[논문리뷰] Composer: Creative and Controllable Image Synthesis with Composable Conditions
arXiv 2023. [Paper] [Page] [Github]
Lianghua Huang, Di Chen, Yu Liu, Yujun Shen, Deli Zhao, Jingren Zhou
Alibaba Group | Ant Group
20 Feb 2023
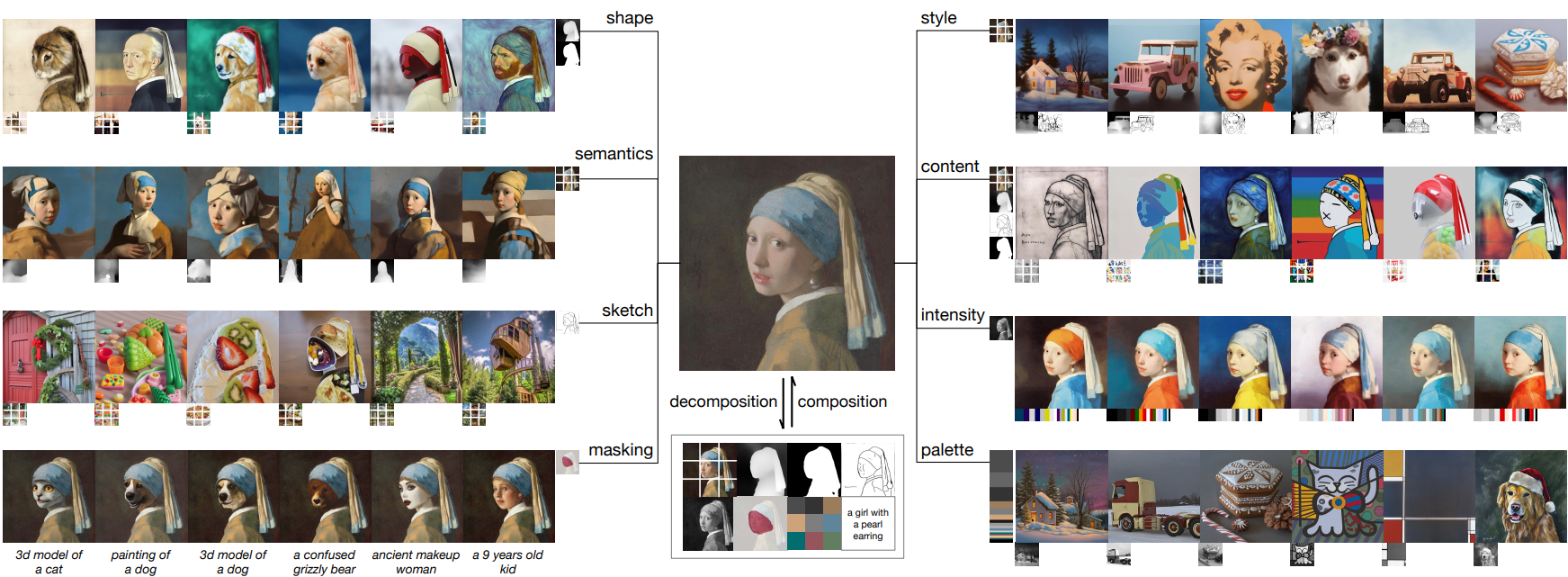
Introduction
텍스트에 기반한 생성 이미지 모델은 이제 사실적이고 다양한 이미지를 생성할 수 있다. 맞춤형 생성을 더욱 달성하기 위해 최근의 많은 연구들은 segmentation map, 장면 그래프, 스케치, 깊이 맵, inpainting mask와 같은 조건을 도입하거나 몇 가지 주제별 데이터에서 사전 학습된 모델을 fine-tuning하여 text-to-image 모델을 확장한다. 그럼에도 불구하고 이러한 모델은 실제 애플리케이션에 사용할 때 제한된 수준의 제어 가능성만 제공한다.
저자들은 제어 가능한 이미지 생성의 핵심이 컨디셔닝뿐만 아니라 합성에 더 크게 의존한다고 주장한다. 후자는 엄청난 수의 잠재적 조합을 도입하여 제어 공간을 기하급수적으로 확장할 수 있다. 예를 들어, 각각 8개의 표현이 있는 100개의 이미지는 약 $100^8$개의 조합을 생성한다. 유사한 개념이 언어 및 장면 이해 분야에서 탐색되며, 여기서 합성성 (compositionality)은 제한된 수의 알려진 구성 요소에서 잠재적으로 무한한 수의 새로운 조합을 인식하거나 생성하는 기술인 합성적 일반화 (compositional generalization)라고 한다.
본 논문에서는 위의 아이디어를 기반으로 합성적 생성 모델의 구현인 Composer를 제시한다. 합성적 생성 모델이란 시각적 구성 요소를 매끄럽게 재결합하여 새로운 이미지를 생성할 수 있는 생성 모델을 말한다. 구체적으로 UNet backbone이 있는 다중 조건부 diffusion model로 Composer를 구현한다. Composer의 모든 학습 iteration에는 두 가지 단계가 있다. 분해 단계에서는 컴퓨터 비전 알고리즘 또는 사전 학습된 모델을 사용하여 배치의 이미지를 개별 표현으로 분해한다. 반면 합성 단계에서는 Composer를 최적화하여 표현 부분 집합에서 이러한 이미지를 재구성할 수 있다. Composer는 재구성 목적 함수로만 학습하였음에도 불구하고 서로 다른 소스에서 나올 수 있고 잠재적으로 서로 호환되지 않을 수 있는 보지 못한 표현 조합에서 새로운 이미지를 디코딩할 수 있다.
개념적으로 간단하고 구현하기 쉬운 Composer는 놀라울 정도로 강력하여 기존 및 이전에 탐색되지 않은 이미지 생성 및 조작 task 모두에서 성능을 향상할 수 있으며, 이에 국한되지 않는다. 또한 마스킹의 직교 표현을 도입함으로써 Composer는 위의 모든 연산에 대해 편집 가능한 영역을 사용자 지정 영역으로 제한할 수 있으며 기존의 인페인팅 연산보다 더 유연하며 이 영역 외부의 픽셀 수정도 방지할 수 있다. Composer는 멀티태스킹 방식으로 학습되었음에도 불구하고 캡션만 조건으로 사용할 때 COCO 데이터셋에서 text-to-image 합성에서 9.2의 zero-shot FID를 달성하여 고품질의 결과를 생성하는 능력을 나타낸다.
Method
Composer의 프레임워크는 이미지가 일련의 독립적인 구성 요소로 나뉘는 분해 단계와 구성 요소가 조건부 diffusion model을 사용하여 재조립되는 합성 단계로 구성된다.
1. Decomposition
이미지를 다양한 측면을 캡처하는 분리된 표현으로 분해한다. 본 논문에서는 8개의 표현을 사용하며, 모두 학습 중에 즉석에서 추출된다.
- 캡션: 이미지-텍스트 학습 데이터 (ex. LAION-5B)의 제목 또는 설명 정보를 이미지 캡션으로 직접 사용한다. 주석을 사용할 수 없는 경우 사전 학습된 이미지 캡션 모델을 활용할 수도 있다. 사전 학습된 CLIP ViT-L/14 모델에서 추출한 문장 임베딩과 단어 임베딩을 사용하여 이러한 캡션을 나타낸다.
- Semantic과 스타일: 사전 학습된 CLIP ViT-L/14 모델에서 추출한 이미지 임베딩을 사용하여 unCLIP과 유사하게 이미지의 의미와 스타일을 나타낸다.
- 색상: 매끄러운 CIELab 히스토그램을 사용하여 이미지의 색상 통계를 나타낸다. CIELab 색상 공간을 11개의 색조 값, 5개의 채도 값, 5개의 조명 값으로 양자화하고 smoothing sigma 10을 사용한다.
- 스케치: 이미지의 스케치를 추출하기 위해 스케치 단순화 알고리즘이 뒤따르는 가장자리 감지 모델을 적용한다. 스케치는 이미지의 로컬 디테일을 캡처하고 semantic이 적다.
- 인스턴스: 인스턴스 마스크를 추출하기 위해 사전 학습된 YOLOv5 모델을 사용하여 이미지에 instance segmentation을 적용한다. Instance segmentation mask는 객체의 카테고리와 모양 정보를 반영한다.
- 깊이 맵: 사전 학습된 단안 깊이 추정 모델을 사용하여 이미지의 레이아웃을 대략적으로 캡처하는 이미지의 깊이 맵을 추출한다.
- 강도: 모델이 색상을 조작하기 위해 그레이스케일 이미지를 도입한다. 랜덤성을 도입하기 위해 사전 정의된 RGB 채널 가중치 집합에서 균일하게 샘플링하여 그레이스케일 이미지를 생성한다.
- 마스킹: Composer가 이미지 생성 또는 조작을 편집 가능한 영역으로 제한할 수 있도록 이미지 마스크를 도입한다. 4채널 표현을 사용한다. 처음 3개 채널은 마스킹된 RGB 이미지에 해당하고 마지막 채널은 이진 마스크에 해당한다.
2. Composition
Diffusion model을 사용하여 일련의 표현에서 이미지를 재구성한다. 특히 GLIDE 아키텍처를 활용하고 컨디셔닝 모듈을 수정한다. 저자들은 표현에 따라 모델을 컨디셔닝하는 두 가지 다른 메커니즘을 탐색하였다.
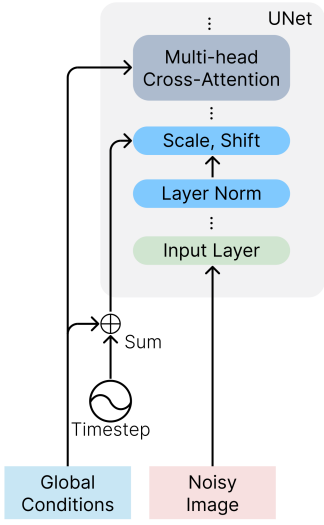
- 글로벌 컨디셔닝: CLIP 문장 임베딩, 이미지 임베딩, 색상 팔레트를 포함한 글로벌 표현의 경우 timestep 임베딩에 project하고 더한다. 또한 이미지 임베딩과 색상 팔레트를 8개의 추가 토큰으로 project하고 이를 CLIP 단어 임베딩과 연결한 다음 unCLIP과 유사하게 GLIDE에서 cross-attention을 위한 컨텍스트로 사용한다. 조건은 부가적이거나 cross 주의에서 선택적으로 마스킹될 수 있으므로 학습 및 inference 중에 조건을 삭제하거나 새로운 글로벌 조건을 도입하는 것이 간단하다.
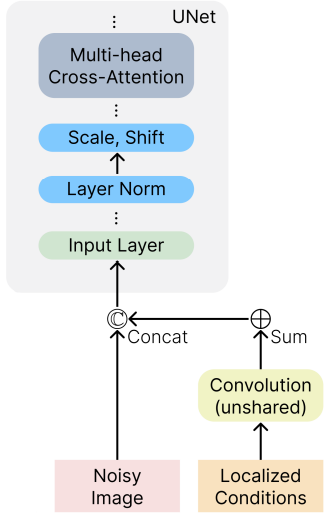
- 로컬 컨디셔닝: 스케치, segmentation mask, 깊이 맵, 강도 이미지, 마스킹된 이미지를 포함한 로컬 표현의 경우 스택된 convolution layer를 사용하여 noisy latent $x_t$와 동일한 공간 크기로 균일한 차원 임베딩으로 project한다. 그런 다음 이러한 임베딩의 합계를 계산하고 결과를 UNet에 공급하기 전에 $x_t$에 concat한다. 임베딩은 부가적이기 때문에 누락된 조건을 수용하거나 새로운 로컬 조건을 통합하기 쉽다.
- 공동 학습 전략: 모델이 다양한 조건 조합에서 이미지를 디코딩하는 방법을 학습할 수 있도록 공동 학습 전략이 필수적이다. 여러 합성을 실험하고 간단하면서도 효과적인 합성을 식별한다. 여기에서 각 조건에 대해 0.5의 독립적인 dropout 확률, 모든 조건을 삭제할 확률 0.1, 모든 조건을 유지하는 확률 0.1을 사용한다. 강도 이미지에 대해 0.7의 특수 dropout 확률을 사용한다. 이는 이미지에 대한 대부분의 정보가 포함되어 있고 학습 중에 다른 조건에 가중치를 줄 수 있기 때문이다.
글로벌 컨디셔닝 모듈 (왼쪽)과 로컬 컨디셔닝 모듈 (오른쪽)의 개요는 아래 그림과 같다.
기본 diffusion model은 64$\times$64 해상도의 이미지를 생성한다. 고해상도 이미지를 생성하기 위해 64$\times$64에서 256$\times$256으로, 256$\times$256에서 1024$\times$1024 해상도로 업샘플링하기 위해 두 개의 unconditional diffusion model을 학습한다. 업샘플링 모델의 아키텍처는 unCLIP에서 수정되어 저해상도 레이어에서 더 많은 채널을 사용하고 self-attention 블록을 도입하여 용량을 확장한다. 또한 캡션에서 이미지 임베딩을 생성하는 선택적 prior 모델을 도입한다. 저자들은 경험적으로 prior 모델이 특정 조건 조합에 대해 생성된 이미지의 다양성을 향상시킬 수 있음을 발견했다.
Experiments
- 데이터셋: ImageNet21K, WebVision, LAION
1. Image Manipulation
다음은 image variation과 image interpolation 결과이다.

다음은 이미지 재구성 결과이다.

다음은 영역별 이미지 편집 결과이다.

2. Reformulation of Traditional Generation Tasks
다음은 Composer를 사용하여 기존 이미지 생성 task를 재구성한 것이다.
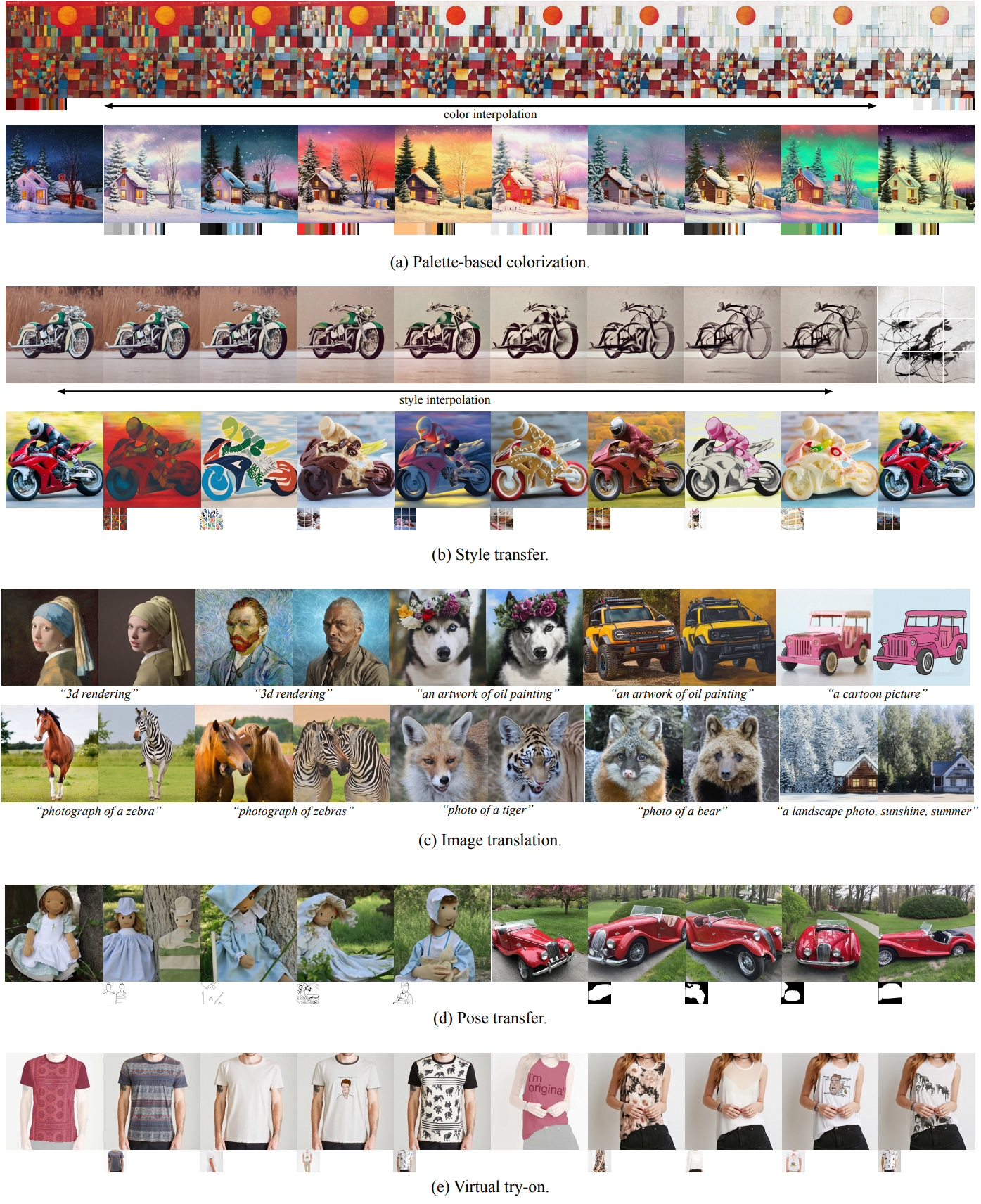
3. Compositional Image Generation
다음은 합성적 이미지 생성 결과이다.

4. Text-to-Image Generation
저자들은 Composer의 이미지 생성 품질을 추가로 평가하기 위해 COCO 데이터셋에서 최신 text-to-image 모델과 성능을 비교하였다. 멀티태스킹 학습에도 불구하고 Composer는 COCO에서 경쟁력 있는 FID 점수 9.2와 CLIP 점수 0.28를 달성하여 최고 성능 모델과 견줄 수 있다.