제로 구현하기 위해 원본 입력 이미지에서 32$\times$32 패치 중 60%를 무작위로 제거한다. Random resized cropping만 포함하여 최소한의 data augmentation을 사용한다.
Encoder design
인코더로 ConvNeXt 모델을 사용한다. Masked image modeling을 효과적으로 만드는 데 있어 한 가지 과제는 모델이 마스킹된 영역에서 정보를 복사하여 붙여넣을 수 있는 shortcut을 학습하지 못하게 하는 것이다. 이는 transformer 기반 모델에서 방지하기가 비교적 쉽다. 이로 인해 눈에 보이는 패치가 인코더에 대한 유일한 입력으로 남을 수 있다. 그러나 2D 이미지 구조가 보존되어야 하기 때문에 ConvNet을 사용하면 이를 달성하기가 더 어렵다. 순진하게 입력 측에 학습 가능한 마스크 토큰을 도입할 수도 있지만 이러한 접근 방식은 사전 학습의 효율성을 감소시키고 테스트 시 마스크 토큰이 없기 때문에 학습-테스트 불일치를 초래한다. 이는 마스킹 비율이 높을 때 특히 문제가 된다.
이 문제를 해결하기 위한 새로운 통찰력은 sparse 포인트 클라우드 학습에서 영감을 얻은 “sparse 데이터 관점”에서 마스킹된 이미지를 보는 것이다. 저자들의 주요 관찰은 마스킹된 이미지가 2D sparse 픽셀 배열로 표현될 수 있다는 것이다. 이러한 통찰력을 바탕으로 MAE의 사전 학습을 용이하게 하기 위해 sparse convolution을 프레임워크에 통합하는 것이 당연하다. 실제로 저자들은 사전 학습 중에 모델이 눈에 보이는 데이터 포인트에서만 작동할 수 있도록 하는 submanifold sparse convolution을 사용하여 인코더의 convolution layer을 변환할 것을 제안한다. Sparse convolution layer는 추가 처리 없이 fine-tuning 단계에서 표준 convolution으로 다시 변환될 수 있다. 대안으로, dense convolution 연산 전후에 이진 마스킹 연산을 적용하는 것도 가능하다. 이 연산은 수치적으로 sparse convolution과 동일한 효과를 가지며 이론적으로 계산 집약적이지만 TPU와 같은 AI 가속기에서는 더 친숙할 수 있다.
Decoder design

디코더로 경량의 일반 ConvNeXt 블록을 사용한다. 인코더가 더 무겁고 계층적 구조를 갖기 때문에 이는 전체적으로 비대칭 인코더-디코더 아키텍처를 형성한다. 또한 계층적 디코더 또는 transformer와 같은 더 복잡한 디코더를 고려했지만 위 표에 설명된 것처럼 더 간단한 단일 ConvNeXt 블록 디코더는 fine-tuning 정확도 측면에서 좋은 성능을 발휘하고 사전 학습 시간을 상당히 줄였다. 저자들은 디코더의 차원을 512로 설정했다.
Reconstruction target
재구성된 이미지와 타겟 이미지 간의 평균 제곱 오차 (MSE)를 계산한다. MAE와 마찬가지로 타겟은 원래 입력의 패치별 정규화된 이미지이며 loss는 마스킹된 패치에만 적용된다.
FCMAE
본 논문은 위의 제안들을 결합하여 Fully Convolutional Masked AutoEncoder (FCMAE)를 제시하였다. 저자들은 이 프레임워크의 효율성을 평가하기 위해 ConvNeXt-Base 모델을 인코더로 사용하고 일련의 ablation study를 수행하였다. Transfer learning의 실질적인 관련성 때문에 end-to-end fine-tuning 성능에 중점을 두고 이를 사용하여 학습된 표현의 품질을 평가하였다.
저자들은 ImageNet-1K (IN1K) 데이터셋을 사용하여 각각 800 epoch와 100 epoch에 대해 사전 학습과 fine-tuning을 수행하고 하나의 224$\times$224 center crop에 대한 top-1 IN-1K 검증 정확도를 평가하였다.
FCMAE 프레임워크에서 sparse convolution 사용의 영향을 이해하기 위해 먼저 마스킹된 이미지 사전 학습 중에 학습된 표현의 품질에 어떤 영향을 미치는지 조사하였다.
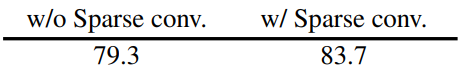
그 결과는 위 표와 같으며, 좋은 결과를 얻기 위해서는 마스킹 영역에서 정보 유출을 방지하는 것이 필수적이라는 것을 보여준다.
다음으로, self-supervised 방식과 supervised 학습을 비교하였다. 구체적으로, 저자들은 동일한 방법을 사용하여 supervise된 100 epoch baseline의 결과와 원래 ConvNeXt 논문에 제공된 300 epoch supervised baseline의 결과를 얻었다.
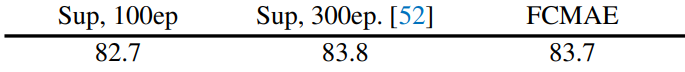
이를 FCMAE와 비교한 결과는 위 표와 같다. FCMAE 사전 학습은 random baseline보다 더 나은 초기화를 제공하지만 (82.7 → 83.7) 여전히 원래 supervised 설정에서 얻은 최고의 성능을 따라잡아야 한다. 이는 사전 학습된 모델이 supervised 모델보다 훨씬 뛰어난 성능을 보이는 transformer 기반 모델을 사용한 masked image modeling의 최근 성공과는 대조적이다. 이는 MAE 사전 학습 중에 ConvNeXt 인코더가 직면한 고유한 문제를 조사하도록 동기를 부여한다.
Global Response Normalization
Feature collapse

저자들은 학습에 대한 더 많은 통찰력을 얻기 위해 먼저 feature space에서 정성적 분석을 수행하였다. 저자들은 FCMAE로 사전 학습된 ConvNeXt-Base 모델의 activation을 시각화하고 흥미로운 “feature collapse” 현상을 발견했다. 즉, 죽거나 포화된 feature map이 많고 activation이 채널 전체에서 중복된다. 위 그림에는 시각화 중 일부가 나와 있다. 이 동작은 주로 ConvNeXt 블록의 차원 확장 MLP layer에서 관찰되었다.
Feature 코사인 거리 분석
저자들은 관찰 결과를 정량적으로 더욱 검증하기 위해 feature 코사인 거리 분석을 수행하였다. Activation 텐서 $X \in \mathbb{R}^{H \times W \times C}$가 주어지면 $X_i \in \mathbb{R}^{H \times W}$는 $i$번째 채널의 feature map이다. 이를 $HW$ 차원 벡터로 reshape하고 채널 전체의 평균 쌍별 코사인 거리를 계산하였다.
\[\begin{equation} \frac{1}{C^2} \sum_i^C \sum_j^C \frac{1 - \cos (X_i, X_j)}{2} \end{equation}\]거리 값이 높을수록 feature가 더 다양하다는 것을 나타내고 값이 낮을수록 feature 중복을 나타낸다.
이 분석을 수행하기 위해 ImageNet-1K validation set의 다양한 클래스에서 1,000개의 이미지를 무작위로 선택하고 FCMAE 모델, ConvNeXt supervised 모델, MAE로 사전 학습된 ViT 모델을 포함한 다양한 모델의 각 레이어에서 고차원 feature를 추출하였다. 그런 다음 각 이미지의 레이어당 거리를 계산하고 모든 이미지의 값을 평균화하였다.
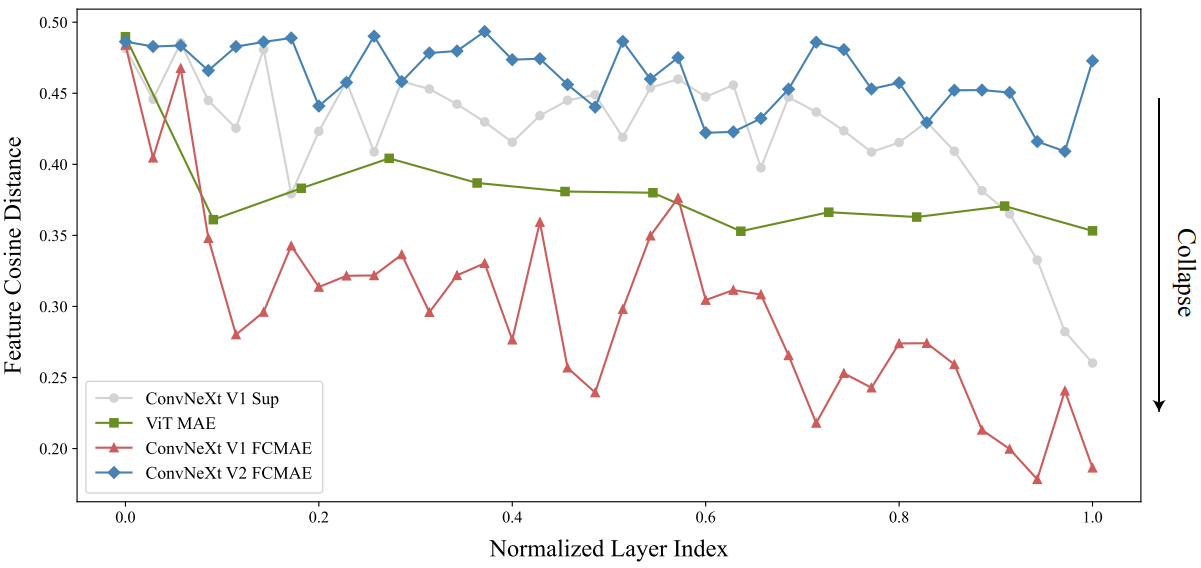
결과는 위 그림에 표시되어 있다. FCMAE로 사전 학습된 ConvNeXt 모델은 이전 activation 시각화의 관찰과 일치하여 feature collapse에 대한 명확한 경향을 나타낸다. 이는 학습 중에 feature를 다양화하고 feature collapse를 방지하는 방법을 고려하도록 동기를 부여한다.
접근 방식
뇌에는 뉴런의 다양성을 촉진하는 많은 메커니즘이 있다. 예를 들어, 측면 억제 (lateral inhibition)는 활성화된 뉴런의 반응을 선명하게 하고 자극에 대한 개별 뉴런의 대비와 선택성을 높이는 동시에 뉴런 집단 전체에 걸쳐 반응의 다양성을 증가시키는 데 도움이 될 수 있다. 딥러닝에서는 이러한 형태의 측면 억제가 반응 정규화를 통해 구현될 수 있다. 이 연구에서는 채널의 대비와 선택성을 높이는 것을 목표로 하는 global response normalization (GRN)라는 새로운 응답 정규화 레이어를 도입한다. 입력 feature $X \in \mathbb{R}^{H \times W \times C}$가 주어지면 제안된 GRN unit 세 단계로 구성된다.
- global feature aggregation
- feature normalization
- feature calibration
먼저, 글로벌 함수 $\mathcal{G}(\cdot)$를 사용하여 공간 feature map $X_i$를 벡터 $gx$로 집계한다.
\[\begin{equation} \mathcal{G} (X) := X \in \mathbb{R}^{H \times W \times C} \mapsto gx \in \mathbb{R}^C \end{equation}\]이는 단순한 pooling layer로 볼 수 있다.

위 표는 다양한 함수들에 대한 실험 결과이다. 흥미롭게도 널리 사용되는 feature aggregator인 global average pooling은 제대로 수행되지 않았다. 대신, norm 기반 feature 집계, 특히 L2-norm을 사용하면 성능이 더 좋아진다는 사실을 발견했다. 이는 집계된 값 집합
를 제공한다. 여기서 $\mathcal{G}(X)_i = | X_i |$는 $i$번째 채널의 통계를 집계하는 스칼라이다.
다음으로, 집계된 값에 응답 정규화 함수 $\mathcal{N}(\cdot)$을 적용한다. 구체적으로, 다음과 같이 표준 분할 정규화를 사용한다.
\[\begin{equation} \mathcal{N} (\| X_i \|) := \| X_i \| \in \mathbb{R} \mapsto \frac{\| X_i \|}{\sum_{j=1}^C \| X_j \|} \in \mathbb{R} \end{equation}\]어디에서 $| X_i |$는 $i$번째 채널의 L2-norm이다. 직관적으로 $i$번째 채널에 대해 위 식은 다른 모든 채널과 비교하여 상대적 중요성을 계산한다. 다른 형태의 정규화와 유사하게 이 단계는 상호 억제를 통해 채널 간 feature 경쟁을 만든다.
위 표는 다른 정규화 함수에 대한 실험 결과이다. 단순한 분할 정규화가 가장 잘 작동하지만 표준화 $(| X_i | − \mu) / \sigma$는 동일한 L2-norm 집계 값에 적용할 때 유사한 결과를 생성한다.
마지막으로 계산된 feature 정규화 점수를 사용하여 원래 입력 응답을 보정한다.
\[\begin{equation} X_i = X_i \cdot \mathcal{N}(\mathcal{G} (X)_i) \in \mathbb{R}^{H \times W} \end{equation}\]핵심 GRN unit은 구현하기가 매우 쉽고 코드 세 줄만 필요하며 학습 가능한 파라미터가 없다. GRN unit의 pseudo-code는 Algorithm 1에 있다.

최적화를 쉽게 하기 위해 두 개의 추가 학습 가능한 파라미터인 $\gamma$와 $\beta$를 추가하고 이를 0으로 초기화한다. 또한 GRN 레이어의 입력과 출력 사이에 residual connection을 추가한다. 최종 GRN 블록은
이다. 이 설정을 통해 GRN 레이어는 초기에 항등 함수이고 학습 중에 점진적으로 적응할 수 있다. Residual connection의 중요성은 아래 표에 나와 있다.
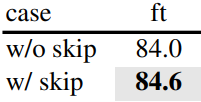
ConvNeXt V2
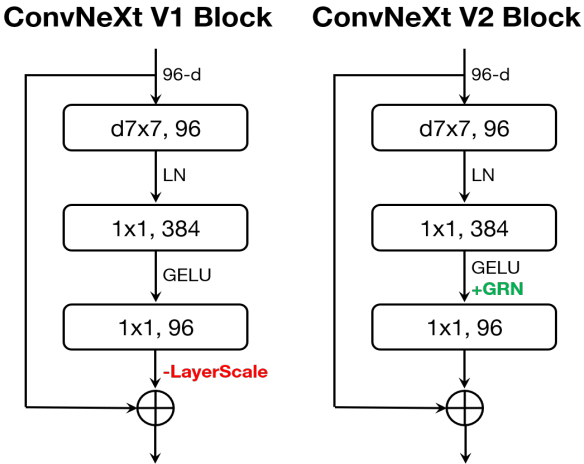
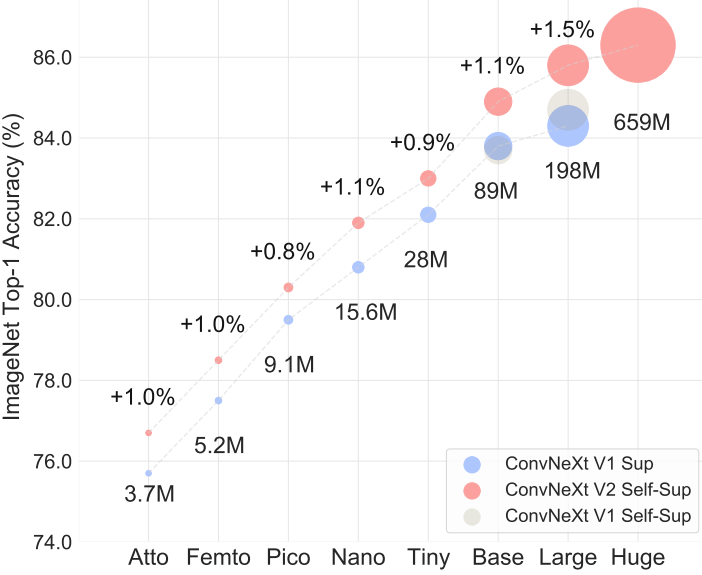
위 그림과 같이 GRN 레이어를 원본 ConvNeXt 블록에 통합한다. 저자들은 GRN을 적용하면 LayerScale이 불필요해지고 제거될 수 있다는 것을 경험적으로 발견했다. 이 새로운 블록 디자인을 사용하여 ConvNeXt V2라고 하는 다양한 효율성과 용량을 갖춘 다양한 모델을 만들 수 있다. 이러한 모델은 경량부터 (ex. Atto) 컴퓨팅 집약적인 (ex. Huge) 모델까지 다양하다.
GRN의 영향
저자들은 FCMAE 프레임워크를 사용하여 ConvNeXt V2를 사전 학습하고 GRN의 영향을 평가하였다. 위의 시각화와 코사인 거리 분석을 통해 ConvNeXt V2가 feature collapse 문제를 효과적으로 완화한다는 것을 확인할 수 있다. 코사인 거리 값은 일관되게 높으며, 이는 feature 다양성이 레이어 전반에 걸쳐 유지된다는 것을 나타낸다. 이 동작은 MAE로 사전 학습된 ViT 모델의 동작과 유사하다. 전반적으로 이는 ConvNeXt V2 학습 동작이 유사한 마스크 이미지 사전 학습 프레임워크 하에서 ViT와 유사할 수 있음을 시사한다.
다음으로 저자들은 fine-tuning 성능을 평가하였으며, 그 결과는 아래 표와 같다.
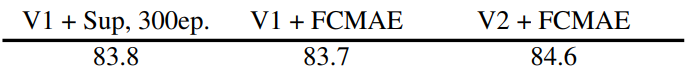
GRN을 장착하면 FCMAE로 사전 학습된 모델은 300 epoch supervised baseline보다 훨씬 뛰어난 성능을 발휘할 수 있다. GRN은 V1 모델에는 없었지만 마스크 기반 사전 학습에 중요한 것으로 입증된 feature 다양성을 강화하여 표현 품질을 향상시킨다. 이 개선은 파라미터 오버헤드를 추가하거나 FLOPS를 늘리지 않고도 달성할 수 있다.
Feature 정규화 방법과의 관계
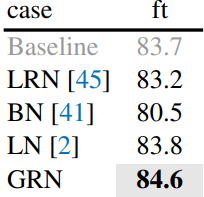
저자들은 다른 정규화 레이어가 GRN 레이어만큼 성능을 발휘할 수 있는가에 대하여 실험하였다. 위 표에서는 GRN을 널리 사용되는 세 가지 정규화 레이어인 LRN (Local Response Normalization), BN (Batch Normalization), LN (Layer Normalization)과 비교하였다. GRN만이 supervised baseline보다 훨씬 뛰어난 성능을 발휘할 수 있다. LRN은 인근의 채널만 대조하므로 글로벌 컨텍스트가 부족하다. BN은 배치 축을 따라 공간적으로 정규화하므로 마스킹된 입력에는 적합하지 않다. LN은 글로벌한 평균과 분산 표준화를 통해 feature 경쟁을 암시적으로 장려하지만 GRN만큼 작동하지는 않는다.
Feature gating 방법과의 관계

뉴런 간 경쟁을 강화하는 또 다른 방법은 동적 feature gating 방법을 사용하는 것이다. 위 표에서는 GRN을 SE (squeeze-and-excite)와 CBAM (convolutional block attention module)이라는 두 가지 클래식 gating 레이어와 비교하였다. SE는 채널 gating에 중점을 두고 CBAM은 공간 gating에 중점을 둔다. 두 모듈 모두 GRN과 유사하게 개별 채널의 대비를 높일 수 있다. GRN은 추가 파라미터 레이어 (ex. MLP)가 필요하지 않으므로 훨씬 간단하고 효율적이다.
사전 학습과 fine-tuning에서 GRN의 역할

저자들은 사전 학습과 fine-tuning에서 GRN의 중요성을 조사하였다. 위 표는 fine-tuning에서 GRN을 제거하거나 fine-tuning 시에만 새로 초기화된 GRN을 추가하였을 때의 결과이다. 어느 쪽이든 상당한 성능 저하가 관찰되었으며, 이는 사전 학습과 fine-tuning 모두에서 GRN을 유지하는 것이 중요함을 시사한다.
Experiments
1. ImageNet
다음은 self-supervised learning 프레임워크 (FCMAE)와 모델 아키텍처 개선 (GRN 레이어)의 공동 설계에 대한 실험 결과이다.

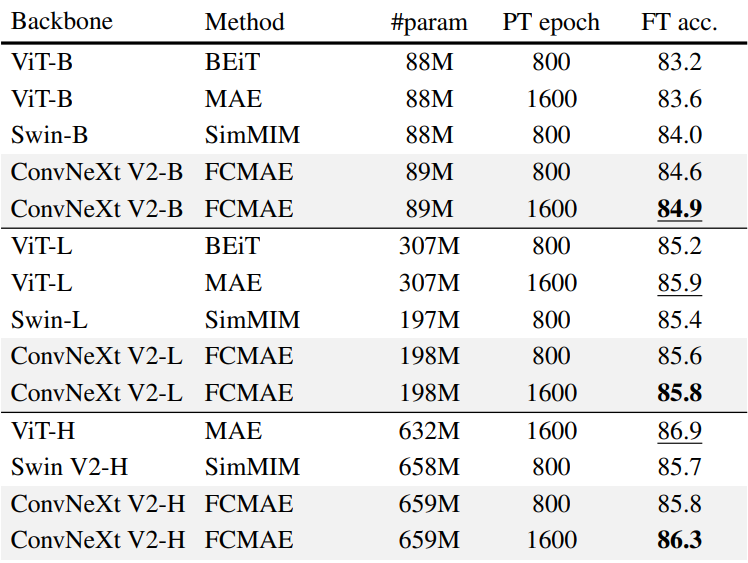
다음은 이전 masked image modeling 방법과 성능을 비교한 표이다.
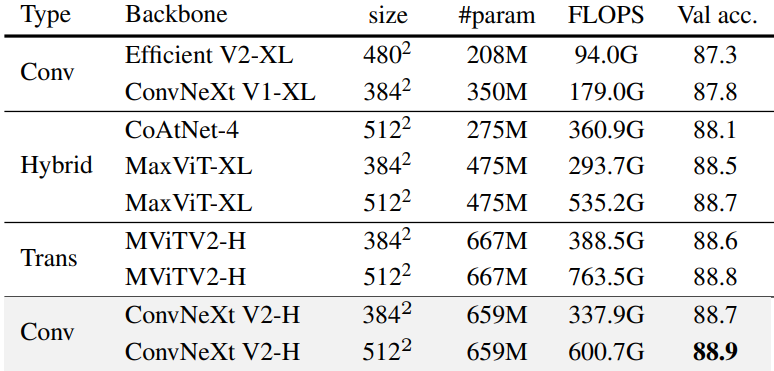
다음은 ImageNet-22K 레이블을 사용한 ImageNet-1K fine-tuning 결과이다.
학습 프로세스는 다음과 같이 세 단계로 구성된다.
- FCMAE 사전 학습
- ImageNet-22K fine-tuning
- ImageNet-1K fine-tuning
2. Transfer Learning
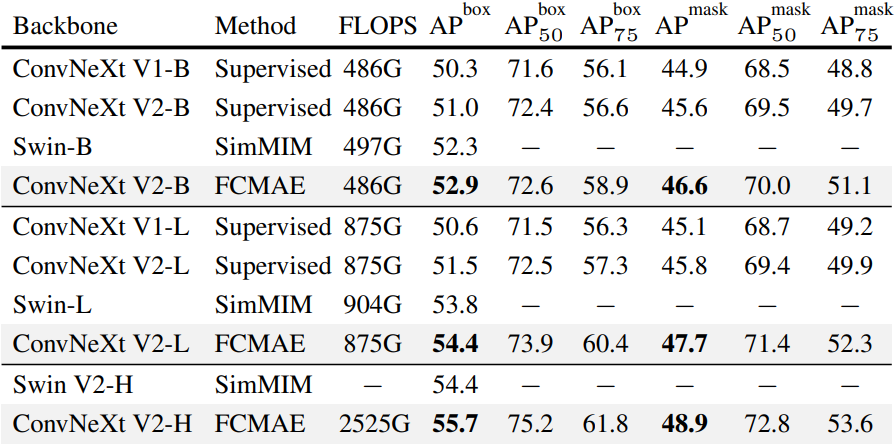
다음은 Mask-RCNN을 사용한 COCO object detection 및 instance segmentation 결과이다.
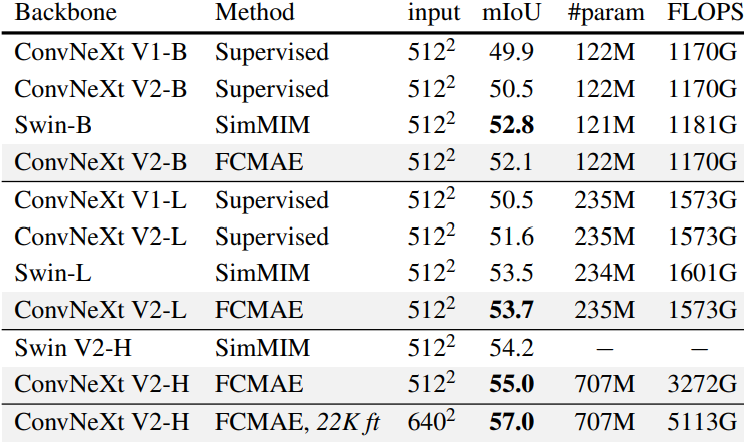
다음은 UPerNet을 사용한 ADE20K semantic segmentation 결과이다.