[논문리뷰] CoAtNet: Marrying Convolution and Attention for All Data Sizes
NeurIPS 2021. [Paper] [Github]
Zihang Dai, Hanxiao Liu, Quoc V. Le, Mingxing Tan
Google Research, Brain Team
9 Jun 2021
Introduction
Vision Transformer (ViT)는 large-scale 데이터셋인 JFT-300M dataset에서 학습시켰을 때 CNN 기반 모델들 중 SOTA인 ConvNets과 비슷한 성능을 보인다. 하지만, large-scale 데이터셋에 대한 추가 training 없이 ImageNet으로만 training을 하면 같은 모델 크기에서는 ConvNets에 성능이 밀린다.
이러한 결과를 통해 알 수 있는 것은
- Vanilla Transformer layer는 CNN 기반 모델에 비해 capacity가 높다.
- 하지만 CNN 기반 모델이 가지고 있는 generalization 능력이 떨어진다.
- 이를 극복하기 위해서는 굉장히 많은 데이터와 컴퓨팅 자원이 필요하다.
이 논문의 목적은 convolution의 generalization과 attention의 capacity를 효과적으로 섞으면서 정확도와 efficiency를 높이는 것이다.
논문에서는 2가지 사실을 확인하였는데,
- Depthwise convolution이 attention layer와 효과적으로 합쳐진다.
- 적절한 방법으로 convolution layer와 attention layer를 쌓는 것만으로도 높은 generalization과 capacity를 얻을 수 있다.
위 2가지 사실을 바탕으로 CoAtNet(Convolution + self-Attention)을 만들었다.
Model
1. Merging Convolution and Self-Attention
저자는 depthwise convolution을 사용하는 MBConv block (MobileNetV2에서 사용)에 주목하였는데, 이는 Transformer의 FFN (Feed Forward Network)와 MBConv 모두 inverted bottleneck 구조를 사용하기 때문이다. Inverted bottleneck 구조는 input의 채널 사이즈를 4배로 확장한 다음 4x-wide hidden state를 원래 채널 사이즈에 project하여 residual connection이 가능하게 한다.
Inverted bottleneck의 유사성 때문에 depthwise convolution과 self-attention은 미리 정의된 receptive field의 값들의 per-dimension weighted sum으로 표현할 수 있다.
Depthwise convolution:
\[\begin{aligned} y_i = \sum_{j \in \mathcal{L} (i)} {w_{i-j} \odot x_j} \end{aligned}\]($x_i , y_i \in \mathbb{R}^D$은 $i$에서의 input과 output, $\mathcal{L} (i)$은 $i$의 local neighborhood)
Self-attention:
\[\begin{aligned} y_i = \sum_{j \in \mathcal{G}} {\frac{\exp(x_i^T x_j)}{\sum_{k \in \mathcal{G}} \exp(x_i^T x_k)} x_j} = \sum_{j \in \mathcal{G}} {A_{i,j} x_j} \end{aligned}\]($\mathcal{G}$는 global spatial space)
각 연산의 장점과 약점은 다음과 같다.
- Input-adaptive Weighting
Depthwise convolution kernel $w_{i-j}$는 input에 독립적인 파라미터지만, attention weight $A_{i,j}$는 input에 의존한다. 그러므로 self-attention은 서로 다른 위치 사이의 관계를 잘 포착하며, 이는 높은 수준의 개념을 다룰 때 필요한 능력이다. 하지만 데이터가 제한적일 때 overfitting이 쉽게 일어난다. - Translation Equivariance
$w_{i-j}$는 두 지점 $i$와 $j$의 상대적 위치 ${i-j}$만 고려할 뿐 $i$와 $j$ 각각의 절대적 위치를 고려하지 않는다. 이러한 특징은 제한적인 크기의 데이터셋에서 generalization을 향상시킨다. 반면 ViT는 positional embedding을 이용하여 절대적 위치를 고려하기 때문에 generalization이 부족하다. - Global Recpetive Field
Self-attention의 receptive field가 이미지 전체이지만 convoluton은 receptive field가 작다. Receptive field가 크면 contextual information가 더 많아 model capacity가 커진다. 하지만 모델의 복잡도가 커지고 더 많은 계산이 필요해진다.
따라서 이상적인 모델은 translation equivariance를 통해 generalization이 높은 동시에 input-adaptive weighting과 global receptive field를 통해 capacity가 높아야 한다.
Convolution 식과 self-attention 식을 합치기 위해 단순히 global static convolution kernel과 adaptive attention matrix를 더하였다. 이 때, Softmax normalization 전에 더하거나 (pre) 후에 더하는 (post) 2가지 방법이 있다.
Pre-normalization:
\[\begin{aligned} y_i^{\text{pre}} = \sum_{j \in \mathcal{G}} {\frac{\exp(x_i^T x_j + w_{i-j})}{\sum_{k \in \mathcal{G}} \exp(x_i^T x_k + w_{i-k})} x_j} \end{aligned}\]Post-normalization:
\[\begin{aligned} y_i^{\text{post}} = \sum_{j \in \mathcal{G}} {\bigg( \frac{\exp(x_i^T x_j)}{\sum_{k \in \mathcal{G}} \exp(x_i^T x_k)} + w_{i-j}\bigg) x_j} \end{aligned}\]Pre-normalization 버전의 경우 attention weight $A_{i,j}$가 translation equivariance의 $w_{i-j}$와 input-adaptive $x_i^T x_j$에 의해 결정되며 상대적 크기에 따라 두 가지 효과를 모두 볼 수 있다. 여기서 파라미터의 개수를 늘리지 않으면서 global convolution kernel이 가능하도록 하기 위하여 벡터 $w_{i-j}$ 대신 스칼라 $w \in \mathbb{R}^{O(|\mathcal{G}|)}$를 사용한다.
스칼라 $w$ 사용의 또 다른 이점은 모든 ($i,j$) 쌍에 대한 정보가 pairwise dot-product attention을 계산하면서 모두 포함된다는 것이다. 이러한 장점들 때문에 post-normalization 대신 pre-normalization을 사용한다.
2. Vertical Layout Deisgn
Global context는 spatial size의 제곱에 비례하여 증가하기 때문에 입력 이미지에 바로 relative attention을 적용하면 계산이 굉장히 느려질 것이다. 따라서, 현실적인 모델 구현을 위한 3가지 옵션이 있다.
- 어느정도 down-sampling으로 spatial size를 줄인 후 global relative attention을 사용한다.
- Local attention을 수행하여 global receptive field $\mathcal{G}$의 attention을 local field $\mathcal{L}$로 제한한다.
→ Local attention의 non-trivial shape formatting 연산이 과도한 메모리 엑세스를 필요로 함. - Quadratic softmax attention을 특정 linear attention의 변형으로 대체한다.
→ 간단한 실험을 해보니 결과가 좋지 못함.
위의 문제점들 때문에 첫번째 방법을 택했다.
Down-sampling 방법은 크게 2가지가 있다.
- ViT에서 사용한 것처럼 stride가 큰 convolution stem 사용 (ex. stride 16x16)
- ConvNets에서 사용한 것처럼 점진적으로 pooling하는 multi-stage network 사용
가장 좋은 방법을 찾기 위해 5가지 모델에 대하여 실험 진행하였다.
- ViT의 convolution stem을 사용한 뒤, relative attention을 하는 $L$개의 Transformer block을 쌓은 모델
→ VITREL로 표기 - ConvNets의 구조를 모방하여 5개의 stage (S0 ~ S4)로 구성한다.
S0는 2-layer convolution stem. S1은 squeeze-excitation (SE)을 사용하는 MBConv block.
S2부터 S4는 MBConv block과 Transformer block 중 선택한다. (MBConv block이 항상 Transformer block보다 앞에 가도록 선택)
→ C-C-C-C, C-C-C-T, C-C-T-T, C-T-T-T로 표기 (C는 MBConv block, T는 Transformer block)
5가지 모델에 개하여 Generalization과 Model capacity를 확인하였다
Generalization: ImageNet-1K (1.3M) 300 epochs
Training loss와 evaluation accuracy 사이의 차이를 확인한다. Training loss가 같다면 evaluation accuracy가 높은 모델이 generalization이 더 잘 된다고 볼 수 있다.

Model capacity: JFT (300M) 3 epochs
큰 training dataset이 잘 적용되는 지 측정한다. 큰 training dataset에 대한 최종 성능이 더 좋다면 모델의 capacity가 높다고 볼 수 있다. 모델의 크기가 커지면 capacity도 같이 커지기 때문에 5가지 모델의 크기를 비슷하게 맞추고 실험을 진행하였다.

Transferability:
C-C-T-T와 C-T-T-T 중 더 좋은 모델을 결정하기 위하여 transferability test을 진행하였다. 각각의 JFT pre-trained 모델을 ImageNet-1K에 대하여 30 epochs만큼 finetune을 한 뒤 성능을 비교하였다.

최종적으로 transfer 성능이 더 좋은 C-C-T-T로 결정하였다.
3. Model 구조

Experiments
- 5개의 크기가 다른 CoAtNet 모델로 실험 진행

- Dataset: ImageNet-1K (이미지 128만 개), ImageNet-21K (이미지 1,270만 개), JFT (이미지 3억 개)
- Pre-train: 각 데이터 셋에 대하여 224x224 이미지로 각각 300, 90, 14 epochs
- Finetune: ImageNet-1K 224x224, 384x384, 512x512 이미지로 30 epochs
- ImageNet-1K 224x224는 별도의 finetune 없이 평가 (어차피 같은 데이터셋, 같은 이미지 크기므로)
- Data Augmentation: RandAugment, MixUP
- Regularization: stochastic depth, label smoothing, weight decay
Results
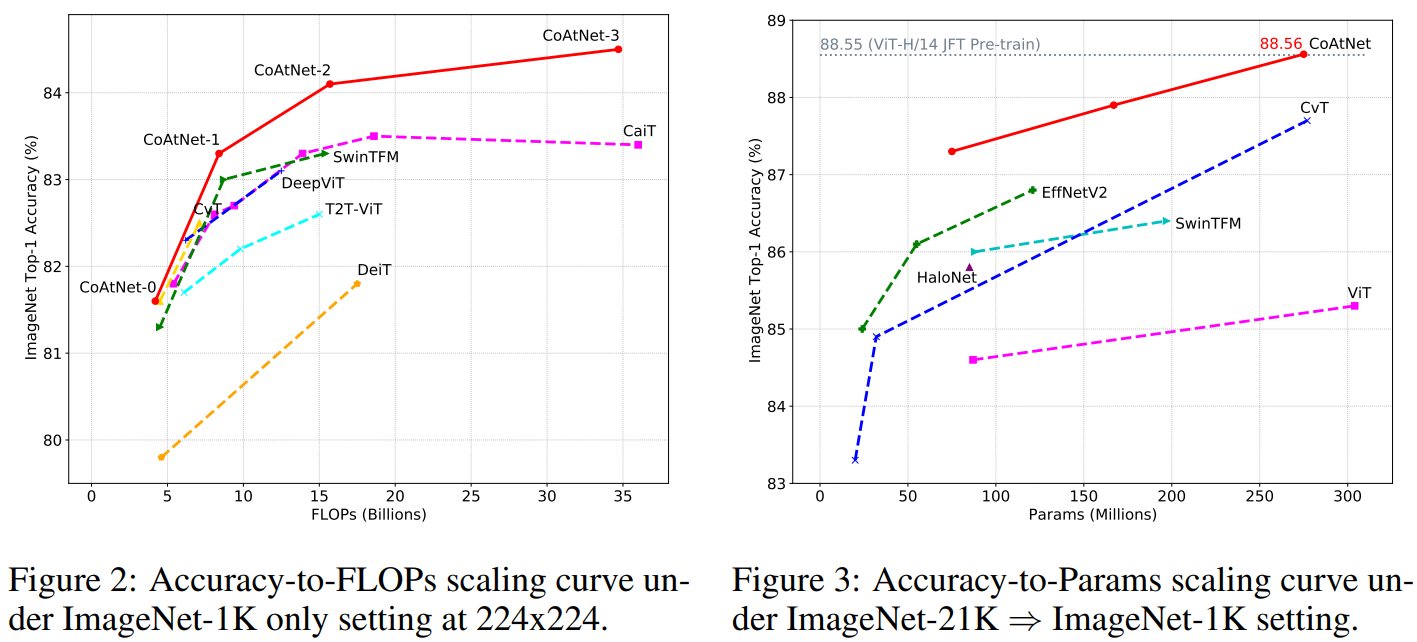
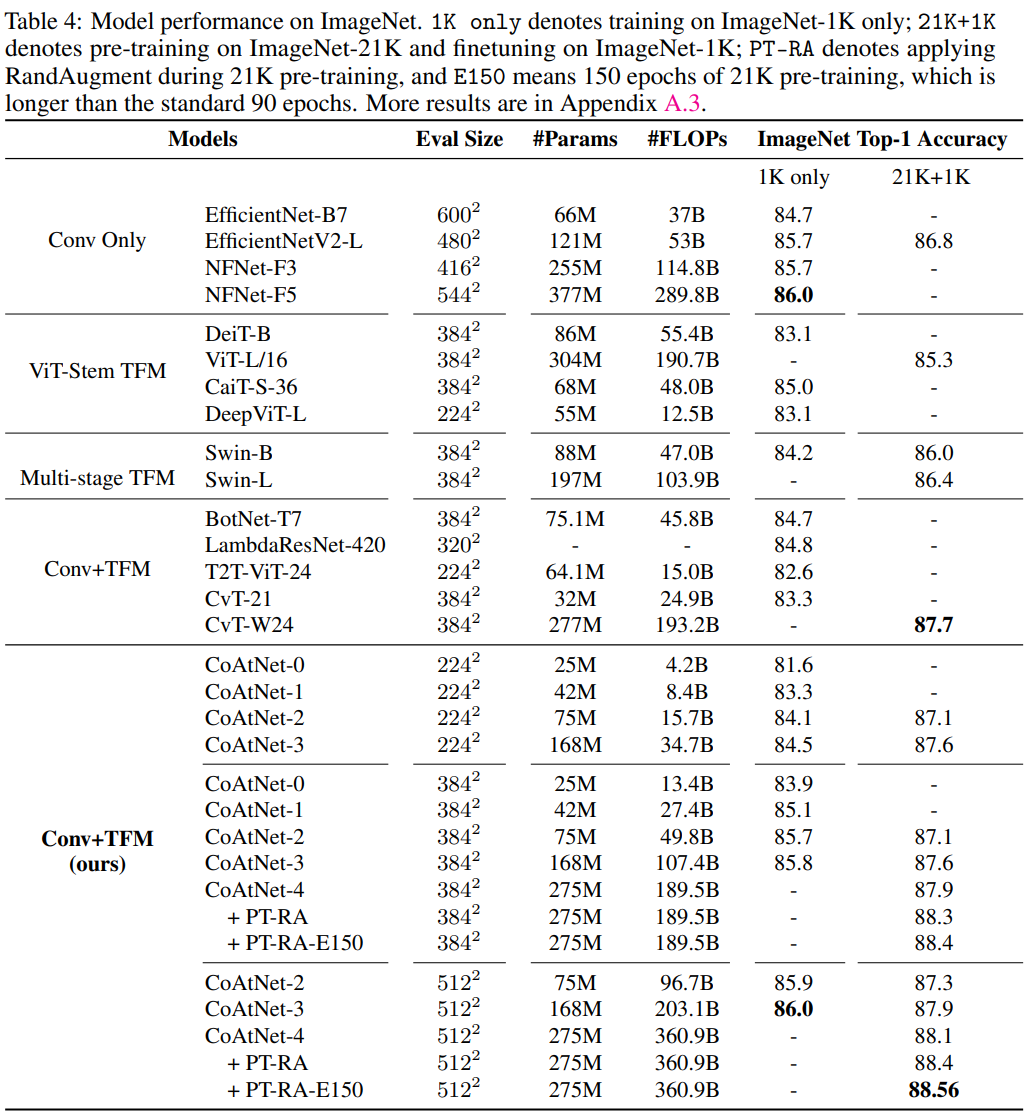
추가로, 모델의 크기를 더 키워 기존 모델과 비교하였다.
- CoAtNet-5: NFNet-F4+와 비슷한 training resource로 세팅
- CoAtNet-6/7: ViT-G/14와 비슷한 training resource로 세팅, JFT-3B dataset으로 학습.
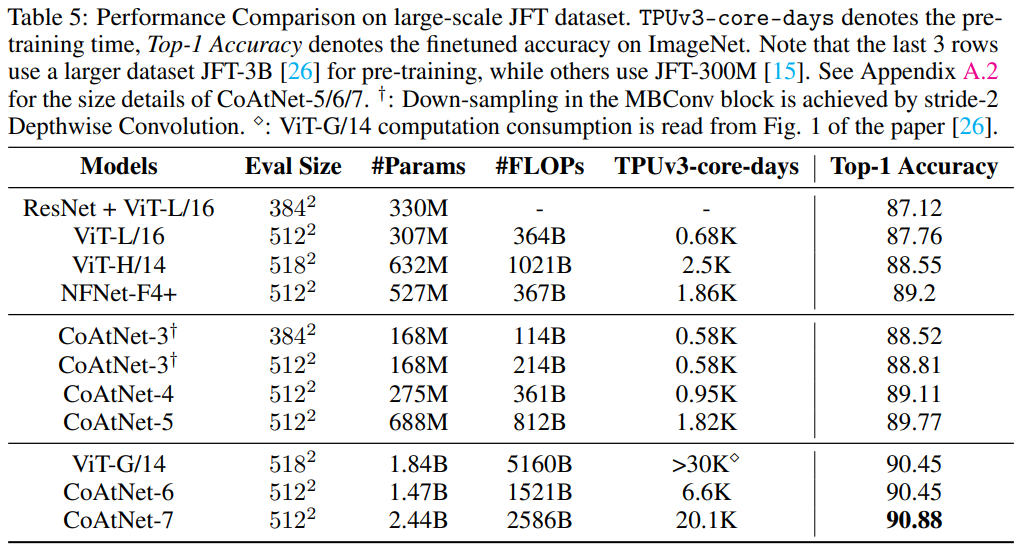
- CoAtNet-6: ViT-G/14보다 1.5배 적은 연산으로 90.45%의 성능 도달
- CoAtNet-7: top-1 accuray가 90.88%로 새로운 state-of-the-art 등극
Ablation study