[논문리뷰] COLMAP-Free 3D Gaussian Splatting (CF-3DGS)
CVPR 2024. [Paper] [Page]
Yang Fu, Sifei Liu, Amey Kulkarni, Jan Kautz, Alexei A. Efros, Xiaolong Wang
UC San Deigo | NVIDIA | UC Berkeley
12 Dec 2023

Introduction
사실적인 장면 재구성 및 뷰 합성 분야는 NeRF의 등장으로 크게 발전했다. NeRF 학습에 중요한 초기화 단계는 먼저 각 입력 이미지에 대한 카메라 포즈를 준비하는 것이다. 이는 일반적으로 Structure-from-Motion (SfM) 라이브러리 COLMAP을 실행하여 수행된다. 그러나 이 전처리는 시간이 많이 걸릴 뿐만 아니라 feature 추출 오차에 대한 민감성과 텍스처가 없거나 반복적인 영역을 처리하는 데 어려움이 있기 때문에 실패할 수도 있다.
최근 연구들에서는 NeRF 프레임워크 내에 pose estimation을 직접 통합하여 SfM에 대한 의존도를 줄이는 데 중점을 두었다. 3D 장면 재구성과 카메라 등록을 동시에 해결하는 것은 컴퓨터 비전에서 오랫동안 닭이 먼저냐 달걀이 먼저냐의 문제였다. 이 문제는 최적화 프로세스에 종종 추가 제약이 포함되는 NeRF와 암시적 표현의 맥락에서 더욱 증폭된다. 최근 제안된 Nope-NeRF는 학습시키는 데 오랜 시간(30시간)이 걸리며 카메라 포즈가 많이 바뀌면(ex. 360도) 잘 작동하지 않는다. 기본적으로 NeRF는 카메라 위치에서 ray casting을 업데이트하여 간접적인 방법으로 카메라 파라미터를 최적화하므로 최적화가 어려워진다.
3D Gaussian Splatting (3DGS)의 등장으로 NeRF의 볼륨 렌더링이 포인트 클라우드를 수용하도록 확장되었다. 3DGS는 원래 사전 계산된 카메라를 사용하여 제안되었지만 본 논문은 SfM 전처리 없이 뷰 합성을 수행할 수 있는 새로운 기회를 제공한다. 저자들은 동영상의 시간적 연속성과 명시적인 포인트 클라우드 표현이라는 두 가지 핵심 요소를 활용하는 COLMAP-Free 3D Gaussian Splatting(CF-3DGS)을 제안하였다.
저자들은 한 번에 모든 프레임을 최적화하는 대신, 카메라가 움직일 때 한 번에 한 프레임씩 성장하는 지속적인 방식으로 장면의 3D Gaussian을 구축하는 것을 제안하였다. 이 과정에서 각 프레임에 대한 local 3D Gaussian 집합을 추출하고 전체 장면의 global 3D 가우스 집합도 유지 관리한다. \(t = \{1, \cdots, T\}\) 프레임들을 순차적으로 반복한다고 가정하면 매번 2단계 절차를 수행한다.
- 주어진 프레임 $t − 1$에 대해 local 3D Gaussian 집합을 구성하고 다음 근처 프레임 $t$를 샘플링한다. 프레임 $t$의 픽셀을 렌더링하기 위해 프레임 $t-1$의 3D Gaussian을 변환할 수 있는 affine transformation을 배우는 것이 목표이다. 뉴럴 렌더링은 기본적으로 프레임 $t - 1$과 $t$ 사이의 relative pose인 affine transformation을 최적화하기 위한 gradient를 제공한다. 명시적 포인트 클라우드 표현을 사용하면 NeRF에서는 불가능했던 affine transformation을 직접 적용할 수 있고 두 프레임이 가까워(시간적 연속성) transformation이 상대적으로 작아지기 때문에 이 최적화는 어렵지 않다.
- 프레임 $t-1$과 $t$ 사이의 relative pose를 얻으면 첫 번째 프레임과 프레임 $t$ 사이의 relative pose를 추론할 수 있다. 이를 통해 현재 프레임 정보를 global 3D Gaussian 집합으로 집계할 수 있으며, 여기서 현재 및 모든 이전 프레임과 카메라 포즈로 최적화를 수행한다.
Method
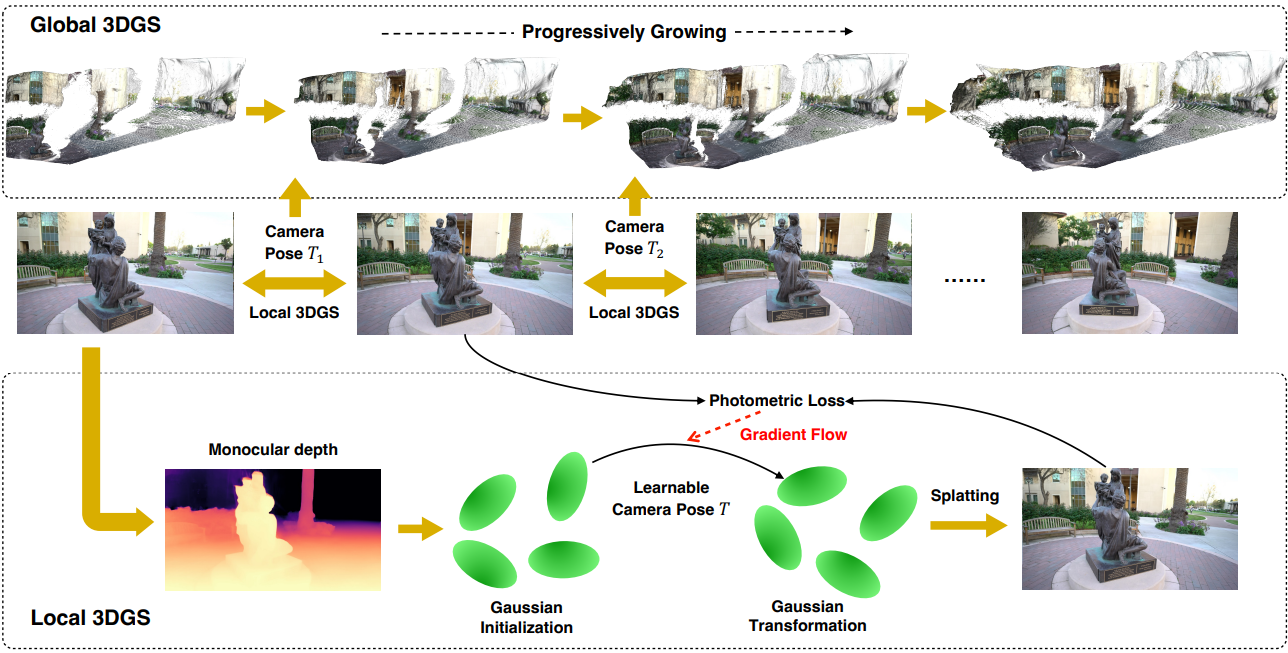
본 논문의 목표는 camera intrinsic과 함께 포즈가 지정되지 않은 일련의 이미지가 주어지면 카메라 포즈를 복구하고 사진처럼 사실적인 장면을 재구성하는 것이다. 이를 위해 3D Gaussian Splatting(3DGS)과 카메라 포즈를 동시에 최적화하는 CF-3DGS를 제안하였다.
1. Local 3DGS for Relative Pose Estimation
이전 연구에서는 카메라 매개변수를 추정하는 동시에 NeRF를 최적화하는 타당성을 입증했다. 이는 일반적으로 다양한 정규화 항과 geometric prior의 통합을 포함한다. 그러나 대부분의 기존 방법은 카메라 포즈를 직접 최적화하는 대신 다양한 카메라 위치에서 ray casting 프로세스를 최적화하는 데 우선순위를 둔다. 이는 암시적 표현의 특성과 NeRF의 ray tracing 구현에 따라 결정된다. 이러한 간접적인 접근 방식은 대규모 카메라 이동 시나리오에서 복잡하고 어려운 최적화를 초래하는 경우가 많다.
반면에 3DGS는 최근 동적 장면에 대한 적용에서 입증된 것처럼 간단한 변형과 이동을 가능하게 하는 포인트 클라우드 형태의 명시적인 장면 표현을 활용한다. 3DGS를 활용하기 위해 local 3DGS를 도입하여 상대적인 카메라 포즈를 추정한다.
카메라 포즈와 Gaussian point의 3D rigid transformation 사이의 관계는 아래와 같다. 중심 $\mu$가 있는 3D Gaussian 집합이 주어졌을 때 카메라 포즈 $W$로 투영하면 다음과 같은 결과가 나온다.
\[\begin{equation} \mu_\textrm{2D} = K (W \mu) / (W \mu)_z \end{equation}\]여기서 $K$는 intrinsic projection matrix이다. 대안적으로, 2D projection $\mu_{2D}$는 rigid transform된 포인트 집합의 직교 방향 $\mathbb{I}$로부터 얻을 수 있다. 즉 $\mu^\prime = W \mu$는 \(\mu_{2D} := K(\mathbb{I} \mu^\prime)/(\mathbb{I} \mu_\prime)_z\)를 생성한다. 따라서 카메라 포즈 $W$를 추정하는 것은 3D Gaussian point의 transformation을 추정하는 것과 동일하다. 이 결과를 바탕으로 저자들은 상대적인 카메라 포즈를 추정하기 위해 다음과 같은 알고리즘을 설계했다.
Initialization from a single view
위 그림의 하단 부분에서 볼 수 있듯이, timestep $t$의 프레임 $I_t$가 주어지면 먼저 기존 monocular depth network, 즉 DPT를 활용하여 monocular depth $D_t$를 생성한다. $D_t$가 카메라 파라미터 없이도 강력한 기하학적 단서를 제공한다는 점을 고려하여 원래 SfM 점 대신 카메라의 intrinsic과 orthogonal projection을 활용하여 monocular depth에서 들어 올린 점으로 3DGS를 초기화한다. 초기화 후 렌더링된 이미지와 현재 프레임 $I_t$ 간의 photometric loss를 최소화하기 위해 모든 속성을 갖춘 3D Gaussian 집합 $G_t$를 학습시킨다. Experiments
\[\begin{equation} G_t^\ast = \underset{c_t, r_t, s_t, \alpha_t}{\arg \min} \, \mathcal{L}_\textrm{rgb} (\mathcal{R} (G_t), I_t) \end{equation}\]여기서 $\mathcal{R}$은 3DGS 렌더링 프로세스이다. Photometric loss \(\mathcal{L}_\textrm{rgb}\)는 D-SSIM과 결합된 \(\mathcal{L}_1\)이다.
\[\begin{equation} \mathcal{L}_\textrm{rgb} = (1 - \lambda) \mathcal{L}_1 + \lambda \mathcal{L}_\textrm{D-SSIM} \end{equation}\]저자들은 모든 실험에 $\lambda = 0.2$를 사용하였다. 이 단계는 실행하기에 매우 가벼우며 입력 프레임에 맞추는 데 약 5초밖에 걸리지 않는다.
Pose Estimation by 3D Gaussian Transformation
상대적인 카메라 포즈를 추정하기 위해 학습 가능한 SE-3 affine transformation $T_t$를 통해 사전 학습된 3D Gaussian $G_t^\ast$를 프레임 $t + 1$로 변환한다. 이는 $G_{t+1} = T_t \odot G_t$로 표시된다. Transformation $T_t$는 렌더링된 이미지와 다음 프레임 $I_{t+1}$ 사이의 photometric loss를 최소화하여 최적화된다.
\[\begin{equation} T_t^\ast = \underset{T_t}{\arg \min} \, \mathcal{L}_\textrm{rgb} (\mathcal{R} (T_t \odot G_t), I_{t+1}) \end{equation}\]앞서 언급한 최적화 과정에서 사전 학습된 3D Gaussian $G_t^\ast$의 모든 속성을 고정하여 3D Gaussian point의 deformation, densification, pruning, self-rotation에서 카메라 움직임을 분리한다. Transformation $T$는 quaternion rotation $\mathbf{q} \in \textrm{so}(3)$와 translation vector $\mathbf{t} \in \mathbb{R}^3$의 형태로 표현된다. 두 개의 인접한 프레임이 가깝기 때문에 transformation이 상대적으로 작고 최적화하기가 더 쉽다. 초기화 단계와 유사하게 포즈 최적화 단계도 매우 효율적이며 일반적으로 5~10초만 필요하다.
2. Global 3DGS with Progressively Growing
모든 이미지 쌍에 로컬 3DGS를 사용함으로써 첫 번째 프레임과 timestep $t$의 모든 프레임 사이의 relative pose를 추론할 수 있다. 그러나 이러한 relative pose는 노이즈가 많아 전체 장면에 대해 3DGS를 최적화하는 데 극적인 영향을 미칠 수 있다. 이 문제를 해결하기 위해 저자들은 순차적인 방식으로 점진적으로 global 3DGS를 학습할 것을 제안하였다.
위 그림의 상단 부분에서 설명한 것처럼 $t$번째 프레임 $I_t$부터 시작하여 앞서 언급한 것처럼 카메라 포즈를 orthogonal로 설정하여 3D Gaussain point 집합을 먼저 초기화한다. 그런 다음 local 3DGS를 활용하여 프레임 $I_t$와 $I_{t+1}$ 사이의 상대적인 카메라 포즈를 추정한다. 그런 다음 global 3DGS는 추정된 relative pose와 관찰된 두 프레임을 입력으로 사용하여 $N$ iteration에 걸쳐 모든 속성과 함께 3D Gaussian point 집합을 업데이트한다. 다음 프레임 $I_{t+2}$가 사용 가능해지면 이 프로세스가 반복된다. 즉, $I_{t+1}$과 $I_{t+2}$ 사이의 relative pose를 추정하고 이어서 $I_t$와 $I_{t+2}$ 사이의 relative pose를 추론한다.
새로운 뷰를 포괄하도록 global 3DGS를 업데이트하기 위해 새로운 프레임이 도착할 때 “under-reconstruction”인 Gaussian들을 densify한다. 3DGS에서 제안한 대로, view-space 위치 기울기의 평균 크기에 따라 densification 후보를 결정한다. 직관적으로, 관찰되지 않은 프레임에는 항상 아직 잘 재구성되지 않은 영역이 포함되어 있으며 최적화에서는 큰 gradient step을 사용하여 Gaussian들을 이동하려고 한다. 따라서 관찰되지 않은 콘텐츠와 영역에 densification을 집중시키기 위해 새 프레임을 추가하는 속도에 맞춰 $N$ step마다 global 3DGS를 densify한다. 또한 학습 단계 중간에 densification을 중단하는 대신 입력 시퀀스가 끝날 때까지 3D Gaussian point를 계속 증가시킨다. Local 3GDS와 global 3DGS를 반복적으로 적용함으로써 global 3DGS는 초기의 부분적인 포인트 클라우드에서 전체 시퀀스에 걸쳐 전체 장면을 포괄하는 완성된 포인트 클라우드로 점진적으로 성장하고 동시에 사실적인 재구성과 정확한 카메라 포즈 추정을 달성한다.
Experiments
- 데이터셋: Tanks and Temples, CO3D-V2
- 구현 디테일:
- 3DGS의 설정에 따라 최적화 파라미터를 따름
- 전체 장면의 점진적인 성장을 달성하기 위해 새 프레임을 추가하는 step 수를 포인트 densification 간격과 동일하게 설정
- 학습 프로세스가 끝날 때까지 불투명도를 계속 재설정하여 관찰된 프레임에서 설정된 Gaussian 모델에 새 프레임을 통합
- 카메라 포즈는 quaternion rotation $\mathbf{q} \in \textrm{so}(3)$와 translation vector $\mathbf{t} \in \mathbb{R}^3$의 표현에서 최적화됨
- 초기 learning rate는 $10^{-5}$이고 수렴할 때까지 $10^{-6}$으로 감소
- 단일 RTX 3090 GPU에서 실험 진행
1. Comparing with Pose-Unknown Methods
다음은 Tanks and Temples에서의 새로운 뷰 합성 결과를 정량적으로 비교한 것이다.
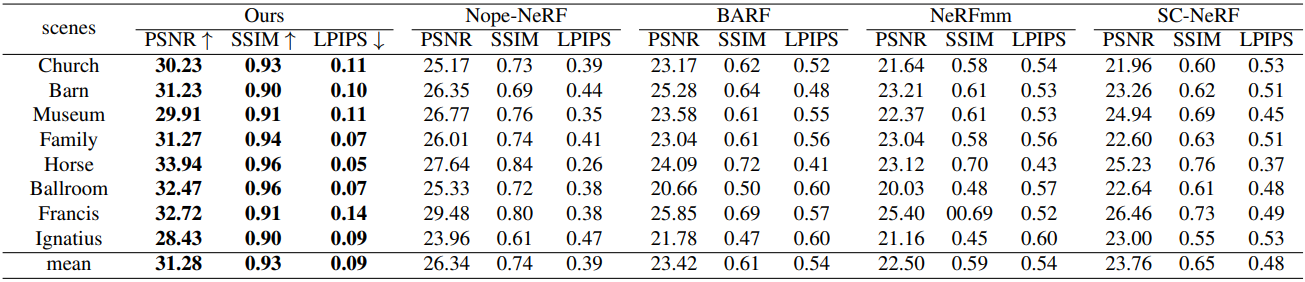
다음은 Tanks and Temples에서의 새로운 뷰 합성 결과를 비교한 것이다.

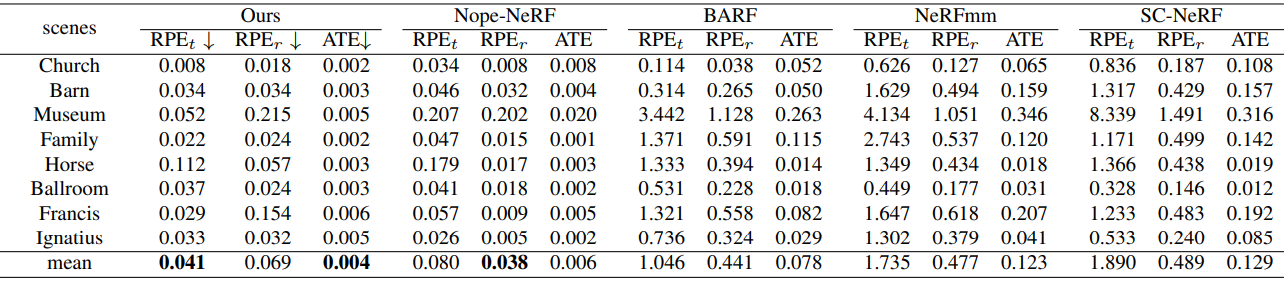
다음은 Tanks and Temples에서의 pose estimation를 정량적으로 비교한 표이다.
2. Results on Scenes with Large Camera Motions
다음은 CO3D V2에서의 새로운 뷰 합성 결과를 정량적으로 비교한 표이다.

다음은 CO3D V2에서의 pose estimation를 정량적으로 비교한 표이다.

다음은 CO3D V2에서의 새로운 뷰 합성 및 pose estimation 결과를 비교한 것이다.

3. Ablation Study
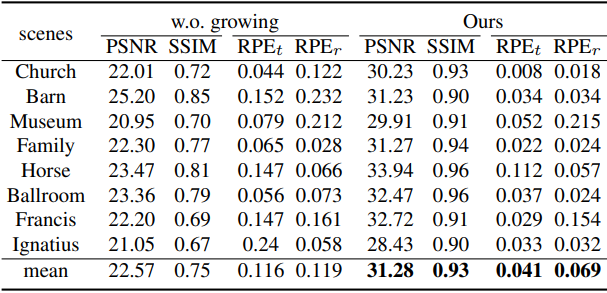
다음은 점진적인 성장에 대한 ablation 결과이다. (Tanks and Temples)
다음은 depth loss에 대한 ablation 결과이다. (Tanks and Temples)
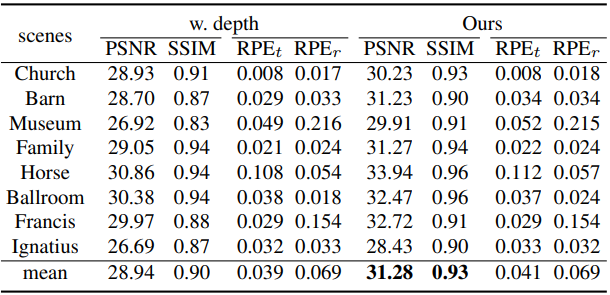
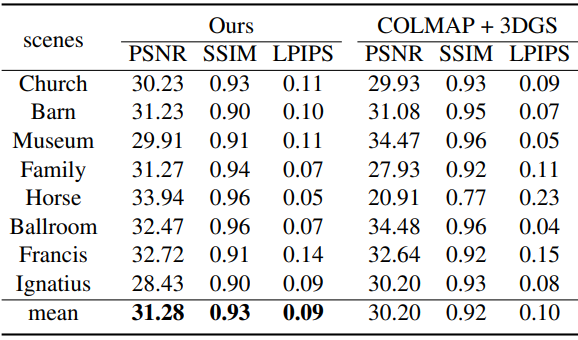
다음은 COLMAP 포즈로 학습된 3DGS 비교한 표이다.
Limitations
본 논문이 제안하는 방법은 카메라 포즈와 3DGS를 순차적인 방식으로 공동으로 최적화하므로 주로 동영상 스트림이나 정렬된 이미지 컬렉션에만 적용할 수 있다.