[논문리뷰] Adding Conditional Control to Text-to-Image Diffusion Models (ControlNet)
arXiv 2023. [Paper] [Github]
Lvmin Zhang, Maneesh Agrawala
Stanford University
10 Feb 2023

Introduction
대형 text-to-image 모델이 있는 경우 시각적으로 매력적인 이미지를 생성하려면 사용자가 입력하는 짧은 설명 프롬프트만 필요할 수 있다. 몇 가지 텍스트를 입력하고 이미지를 얻은 후 자연스럽게 몇 가지 질문이 떠오를 수 있다.
이 프롬프트 기반 컨트롤이 우리의 요구를 충족하는가?
특정 task를 용이하게 하기 위해 이러한 대형 모델을 적용할 수 있는가?
광범위한 문제 조건과 사용자 제어를 처리하기 위해 어떤 종류의 프레임워크를 구축해야 하는가? 특정 task에서 대형 모델이 수십억 개의 이미지에서 얻은 이점과 능력을 보존할 수 있는가?
저자들은 이러한 질문에 답하기 위해 다양한 이미지 처리 애플리케이션을 조사하고 세 가지 결과를 얻었다.
첫째, task별 도메인에서 사용 가능한 데이터 규모는 일반적인 이미지-텍스트 도메인만큼 항상 크지는 않다. 많은 특정 문제(ex. 물체 모양, 포즈 이해 등)의 가장 큰 데이터셋 크기는 종종 100k 미만, 즉 LAION-5B보다 $5 \times 10^4$배 작다. 이를 위해서는 overfitting을 피하고 대형 모델이 학습한 일반화 능력을 보존하기 위해 강력한 신경망 학습 방법이 필요하다.
둘째, 데이터 기반 솔루션으로 이미지 처리 task를 처리할 때 대규모 계산 클러스터를 항상 사용할 수 있는 것은 아니다. 따라서 허용 가능한 시간과 메모리 공간 내에서 특정 task에 대해 대형 모델을 최적화하는 데 빠른 학습 방법이 중요하다. 이를 위해서는 사전 학습된 가중치의 활용과 fine-tuning 전략 또는 transfer learning이 필요하다.
셋째, 다양한 이미지 처리 문제는 다양한 형태의 문제 정의, 사용자 컨트롤 또는 이미지 주석을 가지고 있다. 이러한 문제를 해결할 때 이미지 diffusion 알고리즘을 절차적 방식으로 규제할 수 있지만 이러한 수작업 규칙의 동작은 기본적으로 인간의 지시에 의해 규정된다. Depth-to-image, pose-to-human과 같은 일부 특정 task를 고려할 때 이러한 문제는 본질적으로 개체 레벨 또는 장면 레벨의 이해에 대한 입력의 해석을 필요로 하므로 수작업 절차 방법의 실현 가능성이 떨어진다. 많은 task에서 학습된 솔루션을 달성하려면 end-to-end 학습이 필수 불가결하다.
본 논문에서는 task별 입력 조건을 학습하기 위해 대규모 이미지 diffusion model (ex. Stable Diffusion)을 제어하는 end-to-end 신경망 아키텍처인 ControlNet을 제시한다. ControlNet은 대규모 diffusion model의 가중치를 trainable copy와 locked copy로 복제한다. Locked copy는 수십억 개의 이미지에서 학습한 네트워크 능력을 보존하는 반면 trainable copy는 task별 데이터셋에서 학습되어 조건부 제어를 학습한다. 학습 가능하고 잠긴 신경망 블록은 “zero convolution”이라는 고유한 유형의 convolution layer와 연결되며, 여기서 convolution 가중치는 학습을 통해 0에서 최적화된 파라미터로 점진적으로 증가한다. 생성이 가능한 가중치가 보존되기 때문에 학습은 다양한 규모의 데이터셋에서 강력하다. Zero convolution은 깊은 feature에 새로운 noise를 추가하지 않기 때문에 처음부터 새 레이어를 학습시키는 것과 비교하여 diffusion model을 fien-tuning하는 것만큼 학습이 빠르다.
Method
1. ControlNet
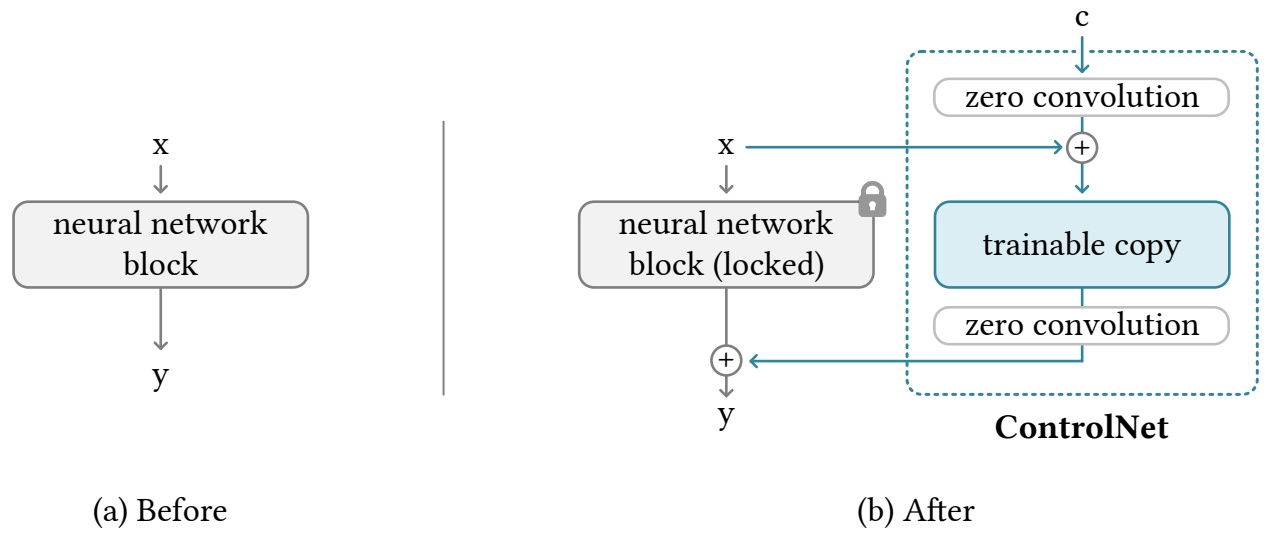
ControlNet은 신경망 블록의 입력 조건을 조작하여 전체 신경망의 전반적인 동작을 추가로 제어한다. 여기서 “네트워크 블록”은 신경망을 구축하기 위해 자주 사용되는 단위로 한데 모인 레이어의 집합을 의미하며, 예를 들어 “resnet” 블록, “conv-bn-relu” 블록, multi-head attention 블록, transformer 블록 등이 있다.
예를 들어 2D feature를 사용하면 \(\{h, w, c\}\)가 높이, 너비, 채널 수 feature map $x \in \mathbb{R}^{h \times w \times c}$가 주어지면 신경망 블록 $F(\cdot; \Theta)$는 다음과 같이 $x$를 다른 feature map $y$로 변환한다. (위 그림의 (a))
\[\begin{equation} y = \mathcal{F} (x; \Theta) \end{equation}\]모든 파라미터를 $\Theta$로 잠근 다음 $\Theta_c$에 복제한다. 복사된 $\Theta_c$는 외부 조건 벡터 $c$로 학습된다. 본 논문에서는 원래 파라미터와 새 파라미터를 locked copy와 trainable copy라고 한다. 원래 가중치를 직접 학습하는 대신 이러한 사본을 만드는 목적은 데이터 셋이 작을 때 overfitting을 방지하고 수십억 개의 이미지에서 학습한 대형 모델의 품질을 보존하는 것이다.
신경망 블록은 “zero convolution”이라고 하는 고유한 유형의 convolution layer, 즉 가중치와 바이어스가 모두 0으로 초기화된 1$\times$1 convolution layer로 연결된다. Zero convolution 연산을 $\mathcal{Z}(\cdot; \cdot)$로 표시하고 파라미터의 두 인스턴스 \(\{\Theta_{z1}, \Theta_{z2}\}\)를 사용하여 다음과 같이 ControlNet 구조를 구성한다. (위 그림의 (b))
\[\begin{equation} y_c = \mathcal{F} (x; \Theta) + \mathcal{Z} (\mathcal{F} (x + \mathcal{Z}(c; \Theta_{z1}); \Theta_c); \Theta_{z2}) \end{equation}\]여기서 $y_c$는 이 신경망 블록의 출력이 된다.
Zero convolution layer의 가중치와 바이어스는 모두 0으로 초기화되기 때문에, 첫 번째 학습 step에서 다음과 같다.
\[\begin{aligned} &\mathcal{Z}(c; \Theta_{z1}) = 0 \\ &\mathcal{F}(x + \mathcal{Z} (c; \Theta_{z1}); \Theta_c) = \mathcal{F} (x; \Theta_c) = \mathcal{F} (x; \Theta) \\ &\mathcal{Z}(\mathcal{F} (x + \mathcal{Z}(c; \Theta_{z1}); \Theta_c); \Theta_{z2}) = \mathcal{Z}(\mathcal{F} (x; \Theta_c); \Theta_{z2}) = 0 \end{aligned}\]그리고 이는 다음과 같이 변환될 수 있다.
\[\begin{equation} y_c = y \end{equation}\]첫 번째 학습 step에서 신경망 블록의 trainable copy와 locked copy의 모든 입력 및 출력은 마치 ControlNet이 존재하지 않는 것과 일치한다. 즉, ControlNet이 일부 신경망 블록에 적용될 때 최적화 전에는 feature에 영향을 미치지 않는다. 모든 신경망 블록의 능력, 기능 및 결과 품질은 완벽하게 보존되며 추가 최적화는 fine-tuning만큼 빠르다 (해당 레이어를 처음부터 학습하는 것과 비교할 때).
Zero convolution layer의 기울기 계산을 간단히 추론해보자. 입력 map $I \in \mathbb{R}^{h \times w \times c}$가 주어지면 임의의 공간적 위치 $p$와 채널별 인덱스 $i$에서 가중치 $W$와 바이어스 $B$를 갖는 $1 \times 1$ convolution layer를 고려하면 forward pass는 다음과 같이 쓸 수 있다.
\[\begin{equation} \mathcal{Z} (I; \{W, B\})_{p, i} = B_i + \sum_j^c I_{p, c} W_{i, j} \end{equation}\]Zero convolution은 최적화 전에 $W = 0$과 $B = 0$이므로 $I_{p,i}$가 0이 아닌 모든 위치에 대해 기울기는
\[\begin{aligned} &\frac{\partial \mathcal{Z} (I; \{W, B\})_{p, i}}{\partial B_i} = 1 \\ &\frac{\partial \mathcal{Z} (I; \{W, B\})_{p, i}}{\partial I_{p,i}} = \sum_j^c W_{i,j} = 0 \\ &\frac{\partial \mathcal{Z} (I; \{W, B\})_{p, i}}{\partial W_{i,j}} = I_{p,i} \ne 0 \end{aligned}\]가 된다.
Zero convolution으로 인해 feature 항 $I$의 기울기가 0이 될 수 있지만 가중치와 바이어스의 기울기의 영향을 받지 않는다는 것을 알 수 있다. Feature $I$가 0이 아닌 한 가중치 $W$는 첫 번째 gradient descent iteration에서 0이 아닌 행렬로 최적화된다. 특히 feature 항은 데이터셋에서 샘플링된 입력 데이터 또는 조건 벡터이며 자연스럽게 0이 아닌 $I$를 보장한다.
예를 들어 전체 loss function $\mathcal{L}$과 학습률 \(\beta_\textrm{lr}\ne 0\)을 사용하는 고전적인 gradient descent를 고려하자. “외부” 기울기 \(\partial \mathcal{L} / \partial \mathcal{Z} (I; \{W, B\})\)가 0이 아니면 다음과 같다.
\[\begin{equation} W^\ast = W - \beta_\textrm{lr} \cdot \frac{\partial \mathcal{L}}{\partial \mathcal{Z} (I; \{W, B\})} \odot \frac{\partial \mathcal{Z} (I; \{W, B\})}{\partial W} \ne 0 \end{equation}\]여기서 $W^\ast$는 하나의 gradient descent step 이후의 가중치다. $\odot$는 Hadamard product (element-wise product)이다. 이 step 후에
\[\begin{equation} \frac{\partial \mathcal{Z} (I; \{W^\ast, B\})_{p,i}}{\partial I_{p,i}} = \sum_j^c W_{i,j}^\ast \ne 0 \end{equation}\]이 된다.
여기서 0이 아닌 기울기가 얻어지고 신경망이 학습을 시작한다. 이러한 방식으로 zero convolution은 학습을 통해 0에서 최적화된 파라미터로 점진적으로 성장하는 고유한 유형의 연결 레이어가 된다.
2. ControlNet in Image Diffusion Model
Stable Diffusion을 예로 들어 ControlNet을 사용하여 task별 조건으로 대규모 diffusion model을 제어하는 방법을 소개한다.
Stable Diffusion은 수십억 개의 이미지에 대해 학습된 대규모 text-to-image diffusion model이다. 이 모델은 본질적으로 인코더, 중간 블록, skip-connection으로 연결된 디코더가 있는 U-net이다. 인코더와 디코더 모두 12개의 블록이 있고 전체 모델에는 25개의 블록 (가운데 블록 포함)이 있다. 이 블록에서 8개의 블록은 다운샘플링 또는 업샘플링 convolution layer이고, 17개의 블록은 각각 4개의 resnet 레이어와 2개의 ViT (Vision Transformers)를 포함하는 기본 블록이다. 각 ViT에는 몇 가지 cross-attention과 self-attention 메커니즘이 포함되어 있다. 텍스트는 OpenAI CLIP으로 인코딩되고 diffusion timestep은 위치 인코딩으로 인코딩된다.
Stable Diffusion은 VQ-GAN과 유사한 전처리 방법을 사용하여 안정화된 학습을 위해 512$\times$512 이미지의 전체 데이터샛을 더 작은 64$\times$64 크기의 “latent 이미지”로 변환한다. 이를 위해서는 convolution 크기와 일치하도록 이미지 기반 조건들을 64$\times$64 feature space로 변환하는 ControlNet이 필요하다. 본 논문은 4$\times$4 kernel과 2$\times$2 stride를 가지는 convolution layer로 구성된 작은 네트워크 $\mathcal{E}(\cdot)$를 사용한다. 다음과 같이 이미지 조건 $c_i$를 feature map으로 인코딩한다.
\[\begin{equation} c_f = \mathcal{E}(c_i) \end{equation}\]여기서 $c_f$는 변환된 feature map이다. 이 네트워크는 512$\times$512 이미지 조건을 64$\times$64 feature map으로 변환한다.
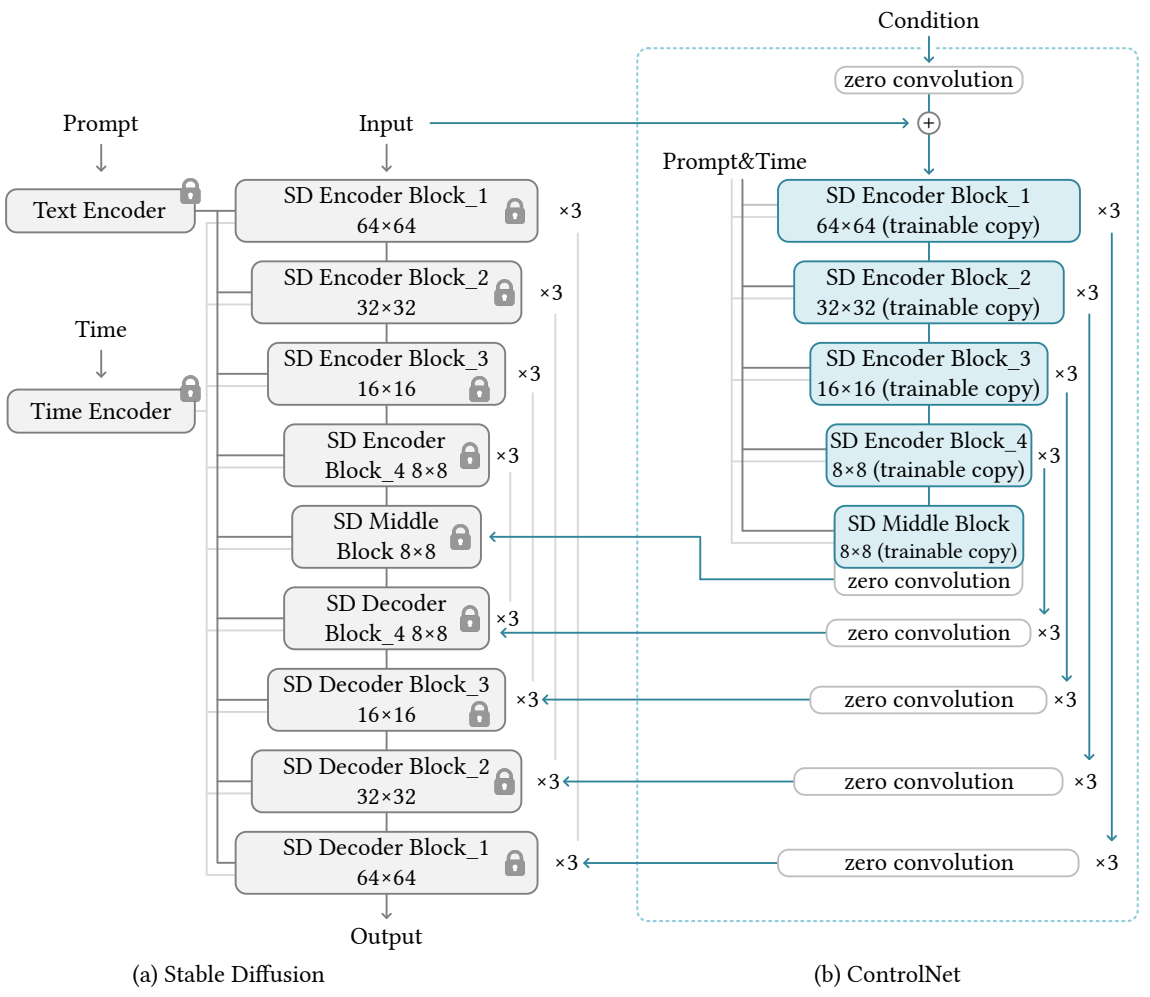
위 그림과 같이 ControlNet을 사용하여 U-net의 각 레벨을 제어한다. ControlNet을 연결하는 방법은 계산적으로 효율적이다. 원래 가중치가 잠겨 있기 때문에 학습을 위해 원래 인코더에 대한 기울기 계산이 필요하지 않다. 이렇게 하면 원본 모델에서 기울기 계산의 절반을 피할 수 있으므로 학습 속도가 빨라지고 GPU 메모리가 절약된다. ControlNet으로 Stable Diffusion 모델을 학습하려면 GPU 메모리가 약 23% 더 필요하고 각 학습 iteration에서 34% 더 많은 시간이 필요하다.
구체적으로, ControlNet을 사용하여 Stable Diffusion의 12개 인코딩 블록과 1개 중간 블록의 trainable copy를 만든다. 12개의 블록은 각각 3개의 블록을 갖는 4개의 해상도 (64$\times$64, 32$\times$32, 16$\times$16, 8$\times$8)로 되어 있다. 출력은 U-net의 skip connection 12개와 중간 블록 1개에 추가된다. Stable Diffusion은 일반적인 U-net 구조이므로 이 ControlNet 아키텍처는 다른 diffusion model에서 사용할 수 있다.
3. Training
이미지 diffusion model은 이미지를 점진적으로 noise를 제거하여 샘플을 생성하는 방법을 학습한다. Noise 제거는 pixel space 또는 학습 데이터에서 인코딩된 latent space에서 발생할 수 있다. Stable Diffusion은 latent를 학습 도메인으로 사용한다.
이미지 $z_0$가 주어지면 diffusion 알고리즘은 점진적으로 이미지에 noise를 추가하고 noise가 추가된 횟수를 $t$로 하여 noisy한 이미지 $z_t$를 생성한다. $t$가 충분히 크면 이미지는 순수한 noise에 가깝다. Timestep $t$, 텍스트 프롬프트 $c_t$, task별 조건 $c_f$를 포함한 일련의 조건이 주어지면, 이미지 diffusion 알고리즘은 다음의 목적 함수로 네트워크 $\epsilon_\theta$를 학습하여 $z_t$에 추가된 noise를 예측한다.
\[\begin{equation} \mathcal{L} = \mathbb{E}_{z_0, t, c_t, c_f, \epsilon \sim \mathcal{N}(0,1)} [\| \epsilon - \epsilon_\theta (z_t, t, c_t, c_f) \|_2^2] \end{equation}\]이 목적 함수는 fine-tuning diffusion model에서 직접 사용할 수 있다.
학습 중에 50%의 텍스트 프롬프트 $c_t$를 빈 문자열로 랜덤하게 바꾼다. 이는 입력 조건 map에서 의미론적 내용을 인식하는 ControlNet의 능력을 용이하게 한다. 이것은 주로 Stable Diffusion 모델에 대한 프롬프트가 표시되지 않을 때 인코더가 프롬프트 대신 입력 제어 map에서 더 많은 semantic을 학습하는 경향이 있기 때문이다.
4. Improved Training
GPU 사용이 매우 제한적이거나 매우 강력한 경우 ControlNet의 학습을 개선하기 위한 몇 가지 전략을 사용할 수 있다.
Small-Scale Training
GPU 사용이 제한될 때 ControlNet과 Stable Diffusion 간의 연결을 부분적으로 끊으면 수렴이 가속화될 수 있다. 기본적으로 ControlNet을 “SD Middle Block”과 “SD Decoder Block 1,2,3,4”에 연결한다. 중간 블록을 연결하면 학습 속도를 약 1.6배 향상시킬 수 있다 (RTX 3070TI 노트북 GPU 기준). 모델이 결과와 조건 사이에 합리적인 연관성을 보여주면 정확한 제어를 용이하게 하기 위해 학습에서 끊긴 연결을 다시 연결할 수 있다.
Large-Scale Training
여기서 대규모 학습이란 강력한 계산 클러스터 (최소 8개의 Nvidia A100 80G 또는 동급)와 대규모 데이터셋 (최소 100만 개의 학습 이미지 쌍)을 모두 사용할 수 있는 상황을 말한다. 이는 일반적으로 데이터를 쉽게 사용할 수 있는 task에 적용된다. 이 경우 overfitting의 위험이 상대적으로 낮기 때문에 먼저 충분히 많은 iteration (보통 50,000 step 이상) 동안 ControlNet을 학습한 다음 Stable Diffusion의 모든 가중치를 잠금 해제하고 전체 모델을 공동으로 학습시킬 수 있다. 이것은 보다 문제에 특화된 모델로 이어질 것이다.
Experiment
- Experimental Settings
- Classifier-free guidance scale: 9.0
- Sampler: DDIM
- step: 20
저자들은 4가지 종류의 프롬프트로 모델을 테스트하였다.
- No prompt: 빈 문자열을 프롬프트로 사용
- Default prompt: Stable diffusion은 본질적으로 프롬프트로 학습되기 때문에 빈 문자열은 모델에 대한 예상치 못한 입력이 될 수 있으며 Stable Diffusion은 프롬프트가 제공되지 않으면 랜덤 텍스처 맵을 생성하는 경향이 있다. 더 나은 설정은 “이미지”, “멋진 이미지”, “전문적인 이미지” 등과 같은 의미 없는 프롬프트를 사용하는 것이다. “전문적이고 상세한 고품질 이미지”를 기본 프롬프트로 사용한다.
- Automatic prompt: 완전 자동 파이프라인의 state-of-the-art 최대 품질을 테스트하기 위해 자동 이미지 캡션 방법 (ex. BLIP)을 사용하여 “Default prompt” 모드에서 얻은 결과를 사용하여 프롬프트를 생성한다. 생성된 프롬프트를 다시 diffusion에 사용한다.
- User prompt: 사용자가 프롬프트를 제공한다.
1. Qualitative Results
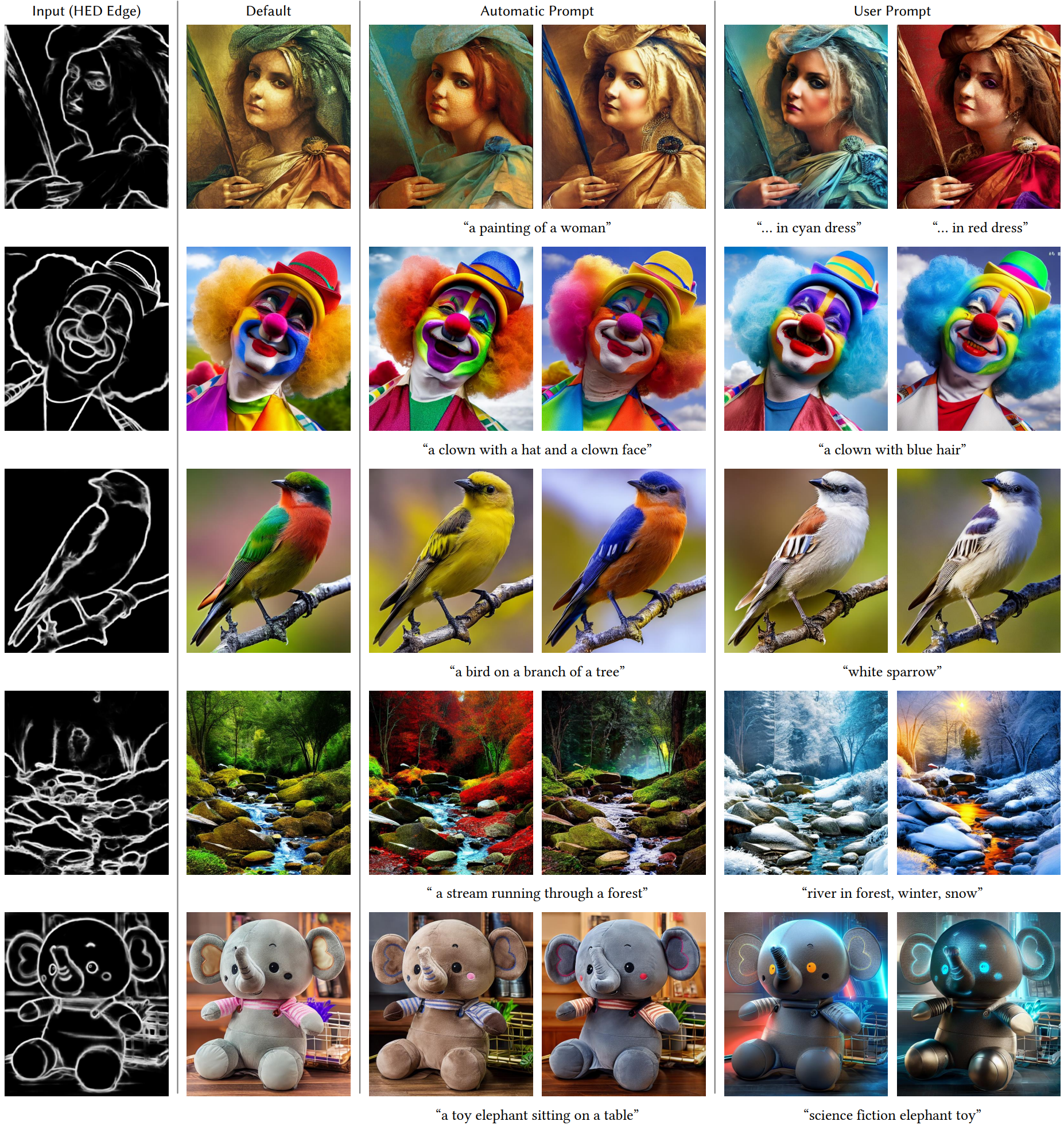
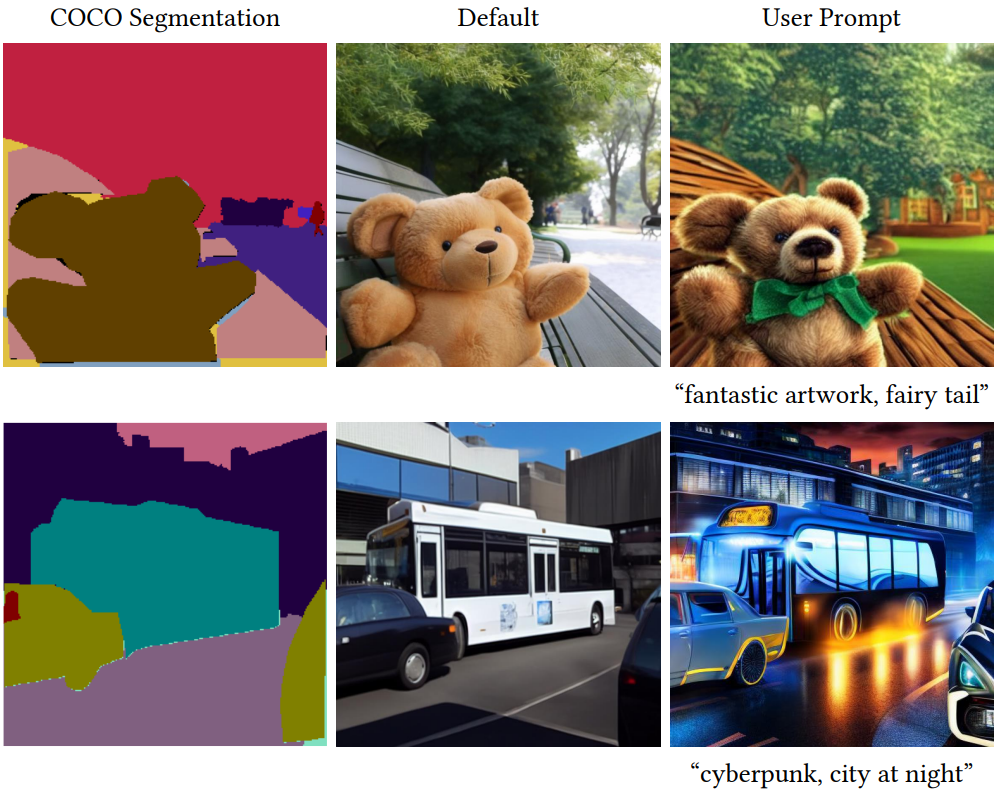
다음은 다양한 이미지 조건으로 Stable Diffusion을 제어한 예시들이다.
Canny edge

Hough line (M-LSD)

사용자의 낙서

HED edge
Openpifpaf pose

Openpose

ADE20K segmentation map

COCO-Stuff segmentation map
DIODE normal map

만화 선화

2. Ablation Study
다음은 ControlNet을 사용하지 않고 학습된 모델과의 비교를 보여준다. 해당 모델은 Stability의 Depth-to-Image 모델과 정확히 동일한 방법으로 학습된다.

다음 그림은 학습 과정을 보여준다. 모델이 갑자기 입력 조건을 따를 수 있게 되는 “급격한 수렴 현상”이 발생한다. 이는 learning rate로 $1 \times 10^{-5}$를 사용할 때 5,000에서 10,000 step까지의 학습 과정 중에 발생할 수 있다.

다음은 다양한 데이터셋 스케일로 학습된 Canny-edge 기반 ControlNet을 보여준다.

3. Comparison to previous methods
다음은 Stability의 Depth-to-Image model과 비교한 예시들이다.

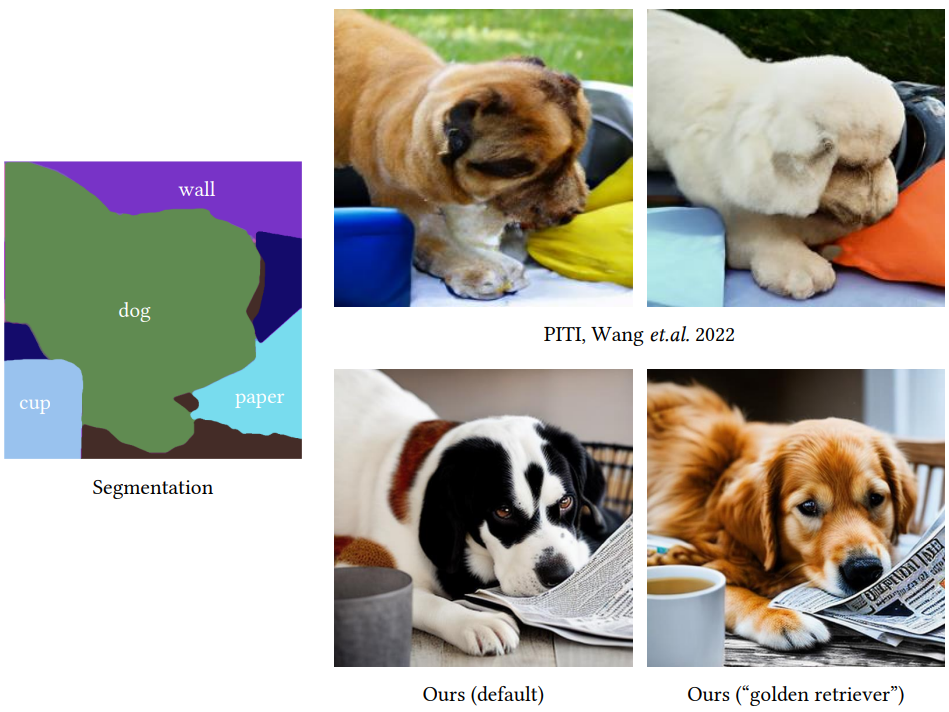
다음은 Pretraining-Image-to-Image(PITI)와 비교한 예시들이다.
다음은 sketch-guided diffusion과 비교한 예시들이다.

다음은 Taming transformer와 비교한 예시들이다.

4. Comparison of pre-trained models
다음 그림은 diffusion process가 마스킹되면 펜 기반 이미지 편집에서 모델을 사용할 수 있음을 보여준다.

다음 그림은 객체가 상대적으로 단순할 때 모델이 디테일을 비교적 정확하게 제어할 수 있음을 보여준다.

다음 그림은 ControlNet이 50% diffusion iteration에만 적용될 때 입력 형태를 따르지 않는 결과를 얻을 수 있음을 보여준다.

Limitation
다음은 semantic 해석이 잘못된 경우 모델이 올바른 내용을 생성하기 어려울 수 있음을 보여준다.
