[논문리뷰] CoCa: Contrastive Captioners are Image-Text Foundation Models
arXiv 2022. [Paper] [Github]
Jiahui Yu, Zirui Wang, Vijay Vasudevan, Legg Yeung, Mojtaba Seyedhosseini, Yonghui Wu
Google Research
4 May 2022
Introduction
딥 러닝은 최근 BERT, T5, GPT-3와 같은 기본 언어 모델 (foundation language model)의 부상을 목격했다. 여기서 모델들은 웹 규모 데이터에서 사전 학습되고 zero-shot, few-shot, transfer learning을 통해 일반적인 멀티태스킹 능력을 보여준다. 전문화된 개별 모델과 비교할 때 대규모 다운스트림 task를 위한 사전 학습 기반 모델은 학습 비용을 상각할 수 있으므로 인간 수준 지능을 위한 모델 규모의 한계를 뛰어넘을 수 있는 기회를 제공한다.
비전과 비전-언어 문제의 경우 여러 기초 모델 후보가 탐색되었다.
- 단일 인코더: 선구적인 연구들은 ImageNet과 같은 이미지 분류 데이터셋에서 cross-entropy loss로 사전 학습된 단일 인코더 모델의 효율성을 보여주었다. 이미지 인코더는 이미지 및 동영상 이해를 포함하여 다양한 다운스트림 task에 적용할 수 있는 일반적인 시각적 표현을 제공한다. 그러나 이러한 모델은 레이블링된된 벡터로 이미지 주석에 크게 의존하고 자유 형식의 인간 자연어 지식 사용하지 않아 비전과 언어 modality를 모두 포함하는 다운스트림 task에 적용하는 데 방해가 된다.
- 이중 인코더: 최근 한 연구에서는 웹 규모의 noisy한 이미지-텍스트 쌍에 contrastive loss가 있는 두 개의 병렬 인코더를 사전 학습하여 이미지-텍스트 기초 모델 후보의 가능성을 보여주었다. 비전 전용 task를 위한 시각적 임베딩 외에도 듀얼 인코더 모델은 동일한 latent space에 텍스트 임베딩을 추가로 인코딩할 수 있으므로 zero-shot 이미지 분류와 이미지-텍스트 검색과 같은 새로운 crossmodal alignment 능력을 사용할 수 있다. 그럼에도 불구하고 이러한 모델은 융합된 이미지와 텍스트 표현을 학습하기 위한 공동 구성 요소가 없기 때문에 visual question answering (VQA)과 같은 비전-언어 공동 이해 task에 직접 적용할 수 없다.
- 인코더-디코더: 또 다른 연구에서는 일반적인 비전과 multimodal 표현을 학습하기 위해 인코더-디코더 모델을 사용한 생성적 사전 학습을 탐구했다. 사전 학습 중에 모델은 인코더 측에서 이미지를 가져오고 디코더 출력에 Language Modeling (LM) loss (또는 PrefixLM)을 적용한다. 다운스트림 task의 경우 디코더 출력을 multimodal 이해 task를 위한 공동 표현으로 사용할 수 있다. 사전 학습된 인코더-디코더 모델로 우수한 비전-언어 결과를 얻었지만 이미지 임베딩과 정렬된 텍스트 전용 표현을 생성하지 않으므로 crossmodal alignment task에 대한 실현 가능성과 효율성이 떨어진다.
본 논문에서는 단일 인코더, 이중 인코더, 인코더-디코더 패러다임을 통합하고 세 가지 접근 방식 모두의 능력을 포함하는 하나의 이미지-텍스트 기반 모델을 학습시켰다. Contrastive loss와 captioning (generative) loss 모두에 대해 학습된 수정된 인코더-디코더 아키텍처를 가진 Contrastive Captioners (CoCa)라는 간단한 모델을 제안하였다.
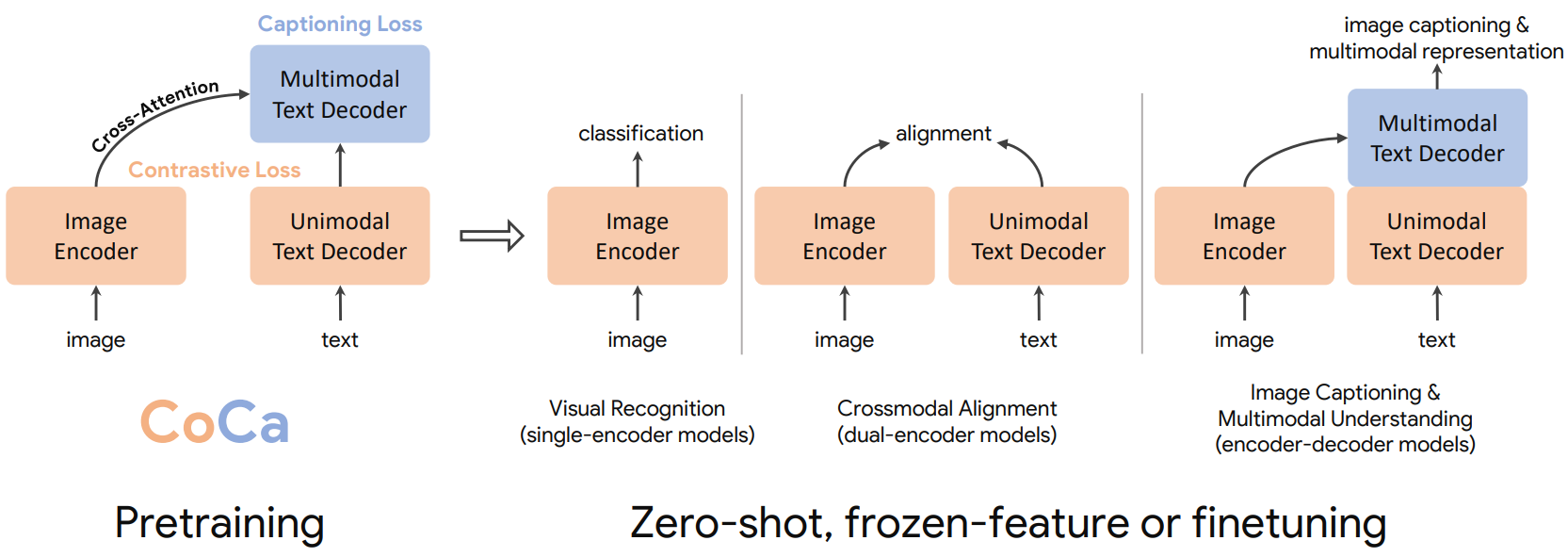
위 그림에서 볼 수 있듯이 디코더 transformer를 unimodal 디코더와 multimodal 디코더의 두 부분으로 분리한다. 텍스트 전용 표현을 인코딩하기 위해 unimodal 디코더 레이어에서 cross-attention을 생략하고, multimodal 이미지-텍스트 표현을 배우기 위해 이미지 인코더 출력에 cross-attending하는 multimodal 디코더 레이어를 cascade한다. 이미지 인코더와 unimodal 텍스트 디코더의 출력 사이에 contrastive 목적 함수와 multimodal 디코더의 출력에서 captioning 목적 함수을 모두 적용한다. 또한 CoCa는 모든 레이블을 단순히 텍스트로 취급하여 이미지 주석 데이터와 noisy한 이미지-텍스트 데이터 모두에 대해 학습한다. 이미지 주석 텍스트의 generative loss는 단일 인코더 cross-entropy loss 접근 방식과 유사한 세분화된 학습 신호를 제공하여 세 가지 사전 학습 패러다임을 모두 단일 통합 방법으로 효과적으로 통합한다.
CoCa의 디자인은 글로벌한 표현을 학습하기 위한 contrastive learning과 세분화된 영역 레벨 feature를 위한 captioning을 활용하므로 세 가지 카테고리 모두에서 도움이 된다. CoCa는 사전 학습된 단일 모델이 zero-shot transfer 또는 최소한의 task별 적응을 사용하는 많은 특수 모델을 능가할 수 있음을 보여준다.
Approach
1. Natural Language Supervision
Single-Encoder Classification
고전적인 단일 인코더 접근 방식은 일반적으로 주석 텍스트의 vocabulary가 고정된 대규모 데이터셋의 이미지 분류를 통해 시각적 인코더를 사전 학습한다. 이러한 이미지 주석은 일반적으로 cross-entropy loss로 학습하기 위해 discrete한 클래스 벡터에 매핑된다.
\[\begin{equation} \mathcal{L}_\textrm{Cls} = - p(y) \log q_\theta (x) \end{equation}\]여기서 $p(y)$는 ground-truth label $y$에 대한 one-hot 분포, multi-hot 분포, 또는 smoothed label 분포이다. 그런 다음 학습된 이미지 인코더는 다운스트림 task를 위한 일반적인 시각적 표현 추출기로 사용된다.
Dual-Encoder Contrastive Learning
사람이 주석을 달고 데이터를 정리해야 하는 단일 인코더 분류를 사용한 사전 학습과 비교하여 이중 인코더 접근 방식은 noisy한 웹 규모 텍스트 설명을 활용하고 학습 가능한 텍스트 타워를 도입하여 자유 형식 텍스트를 인코딩한다. 두 개의 인코더는 쌍을 이루는 텍스트를 샘플 배치의 다른 텍스트와 대조하여 공동으로 최적화된다.
\[\begin{equation} \mathcal{L}_\textrm{Con} = - \frac{1}{N} \bigg( \underbrace{\sum_i^N \log \frac{\exp (x_i^\top y_i / \sigma)}{\sum_{j=1}^N \exp (x_i^\top y_j / \sigma)}}_{\textrm{image-to-text}} + \underbrace{\sum_i^N \log \frac{\exp (y_i^\top x_i / \sigma)}{\sum_{j=1}^N \exp (y_i^\top x_j / \sigma)}}_{\textrm{text-to-image}} \bigg) \end{equation}\]여기서 $x_i$와 $y_j$는 $i$번째 쌍에 있는 이미지와 $j$번째 쌍에 있는 텍스트의 정규화된 임베딩이다. $N$은 배치 크기이고 $\sigma$는 logit의 크기를 조정하는 temperature이다. 이미지 인코더 외에도 이중 인코더 접근 방식은 이미지-텍스트 검색과 zero-shot 이미지 분류와 같은 crossmodal alignment 애플리케이션을 가능하게 하는 정렬된 텍스트 인코더를 학습한다. 경험적 증거에 따르면 zero-shot 분류는 손상되거나 분포 밖의 이미지에서 더 강력하다.
Encoder-Decoder Captioning
이중 인코더 접근 방식은 텍스트를 전체적으로 인코딩하는 반면, 생성적 접근 방식 (일명 captioner)은 세부적인 세분성(granularity)을 목표로 하며 모델이 $y$의 정확한 토큰화된 텍스트를 autoregressive하게 예측해야 한다. 표준 인코더-디코더 아키텍처에 따라 이미지 인코더는 latent 인코딩 능력 (ex. ViT나 ConvNets 사용)을 제공하고 텍스트 디코더는 forward autoregressive factorization 하에서 쌍을 이루는 텍스트 $y$의 조건부 likelihood를 최대화하는 방법을 학습한다.
\[\begin{equation} \mathcal{L}_\textrm{Cap} = - \sum_{t=1}^T \log P_\theta (y_t \vert y_{<t}, x) \end{equation}\]인코더-디코더는 계산을 병렬화하고 학습 효율성을 최대화하기 위해 teacher-forcing으로 학습된다. 이전 방법들과 달리 captioner 접근 방식은 비전-언어 이해에 사용할 수 있는 이미지-텍스트 공동 표현을 생성하며 자연어 생성과 함께 이미지 캡션 애플리케이션도 가능하다.
2. Contrastive Captioners Pretraining
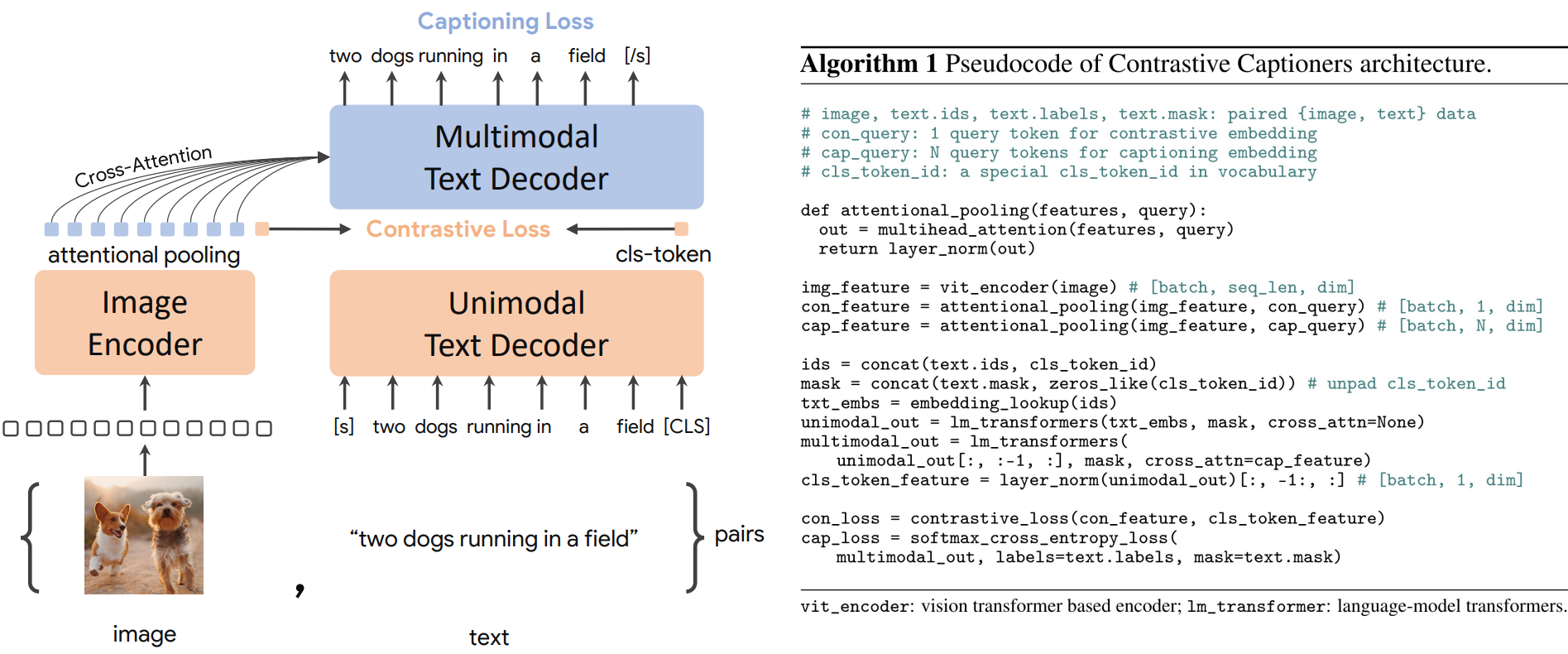
위 그림은 세 가지 학습 패러다임을 매끄럽게 결합하는 간단한 인코더-디코더 접근 방식인 contrastive captioner (CoCa)를 보여준다. 표준 이미지-텍스트 인코더-디코더 모델과 유사하게 CoCa는 이미지를 ViT와 같은 신경망 인코더에 의해 latent 표현으로 인코딩하고 causal masking transformer 디코더로 텍스트를 디코딩한다. 표준 디코더 transformer와 달리 CoCa는 디코더 레이어의 전반부에서 cross-attention을 생략하여 유니모달 텍스트 표현을 인코딩하고 나머지 디코더 레이어를 캐스케이드하여 멀티모달 이미지-텍스트 표현을 위해 이미지 인코더에 cross-attending한다. 결과적으로 CoCa 디코더는 unimodal 및 multimodal 텍스트 표현을 동시에 생성하여 contrastive 목적 함수와 generative 목적 함수를 모두 다음과 같이 적용할 수 있도록 한다.
여기서 $\lambda_\textrm{Con}$과 $\lambda_\textrm{Cap}$은 loss 가중치 hyperparameter이다. 단일 인코더 방식의 cross-entropy classification 목적 함수는 vocabulary가 모든 레이블 이름의 집합일 때 이미지 주석 데이터에 적용되는 생성적 접근 방식의 특수한 경우로 해석될 수 있다.
Decoupled Text Decoder and CoCa Architecture
Captioning 접근 방식은 텍스트의 조건부 likelihood를 최적화하는 반면 contrastive 접근 방식은 unconditional한 텍스트 표현을 사용한다. 본 논문은 이 딜레마를 해결하고 이 두 가지 방법을 단일 모델로 결합하기 위해 unimodal 디코더 레이어에서 cross-attention 메커니즘을 건너뛰어 디코더를 unimodal 및 multimodal 구성 요소로 분할하는 간단한 분리 디코더 디자인을 제안하였다. 즉, 하위 $n_\textrm{uni}$개의 unimodal 디코더 레이어는 causally-masked self-attention이 있는 latent 벡터로 입력 텍스트를 인코딩하고, 상위 $n_\textrm{multi}$개의 multimodal 레이어는 causally-masked self-attention과 cross-attention을 시각적 인코더의 출력에 추가로 적용한다.
모든 디코더 레이어는 토큰이 미래의 토큰에 attend하는 것을 금지하며 \(\mathcal{L}_\textrm{Cap}\)에 대한 multimodal 텍스트 디코더 출력을 사용하는 것은 간단하다. \(\mathcal{L}_\textrm{Con}\)의 경우 입력 문장 끝에 학습 가능한 토큰을 추가하고 해당하는 unimodal 디코더 출력을 텍스트 임베딩으로 사용한다. \(n_\textrm{uni} = n_\textrm{multi}\)가 되도록 디코더를 반으로 나눈다. ALIGN을 따라 288$\times$288의 이미지 해상도와 18$\times$18의 패치 크기로 사전 학습하여 총 256개의 이미지 토큰이 생성된다.
가장 큰 CoCa 모델 (“CoCa”)은 이미지 인코더에 10억개의 파라미터가 있고 텍스트 디코더에 21억개의 파라미터가 있는 ViT-giant 설정을 따른다. 또한 저자들은 아래 표 1에 자세히 설명된 “CoCa-Base”와 “CoCa-Large”의 두 가지 더 작은 변형을 살펴보았다.

Attentional Poolers
Contrastive loss는 각 이미지에 대해 단일 임베딩을 사용하는 반면 디코더는 일반적으로 인코더-디코더 captioner의 이미지 출력 토큰 시퀀스에 attend한다. 하나의 풀링된 이미지 임베딩은 글로벌 표현으로서 시각적 인식에 도움이 되는 반면 더 많은 visual token은 로컬 레벨 feature가 필요한 multimodal 이해에 도움이 된다. 따라서 CoCa는 task별 attention pooling을 채택하여 다양한 유형의 목적 함수와 다운스트림 task에 사용할 시각적 표현을 커스터마이징한다. 여기서 pooler는 $n_\textrm{query}$개의 학습 가능한 query가 있는 단일 multi-head attention layer이며 인코더 출력은 key와 value로 사용된다. 이를 통해 모델은 두 목적 함수에 대해 서로 다른 길이의 임베딩을 풀링하는 방법을 학습할 수 있다. Task별 pooling을 사용하면 다양한 task에 대한 다양한 요구 사항을 해결할 뿐만 아니라 pooler를 자연스러운 task adapter로 도입할 수 있다. 본 논문에서는 generative loss $n_\textrm{query} = 256$와 contrastive loss $n_\textrm{query} = 1$에 대한 사전 학습에서 attentional pooler를 사용한다.
Pretraining Efficiency
분리된 autoregressive 디코더 디자인의 주요 이점은 효율적으로 고려되는 두 가지 학습 loss들을 계산할 수 있다는 것이다. 단방향 언어 모델은 완전한 문장에 대한 인과적 마스킹 (causal masking)으로 학습되기 때문에 디코더는 한 번의 pass (양방향 접근법의 경우 두 번의 pass와 비교)로 contrastive loss와 generative loss 모두에 대한 출력을 효율적으로 생성할 수 있다. 따라서 계산의 대부분은 두 loss들 간에 공유되며 CoCa는 표준 인코더-디코더 모델에 비해 최소한의 오버헤드만 유발한다. 반면에 많은 기존 방법이 다양한 데이터 소스 또는 modality에 대해 여러 단계로 모델 구성 요소를 교육하는 반면 CoCa는 다양한 데이터 소스 (즉, 주석이 달린 이미지와 noisy한 alt-text 이미지)를 사용하여 end-to-end로 사전 학습된다. 이 떄, contrastive 및 generative 목적 함수 모두에 대해 모든 레이블을 텍스트로 취급한다.
3. Contrastive Captioners for Downstream Tasks
Zero-shot Transfer
사전 학습된 CoCa 모델은 zero-shot 이미지 분류, zero-shot 이미지-텍스트 교차 검색, zero-shot 동영상-텍스트 교차 검색을 포함하여 이미지와 텍스트 입력을 모두 활용하여 zero-shot 방식으로 많은 task를 수행한다. 이전 관행에 따라 여기에서 “zero-shot”은 사전 학습 중에 모델이 관련 supervision 정보를 볼 수 있지만 전송 프로토콜 중에 supervision 예제가 사용되지 않는다는 점에서 기존의 zero-shot 학습과 다르다. 사전 학습 데이터의 경우 다운스트림 task에 대한 모든 가까운 도메인 예제를 필터링하기 위해 도입된 엄격한 중복 제거 절차를 따른다.
Frozen-feature Evaluation
CoCa는 backbone 인코더를 공유하면서 다양한 유형의 다운스트림 task에 대한 시각적 표현을 커스터마이징하기 위해 task별 attentional pooling (pooler)을 채택한다. 이를 통해 모델은 feature들을 집계하기 위해 새로운 pooler만 학습하는 고정 인코더로서 강력한 성능을 얻을 수 있다. 또한 동일한 고정 이미지 인코더 계산을 공유하지만 task별 head가 다른 multi-task 문제에 도움이 될 수 있다. Linear evaluation은 학습된 표현을 정확하게 측정하는 데 어려움이 있으며 attentional pooler가 현실 애플리케이션에 더 실용적이다.
CoCa for Video Action Recognition
동영상 동작 인식 task를 위해 학습된 CoCa 모델을 활성화하는 간단한 접근 방식을 사용한다.
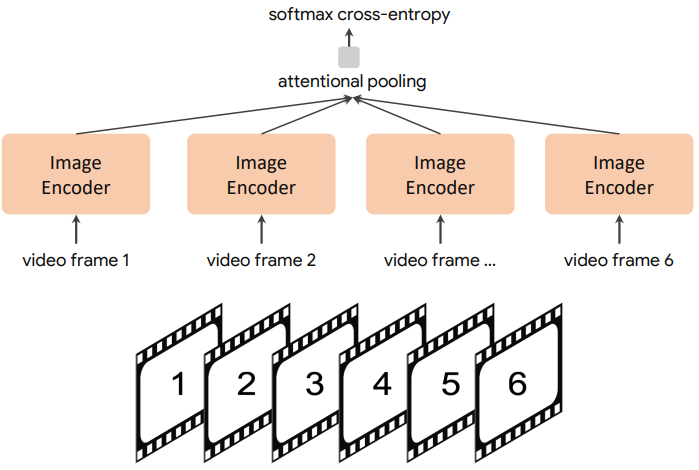
먼저 동영상의 여러 프레임을 가져와 위 그림과 같이 각 프레임을 공유 이미지 인코더에 개별적으로 공급한다. Frozen-feature 평가 또는 fine-tuning을 위해 softmax cross-entropy loss를 사용하여 공간적 및 시간적 feature 토큰 위에 추가 pooler를 학습한다. Pooler에는 하나의 query 토큰이 있으므로 모든 공간적 및 시간적 토큰에 대한 pooling 계산 비용이 많이 들지 않는다. Zero-shot 동영상 텍스트 검색의 경우 동영상의 16개 프레임의 평균 임베딩을 계산하여 훨씬 더 간단한 접근 방식을 사용한다 (프레임은 동영상에서 균일하게 샘플링됨). 또한 검색 메트릭을 계산할 때 각 동영상의 캡션을 타겟 임베딩으로 인코딩한다.
Experiments
- 데이터셋: JFT-3B (label name), ALIGN (noisy alt-text)
- 최적화
- 스케일링 성능을 위해 GSPMD를 사용한 Lingvo 프레임워크에서 구현
- batch size: 65,536 (이미지-텍스트 쌍)
- 50만 step, JFT에서 5 epochs, ALIGN에서 10 epochs
- \(\lambda_\textrm{Cap}\) = 2.0, \(\lambda_\textrm{Con}\) = 1.0, $\tau$ = 0.07
- optimizer: Adafactor ($\beta_1$ = 0.9, $\beta_2$ = 0.999, weight decay: 0.01)
- learning rate: 최대값 $8 \times 10^{-4}$, 처음 2%동안 warmup 후 linear decay
- 2048개의 CloudTPUv4 칩에서 5일 소요
1. Main Results
다음은 다른 이중 인코더와 인코더-디코더 기초 모델들, SOTA task 전용 방법들을 CoCa와 주요 벤치마크에서의 성능을 비교한 것이다.
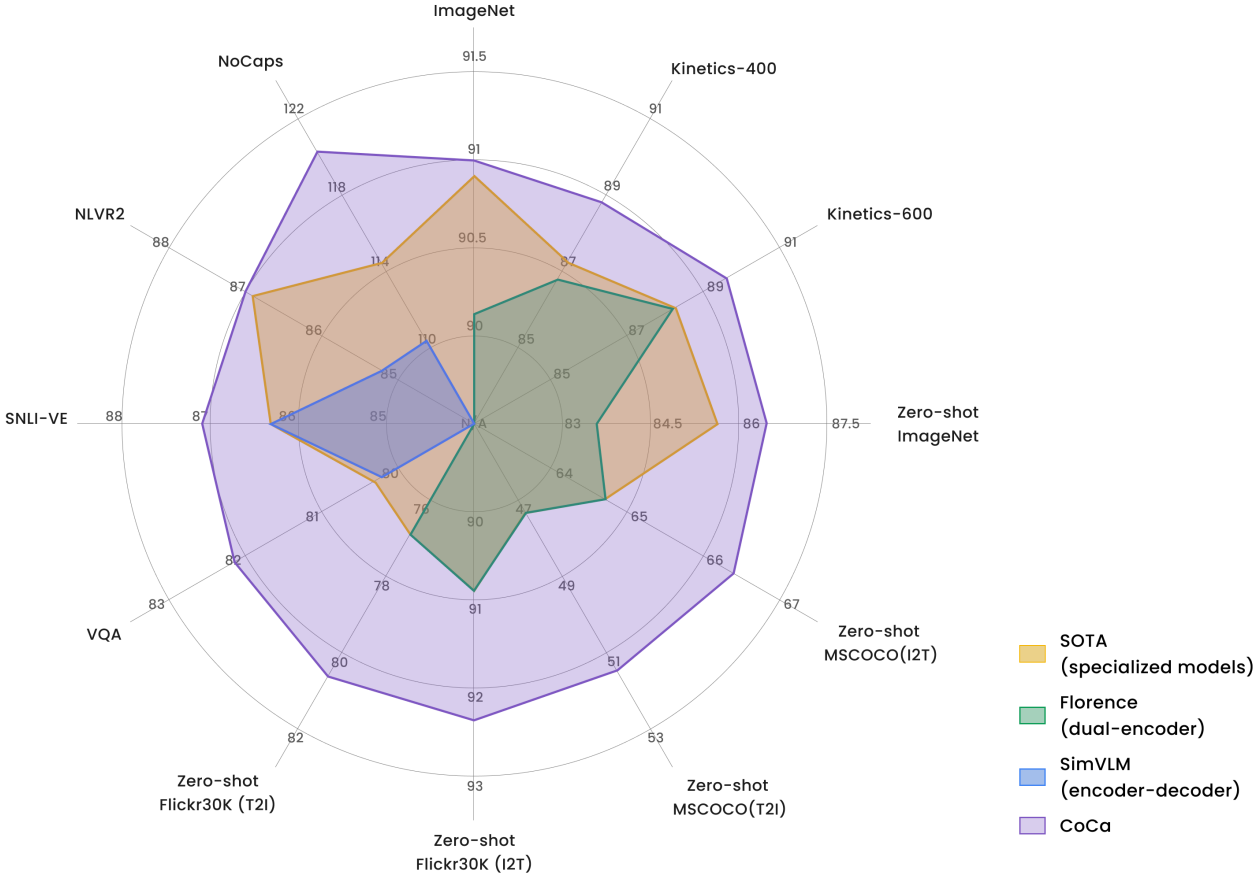
Visual Recognition Tasks
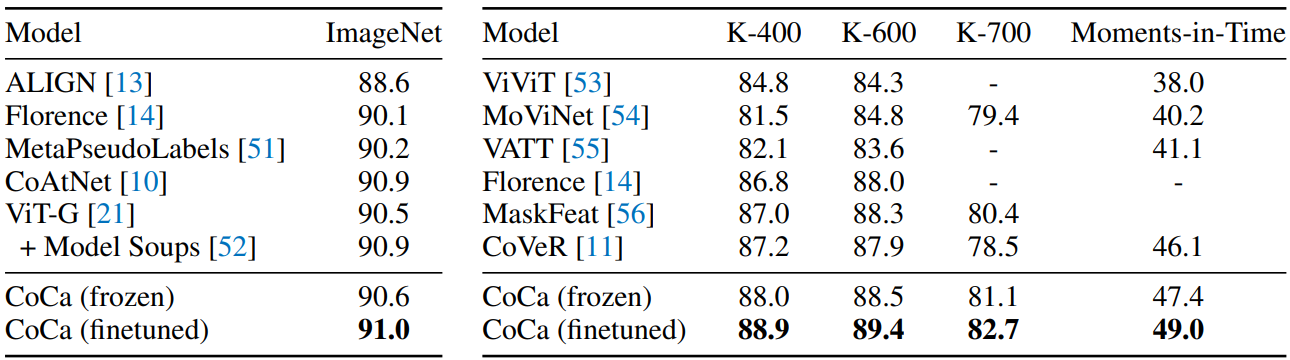
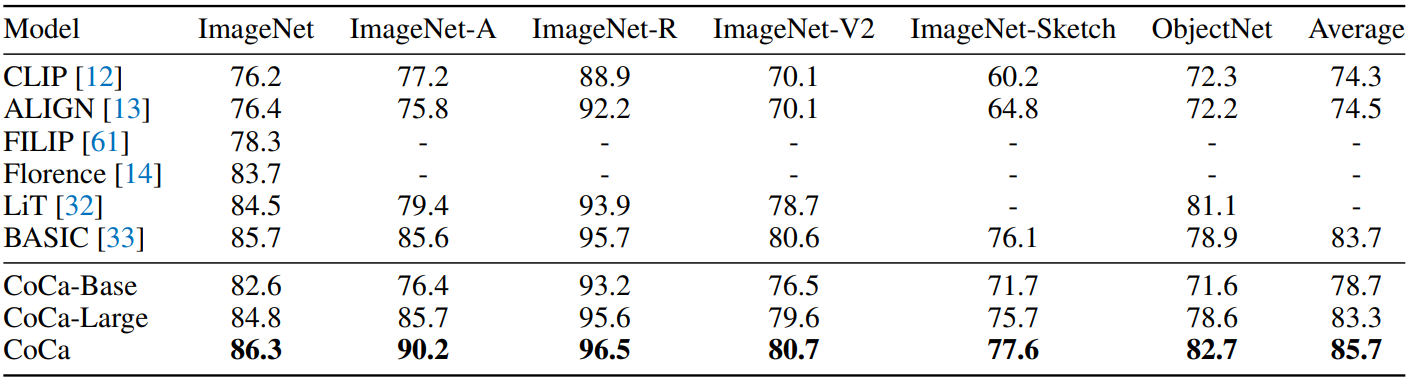
다음은 이미지 분류 (왼쪽)와 동영상 동작 인식 (오른쪽) 성능을 비교한 표이다.
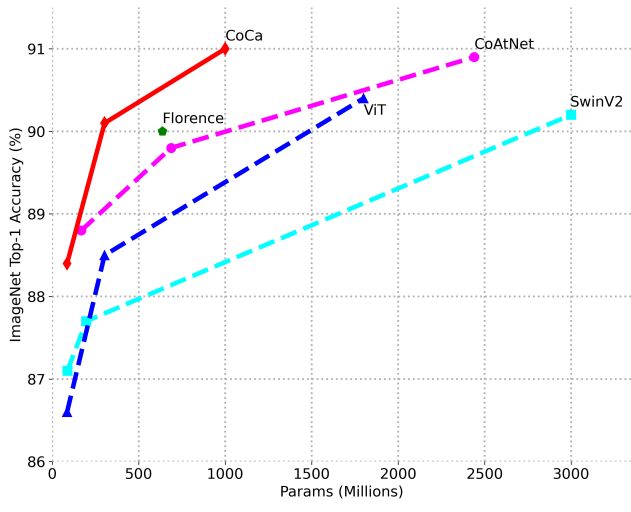
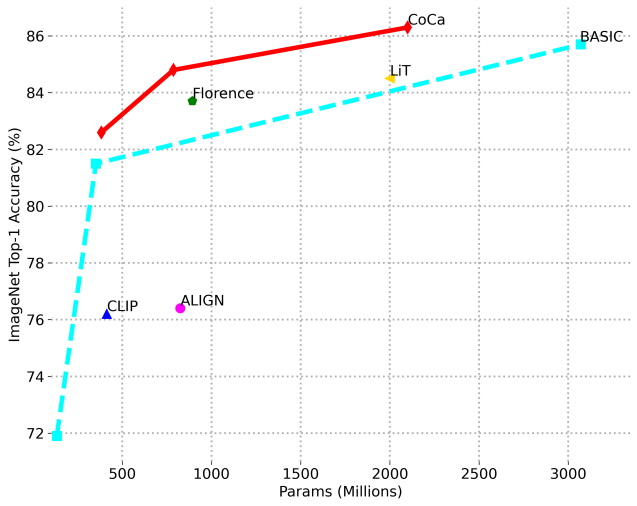
다음은 fine-tuning된 ImageNet top-1 정확도를 비교한 그래프이다.
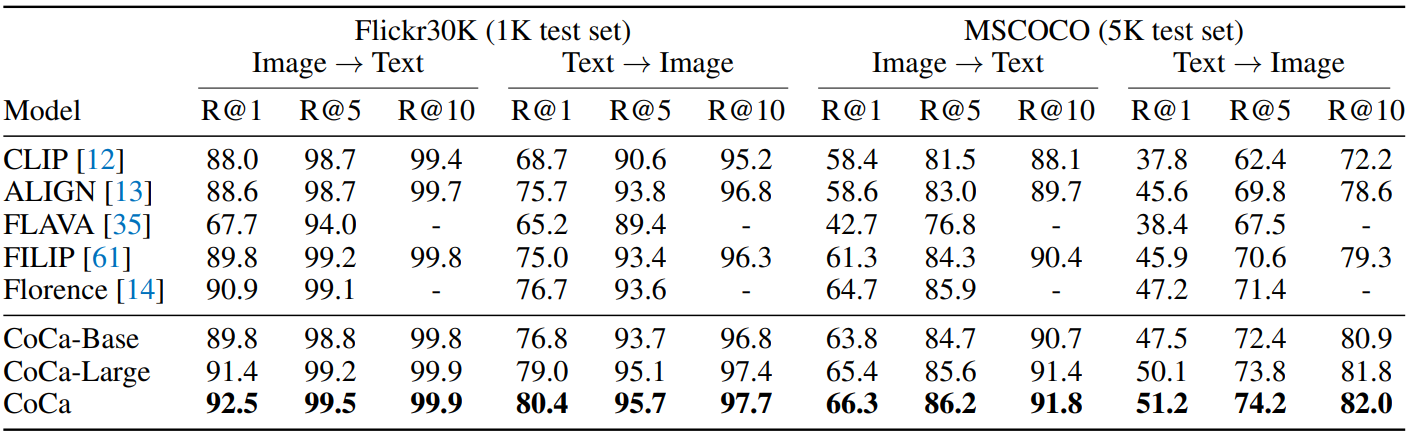
Crossmodal Alignment Tasks
다음은 zero-shot 이미지-텍스트 검색 결과를 비교한 표이다.
다음은 zero-shot 이미지 분류 결과를 비교한 표와 그래프이다.
다음은 zero-shot 동영상-텍스트 검색 결과를 비교한 표이다.

Image Captioning and Multimodal Understanding Tasks
다음은 비전-언어 사전 학습 방법들과 multimodal 이해 결과를 비교한 표이다.
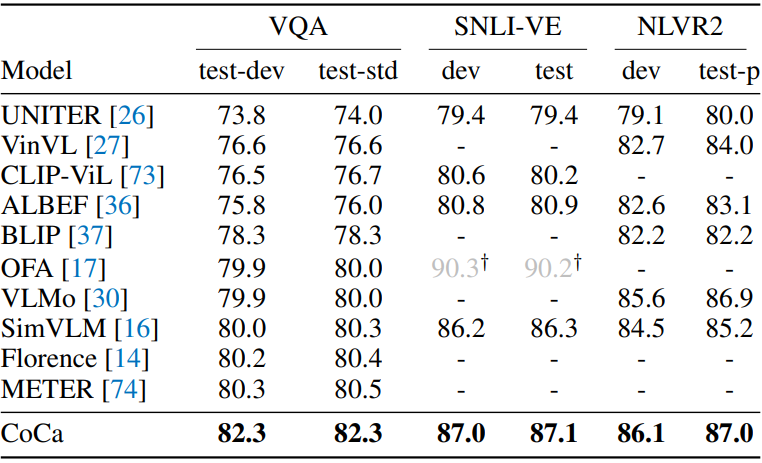
다음은 image captioning 결과를 비교한 표이다.

다음은 NoCaps 이미지를 입력으로 하여 CoCa로 생성한 텍스트 캡션 샘플들이다.

2. Ablation Analysis
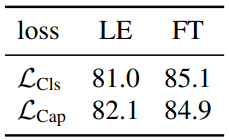
Captioning vs. Classification
다음은 인코더-디코더 모델과 단일 인코더 모델을 비교한 표이다. (JFT에서 학습)
Training Objectives
다음은 목적 함수에 대한 ablation 결과이다.
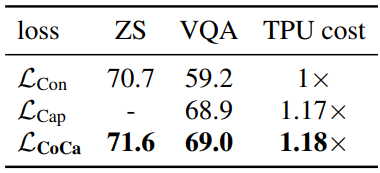
다음은 목적 함수 가중치에 대한 ablation 결과이다.
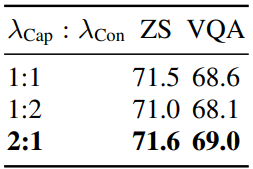
Unimodal and Multimodal Decoders
다음은 unimodal 디코더 레이어 수 $n_\textrm{uni}$에 대한 ablation 결과이다.
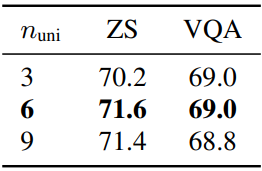
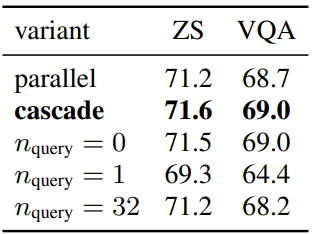
다음은 contrastive text embedding 디자인에 대한 ablation 결과이다.
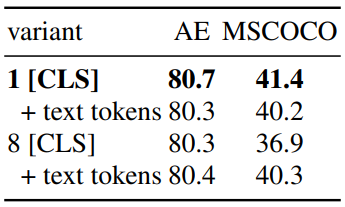
Attentional Poolers
다음은 attentional pooler 디자인에 대한 ablation 결과이다.