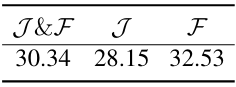[논문리뷰] CLIP as RNN: Segment Countless Visual Concepts without Training Endeavor
CVPR 2024. [Paper] [Page] [Github]
Shuyang Sun, Runjia Li, Philip Torr, Xiuye Gu, Siyang Li
University of Oxford | Google Research
12 Dec 2023

Introduction
다양한 연구들에서는 CLIP과 같은 인터넷 규모의 이미지-텍스트 쌍에 대해 학습된 비전-언어 모델(VLM)을 사용하여 임의의 텍스트 쿼리에 의해 이미지의 모든 개념을 분할하는 방법을 모색했다. 몇몇 연구에서는 사전 학습된 VLM을 bounding box나 마스크에 대해 학습된 segmenter와 통합했다. 이러한 방법들은 공통 카테고리를 사용하는 segmentation 벤치마크에서 우수한 성능을 보이지만 더 넓은 어휘를 처리하는 능력은 fine-tuning에 사용되는 데이터셋의 작은 카테고리 목록으로 인해 방해를 받는다. 예를 들어 Pepsi나 Coca Cola와 같은 개념을 인식하지 못한다.

Bounding box나 마스크 주석은 비용이 많이 들기 때문에 기존 연구들은 이미지 수준 주석만 사용하여 VLM과 보조 segmentation 모듈을 fine-tuning하려고 하였다. 이로 인해 복잡한 fine-tuning 파이프라인이 발생하게 된다. 게다가 이미지 수준 레이블은 좋지 못한 마스크 품질을 갖는 경우가 많다.
본 논문에서는 사전 학습된 VLM의 광범위한 어휘 공간을 완전히 보존하기 위해 마스크 주석 또는 추가 이미지-텍스트 쌍에 대한 fine-tuning을 제거하였다. VLM의 사전 학습은 dense한 예측을 위해 특별히 설계되지 않았기 때문에 fine-tuning을 하지 않는 기존 연구들은 일부 텍스트 쿼리가 이미지에 존재하지 않는 개체를 참조하는 경우 텍스트 쿼리에 해당하는 정확한 마스크를 생성하는 데 어려움을 겪는다.
본 논문에서는 이 문제를 해결하기 위해 각 mask proposal과 텍스트 쿼리 간의 정렬 정도를 반복적으로 평가하고 신뢰도가 낮은 텍스트 쿼리를 점진적으로 제거하였다. 텍스트 쿼리가 더 명확해짐에 따라 결과적으로 더 나은 mask proposal을 얻을 수 있다. 이러한 반복적 개선을 용이하게 하기 위해 recurrent unit으로 two-stage segmenter를 사용하는 새로운 recurrent 아키텍처를 제안하였다. Two-stage segmenter는 mask proposal generator와 mask proposal을 평가하는 mask classifier로 구성된다. 둘 다 수정 없이 사전 학습된 CLIP 모델을 기반으로 구축되었다. 입력 이미지와 여러 텍스트 쿼리가 주어지면 비전 공간과 텍스트 공간을 반복적으로 정렬하고 최종 출력으로 세련된 마스크를 생성하여 안정적인 상태가 달성될 때까지 반복한다. 반복되는 특성으로 인해 전체 프레임워크를 CLIP as RNN (CaR)이라 부른다.
Method
1. Overview
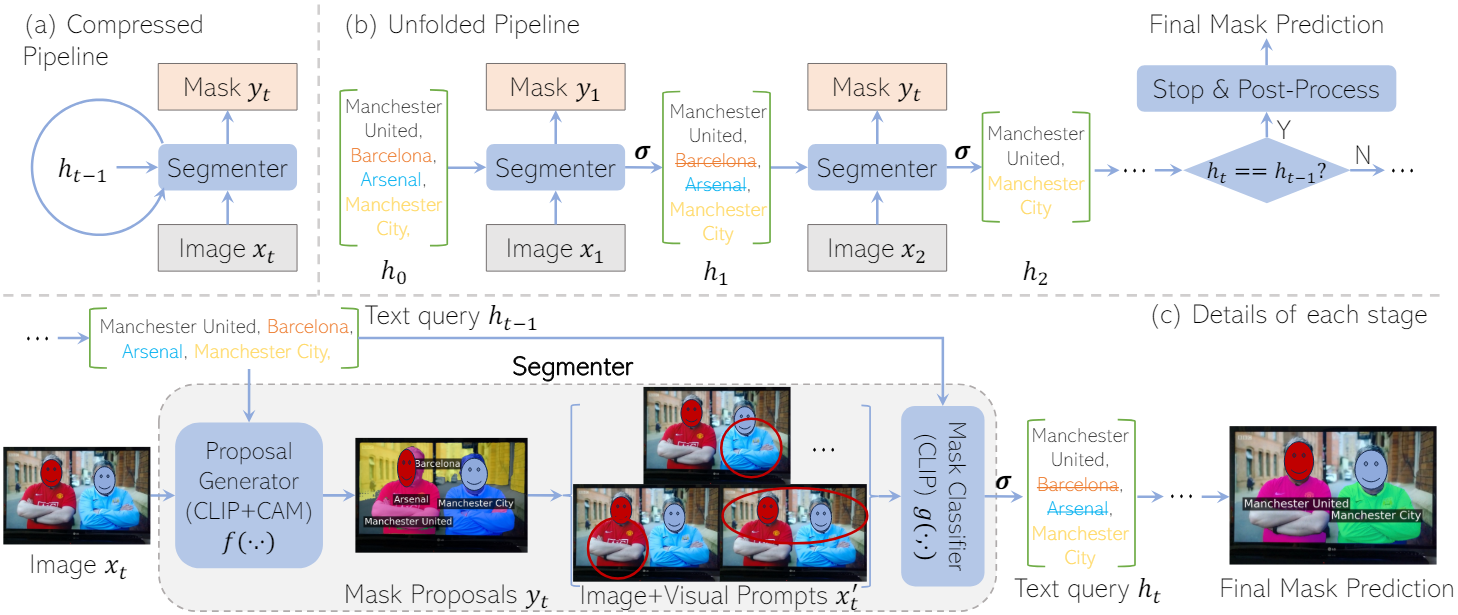
위와 같은 학습 없는 프레임워크는 모든 timestep에서 고정된 가중치의 segmenter를 공유하여 반복적인 방식으로 작동한다. $t$번째 timestep에서 segmenter는 이미지 $x_t \in \mathbb{R}^{3 \times H \times W}$와 이전 step의 텍스트 쿼리 집합 $h_{t−1}$을 입력으로 받는다. 그런 다음 $N_{t−1}$개의 입력 텍스트 쿼리에 해당하는 마스크 집합 $y_t \in [0, 1]^{N_{t-1} \times H \times W}$와 후속 step에 대한 업데이트된 텍스트 쿼리 $h_t$를 출력한다. Image segmentation의 경우 모든 timestep은 동일한 $x_t$를 공유한다.
여기서 함수 $f$는 mask proposal generator이고 $W_f$는 사전 학습된 가중치이다. Mask proposal generator는 입력 이미지 $x_t$와 이전 step의 텍스트 쿼리 $h_{t-1}$을 처리하여 후보 mask proposal $y_t$를 생성한다. Mask proposal generator가 dense한 예측을 위해 사전 학습되지 않은 경우 $f$의 mask proposal $y_t$는 정확하지 않다. 이러한 mask proposal을 평가하기 위해 mask proposal을 기반으로 $x_t$에 빨간색 원이나 배경 blur와 같은 비주얼 프롬프트를 그린다. 비주얼 프롬프팅 함수 $v$는 다음과 같이 정의된다.
\[\begin{equation} x_t^\prime = v (x_t, y_t) \end{equation}\]$x_t^\prime$은 비주얼 프롬프트가 포함된 $N_{t−1}$개의 이미지이다. 그런 다음 $x_t^\prime$은 텍스트 쿼리 $h_{t−1}$과 함께 사전 학습된 가중치 $W_g$의 mask classifier $g$에 전달되며, 유사도 행렬 $P_t$가 계산된다. Mask classifier의 전체 프로세스는 다음과 같이 정의할 수 있다.
\[\begin{equation} P_t = g(x_t^\prime, h_{t-1}; W_g) \end{equation}\]마지막으로 thresholding 함수 $\sigma$를 거친 후 유사도 점수가 threshold $\theta$보다 낮은 텍스트 쿼리를 제거하여 다음 step $t$에 대한 텍스트 쿼리 $h_t = \sigma (P_t)$를 얻는다. $h_t$는 $h_{t−1}$의 부분 집합이다. 이 반복 프로세스는 연속된 step 사이에서 텍스트 쿼리가 변경되지 않을 때까지, 즉 $h_t = h_{t−1}$일 때까지 계속된다. 이 최종 timestep을 $T$로 나타낸다. 마지막으로, $T$에서 생성된 mask proposal $y_T$에 후처리를 적용한다.
Algorithm 1은 PyTorch 스타일의 pseudo-code이다.

2. The Two-stage Segmenter
Mask proposal generator가 먼저 각 텍스트 쿼리에 대한 마스크를 예측한 다음 mask classifier가 관련 마스크와의 정렬 정도에 따라 관련 없는 텍스트 쿼리를 필터링한다. CLIP의 지식을 완전히 보존하기 위해 proposal generator와 classifier 모두에 사전 학습된 CLIP 모델의 고정된 가중치를 사용한다.
Mask proposal generator
Mask proposal $y_t$를 예측하기 위해 사전 학습된 CLIP에 gradCAM (gradient-based Class-Activation Map)이 적용된다. 이미지 $x_t$와 텍스트 쿼리 $h_{t−1}$이 먼저 CLIP에 입력되어 이미지와 각 텍스트 사이의 점수를 얻는다. 그런 다음 CLIP 이미지 인코더의 feature map에서 각 텍스트 쿼리(즉, 클래스) 점수의 기울기를 역전파하여 히트맵을 얻는다. 저자들은 CLIP-ES를 mask proposal generator로 사용하였다. 현재 step의 텍스트 쿼리와 별도로 텍스트 쿼리에 존재하지 않는 카테고리를 설명하는 일련의 배경 쿼리를 명시적으로 추가하고 해당 기울기를 계산한다. 이는 후속 마스크 분류 프로세스에서 관련 없는 텍스트의 활성화를 억제하는 데 도움이 된다.
Mask classifier
Proposal generator의 마스크는 입력 텍스트가 제한되지 않은 어휘에서 나온 것이고 입력 이미지에 존재하지 않는 개체를 참조할 수 있기 때문에 잡음이 있을 수 있다. 이러한 유형의 proposal을 제거하기 위해 다른 CLIP 모델을 적용하여 각 쿼리와 관련 mask proposal 간의 유사도 점수를 계산한다. 빨간색 원, bounding box, 배경 blur, 회색 배경과 같은 다양한 시각적 프롬프트를 적용하여 CLIP 모델이 전경 영역에 초점을 맞추도록 가이드한다.
이러한 비주얼 프롬프트를 이미지에 적용하기 전에 먼저 threshold $\eta$를 기준으로 mask proposal $y_t$를 바이너리로 만든다. 비주얼 프롬프트를 적용한 후 $N_{t−1}$개의 텍스트 쿼리 $h_{t−1}$에 해당하는 $N_{t−1}$개의 프롬프팅된 이미지를 얻는다. 이러한 이미지와 텍스트 쿼리를 CLIP classifier $g$에 입력한 다음 텍스트 쿼리 차원을 따라 softmax 연산을 수행하여 유사도 행렬 $P_t \in \mathbb{R}^{N_{t-1} \times N_{t-1}}$을 얻는다. $i$번째 마스크와 $i$번째 쿼리 사이의 매칭 점수로 $P_t$의 대각 성분만 유지한다. 점수가 threshold $\theta$보다 낮으면 쿼리와 해당 마스크가 필터링된다. Thresholding 함수 $\sigma$는 다음과 같이 정의된다.
\[\begin{equation} h_t^i = \sigma (P_t^{ii}) = \begin{cases} h_{t-1}^i & \quad \textrm{if} \quad P_t^{ii} \ge \theta \\ \textrm{NULL} & \quad \textrm{if} \quad P_t^{ii} < \theta \end{cases} \end{equation}\]$\textrm{NULL}$은 필터링되어 제거되었음을 의미하며 다음 step에 입력으로 사용되지 않는다.
3. Post-Processing
반복 프로세스가 중지되면 최종 step $T$의 마스크인 $y_T$를 후처리한다. Dense한 conditional random field (CRF)를 사용하여 마스크 경계를 개선한다. CRF를 구성할 때 마지막 단계의 mask proposal을 기반으로 unary potential이 계산된다. 마지막으로 argmax 연산을 텍스트 쿼리 차원에 따라 마스크 출력에 적용한다. 따라서 마스크의 각 공간적 위치에 대해 응답이 가장 높은 텍스트 쿼리(클래스)만 유지한다.
또한 선택적 후처리 모듈로 CRF 정제 마스크를 SAM과 앙상블한다. 먼저 SAM에 프롬프트를 입력하지 않고 자동 마스크 모드를 사용하여 일련의 mask proposal을 생성한다. 이러한 SAM proposal을 CRF에서 처리된 마스크와 일치시키기 위해 IoM (Intersection over the Minimum-mask)이라는 새로운 메트릭을 도입한다. SAM의 마스크와 CRF 정제 마스크 사이의 IoM이 threshold \(\phi_\textrm{iom}\)을 초과하면 일치하는 것으로 간주한다. 그런 다음 동일한 CRF 정제 마스크와 일치하는 모든 SAM proposal이 하나의 마스크로 결합된다. 마지막으로 결합된 마스크와 원래 CRF 정제 마스크 사이의 IoU를 계산한다. IoU가 threshold \(\phi_\textrm{iou}\)보다 크면 원래 마스크를 대체하기 위해 결합된 마스크를 채택하고, 그렇지 않으면 CRF로 정제된 마스크를 계속 사용한다.
Experiments
- 데이터셋: Pascal VOC, Pascal Context, COCO Object
- 구현 디테일
- mask proposal generator $f$: CLIP (ViTB/16)
- mask classifier $g$: CLIP (ViT-L/14)
- threshold
- Pascal VOC: $\eta = 0.4$, $\theta = 0.6$, $\lambda = 0.4$
- COCO: $\eta = 0.5$, $\theta = 0.3$, $\lambda = 0.5$
- Pascal context: $\eta = 0.6$, $\theta = 0.2$, $\lambda = 0.4$
- \(\phi_\textrm{iom} = 0.7\), \(\phi_\textrm{iou} = 0.7\)
- CLIP의 경우 half-precision floating point 사용
- GPU: NVIDIA V100 GPU 1개
1. Zero-shot Semantic Segmentation
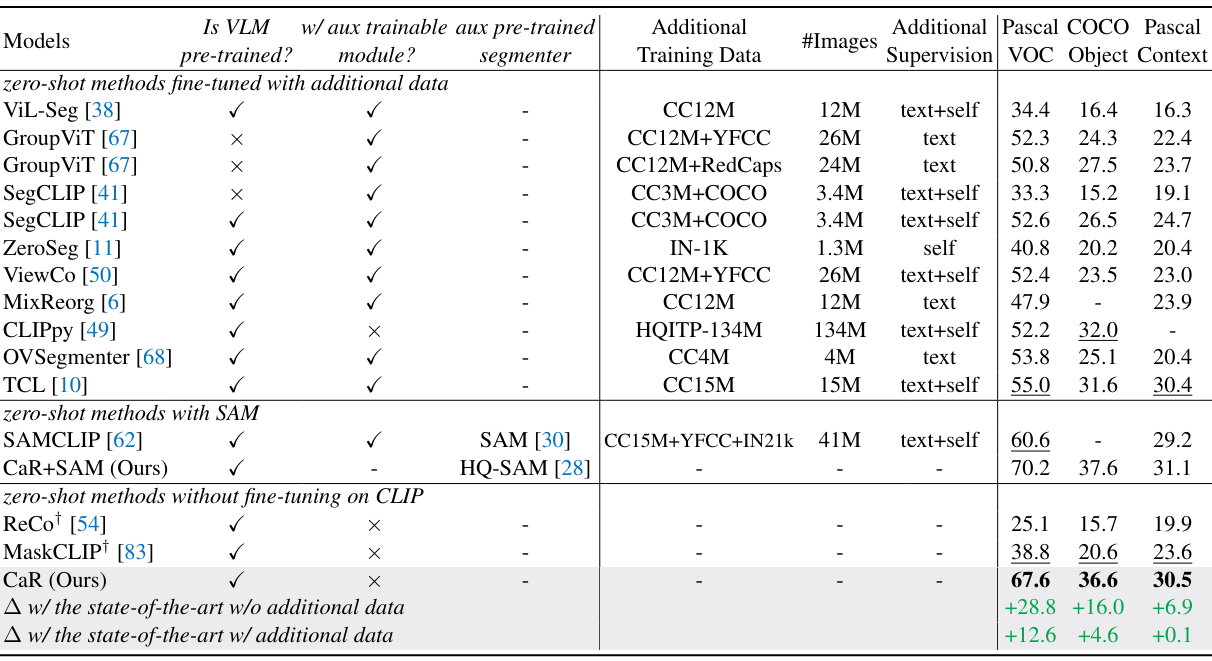
다음은 SOTA zero-shot semantic segmentation 방법들과 성능을 비교한 표이다.
2. Ablation Studies
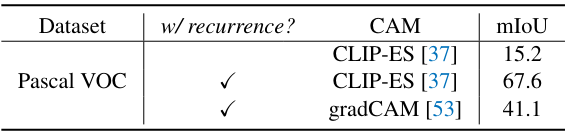
다음은 recurrent 아키텍처 적용과 CAM 방법들에 대한 효과를 비교한 표이다.
다음은 CLIP backbone에 대한 효과를 비교한 표이다.

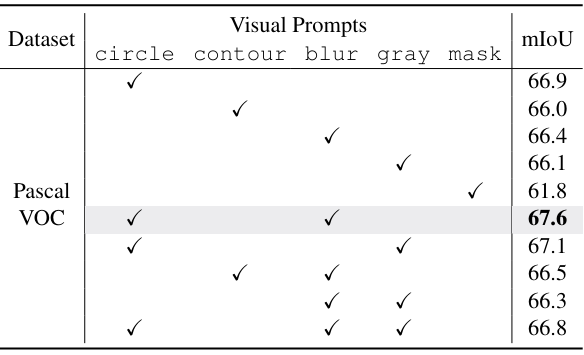
다음은 (왼쪽) 비주얼 프롬프트와 (오른쪽) 배경 쿼리에 대한 효과를 비교한 표이다. (Pascal VOC)

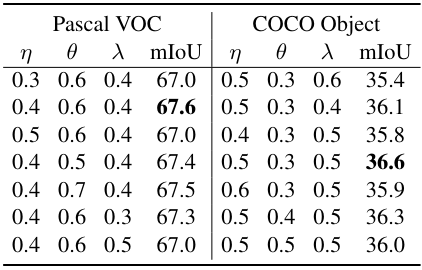
다음은 여러 hyperparameter들에 대한 효과를 비교한 표이다.
3. Referring Segmentation
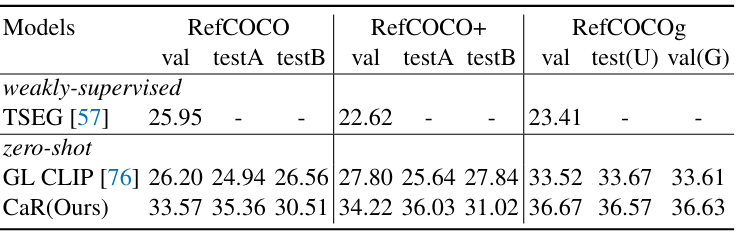
다음은 SOTA 방법들과 referring image segmentation 성능을 mIoU로 비교한 표이다.
다음은 Ref-DAVIS 2017에서의 결과이다. $\mathcal{J}$는 영역 유사도, $\mathcal{F}$는 윤곽 정확도, $\mathcal{J} \& \mathcal{F}$는 평균 점수이다.