[논문리뷰] Training Large Language Models to Reason in a Continuous Latent Space
arXiv 2024. [Paper]
Shibo Hao, Sainbayar Sukhbaatar, DiJia Su, Xian Li, Zhiting Hu, Jason Weston, Yuandong Tian
FAIR at Meta | UC San Diego
9 Dec 2024
Introduction
LLM이 추론을 위해 언어를 사용할 때 중요한 문제가 발생한다. 각 추론 토큰에 필요한 추론의 양은 서로 크게 다르지만, 현재 LLM 아키텍처는 각 토큰을 예측하는 데 거의 동일한 컴퓨팅 예산을 할당한다. 추론 체인의 대부분 토큰은 유창성을 위해서만 생성되며 실제 추론 프로세스에 거의 기여하지 않는다. 반대로 일부 중요한 토큰은 복잡한 계획이 필요하고 LLM에 큰 어려움을 준다.
이전 연구에서는 LLM이 간결한 추론 체인을 생성하도록 촉구하거나 일부 중요한 토큰을 생성하기 전에 추가 추론을 수행하여 이러한 문제를 해결하려고 시도했지만, 이러한 방법은 언어 공간 내에서 제한을 받고 근본적인 문제를 해결하지 못한다. LLM이 언어적 제약 없이 추론할 수 있는 자유를 갖고 필요한 경우에만 결과를 언어로 번역하는 것이 이상적이다.
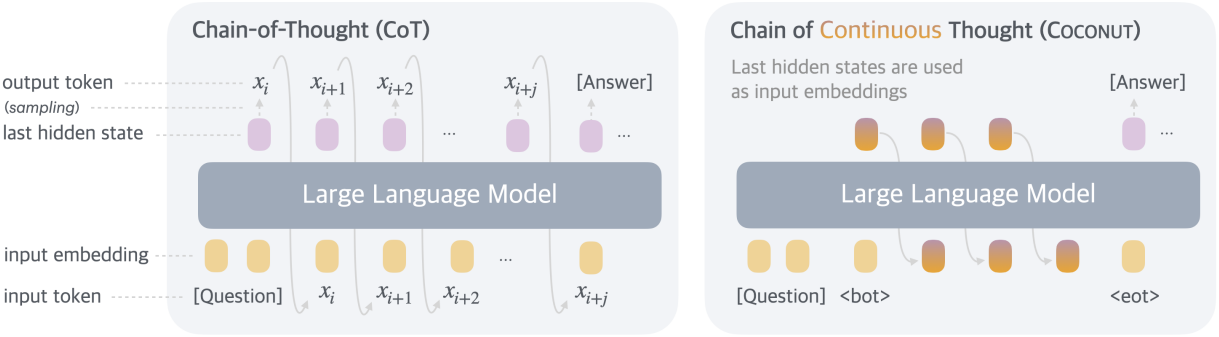
본 논문에서는 새로운 패러다임인 Coconut (Chain of Continuous Thought)을 도입하여 latent space에서의 LLM 추론을 탐구하였다. 여기에는 기존 CoT (Chain of Thought) 프로세스에 대한 간단한 수정이 포함된다. 언어 모델 head와 임베딩 레이어를 사용하여 hidden state와 언어 토큰을 매핑하는 대신, Coconut은 마지막 hidden state를 다음 토큰의 입력 임베딩으로 직접 공급한다. 이 수정은 추론이 언어 공간 내에 있지 않도록 하고, 완전히 미분 가능하기 때문에 gradient descent를 통해 시스템을 end-to-end로 최적화할 수 있다. 저자들은 latent 추론의 학습을 강화하기 위해 다단계 학습 전략을 채택하여 언어 추론 체인을 효과적으로 활용하여 학습 프로세스를 가이드하였다.
Coconut은 효율적인 추론 패턴으로 이어진다. 언어 기반 추론과 달리, Coconut의 continuous thought은 잠재적인 여러 다음 단계를 동시에 인코딩할 수 있어 너비 우선 탐색(BFS)과 유사한 추론 프로세스가 가능하다. 이 모델은 처음에는 올바른 결정을 내리지 못할 수 있지만, continuous thought 내에서 많은 가능한 옵션을 유지하고 추론을 통해 잘못된 경로를 점진적으로 제거할 수 있다. 이 고급 추론 메커니즘은 모델이 이런 방식으로 작동하도록 명시적으로 학습되거나 지시받지 않았음에도 불구하고 기존의 CoT를 능가한다.
Coconut은 LLM의 추론 능력을 성공적으로 향상시킨다. 수학적 추론의 경우, continuous thought을 사용하는 것이 추론 정확도에 유익한 것으로 나타났다. 이는 continuous thought을 체인으로 연결하여 점점 더 어려워지는 문제를 확장하고 해결할 수 있는 잠재력을 나타낸다. 논리적 추론의 경우, Coconut은 추론 중에 훨씬 적은 토큰을 생성하면서도 언어 기반 CoT 방법을 능가하였다.
Method
입력 시퀀스 $x = (x_1, \ldots, x_T)$에 대하여, 표준 LLM $\mathcal{M}$은 다음과 같이 설명할 수 있다.
\[\begin{equation} H_t = \textrm{Transformer}(E_t) \\ \mathcal{M}(x_{t+1} \vert x_{\le t}) = \textrm{softmax} (W h_t) \end{equation}\]- $E_t = [e(x_1), \ldots, e(x_t)]$: 위치 $t$까지의 토큰 임베딩 시퀀스
- $H_t \in \mathbb{R}^{t \times d}$: 위치 $t$까지의 모든 토큰에 대한 마지막 hidden state의 행렬
- $h_t$: 위치 $t$의 마지막 hidden state ($h_t = H_t [t, :]$)
- $e(\cdot)$: 토큰 임베딩 함수
- $W$: 언어 모델 head의 파라미터
Overview
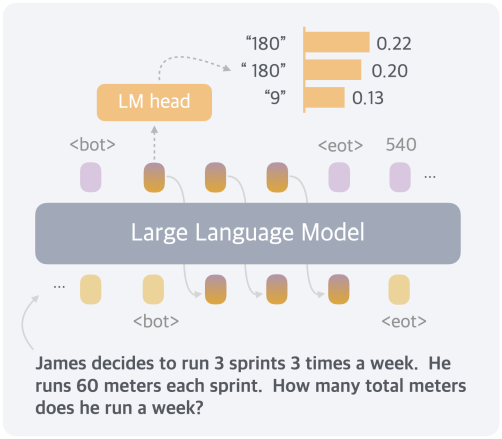
제안된 Coconut 방식에서 LLM은 “언어 모드”와 “latent 모드” 사이를 전환한다. 언어 모드에서 모델은 표준 언어 모델로 작동하여 다음 토큰을 autoregressive하게 생성한다. Latent 모드에서는 마지막 hidden state를 다음 입력 임베딩으로 직접 활용한다. 이 마지막 hidden state는 “continuous thought”이라고 하는 현재 추론 상태를 나타낸다.
특수 토큰 $\langle \textrm{bot} \rangle$와 $\langle \textrm{eot} \rangle$는 각각 latent 모드의 시작과 끝을 표시하는 데 사용된다. 예를 들어, latent 추론이 위치 $i$와 $j$ 사이에서 발생한다고 가정하면, $x_i = \langle \textrm{bot} \rangle$과 $x_j = \langle \textrm{eot} \rangle$이다. 이 경우, 모델이 latent 모드에 있을 때 ($i < t < j$), 이전 토큰의 마지막 hidden state를 사용하여 입력 임베딩을 대체한다.
\[\begin{equation} E_t = [e(x_1), e(x_2), \ldots, e(x_i), h_i, h_{i+1}, \ldots, h_{t-1}] \end{equation}\]Latent 모드가 완료된 후 ($t \ge j$), 입력은 다시 토큰 임베딩을 사용한다.
\[\begin{equation} E_t = [e(x_1), e(x_2), \ldots, e(x_i), h_i, h_{i+1}, \ldots, h_{j-1}, e(x_j), \ldots, e(x_t)] \end{equation}\]마지막 hidden state는 최종 normalization layer에서 처리되었으므로 크기가 너무 크지 않다. Latent thought은 언어 공간으로 다시 매핑되도록 의도되지 않았으므로 $i < t < j$일 때 \(\mathcal{M} (x_{t+1} \vert x_{\le t})\)는 정의되지 않는다. 그러나 $\textrm{softmax}(W h_t)$는 여전히 탐색 목적으로 계산할 수 있다.
Training Procedure

본 논문에서는 모델이 입력으로 질문을 받고 추론 과정을 통해 답을 생성할 것으로 예상되는 문제 해결 설정에 초점을 맞추었다. 저자들은 iCoT에서 영감을 얻은 다단계 학습 커리큘럼을 구현하여 언어 CoT 데이터를 활용하여 continuous thought을 학습시켰다.
위 그림에서 볼 수 있듯이 초기 단계에서 모델은 일반적인 CoT 인스턴스에서 학습된다. $k$번째 단계에서 처음 $k$개의 CoT 추론 단계는 $k \times c$개의 continuous thought으로 대체된다. 여기서 $c$는 하나의 언어 추론 단계를 대체하는 continuous thought의 수를 제어하는 hyper-parameter이다. 학습 단계가 전환될 때 optimizer state도 재설정한다. 저자들은 $\langle \textrm{bot} \rangle$와 $\langle \textrm{eot} \rangle$ 토큰을 삽입하여 continuous thought을 캡슐화하였다.
학습 과정에서는 일반적인 negative log-likelihood loss를 최적화하지만 질문과 continuous thought에 대한 loss는 마스킹한다. 이를 통해 continuous thought이 제거된 기존의 언어적 사고를 압축하는 것을 방지하고 오히려 미래의 추론 예측을 용이하게 한다. 따라서 LLM은 인간 언어에 비해 추론 단계의 더 효과적인 표현을 학습할 수 있다.
Training Details
제안된 continuous thought은 완전히 미분 가능하며 backpropagation을 허용한다. 현재 학습 단계에 $n$개의 continuous thought이 예약되어 있을 때 $n + 1$개의 forward pass를 수행하고, 각 pass에 새로운 continuous thought을 계산하고 마지막으로 나머지 텍스트 시퀀스에 대한 loss를 얻기 위해 추가 forward pass를 수행한다. KV cache를 사용하여 반복적인 컴퓨팅을 저장할 수 있지만, 여러 forward pass의 순차적인 특성으로 인해 병렬성에 대한 한계점이 존재한다.
Inference Process
Coconut의 inference 프로세스는 표준 언어 모델 디코딩과 유사하지만 latent 모드에서는 마지막 hidden state를 다음 입력 임베딩으로 직접 공급한다. 문제는 latent 모드와 언어 모드 사이를 언제 전환할지 결정하는 데 있다. 저자들은 문제 해결 task에 집중하였기 때문에, 질문 토큰 바로 뒤에 $\langle \textrm{bot} \rangle$ 토큰을 삽입하였다. $\langle \textrm{eot} \rangle$의 경우 두 가지 잠재적 전략을 고려하였다.
- Latent thought에 대한 binary classifier를 학습하여 모델이 latent 추론을 종료할 시기를 자율적으로 결정할 수 있도록 한다.
- 항상 continuous thought을 일정한 길이로 채운다.
두 가지 접근 방식 모두 비교적 잘 작동하기 때문에 단순성을 위해 두 번째 옵션을 사용하였다.
Experiments
- 데이터셋
- 수학적 추론: GSM8k
- 논리적 추론: 5-hop ProntoQA, ProsQA (새로 제안)
- 실험 디테일
- base model: GPT-2
- learning rate: $1 \times 10^{-4}$
- batch size: 128
- 수학적 추론
- 각 추론 단계 마다 2개의 continuous thought ($c = 2$)
- 먼저 3개의 추론 단계로 다단계 학습 ($k = 3$)
- 긴 추론 체인을 다루게 하기 위해, 6개의 continuous thought을 사용하고 나머지 언어적 추론 체인을 제거하여 추가 학습
- 단계별로 각각 6 epoch, 3 epoch 동안 학습
- 논리적 추론
- 각 추론 단계 마다 1개의 continuous thought ($c = 1$)
- 6개의 추론 단계로 다단계 학습 ($k = 6$)
- 단계별로 5 epoch 동안 학습
1. Results
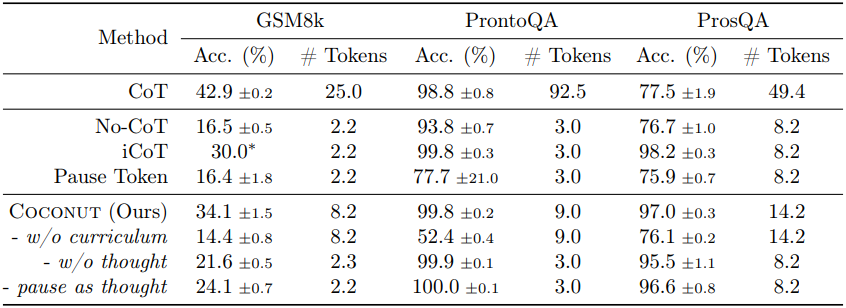
다음은 세 데이터셋에서의 결과를 기존 방법들과 비교한 표이다.
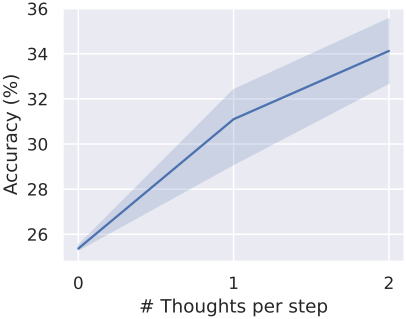
다음은 continuous thought의 수에 따른 GSM8k 정확도를 비교한 그래프이다.
다음은 continuous thought을 언어 토큰으로 해독한 case study이다.
2. Interpolating between Latent and Language Reasoning
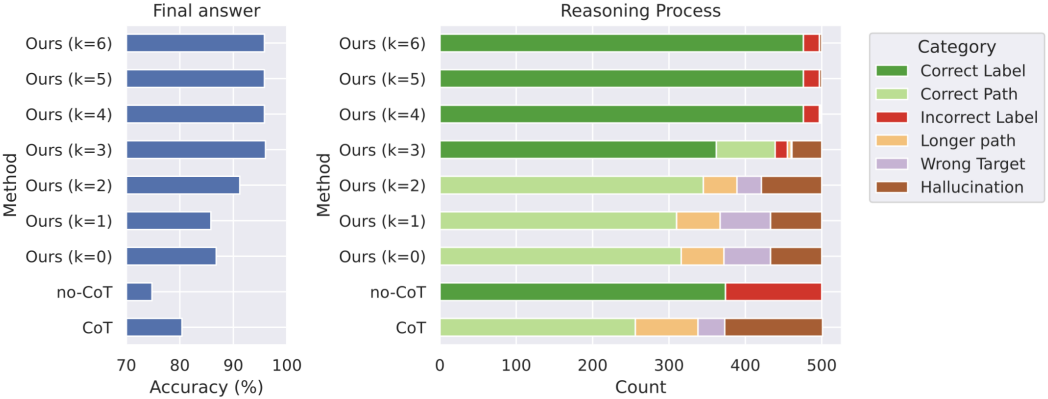
다음은 ProsQA에서 (왼쪽) 최종 정답의 정확도와 (오른쪽) 추론 프로세스를 비교한 비교한 그래프이다.
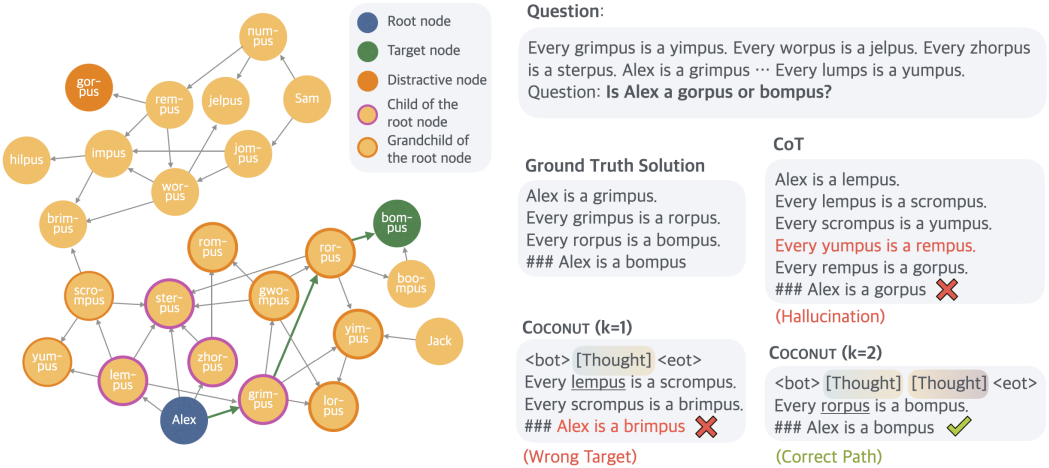
다음은 ProsQA에서의 case study이다. CoT로 학습된 모델은 막다른 길에 갇힌 후 hallucination이 발생한다. Coconut ($k=1$)은 무관한 node로 끝나는 경로를 출력한다. Coconut ($k=2$)는 문제를 올바르게 해결한다.
3. Interpreting the Latent Search Tree
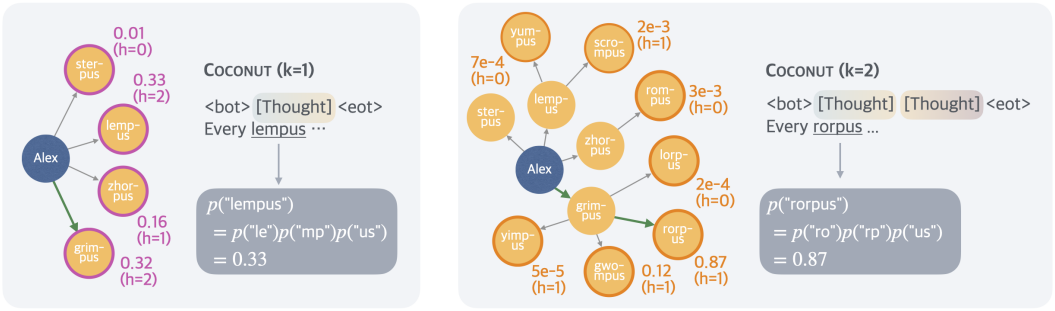
다음은 위 그림의 예시에서 모델이 예측한 첫 번째 개념의 확률을 나타낸 latent search tree이다. 이 지표는 모델이 추정한 암시적인 value function으로 해석될 수 있으며, 각 node의 잠재력을 평가하여 정답을 도출한다.
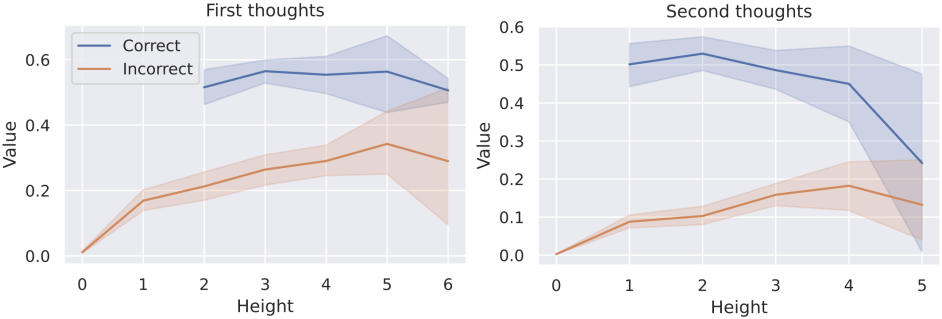
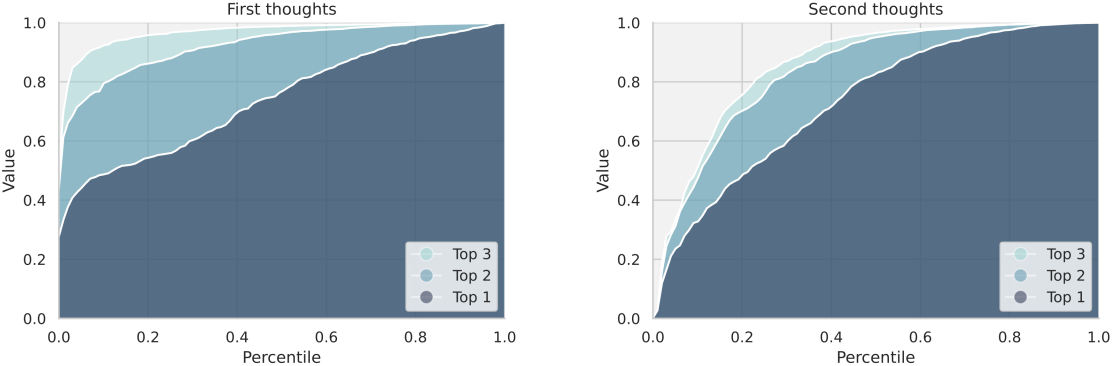
다음은 latent tree search의 병렬 구조를 분석한 그래프이다. 왼쪽 그래프에서 선 사이의 뚜렷한 간격은 모델이 continuous thought을 병렬로 탐색할 수 있음을 나타낸다. 오른쪽 그래프에서는 선 사이의 간격이 더 좁아 search tree가 발전함에 따라 병렬성이 감소하고 추론의 확실성이 증가함을 나타낸다.
4. Why is a Latent Space Better for Planning?
다음은 개념의 예측 확률과 height 사이의 상관 관계를 나타낸 그래프이다. 모델은 height가 낮을 때 잘못된 node에 낮은 값을 할당하고 올바른 node에 높은 값을 성공적으로 할당한다. 그러나 height가 증가함에 따라 이러한 구별은 덜 두드러져 정확한 평가가 더 어려워진다.