[논문리뷰] Concept Sliders: LoRA Adaptors for Precise Control in Diffusion Models
ECCV 2024. [Paper] [Page] [Github]
Rohit Gandikota, Joanna Materzynska, Tingrui Zhou, Antonio Torralba, David Bau
Northeastern University | Massachusetts Institute of Technology
20 Nov 2023

Introduction
Text-to-image diffusion model의 사용자는 생성된 이미지에 표현된 시각적 속성과 개념을 현재 가능한 것보다 더 세밀하게 제어해야 하는 경우가 많다. 텍스트 프롬프트만 사용하면 사람의 나이나 날씨의 강도와 같은 연속적인 속성을 정밀하게 조정하는 것이 어려울 수 있으며, 이러한 제한은 제작자가 자신의 생각에 맞게 이미지를 조정하는 능력을 방해한다. 본 논문에서는 diffusion model 내에서 개념을 세밀하게 편집할 수 있는 해석 가능한 Concept Sliders를 도입하여 이러한 요구 사항을 해결한다. 본 논문의 방법은 제작자가 이미지 편집뿐만 아니라 생성 프로세스에 대한 충실도 높은 제어 기능을 제공한다.
Concept Sliders는 이전 방법으로는 잘 해결되지 않은 몇 가지 문제를 해결한다. 직접적인 프롬프트 수정은 많은 이미지 속성을 제어할 수 있지만 프롬프트를 변경하면 프롬프트-시드 조합에 대한 출력 민감도로 인해 전체 이미지 구조가 크게 변경되는 경우가 많다. PromptToPrompt나 Pix2Video와 같은 기술을 사용하면 diffusion process를 반전시키고 cross-attention을 수정하여 이미지의 시각적 개념을 편집할 수 있다. 그러나 이러한 방법은 각각의 새로운 개념에 대해 별도의 inference pass가 필요하며 제한된 편집만 지원한다. 단순하게 일반화할 수 있는 제어를 배우기보다는 개인의 이미지에 적합한 프롬프트 엔지니어링이 필요하며, 주의 깊게 프롬프팅하지 않으면 나이를 수정할 때 인종을 바꾸는 등 개념 간의 얽힘(entanglement)을 유발할 수 있다. 반면 Concept Sliders는 효율적인 합성과 최소한의 얽힘으로 하나의 inference pass에서 원하는 개념에 대한 정확하고 지속적인 제어를 가능하게 하는 사전 학습된 모델에 적용되는 가벼운 plug-and-play 어댑터를 제공한다.
각 Concept Slider는 diffusion model의 low-rank 수정이다. 저자들은 low-rank 제약이 개념에 대한 정밀 제어의 중요한 측면이라는 것을 발견했다. Low-rank regularization 없이 fine-tuning하면 정밀도와 이미지 품질이 감소하는 반면, low-rank 학습은 최소한의 개념 부분공간을 식별하여 제어되고 고품질이며 disentangle한 편집이 가능해진다. 모델 파라미터가 아닌 하나의 이미지에 대해 작동하는 이미지 편집 방법은 이 low-rank 프레임워크의 이점을 누릴 수 없다.
Concept Sliders를 사용하면 텍스트 설명으로 포착할 수 없는 시각적 개념을 편집할 수도 있다. 이는 텍스트에 의존하는 이전의 개념 편집 방법과 구별된다. 이미지 기반 모델 customization 방법은 새로운 이미지 기반 개념에 대한 새로운 토큰을 추가할 수 있지만 이미지 편집에는 사용하기 어렵다. 반면, Concept Sliders를 사용하면 사용자는 몇 개의 쌍을 이루는 이미지를 제공하여 원하는 컨셉을 정의할 수 있으며, 그런 다음 Concept Sliders는 시각적 컨셉을 일반화하고 이를 말로 설명하는 것이 불가능한 경우에도 다른 이미지에 적용한다.
GAN과 같은 다른 생성 이미지 모델은 이전에 생성된 출력에 대해 고도로 disentangle한 제어를 제공하는 latent space를 보여주었다. 특히, StyleGAN의 스타일 공간은 말로 설명하기 어려운 이미지의 많은 의미 있는 측면에 대한 세부적인 제어를 제공하는 것으로 관찰되었다. 저자들은 Concept Sliders의 능력을 추가로 입증하기 위해 FFHQ 얼굴 이미지로 학습된 StyleGAN의 스타일 공간에서 diffusion model로 latent 방향을 전송하는 Concept Sliders를 생성하는 것이 가능하다는 것을 보여주었다. 특히, 얼굴 데이터셋에서 시작되었음에도 불구하고 Concept Sliders는 latent를 성공적으로 조정하여 다양한 이미지 생성에 대한 미묘한 스타일 제어를 가능하게 한다. 이는 diffusion model이 텍스트 설명과 일치하지 않는 개념이라도 GAN latent에 표현된 복잡한 시각적 개념을 캡처할 수 있는 방법을 보여준다.
Concept Slider의 표현력은 사실성을 강화하고 손 왜곡을 수정하는 등 강력하다. 생성 모델이 사실적인 이미지 합성에서 상당한 진전을 이루었지만 Stable Diffusion XL과 같은 최신 diffusion model은 여전히 왜곡된 손, 뒤틀린 얼굴, 떠다니는 물체, 왜곡된 원근을 합성하는 경향이 있다. 저자들은 “현실적인 이미지”에 대한 Concept Slider와 “고정된 손”에 대한 Concept Slider가 모두 이미지 내용을 변경하지 않고 사실성에 통계적으로 유의미한 개선을 가져온다는 것을 검증했다.
Concept Sliders는 모듈식이며 합성 가능하다. 저자들은 출력 품질을 저하시키지 않고 50개 이상의 고유한 슬라이더를 합성할 수 있음을 발견했다. 이러한 다양성은 사용자에게 수많은 텍스트 Concept Slider, 시각적 Concept Slider, GAN에서 정의된 Concept Slider를 혼합할 수 있는 미묘한 이미지 제어의 새로운 세계를 제공한다. Concept Sliders는 표준 프롬프트 토큰 제한을 피하기 때문에 텍스트만으로 달성할 수 있는 것보다 더 복잡한 편집이 가능하다.
Method
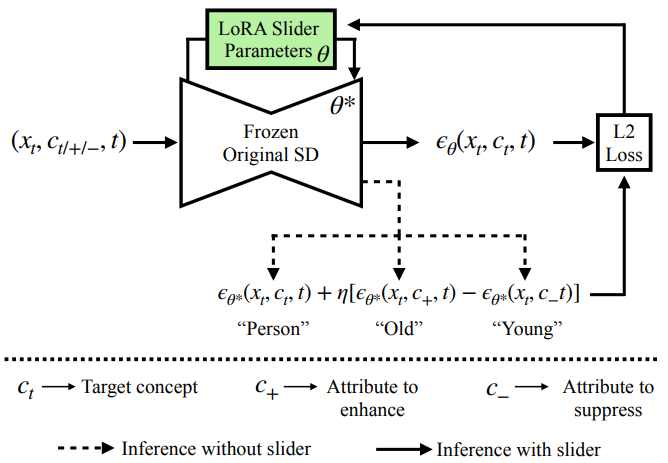
Concept Sliders는 위 그림과 같이 개념을 타겟으로 하는 이미지 제어를 가능하게 하기 위해 diffusion model에서 LoRA 어댑터를 fine-tuning하는 방법이다. 타겟 개념으로 컨디셔닝될 때 특정 속성의 표현을 늘리거나 줄이는 low-rank 파라미터 방향을 학습한다. 타겟 개념 $c_t$와 모델 $\theta$가 주어지면 $c_t$로 컨디셔닝될 때 이미지 $X$에서 속성 $c_{+}$와 $c_{−}$의 likelihood를 수정하는 $\theta^\ast$를 얻는 것이 목표이다. 즉, 속성 $c_{+}$의 likelihood를 높이고 속성 $c_{−}$의 likelihood를 줄이는 것이 목표이다.
여기서 $P_\theta (X \vert c_t)$는 $c_t$로 컨디셔닝될 때 원래 모델에 의해 생성된 분포를 나타낸다.
\[\begin{equation} P (c_{+} \vert X) = \frac{P (X \vert c_{+}) P (c_{+})}{P(X)} \end{equation}\]를 전개하면 로그 확률의 기울기, 즉 score \(\nabla \log P_{\theta^\ast} (X \vert c_t)\)는
\[\begin{equation} \nabla \log P_\theta (X \vert c_t) + \eta (\nabla \log P_\theta (X \vert c_{+}) - \nabla \log P_\theta (X \vert c_{-})) \end{equation}\]에 비례한다.
Tweedie’s formula와 DDPM의 reparametrization trick을 기반으로 시간에 따라 변하는 noising process를 도입하고 각 score를 denoising 예측 $\epsilon (X, c_t, t)$로 표현할 수 있다. 따라서 위 식은 다음과 같다.
\[\begin{equation} \epsilon_{\theta^\ast} (X, c_t, t) \leftarrow \epsilon_\theta (X, c_t, t) + \eta (\epsilon_\theta (X, c_{+}, t) - \epsilon_\theta (X, c_{-}, t)) \end{equation}\]위 식에서 제안된 score function은 타겟 개념 $c_t$의 분포를 이동하여 더 많은 $c_{+}$ 속성과 더 적은 $c_{−}$ 속성을 나타낸다. 실제로 하나의 프롬프트 쌍이 원하지 않는 속성과 얽힌 방향을 식별할 수 있는 경우가 있다. 따라서 최적화를 제약하기 위해 일련의 보존 개념 $p \in \mathcal{P}$를 통합한다 (ex. 연령을 편집하는 동안 인종 이름들을 통합). 단순히 $P_\theta (c_{+} \vert X)$를 늘리는 대신 모든 $p$에 대해 $P_\theta ((c_{+}, p) \vert X)$를 늘리고 $P_\theta ((c_{−}, p) \vert X)$를 줄이는 것을 목표로 한다. 이는 disentanglement 목적 함수로 이어진다.
\[\begin{equation} \epsilon_{\theta^\ast} (X, c_t, t) \leftarrow \epsilon_\theta (X, c_t, t) + \eta \sum_{p \in \mathcal{P}} (\epsilon_\theta (X, (c_{+}, p), t) - \epsilon_\theta (X, (c_{-}, p), t)) \end{equation}\]이 disentanglement 목적 함수는 사전 학습된 가중치를 고정한 상태로 유지하면서 Concept Slider 모듈을 fine-tuning한다. LoRA는 inference 시간에 수정될 수 있는 LoRA scaling factor $\alpha$를 도입한다. $\alpha$를 사용하면 편집 강도를 조정할 수 있다. $\alpha$를 늘리면 모델을 다시 학습시키지 않고도 편집이 더 강력해진다. 이전 모델 편집 방법은 증가된 guidance $\eta$를 사용하여 재학습을 통해 더 강력한 편집을 제공하였다. 그러나 Concept Sliders는 inference 시 $\alpha$를 간단히 조정하여 비용이 많이 드는 재학습 없이 편집을 강화하는 동일한 효과가 생성된다.
1. Learning Visual Concepts from Image Pairs
본 논문은 텍스트 프롬프트를 사용하여 지정하기 어려운 미묘한 시각적 개념을 제어하기 위해 슬라이더를 제안하였다. 저자들은 이러한 개념에 대한 슬라이더를 학습시키기 위해 작은 before/after 이미지 쌍 데이터셋을 활용하였다. 슬라이더는 이미지 쌍 $(x^A, x^B)$ 간의 대비를 통해 시각적 개념을 캡처하는 방법을 학습한다.
학습 시에는 negative 방향과 positive 방향 모두에 적용되는 LORA를 최적화한다. Positive LoRA를 적용하는 경우 \(ϵ_{\theta_{+}}\)라 쓰고, negative LORA를 적용하는 경우에는 \(ϵ_{\theta_{-}}\)라 쓴다. 그런 다음 다음과 같은 loss를 최소화한다.
\[\begin{equation} \| \epsilon_{\theta_{-}} (x_t^A, `\textrm{ '}, t) - \epsilon \|^2 + \| \epsilon_{\theta_{+}} (x_t^B, `\textrm{ '}, t) - \epsilon \|^2 \end{equation}\]이는 LORA가 A를 negative 방향으로 B를 positive 방향으로 정렬되도록 하는 효과가 있다. 이러한 방식으로 시각적으로 방향을 정의하면 사용자가 커스텀 아트워크를 통해 Concept Slider를 정의할 수 있을 뿐만 아니라, StyleGAN과 같은 다른 생성 모델에서 latent를 전송하는 데 사용하는 것과 동일한 방법이다.
Experiments
- 모델: Stable Diffusion XL (1024)
- Inference 시 구조와 의미를 유지하기 위해 SDEdit 테크닉을 따름
- 처음 $t$ step에 원래 사전 학습된 모델을 사용하고 LoRA 어댑터 multiplier를 0으로 설정하여 사전 학습된 모델을 유지한다.
- 나머지 step에서 LoRA 어댑터를 켠다.
1. Textual Concept Sliders
다음은 Prompt2Prompt와 성능을 비교한 표이다.
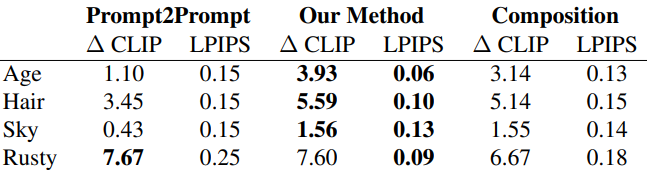
다음은 특정 개념을 세밀하게 편집하는 동시에 우수한 이미지 구조를 유지하는 정성적인 예시들이다.

2. Visual Concept Sliders
다음은 선택적 텍스트 guidance가 포함된 이미지 쌍 기반 Concept Sliders를 사용하여 눈썹 모양과 눈 크기와 같은 세밀한 속성을 제어한 결과이다.

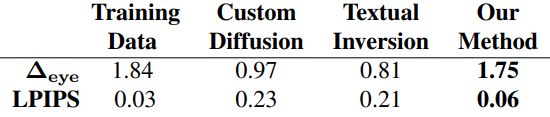
다음은 customization 방법들과 비교한 표이다. $\Delta_\textrm{eye}$는 원본 이미지와 비교하여 눈 크기의 변화 비율을 나타낸다.
3. Sliders transferred from StyleGAN
다음은 FFHQ 데이터셋에서 학습된 StyleGAN-v3 스타일 공간에서 전송된 슬라이더를 보여준다.

4. Composing Sliders
다음은 두 텍스트 기반 슬라이더를 합성한 결과이다.

다음은 여러 슬라이더를 점진적으로 합성한 결과이다.

Concept Sliders to Improve Image Quality
Fixing Hands
다음은 Stable Diffusion에서 손을 수정한 결과이다.

Repair Slider
다음은 repair slider를 사용하여 더욱 사실적이고 왜곡되지 않은 이미지를 생성한 예시들이다. Repair slider는 (a, b)의 왜곡된 인간과 애완동물, (b, c, d)의 부자연스러운 물체, (b, c)의 흐릿한 이미지와 같이 생성된 출력의 일부 결함을 수정하는 데 도움이 된다.

다음은 미세한 디테일에 대한 repair sliders의 효과를 보여주는 예시이다.

Ablations
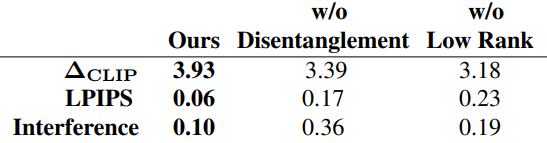
다음은 ablation study 결과이다.

Limitations
- 일부 residual effect가 여전히 관찰된다.
- Inference 시 사용되는 SDEdit 테크닉은 이미지 구조를 보존하는 데 도움이 되지만 편집 강도를 줄일 수 있다. SDEdit 접근 방식은 향상된 구조적 일관성을 위해 편집 강도를 절충한다.