[논문리뷰] ConsiStory: Training-Free Consistent Text-to-Image Generation
SIGGRAPH 2024. [Paper] [Page]
Yoad Tewel, Omri Kaduri, Rinon Gal, Yoni Kasten, Lior Wolf, Gal Chechik, Yuval Atzmon
NVIDIA | Tel Aviv University
5 Feb 2024

Introduction
대규모 text-to-image (T2I) diffusion model을 사용하면 상상력이 풍부한 장면을 만들 수 있지만 확률론적 특성으로 인해 일관된 주제를 묘사하려고 할 때 문제가 발생한다. 일관된 이미지 생성 분야에서 현재 접근 방식은 T2I 모델이 주어진 이미지 세트에서 특정 주제를 표현하기 위해 새로운 단어를 학습하는 프로세스인 개인화(personalization)에 주로 의존한다. 그러나 이러한 개인화 기반 방법에는 몇 가지 단점이 있다.
- 주제별 학습이 필요하다.
- 하나의 이미지에 여러 개의 일관된 주제를 동시에 묘사하는 데 어려움을 겪는다.
- 일관된 주제를 묘사하면서 프롬프트를 만족해야 하므로 둘 사이의 trade-off로 어려움을 겪을 수 있다.
인코더를 사용한 이미지 조건부 diffusion model 학습과 같은 대안은 상당한 계산 리소스가 필요하며 여러 객체가 있는 장면으로의 확장은 여전히 불분명하다. 이러한 모든 접근 방식들은 공통점은 뒤에서부터 일관성을 강화하려고 시도한다는 것이다. 즉, 생성된 이미지가 특정 주어진 타겟과 일치하도록 작동한다. 이러한 접근 방식은 모델의 창의성을 주어진 타겟 이미지로 제한하며, 모델을 학습 분포에서 멀어지게 만드는 경향이 있다.
본 논문은 기존 이미지에 조건을 두지 않고 zero-shot 방식으로 일관성을 달성하는 방법을 제안하였다. 핵심 아이디어는 생성 중에 프레임 간 일관성을 앞에서부터 촉진하는 것이다. 이를 위해 생성된 이미지를 외부 소스와 추가로 정렬할 필요 없이 diffusion model의 내부 feature 표현을 활용하여 서로 정렬한다. 이를 통해 오랜 학습이나 역전파 없이 바로 일관된 생성을 가능하게 하여 현재 SOTA보다 대략 20배 더 빠르게 생성할 수 있다.
본 논문의 접근 방식은 세 단계로 이루어진다.
- 생성된 이미지 batch의 activation 전반에 걸쳐 주제별 정보를 공유하는 것을 목표로 하는 Subject-Driven Self-Attention (SDSA)을 도입하여 주제 일관성을 장려한다.
- SDSA는 생성된 레이아웃의 다양성을 줄인다. 따라서 일관되지 않은 vanilla 샘플링 step의 feature를 통합하고 공유된 key와 value에 새로운 inference-time dropout을 도입하여 다양성을 유지한다.
- 더 세밀하게 일관성을 향상시키기 위해 전체 세트의 해당 주제 픽셀 사이에 self-attention 출력 feature를 정렬한다.
ConsiStory라고 하는 본 논문의 방법은 이러한 구성 요소들을 결합하여 학습이 필요 없는 일관된 생성을 가능하게 한다. ConsiStory는 생성 프로세스 중에 feature를 정렬함으로써 생성 프로세스 속도를 크게 높일 뿐만 아니라 프롬프트를 더 잘 만족시킨다. 또한 여러 주제가 포함된 장면으로 확장하기가 쉽우며, ControlNet과 같은 기존 편집 도구와 호환된다. ConsiStory는 공통 객체 클래스들에 대한 학습 없는 개인화에 아이디어를 적용하여 처음으로 인코더를 사용하지 않고 학습 없는 개인화를 보여주었다.
Method
본 논문의 목표는 다양한 프롬프트에 걸쳐 일관된 주제를 묘사하는 일련의 이미지를 생성하는 것이다. ConsiStory는 denoising 중에 T2I 모델의 내부 activation을 더 잘 조정하여 목표를 달성하였다. 중요한 점은 추가 학습 없이 inference 기반 메커니즘을 통해서만 일관성을 강화하는 것을 목표로 한다는 것이다.
1. Subject-driven self-attention
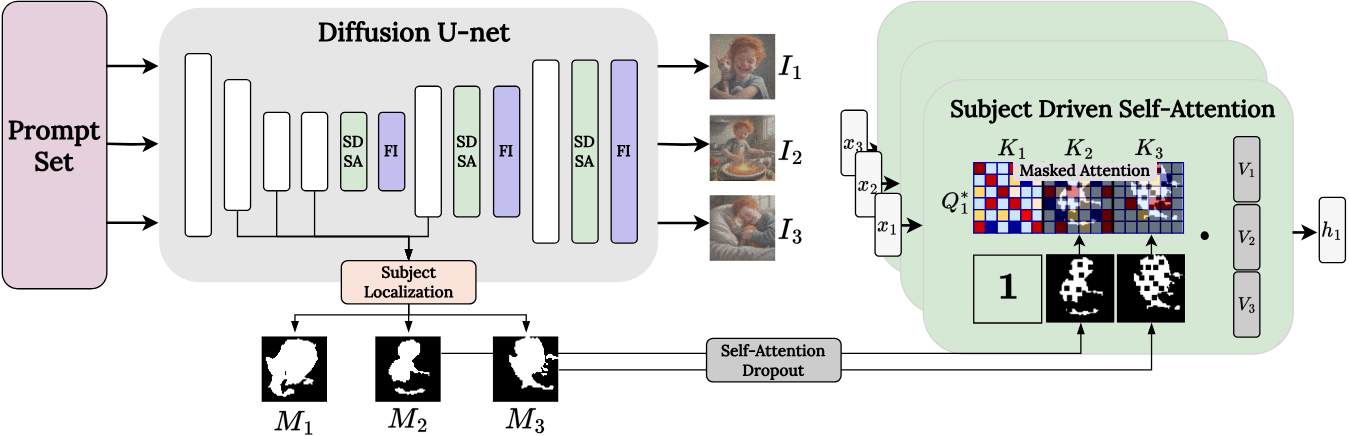
일관성을 높이기 위한 간단한 아이디어는 한 이미지의 query가 batch에 있는 다른 이미지의 key와 value에도 attention할 수 있도록 self-attention을 확장하는 것이다. 이를 통해 반복되는 개체가 자연스럽게 서로 연결되어 이미지 전반에 걸쳐 feature를 공유할 수 있다.
이 아이디어는 동영상 생성 및 편집에 자주 사용되어 프레임 전체의 일관성을 향상시킨다. 그러나 동영상 생성과 본 논문의 시나리오와 다르다. 동영상 생성은 프레임 전체에 걸쳐 공유되는 단일 프롬프트로 생성되며, 일반적으로 한 프레임에서 다음 프레임으로 배경이나 레이아웃을 거의 변경하지 않아도 된다. 반면 본 논문의 목표는 각 프레임이 고유한 프롬프트를 따르기를 원하며 배경과 레이아웃의 다양성을 유지하는 것이 중요하다. 이러한 동영상 기반 메커니즘을 단순하게 사용하면 균일한 배경이 생성되고 각 이미지의 프롬프트와의 정렬이 크게 감소한다.
이러한 제한을 해결하는 한 가지 방법은 배경 패치에서 공유되는 정보의 양을 줄이는 것이다. 주제의 외형 공유에만 관심이 있기 때문에 확장된 self-attention을 마스킹하여 한 이미지의 query가 동일한 이미지 또는 다른 이미지의 주제를 포함하는 영역의 key 및 value와만 일치할 수 있도록 한다. 이러한 방식으로 반복되는 주제에 대한 feature는 공유될 수 있지만 배경 feature는 별도로 유지된다.
이를 위해, cross-attention feature를 사용하여 타겟을 포함할 가능성이 있는 noisy latent 패치를 식별한다. Diffusion step과 레이어 전반에 걸쳐 타겟 토큰과 관련된 cross-attention map을 평균화하고 threshold를 지정하여 타겟별 마스크를 생성한다. 이러한 마스크를 사용하여 각 이미지가 자체 패치 또는 batch 내의 주제 패치에만 attention할 수 있도록 attention이 가려지는 Subject-Driven Self-Attention (SDSA)를 제안하였다.
\[\begin{aligned} K^{+} &= [K_1 \oplus K_2 \oplus \ldots \oplus K_N] \in \mathbb{R}^{N \cdot P \times d_k} \\ V^{+} &= [V_1 \oplus V_2 \oplus \ldots \oplus V_N] \in \mathbb{R}^{N \cdot P \times d_v} \\ M_i^{+} &= [M_1 \oplus \ldots \oplus M_{i-1} \oplus \unicode{x1D7D9} \oplus M_{i+1} \oplus \ldots \oplus M_N] \\ A_i^{+} &= \textrm{softmax} \bigg( \frac{Q_i K^{+ \top}}{\sqrt{d_k}} + \log M_i^{+} \bigg) \in \mathbb{R}^{P \times N \cdot P} \\ h_i &= A_i^{+} \cdot V^{+} \in \mathbb{R}^{P \times d_v} \end{aligned}\]여기서 $M_i$는 batch의 $i$번째 이미지에 대한 주제 마스크이고, $\oplus$는 행렬 concatenation이다. Query $Q_i$는 변경되지 않은 상태로 유지되며 $M_i^{+}$는 $i$번째 이미지 자체에 속하는 패치 인덱스에 대해 1의 배열로 설정된다.
2. Enriching layout diversity
SDSA를 사용하면 프롬프트가 정렬되고 배경 붕괴가 방지된다. 그러나 SDSA는 이미지 레이아웃 간의 과도한 유사성을 초래한다. 예를 들어, 주제는 일반적으로 비슷한 위치와 포즈로 생성된다.
본 논문은 결과의 다양성을 향상시키기 위해 두 가지 전략을 제안하였다.
- 일관성이 없는 vanilla 샘플링 step의 feature를 통합한다.
- Dropout 메커니즘을 통해 주체 중심의 공유 attention를 더욱 약화시킨다.
Vanilla query feature 사용
최근 연구에서는 외형 이미지에서 self-attention key와 value를 주입하고 구조 이미지에서 query를 주입하여 한 이미지의 외형을 다른 이미지의 구조와 결합할 수 있음을 보여주었다. 이에 영감을 받아 저자들은 보다 다양한 vanilla forward pass에 의해 예측된 구조와 더 밀접하게 정렬하여 포즈 변형을 향상시키는 것을 목표로 한다.
주로 레이아웃을 제어하는 것으로 알려진 diffusion process의 초기 step에 초점을 맞추어 query를 혼합한다. 먼저 SDSA 없이 noisy latent $z_t$에 vanilla denoising step을 적용하고 diffusion model에서 생성된 self-attention query $Q_t^\textrm{vanilla}$를 캐싱한다. 그런 다음 이번에는 SDSA를 사용하여 동일한 latent $z_t$를 다시 denoise한다. 이 두 번째 pass에서는 모든 SDSA 레이어에 대해 생성된 query $Q_t^\textrm{SDSA}$와 vanilla query $Q_t^\textrm{vanilla}$를 linear interpolatation하여 다음과 같은 결과를 얻는다.
\[\begin{equation} Q_t^\ast = (1 - v_t) Q_t^\textrm{SDSA} + v_t Q_t^\textrm{vanilla} \end{equation}\]여기서 $v_t$는 선형적으로 감소하는 혼합 파라미터이다.
Query feature 혼합을 사용하면 일관성이 없는 샘플링에서 다양성을 유지할 수 있다.
Self-Attention Dropout
레이아웃 변형을 강화하기 위한 두 번째 전략은 dropout을 사용하여 SDSA를 약화시키는 것이다. 특히, 각 denoising step에서 $M_i$의 패치 부분집합을 0으로 설정하여 무작위로 무효화한다. 이는 서로 다른 이미지 간의 attention 공유를 약화시키고 결과적으로 더 풍부한 레이아웃 변형을 촉진한다. 특히, dropout 확률을 조정하여 일관성의 강도를 조절하고 시각적 일관성과 레이아웃 변형 간의 균형을 맞출 수 있다.
Attention dropout은 공유된 key와 value에 모델이 덜 의존하여 지나친 일관성을 피하도록 한다.
3. Feature injection
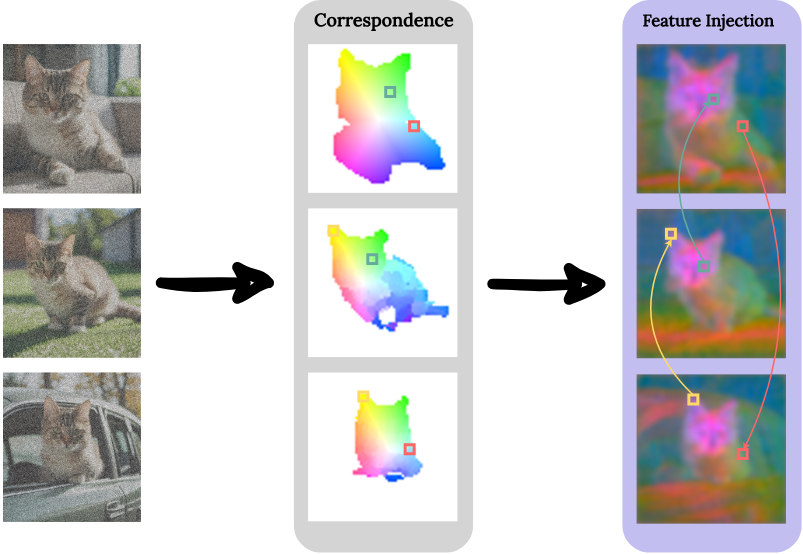
공유 attention 메커니즘은 주제의 일관성을 눈에 띄게 향상시키지만 세밀한 시각적 feature 때문에 어려움을 겪을 수 있으며, 이로 인해 주제의 identity가 손상될 수 있다. 따라서 새로운 이미지 간 feature 주입 메커니즘을 통해 일관성을 더욱 향상시킨다.
여기서는 batch의 여러 이미지에서 대응되는 영역(ex. 왼쪽 눈)의 feature 유사성을 향상시키는 것을 목표로 한다. 구체적으로, self-attention 출력 feature인 $x^\textrm{out}$에 상당한 텍스처 정보가 포함되어 있으며 이러한 feature를 일치하는 영역 간에 정렬하면 일관성을 향상시킬 수 있다.
Feature를 정렬하기 위해 먼저 DIFT feature $D_t$와 $D_s$를 사용하여 batch의 모든 이미지 $I_t$와 $I_s$ 쌍 사이에 패치 correspondence map $C_{t \rightarrow s}$를 구축한다. 그런 다음 feature 유사도를 높이기 위해 이 매핑을 기반으로 대응되는 feature를 혼합할 수 있다. 저자들은 이 아이디어를 각 이미지 $I_t$가 batch의 다른 이미지와 혼합되는 다대일 시나리오로 확장하였다. $I_t$의 각 패치 인덱스 $p$에 대해 다른 모든 이미지의 대응되는 패치를 비교하고 DIFT feature space에서 코사인 유사도가 가장 높은 패치를 선택한다.
\[\begin{equation} \textrm{src}(p) = \underset{s \ne t}{\arg \max} \; \textrm{sim} (D_t [p], D_s [C_{t \rightarrow s} [p]]) \end{equation}\]여기서 $\textrm{src}(p)$는 타겟 패치 $p$에 대한 최고의 소스 패치이고 $\textrm{sim}$은 코사인 유사도이다.
마지막으로 타겟 이미지 $x_t^\textrm{out}$의 self-attention 출력 레이어 feature와 해당 소스 패치 $x_s^\textrm{out}$를 혼합한다.
\[\begin{equation} \hat{x}_t^\textrm{out} = (1 - \alpha) \cdot x_t^\textrm{out} + \alpha \cdot \textrm{src} (x_t^\textrm{out}) \end{equation}\]여기서 $\textrm{src} (x_t^\textrm{out}) \in \mathbb{R}^{P \times d}$은 각각의 패치 $p$에 대해 $x_t^\textrm{out}$에서 대응되는 패치 $\textrm{src}(p)$의 feature를 풀링하여 얻은 텐서이다.
실제로는 배경에 영향을 주지 않고 동일한 주제의 외형 간의 일관성을 유지하기 위해 주제 마스크 $M_i$에 따라 feature 주입을 적용한다. 또한 DIFT space에서 유사도가 충분히 높은 패치 사이에만 feature를 주입하도록 threshold를 적용한다. 이 방법을 사용하면 주제의 외형에 기여하는 feature가 모든 소스 이미지에서 집합적으로 추출되어 보다 포괄적인 합성이 가능해진다.
4. Anchor images and reusable subjects
추가적인 최적화로 생성된 이미지의 부분집합을 “앵커 이미지”로 지정하여 계산 복잡도를 줄일 수 있다. SDSA 단계 중에 생성된 모든 이미지에서 key와 value를 공유하는 대신 이미지가 앵커에서 파생된 key와 value만 보도록 한다. 마찬가지로 feature 주입의 경우 앵커만 유효한 feature 소스로 간주한다. 앵커는 생성 중에 서로를 볼 수 있지만 앵커가 아닌 이미지의 feature는 보지 못한다. 대부분의 경우 앵커 두 개면 충분하다.
이러한 방식은 여러 가지 이점을 제공한다.
- 확장된 attention의 크기를 제한하므로 더 빠른 inference가 가능하고 GPU 메모리 사용량이 줄어든다.
- 대규모 batch에서 생성 품질을 향상시켜 시각적 아티팩트를 줄일 수 있다.
가장 중요한 점은 앵커 이미지를 다시 생성하기 위해 동일한 프롬프트와 시드가 사용되지만 앵커가 아닌 프롬프트는 변경된 새로운 batch를 생성하여 새로운 장면에서 동일한 주제를 재사용할 수 있다는 것이다. 이 메커니즘을 통해 주제들을 재사용하고 무제한의 일관된 이미지를 생성할 수 있다.
5. Multi-subject consistent generation
개인화 기반 접근 방식은 하나의 이미지 내의 여러 주제에 대한 일관성을 유지하는 데 어려움을 겪는다. 그러나 ConsiStory를 사용하면 단순히 주제 마스크의 합집합을 취하는 것만으로 간단하고 직접적인 방식으로 여러 주제의 일관적인 생성이 가능하다. 주제의 의미가 다를 경우, 주제 사이의 정보 유출은 문제가 되지 않는다. 이는 관련 없는 주제 간의 정보 유출을 억제하는 게이트 역할을 하는 attention softmax의 지수적 형태 때문이다. 마찬가지로, feature 주입 중에 correspondence map을 thresholding하면 정보 누출을 방지하는 게이팅 효과가 생긴다.
Experiments
1. Qualitative Results
다음은 IP-Adapter, Textual Inversion (TI), DreamBooth-LORA (DB-LORA)와 비교한 결과이다.

다음은 다양한 초기 noise 입력에 따른 결과들이다.

다음은 여러 주제로 일관되게 생성한 결과를 DB-LORA와 비교한 것이다.

2. Quantitative evaluation
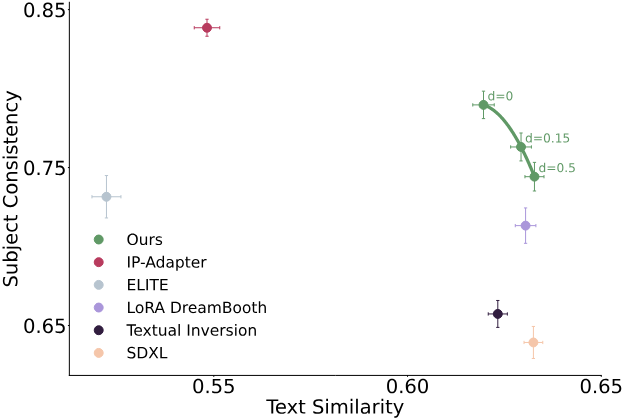
다음은 여러 방법들의 주제 일관성과 텍스트 유사도를 비교한 그래프이다.
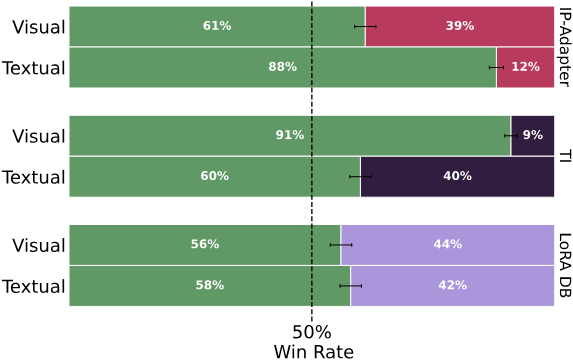
다음은 user study 결과이다.
3. Ablation study
다음은 구성 요소들에 대한 ablation 결과이다.

다음은 주제 마스킹에 대한 ablation 결과이다.

4. Extended Applications
다음은 ConsiStory에 ControlNet을 통합한 결과이다.

다음은 두 주제를 Edit Friendly DDPM-Inversion으로 반전한 후 앵커로 사용하여 학습 없는 개인화를 최초로 선보인 결과이다.
