[논문리뷰] CLoRA: A Contrastive Approach to Compose Multiple LoRA Models
arXiv 2024. [Paper] [Page]
Tuna Han Salih Meral, Enis Simsar, Federico Tombari, Pinar Yanardag
Virginia Tech | ETH Zürich | Google | TUM
28 Mar 2024

Introduction
Diffusion text-to-image 모델은 텍스트 프롬프트에서 이미지 생성에 혁명을 일으켰다. 생성 모델이 점점 대중화되면서 개인화된 이미지 생성은 사용자 선호도에 맞는 고품질의 다양한 이미지를 생성하는 데 중요한 역할을 한다. 기존 접근 방식은 style transfer를 통해 diffusion process에서 사용자 피드백을 통합하였다. 그러나 이러한 방법을 사용하려면 전체 diffusion model을 fine-tuning해야 하는 경우가 많으며 이는 계산 비용과 시간이 많이 소요된다.
LLM에 처음 도입된 Low-Rank Adaptation (LoRA)는 모델 개인화를 위한 강력한 기술로 등장했다. 재학습이나 상당한 계산 리소스 없이도 사전 학습된 diffusion model을 효율적으로 fine-tuning할 수 있다. LoRA는 attention layer를 위해 low-rank의 factorize된 가중치 행렬을 최적화하도록 설계되었으며 특정 개체 또는 예술적 스타일에 대한 개인화된 콘텐츠를 생성한다.
기존 LoRA는 사전 학습된 모델을 위한 plug-and-play 플러그인으로 작동하지만, 여러 LoRA를 통합하여 여러 개념의 공동 합성을 촉진하는 데는 몇 가지 문제점이 있다. 다양한 예술적 스타일이나 고유한 개체의 통합과 같은 다양한 요소를 응집력 있는 시각적 내러티브로 혼합하는 능력이 중요하다. 예를 들어, 각각 특정 스타일로 고양이와 개를 나타내는 사전 학습된 LoRA 모델이 있는 상황을 생각해 보자. 이 두 모델을 결합하여 다양한 배경이나 시나리오에 대해 고양이와 개의 이미지를 생성해야 한다.
그러나 여러 LoRA 모델을 병합하여 새로운 합성 이미지를 생성하는 프로세스는 어려운 것으로 입증되었으며 종종 만족스럽지 못한 결과를 초래한다. 여러 LoRA의 가중 선형 결합을 사용하는 등 LoRA 모델을 결합하려는 시도가 있었지만 LoRA 개념 중 하나가 무시되는 바람직하지 않은 결과를 초래했다. 다른 접근 방식들도 LoRA 수가 증가함에 따라 병합 프로세스를 불안정하게 만드는 성능 문제가 발생하거나 특정 LoRA 모델로 학습해야 한다. 또한 ControlNet 조건에 의해 정의된 제어에 의존하여 생성 능력이 제한된다.
본 논문은 새로운 모델을 학습시키거나 제어를 지정할 필요 없이 테스트 시 여러 LoRA를 합성하는 방법을 제안하였다. 본 논문의 접근 방식에는 LoRA 가중치를 그대로 유지하면서 적절한 LoRA 모델을 이미지의 올바른 영역으로 효과적으로 가이드하기 위해 테스트 시간 동안 latent 업데이트를 통해 attention map을 조정한다.

이전에 이미지 생성에서 언급된 ‘attention overlap’ 및 ‘attribute binding’ 문제가 LoRA 모델에도 존재한다. 특수한 LoRA 모델이 이미지 내의 유사한 feature나 영역에 중복적으로 초점을 맞출 때 attention overlap이 발생한다. 이러한 상황은 하나의 LoRA 모델이 다른 모델의 기여도를 압도하여 균형 잡힌 표현을 희생하면서 생성 프로세스를 특정 속성이나 스타일로 왜곡하는 지배력 문제로 이어질 수 있다 (위 그림 참조). 이러한 지배력은 여러 콘텐츠 LoRA를 포함하는 경우에 특히 문제가 된다.
또 다른 문제는 attribute binding이며, 특히 여러 콘텐츠별 LoRA와 관련된 시나리오에서 발생한다. 예를 들어, 각 LoRA 모델이 그룹 초상화에서 서로 다른 개인의 특성에 초점을 맞추는 경우 attribute binding은 한 개인의 특징이 이미지를 지배하는 위험을 초래할 수 있을 뿐만 아니라 다양한 사람을 나타내려는 특징이 불명확하게 혼합되는 시나리오로 이어질 수도 있다. 이러한 혼합으로 인해 각 개인의 무결성과 인식 가능성을 유지하지 못하는 표현이 생성되어 LoRA 모델이 달성하고자 하는 개인화 및 정확성이 훼손될 수 있다.
예를 들어 ‘집에 있는 $L_1$ 고양이와 $L_2$ 펭귄’이라는 텍스트 프롬프트를 생각해 보자. Stable Diffusion (SD) 모델은 의도한 결과를 생성하지 못하고 두 마리의 고양이를 출력한다. 이 문제는 고양이에 초점을 맞춰야 하는 $L_1$ attention이 펭귄의 $L_2$ attention과 혼합되기 때문에 발생한다. 반면, 본 논문의 방식은 의도된 속성에 집중하기 위해 LoRA 모델의 attention map을 효과적으로 개선하여 두 LoRA 모델을 올바른 위치에 정확하게 배치하는 이미지를 생성한다.
Methodology
본 논문의 방법은 LoRA를 활용하여 사용자 정의 개념을 Stable Diffusion 이미지 생성에 통합하기 위해 contrastive learning 프레임워크 내에서 attention map 개념을 활용한다. 두 개의 LoRA 모델인 ‘여성’을 뜻하는 $L_1$과 ‘우산’을 뜻하는 $L_2$를 생각해 보자. $L_1$이 여성의 스타일이나 컨셉을 정의하고 $L_2$가 우산의 스타일이나 컨셉을 정의하는 ‘우산을 쓴 여성’의 이미지가 출력되어야 한다.
프롬프트 분석 및 임베딩
세 가지 별도의 텍스트 프롬프트를 만든다.
- 원본 프롬프트: ‘우산을 쓴 여성’
- $L_1$ LoRA가 적용된 프롬프트: ‘우산을 쓴 $L_1$ 여성’
- $L_2$ LoRA가 적용된 프롬프트: ‘$L_2$ 우산을 쓴 여성’
그런 다음 텍스트 인코더 모델인 CLIP 모델도 LoRA 학습 과정에서 fine-tuning될 수 있으므로 해당 모델을 사용하여 해당 프롬프트 임베딩을 생성한다. 텍스트 인코더 모델이 UNet 가중치와 함께 학습되지 않으면 base model을 사용하여 모든 텍스트 임베딩을 추출할 수 있다.
Attention map을 통한 diffusion 가이드
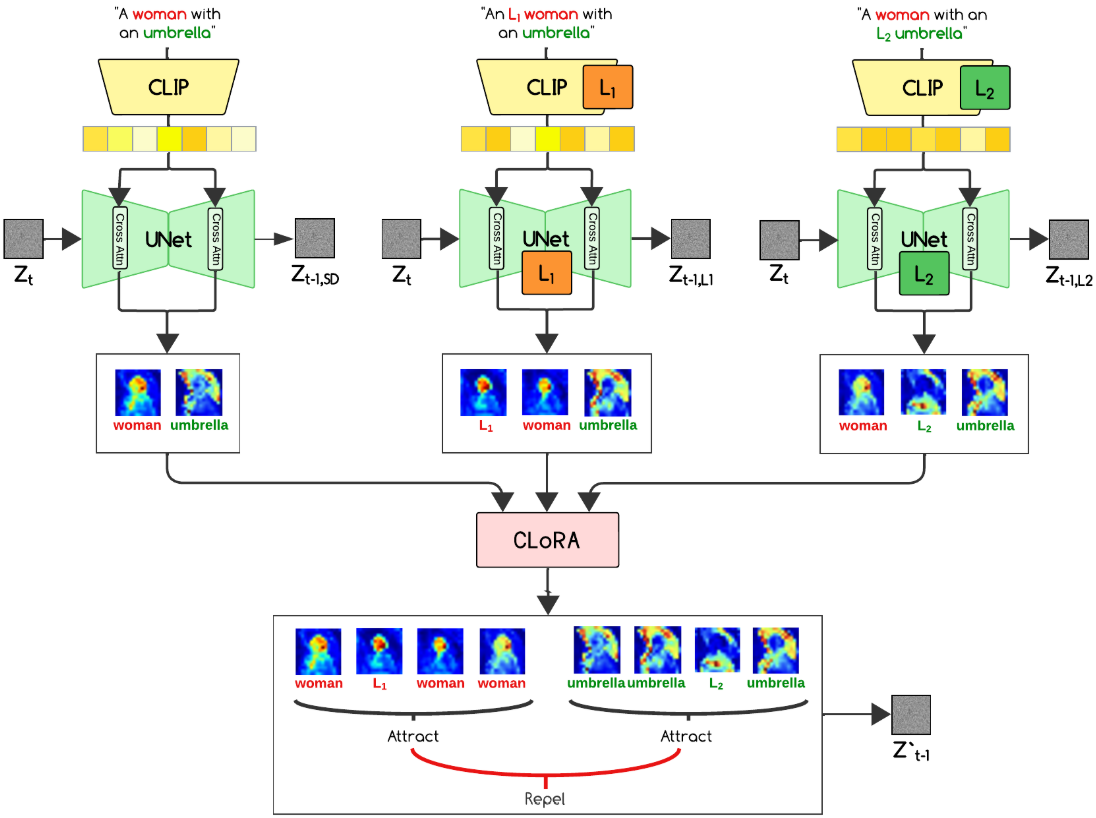
이미지 생성 중에 Stable Diffusion은 cross-attention map을 사용하여 각 step의 특정 이미지 영역에 초점을 맞춘다. Cross-attention map을 활용하여 원하는 LoRA 개념을 통합하는 방향으로 diffusion process를 가이드한다.
프롬프트의 해당 토큰을 기반으로 각 개념(여성, 우산)에 대한 cross-attention map을 그룹화한다. 그룹화의 세부 분류는 다음과 같다.
- ‘여성’ 개념 그룹
- 원본 프롬프트의 ‘여성’에 대한 cross-attention map
- $L_1$이 적용된 프롬프트에서 ‘$L_1$’과 ‘여성’에 대한 cross-attention map
- $L_2$가 적용된 프롬프트에서 ‘여성’에 대한 cross-attention map
- ‘우산’ 개념 그룹
- 원본 프롬프트의 ‘우산’에 대한 cross-attention map
- $L_1$이 적용된 프롬프트에서 ‘우산’에 대한 cross-attention map
- $L_2$가 적용된 프롬프트에서 ‘$L_2$와 ‘우산’에 대한 cross-attention map
그룹화를 통해 diffusion process는 모든 프롬프트에서 동일한 개념에 대한 attention을 동시에 고려한다. 이는 LoRA 모델에서 정의한 스타일 변형을 통합하면서 모델이 각 개체의 전반적인 개념을 이해하는 데 도움이 된다. 또한 이 그룹화는 여러 그룹이 동일한 위치에 attention되는 것을 방지한다. 예를 들어 여성에 대한 attention이 우산에 대한 attention과 겹치지 않도록 한다. 이렇게 하면 생성 중에 텍스트의 어떤 측면도 무시되는 것을 방지할 수 있다.
충실도를 위한 대조 학습
입력 프롬프트에 대한 생성의 충실도를 보장하기 위해 inference 중에 contrastive learning을 사용한다. Contrastive learning 목적 함수의 경우 수렴이 빠르다고 알려진 InfoNCE loss를 사용한다. InfoNCE loss는 cross-attention map 쌍에서 작동한다. 동일한 그룹 내의 attention map 쌍은 positive로 지정되고 다른 그룹 사이의 쌍은 negative로 지정된다. Loss function은 주어진 attention map $A^j$에 대해 다음과 같이 표현될 수 있다.
\[\begin{equation} \mathcal{L} = - \log \frac{\exp (\textrm{sim} (A^j, A^{j^{+}}) / \tau)}{\sum_{n \in \{j^{+}, j_1^{-}, \cdots, j_N^{-}\}} \exp (\textrm{sim} (A^j, A^n) / \tau)} \end{equation}\]여기서 $\textrm{sim}$ 함수는 cosine similarity이다. $\tau$는 temperature 파라미터이고 분모의 합은 $A_j$에 대한 하나의 positive 쌍과 모든 negative 쌍이 포함된다. 모든 positive 쌍에 대한 평균 InfoNCE loss를 계산한다.
최적화
Loss function은 하나의 항으로 구성된다. 그런 다음 loss function으로 측정된 방향으로 latent 표현을 보낸다. Latent 표현은 다음과 같이 각 step에서 업데이트된다.
\[\begin{equation} z_t^\prime = z_t - \alpha_t \nabla_{z_t} \mathcal{L} \end{equation}\]Latent 마스킹
Diffusion process에서 한 backward step 후 Stable Diffusion에 의해 생성된 latent 표현을 추가 LoRA 모델의 latent 표현과 결합한다. 이러한 label를 직접 결합하는 것이 가능하지만 LoRA가 관련 이미지 영역에만 영향을 미치도록 마스킹 메커니즘을 도입한다. 이 마스킹은 해당 LoRA 출력에서 얻은 attention mask 값에 의존한다. 각 토큰의 attention map 값에 threshold를 적용하여 바이너리 마스크를 만든 다음 합집합 연산을 사용하여 결합한다.
‘$L_2$ 우산을 쓴 $L_1$ 여성’의 경우 마스킹 절차는 다음과 같이 작동한다.
- $L_1$이 적용된 프롬프트에서 ‘$L_1$’과 ‘여성’의 attention map을 얻는다. $L_2$가 적용된 프롬프트에서 ‘$L_2$’와 ‘우산’의 attention map을 얻는다.
- Attention map의 최댓값의 특정 백분율을 초과하는 attention 값이 있는 영역만 1이 되도록 각 attention map에 thresholding 연산을 적용한다.
- 하나의 LoRA에 기여하는 여러 토큰이 있을 수 있으므로 (ex. $L_1$의 경우 ‘여성’, ‘$L_1$ 여성’) 개별 마스크에 대해 합집합 연산을 수행한다. 이렇게 하면 두 토큰 중 하나에서 attention되는 모든 영역이 해당 LoRA의 최종 마스크에 포함된다.
Experiments
- 데이터셋: Custom Concept
- 실험 셋업
- 각 프롬프트마다 시드 10개를 사용
- 모델: Stable Diffusion v1.5 (50 iterations)
- iteration \(i \in \{0, 10, 20\}\)에서 backward step를 시작하기 전에 최적화를 여러 번 수행
- $i = 25$ 이후에는 원치 않는 아티팩트를 방지하기 위해 추가 최적화도 중지
- temperature: $\tau = 0.5$
- GPU: NVIDIA V100
1. Qualitative Experiments
다음은 CLoRA의 다양한 합성 결과이다. (동물-동물, 물체-물체, 동물-물체)

다음은 두 LoRA를 합성한 결과를 다른 방법들과 비교한 것이다.


다음은 세 LoRA를 합성한 결과를 다른 방법들과 비교한 것이다.

다음은 인간 피사체에 대한 합성 결과들을 비교한 것이다.

다음은 두 가지 피사체와 한 가지 스타일을 합성한 CLoRA의 결과들이다.

2. Quantitative Experiments
다음은 DINO image-image similarity를 비교한 결과와 user study 결과이다.

3. Ablation Study
다음은 latent 업데이트 및 마스킹에 대한 ablation 결과이다.

Limitation
- 합성 결과가 LoRA 모델의 품질에 달려 있다
- 여러 LoRA 모델을 동시에 통합하고 최적화하는 데 수반되는 잠재적인 계산 복잡도가 높다. 이는 이미지 생성을 시간 및 리소스 요구 사항 측면에서 문제를 일으킬 수 있다.