[논문리뷰] CLIPPO: Image-and-Language Understanding from Pixels Only
CVPR 2023. [Paper] [Github]
Michael Tschannen, Basil Mustafa, Neil Houlsby
Google Research, Brain Team
15 Dec 2022
Introduction
최근 몇 년 동안 Transformer 기반 모델의 대규모 멀티모달 학습을 통해 비전, 언어, 오디오를 포함한 다양한 도메인에서 SOTA 개선이 이루어졌다. 특히, 컴퓨터 비전과 이미지-언어 이해에서는 하나의 대규모 사전 학습 모델이 task별 전문가 모델보다 성능이 뛰어날 수 있다. 그러나 대규모 멀티모달 모델은 modality 또는 데이터셋별 인코더 및 디코더를 사용하는 경우가 많으며 그에 따라 관련 프로토콜이 발생한다. 예를 들어, 이러한 모델에는 데이터셋별 전처리를 사용하거나 task별 방식으로 다른 부분을 전송하는 등 해당 데이터셋에 대해 별도의 단계에서 모델의 여러 부분을 학습하는 경우가 많다. 이러한 modality 및 task별 구성 요소는 추가적인 엔지니어링 복잡성을 초래할 수 있으며 새로운 사전 학습 loss 또는 다운스트림 task를 도입할 때 문제를 발생시킨다. 모든 modality 또는 modality의 조합을 처리할 수 있는 하나의 end-to-end 모델을 개발하는 것은 멀티모달 학습을 위한 귀중한 단계가 될 것이다. 본 논문에서는 이미지와 텍스트에 중점을 둔다.
여러 주요 통합들로 멀티모달 학습의 진행이 가속화되었다. 첫째, Transformer 아키텍처는 텍스트, 비전, 오디오, 기타 도메인에서 우수한 성능을 발휘하는 범용 backbone으로 작동하는 것으로 나타났다. 둘째, 많은 연구들에서는 입력/출력 인터페이스를 단순화하거나 많은 task에 대한 하나의 인터페이스를 개발하기 위해 다양한 modality를 하나의 공유 임베딩 공간에 매핑하는 방법을 탐구했다. 셋째, modality의 대안적 표현을 통해 한 도메인의 아키텍처 또는 다른 도메인을 위해 설계된 학습 절차를 활용할 수 있다. 예를 들어, 이러한 텍스트와 오디오를 각각 이미지로 렌더링하여 사용할 수 있다.
본 논문에서는 텍스트와 이미지의 멀티모달 학습을 위한 순수 픽셀 기반 모델의 사용을 살펴본다. 본 논문의 모델은 시각적 입력, 텍스트 또는 둘 다를 모두 RGB 이미지로 렌더링하는 하나의 ViT이다. 낮은 수준의 feature 처리를 포함한 모든 modality에 동일한 모델 파라미터가 사용된다. 즉, modality별 초기 convolution, 토큰화 알고리즘, 입력 임베딩 테이블이 없다. CLIP과 ALIGN으로 대중화된 contrastive learning이라는 하나의 task만 사용하여 모델을 학습시킨다. 따라서 본 논문의 모델을 CLIP-Pixels Only (CLIPPO)라고 부른다.
CLIPPO는 modality별 타워가 없음에도 불구하고 CLIP이 설계된 주요 task (이미지 분류, 텍스트/이미지 검색)에서 CLIP 스타일 모델과 유사하게 수행되는 것으로 나타났다. 놀랍게도 CLIPPO는 left-to-right 언어 모델링, masked language modelling, 명시적인 단어 수준 loss 없이 복잡한 언어 이해 task를 괜찮은 수준으로 수행할 수 있다. 특히 GLUE 벤치마크에서 CLIPPO는 ELMO+BiLSTM+attention과 같은 기존 NLP baseline보다 성능이 뛰어나고 이전 픽셀 기반 masked language model보다 성능이 뛰어나며 BERT의 점수에 근접한다. 흥미롭게도 CLIPPO는 VQA 데이터에 대해 사전 학습을 받은 적이 없음에도 불구하고 단순히 이미지와 텍스트를 함께 렌더링할 때 VQA에서 좋은 성능을 얻는다.
픽셀 기반 모델은 vocabulary/토크나이저를 미리 결정하고 상응하는 복잡한 trade-off를 탐색할 필요가 없기 때문에 일반 언어 모델에 비해 즉각적인 이점이 있다. 결과적으로 CLIPPO는 기존 토크나이저를 사용하는 동등한 모델에 비해 다국어 검색 성능이 향상되었다.
Contrastive language-image pretraining with pixels
Contrastive language-image pretraining (CLIP)은 웹 스케일 데이터셋에서 다양한 비전 모델을 학습하기 위한 강력하고 확장 가능한 패러다임으로 등장했다. 구체적으로 이 접근 방식은 웹에서 대규모로 자동 수집할 수 있는 이미지/대체 텍스트 쌍에 의존한다. 따라서 텍스트 설명은 일반적으로 잡음이 많으며, 단일 키워드, 키워드 집합, 이미지 콘텐츠를 설명하는 많은 속성이 포함된 긴 설명으로 구성된다. 이 데이터를 사용하여 두 개의 인코더, 즉 대체 텍스트를 임베딩하는 텍스트 인코더와 해당 이미지를 공유 latent space에 포함하는 이미지 인코더가 공동으로 학습된다. 이 두 인코더는 contrastive loss로 학습되어 일치하는 이미지와 대체 텍스트의 임베딩이 유사하면서도 동시에 다른 모든 이미지와 대체 텍스트 임베딩과 다르지 않도록 장려한다.
일단 학습되면 이러한 인코더 쌍은 다양한 방법으로 사용될 수 있다. 텍스트 설명을 통해 고정된 시각적 개념 집합을 분류하는 데 특화될 수 있다. 임베딩은 텍스트 설명이 제공된 이미지를 검색하는 데 사용될 수 있으며 그 반대의 경우도 마찬가지이다. 또는 비전 인코더는 레이블이 지정된 데이터셋을 fine-tuning하거나 고정된 이미지 인코더 표현 위에 head를 학습시킴으로써 supervised 방식으로 다운스트림 task로 전송될 수 있다. 원칙적으로 텍스트 인코더는 독립형 텍스트 임베딩으로 사용될 수 있지만 이 애플리케이션은 심층적으로 탐색되지 않았으며 일부 연구에서는 대체 텍스트의 품질이 낮아서 텍스트 인코더의 언어 모델링 성능이 약하다고 언급했다.
이전 연구에서는 이미지와 텍스트 인코더가 하나의 공유 Transformer 모델 (단일 타워 모델, 1T-CLIP)로 실현될 수 있음을 보여주었다. 여기서 이미지는 패치 임베딩을 사용하여 임베딩되고 토큰화된 텍스트는 별도의 단어 임베딩을 사용하여 임베딩된다. Modality별 임베딩 외에도 모든 모델 파라미터는 두 가지 modality에 대해 공유된다. 이러한 유형의 공유는 일반적으로 이미지 task와 이미지-언어 task에서 약간의 성능 저하로 이어지지만 모델 파라미터 수도 절반으로 줄어든다.

CLIPPO는 이 아이디어를 한 단계 더 발전시킨다. 텍스트 입력은 빈 이미지에 렌더링되고 이후 초기 패치 삽입을 포함하여 완전히 이미지로 처리된다 (위 그림 참조). 이 하나의 ViT를 대조적으로 학습함으로써 비전의 단일 인터페이스를 통해 이미지와 텍스트를 모두 이해할 수 있고 이미지, 이미지-언어, 언어 이해 task를 해결하는 데 사용할 수 있는 단일 표현을 제공하는 하나의 ViT 모델을 얻는다.
멀티모달 다양성과 함께 CLIPPO는 텍스트 처리, 즉 적절한 토크나이저와 vocabulary 개발과 관련된 일반적인 장애물을 완화한다. 이는 텍스트 인코더가 수십 개의 언어를 처리해야 하는 대규모 다국어 설정에서 특히 흥미롭다.
이미지/대체 텍스트 쌍에 대해 학습된 CLIPPO는 일반적인 이미지 및 이미지 언어 벤치마크에서 1T-CLIP 성능과 비슷한 성능을 발휘하며 GLUE 벤치마크에서 강력한 baseline 언어 모델과 경쟁적이다. 그러나 문법적인 문장이 아닌 대체 텍스트의 품질이 낮기 때문에 대체 텍스트에서만 언어 이해를 학습하는 것은 근본적으로 제한된다. 따라서 언어 기반 contrastive learning을 통해 사전 학습을 강화한다. 구체적으로, 텍스트 코퍼스에서 샘플링된 연속 문장의 positive 쌍을 사용하며, 렌더링된 텍스트/텍스트 쌍으로 이미지/대체 텍스트 배치를 보완한다.
Experiments
- 데이터셋
- 이미지/대체 텍스트: WebLI
- 텍스트/텍스트: Colossal Clean Crawled Corpus
- 구현 디테일
- 기본 아키텍처: ViT-B/16
- 표현의 차원: 768
- batch size: 10,240
- 학습 iteration 수: 25만
- 일정 비율의 텍스트/텍스트 데이터로 공동 학습된 모델의 경우, 이미지/대체 텍스트 쌍의 수가 텍스트/텍스트 데이터가 없는 모델의 iteration 수와 일치하도록 iteration 수를 조정 (ex. 50%의 데이터가 텍스트/텍스트 쌍인 경우 iteration 수를 25만에서 50만으로 증가시킴)
- contrastive loss는 전체 배치에 대하여 계산됨
- optimizer: Adafactor
- learning rate: $10^{-3}$
- weight decay: $10^{-4}$
- 텍스트 렌더링 폰트: GNU Unifont
1. Vision and vision-language understanding
Image classification and retrieval
다음은 비전 및 비전-언어 결과이다.
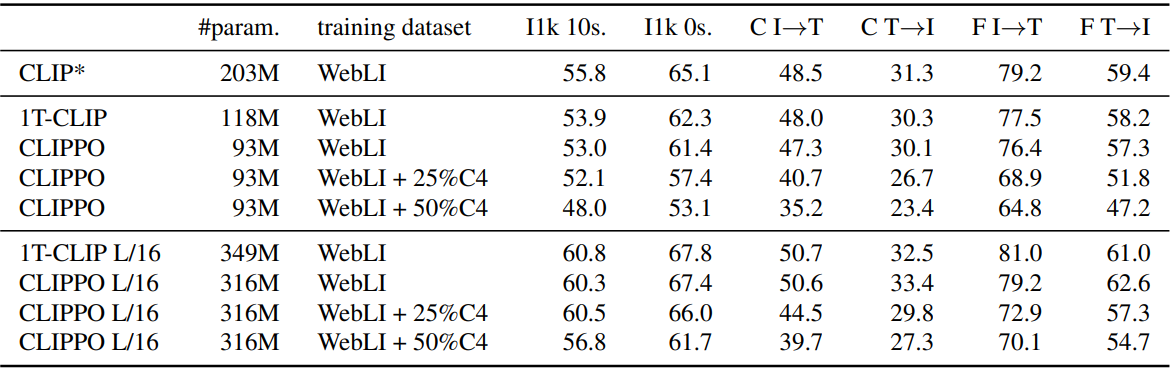
사용된 평가 지표는 다음과 같다.
- I1k 10s: ImageNet-1k 10-shot linear transfer 정확도
- I1k 0s: ImageNet-1k zero-shot transfer 정확도
- C I$\rightarrow$T: MS-COCO image-to-text 검색 recall@1
- C T$\rightarrow$I: MS-COCO text-to-image 검색 recall@1
- F I$\rightarrow$T: Flickr30k image-to-text 검색 recall@1
- F T$\rightarrow$I: Flickr30k text-to-image 검색 recall@1
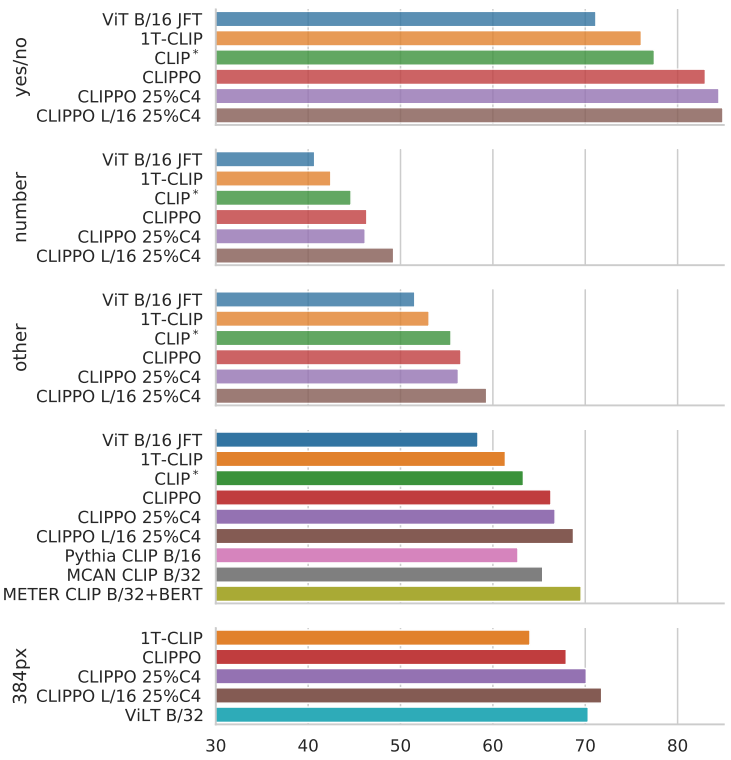
VQA
다음은 VQAv2 test-dev에 대한 결과이다.
2. Multilingual vision-language understanding
다음은 Crossmodal3600에서 다국어 이미지/텍스트 검색에 대하여 WebLI에서 학습된 CLIPPO (검은 점선)와 다국어 대체 텍스트를 여러 SentencePiece 토크나이저가 있는 1T-CLIP과 비교한 결과이다.

Tokenization efficiency
다음은 주어진 방법으로 생성된 시퀀스 길이 측면에서 토큰화 효율성을 분석한 결과이다.
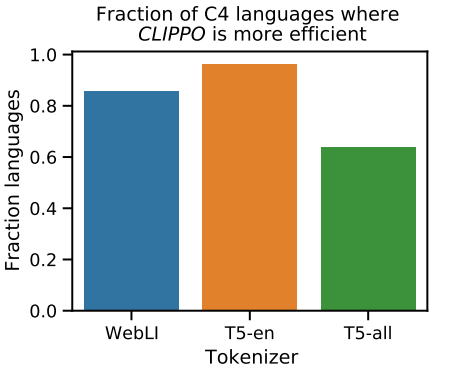
CLIPPO는 대체 토크나이저를 사용하는 1T-CLIP에 비해 대부분의 언어에 대해 더 작은 시퀀스를 생성한다.
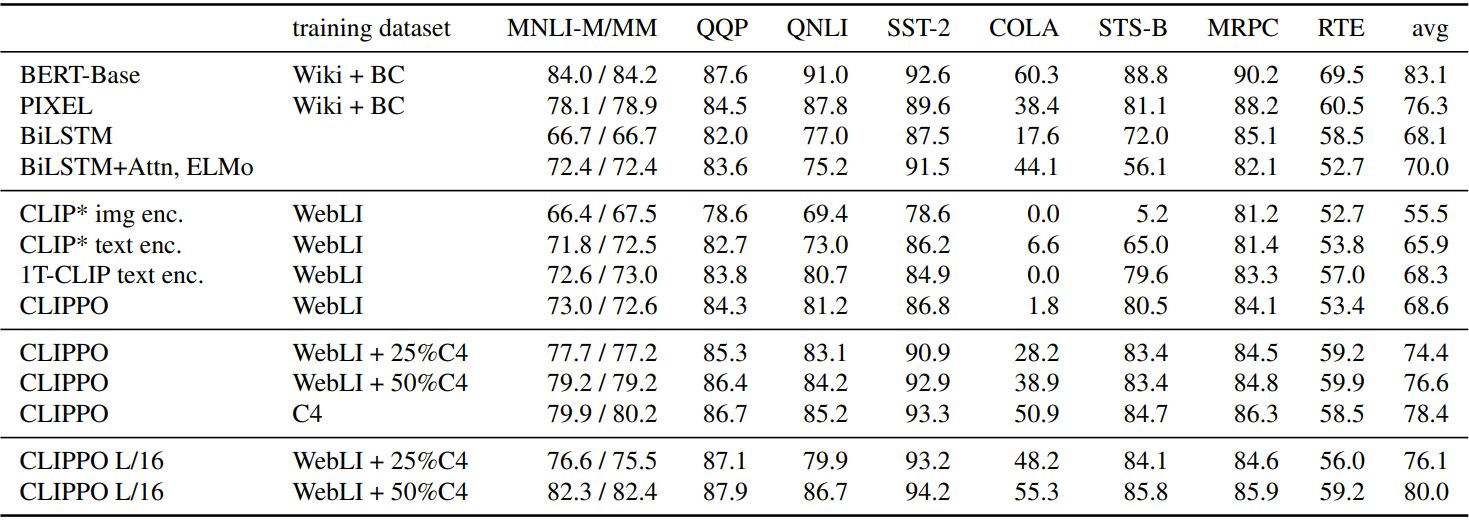
3. Language understanding
다음은 GLUE 벤치마크 (dev set)에서의 결과이다. QQP와 MRPC
4. Ablations and analysis
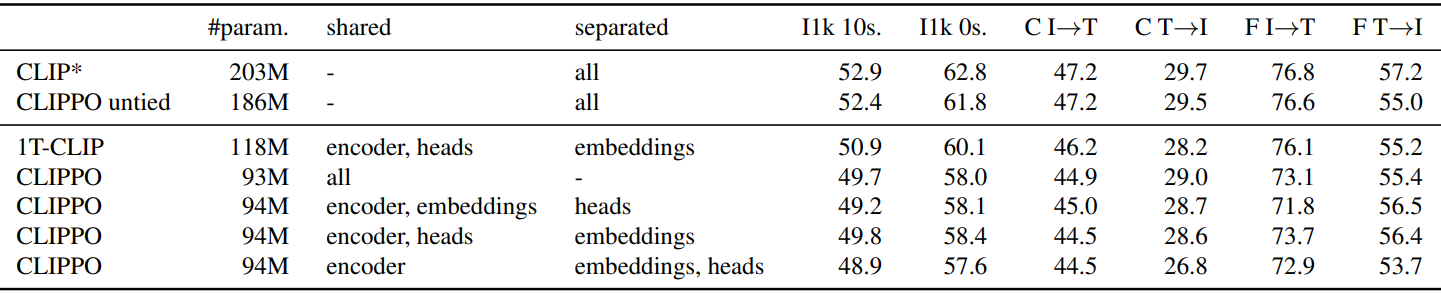
Impact of weight sharing across modalities
다음은 이미지와 렌더링된 텍스트 입력에 대하여 별도의 임베딩 및/또는 head를 사용한 다양한 모델을 학습한 후 비교한 표이다.
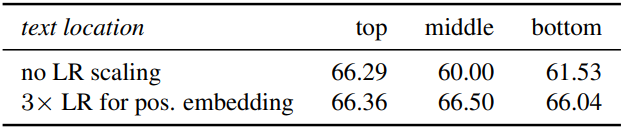
Impact of the text location
다음은 VQAv2 test-dev에서 텍스트 위치에 대한 영향을 비교한 표이다.
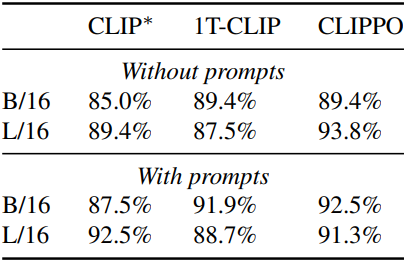
Typographic attacks
다음은 실제 typographic attack 데이터셋에서 모델을 테스트한 결과이다. 데이터셋은 20개 객체로 생성되었다. 각 객체에는 공격이 전혀 없는 객체의 그림과 객체 위에 포스트잇이 붙어 있는 버전이 19개 있다. 포스트잇에는 객체와 관련이 없는 잘못된 레이블이 적혀 있다. 공격에 취약한 모델은 객체를 이러한 혼란스러운 레이블 중 하나로 분류한다.
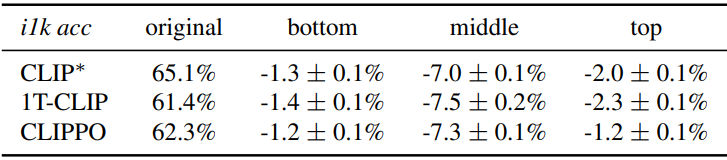
다음은 ImageNet에서 각 이미지에 대해 Unifont 렌더러를 사용하여 무작위로 선택된 잘못된 레이블을 삽입한 후 zero-shot 분류 정확도를 평가한 결과이다. 이 레이블을 읽는 모델은 ImageNet 정확도가 크게 떨어지므로 공격에 더 취약해진다.
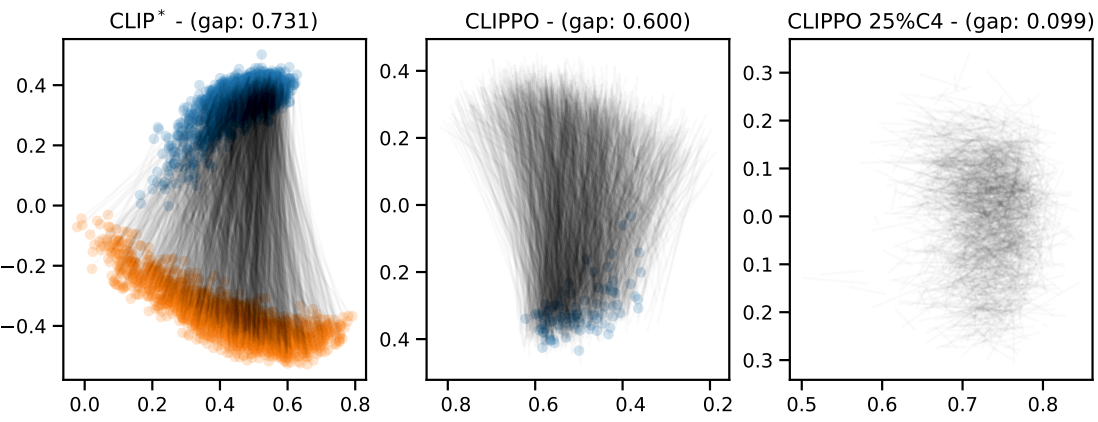
Modality gap
다음은 25% C4 데이터로 선택적으로 학습된 CLIP*과 CLIPPO에 대한 modality 격차를 시각화한 것이다.
Text/text co-training objectives
다음은 텍스트 쌍 기반 공동 학습에 대한 ablation 결과이다.
- WMT19: 병렬 번역 문장에 대하여 학습
- WMT19 BT: 병렬 역번역 문장에 대하여 학습되면
- C4 NSP: C4에서 샘플링된 문장에 대한 다음 문장 예측

Limitations
- 공동 학습: GLUE에서 PIXEL, BERT와 경쟁할 수 있는 언어 이해 성능을 달성하기 위해서는 텍스트 쌍을 이용한 공동 학습이 필요하다. 배치에 25%의 C4 데이터를 추가하면 고려된 모든 task에서 좋은 균형을 이루는 것처럼 보이지만 zero-shot 이미지 분류와 이미지/텍스트 검색에서는 무시할 수 없을 정도로 성능이 감소한다. 이 하락은 C4의 비율이 증가함에 따라 더욱 심각해진다.
- 다양한 렌더링 텍스트: CLIPPO는 현재 깔끔하게 렌더링된 텍스트를 입력으로 사용하며 추가 조정 없이 문서 또는 웹 페이지의 텍스트를 처리하는 능력이 제한된다. 문서 및 웹 사이트의 배포를 모방하는 noisy한 렌더링 텍스트로 CLIPPO를 학습하면 이미지/대체 텍스트 쌍의 상관 관계가 낮아지고 학습 신호가 약해지기 때문에 고려된 task 전체에서 성능이 저하될 가능성이 높다.
- 생성형 모델링: CLIP, BERT, PIXEL 및 기타 여러 모델과 마찬가지로 CLIPPO는 인코더만 있는 디자인을 사용하므로 텍스트 출력을 생성하는 능력이 부족하다. 인코더만 있는 모델에 생성 능력을 장착하는 일반적인 접근 방식은 사전 학습된 언어 모델과 결합하는 것이다. 이 접근 방식은 자연스럽게 CLIPPO과 PIXEL에도 적용되지만 특정 시나리오 (ex. 다국어)에서는 시각적 텍스트의 장점이 무산된다.
- 다국어 학습: 검색 성능을 세밀하게 조정하고 균형을 맞추려면 데이터 균형 조정이나 다국어 텍스트 데이터와의 공동 학습 등의 추가 단계가 필요하다. 또한 PIXEL과 유사하게 CLIPPO는 시각적 표현과 관련하여 특정 임시 디자인 선택에 의존한다. 이 접근 방식은 평균적으로 괜찮은 성능을 제공하지만 어떤 종류의 원치 않는 영향이 발생하고 이를 어떻게 완화할 수 있는지는 확실하지 않다.