[논문리뷰] CCL-LGS: Contrastive Codebook Learning for 3D Language Gaussian Splatting
ICCV 2025. [Paper] [Page]
Lei Tian, Xiaomin Li, Liqian Ma, Hao Yin, Zirui Zheng, Hefei Huang, Taiqing Li, Huchuan Lu, Xu Jia
Dalian University of Technology | ZMO AI Inc.
26 May 2025

Introduction
3D Gaussian Splatting (3DGS)의 등장으로 3D 색상 재현이 충실하게 구현되고 새로운 시점의 실시간 렌더링이 가능해졌다. 한편, CLIP, LSeg와 같은 VLM은 두 모달리티 간의 간극을 메워 추가적인 supervision 없이도 이미지에 대한 풍부하고 dense한 semantic map을 생성할 수 있게 되었다. 덕분에 멀티뷰 이미지와 해당 카메라 포즈에서 3D semantic 표현을 얻는 것을 목표로 하는 3D semantic 이해 분야가 빠르게 발전했다.
이 task는 semantic 모호성과 vocabulary 쿼리의 롱테일 분포와 같은 요소 때문에 특히 어렵다. 최근 방법들의 패러다임은 3D semantic 표현을 2D 뷰로 projection하여 렌더링된 결과를 사전 학습된 VLM에서 추출한 feature와 비교하는 것이다. 그러나 2D prior 기반 패러다임은 semantic supervision이 여러 뷰에서 일관성을 유지한다는 가정에 크게 의존한다. 실제로 가려짐, 모션 블러, 뷰에 따른 변화와 같은 요인은 동일한 물체의 2D semantic feature에 대해 여러 뷰에서 상당한 불일치를 초래할 수 있다.
최근 3D 기하학적 일관성을 활용하여 뷰 간 semantic 불일치를 부분적으로 해결하는 연구도 있었지만, 여전히 2D supervision에 의존하기 때문에 입력 feature의 상당한 불일치가 3D 공간으로 전파될 수 있다. 이로 인해 뷰 간 semantic 일관성을 유지하기 어렵고, 렌더링된 새로운 뷰에서 종종 아티팩트가 발생한다.
본 논문에서는 뷰 일관성 있는 3D semantic 재구성을 위한 새로운 프레임워크인 CCL-LGS를 제안하였다. 본 논문의 핵심은 특별히 설계된 3단계 파이프라인을 통해 뷰 일관성 있는 semantic supervision을 구축하여 3D Gaussian semantic field의 재구성을 가능하게 하는 것이다.
구체적으로, 먼저 SAM을 사용하여 정확한 인스턴스 마스크를 추출하고, zero-shot 추적을 통해 뷰 간 대응 관계를 정렬한 후, Contrastive Codebook Learning (CCL) 모듈을 통해 semantic을 추출한다. 제안된 CCL 모듈은 클래스 간 feature의 고유성을 유지하면서 클래스 내 feature의 밀집성을 강화하기 위해 contrastive learning을 도입하였다. 이 설계는 불완전하거나 노이즈가 있는 마스크로 인해 발생하는 semantic 모호성을 효과적으로 완화한다.
불완전한 마스크에 CLIP을 직접 적용하는 기존 방법들과 달리, 본 프레임워크는 시점 간 신뢰할 수 있는 semantic 대응 관계를 구축할 뿐만 아니라 카테고리별 고유성도 유지하여 더욱 robust하고 일관된 3D semantic 재구성을 가능하게 한다. 3D open-vocabulary 장면 이해에 대한 능숙성 덕분에, CCL-LGS는 다양한 다운스트림 애플리케이션에 도움이 될 수 있다.
Method
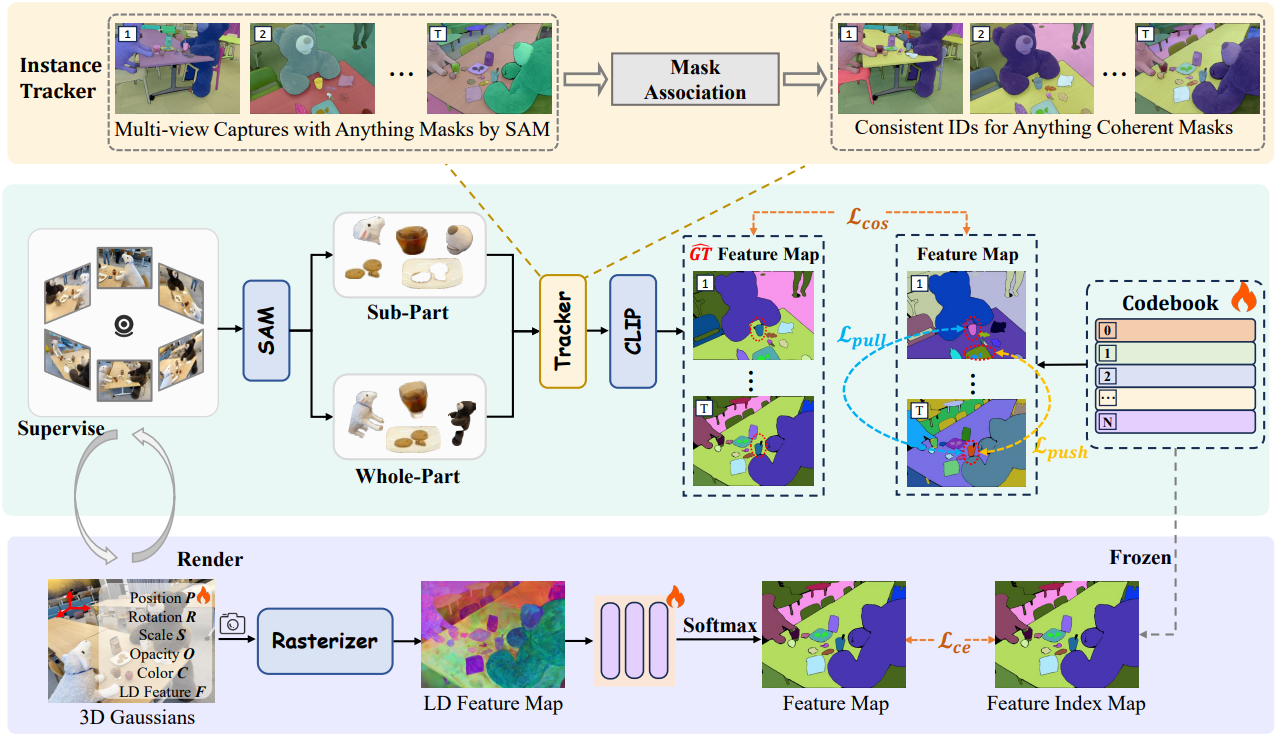
1. Two-Level Semantic Feature Extraction
본 방법에서는 SAM에 균일한 32$\times$32 포인트 프롬프트를 제공하여 subpart, part, whole의 semantic 스케일에 해당하는 세 가지 유형의 마스크를 생성한다. 서로 다른 포인트가 상충되는 스케일 할당을 생성할 수 있다는 점을 인지하고, subpart 마스크와 part 마스크를 병합한 마스크 집합 \(M_o^\textrm{sp}\)와, whole 마스크와 part 마스크를 병합한 마스크 집합 \(M_o^\textrm{wp}\)를 얻는다. 그런 다음, 예측된 IoU 점수, 안정성 지표, 그리고 중첩률을 기반으로 중복 마스크를 제거하는 필터링 절차를 적용한다. 최종 비중첩 마스크 $M_i$는 IoU 점수와 안정성 점수의 곱을 기반으로 선택된다. 모든 연산은 각 스케일에 독립적으로 적용된다. Segmentation map을 얻은 후, CLIP을 사용하여 픽셀 정렬된 언어 임베딩을 추출할 수 있다. 각 픽셀 $v$에 대해 semantic feature $F_i (v)$는 다음과 같이 표현될 수 있다.
\[\begin{equation} F_i (v) = \textrm{CLIP} (I_t \odot M_i (v)) \end{equation}\]($I_t$는 입력 이미지, $M_i (v)$는 픽셀 $v$가 해당되는 마스크 영역)
이 모듈의 설계는 계산 효율성과 멀티 스케일 semantic 정밀도 간의 균형을 맞추기 위한 필요성에 기반한다. 마스크 생성과 feature 추출을 하나의 프레임워크에 통합함으로써, 높은 semantic 정확도와 정밀한 경계 묘사를 보장하는 동시에 계산 오버헤드를 줄였다.
2. Contrastive Codebook Learning
최근 방법들은 고차원 feature 집합을 얻은 후, 일반적으로 오토인코더나 codebook을 사용하여 저차원 semantic feature를 얻는다. 이러한 저차원 feature는 3D Gaussian에 저장된 저차원 semantic 인코딩을 학습시키는 데 사용된다. 그러나 가려짐, 모션 블러, 뷰에 따른 변화로 인해 불완전한 마스크에 CLIP을 직접 적용하면 일관되지 않은 semantic feature가 생성되어 궁극적으로 3D semantic field의 품질에 영향을 미친다.
저자들은 불완전 마스크에서 추출한 feature를 직접 사용하는 것의 한계를 완화하기 위해 codebook 기반 contrastive learning 접근법을 도입하였다. 이 접근법은 두 가지 핵심 단계로 구성된다.
- IoU 매칭을 통한 마스크 연관
- Contrastive loss를 적용하여 feature 표현 개선
첫 번째 단계에서는 먼저 SAM2를 사용하여 첫 번째 프레임에서 모든 프레임으로 $K$개의 마스크를 전파한다. $t$번째 프레임의 경우, 전파된 $K$개의 마스크는 IoU를 사용하여 해당 프레임의 모든 마스크 $M_i$와 비교된다. 전파된 마스크와 마스크 $M_i$ 사이의 최대 IoU가 0.5를 초과하면 $M_i$는 일치하는 전파된 마스크의 카테고리에 할당된다. 그렇지 않으면 일치하지 않는 마스크를 나타내기 위해 -1이 할당된다. 따라서 각 마스크 $M_i$에는 레이블 $y_i \in {1, \ldots, K, -1}$$이 할당된다.
두 번째 단계에서는 codebook \(T = \{T_j\}_{j=1}^N\)이 구축되며, 각 프로토타입 $T_j \in \mathbb{R}^d$는 학습 과정에서 학습된다. $N$은 $K + 1$개의 마스크 카테고리와 독립적이다. 구체적으로, $N$은 장면별 feature 학습을 위한 고정 용량을 나타내며, $K$는 현재 장면 부분 집합에서 관찰된 카테고리의 수를 나타내며, 제한된 관측으로 인해 불완전할 수 있다. Codebook은 contrastive learning을 위한 feature space를 구성하는 latent feature 프로토타입 역할을 한다. 그런 다음 contrastive loss를 적용하여 동일한 카테고리의 feature들을 정렬하고 다른 카테고리의 feature들을 분리한다.
각 feature $F_i$에 대해 코사인 유사도를 기반으로 $T$에서 가장 유사한 프로토타입을 검색한다.
\[\begin{equation} j^\ast = \underset{j}{\arg \max} \; \textrm{cos} (F_i, T_j) \end{equation}\]$F_i$가 가장 가까운 프로토타입과 잘 일치하도록 하기 위해 matching loss를 다음과 같이 정의한다.
\[\begin{equation} L_\textrm{max} = 1 - \textrm{cos}(F_i, T_{j^\ast}) \end{equation}\]두 feature $F_i$와 $F_k$에 대해, 할당된 마스크 레이블 $y_i$와 $y_k$에 따라 contrastive loss가 적용된다. $y_i = y_k$이고 $y_i \ne −1$인 경우, codebook projection을 통해 연관된 descriptor를 더 가깝게 끌어당기기 위해 pull loss를 적용한다.
\[\begin{equation} L_\textrm{pull} = 1 - \textrm{cos} (T_{j_i}, T_{j_k}) \end{equation}\]$y_i \ne y_k$이고 $y_i, y_k \ne −1$인 경우, push loss를 적용하여 codebook 표현을 분리한다.
\[\begin{equation} L_\textrm{push} = \textrm{ReLU} (\textrm{cos}(T_{j_i}, T_{j_k}) - m) \end{equation}\]($m$은 미리 정의된 margin)
$y_i = −1$인 feature의 경우, pull loss나 push loss가 적용되지 않는다. 총 loss는 다음과 같다.
\[\begin{equation} L = L_\textrm{max} + \lambda_\textrm{pull} L_\textrm{pull} + \lambda_\textrm{push} L_\textrm{push} \end{equation}\]이 프레임워크 설계는 두 가지 장점을 가지고 있다.
- 오토인코더와 비교했을 때, feature space의 유사한 feature들은 암묵적으로 동일한 테이블 항목으로 제한되어 일관성 제약 조건이 더 강해진다.
- Contrastive loss를 통해 이 프레임워크는 동일한 마스크 카테고리에 해당하는 feature들은 잘 클러스터링되고, 다른 마스크 카테고리에 해당하는 feature들은 효과적으로 분리되도록 보장한다. 이를 통해 불완전 마스크의 semantic 일관성이 향상되고 semantic 간의 구분이 증가하여 더 나은 2D 표현이 된다.
3. 3D Gaussian Semantic Field
학습된 codebook \(T = \{T_j\}_{j=1}^N\)이 주어지면, 픽셀별 semantic feature를 discrete한 인덱스로 변환하고 이러한 인덱스를 3DGS의 출력에 맞춰 3D Gaussian semantic field를 구성한다.
구체적으로, 각 픽셀 $v$에 대해 semantic feature $F_i (v)$를 계산한 후, $j^\ast$를 $v$에 할당되어 인덱스 맵 $\mathcal{M} \in \mathbb{R}^{H \times W}$를 생성한다. 그런 다음, feature map $\hat{F} \in \mathbb{R}^{H \times W \times d_f}$는 rasterization과 알파 블렌딩을 통해 렌더링된다. 이 feature map은 MLP 디코더에서 처리된 후 softmax layer에서 처리되어 semantic feature 분포 $\hat{\mathcal{M}} \in \mathbb{R}^{H \times W \times N}$을 생성한다. 3D Gaussian의 semantic feature와 MLP 디코더를 함께 최적화하기 위해 cross-entropy loss를 최소화한다.
\[\begin{equation} \mathcal{L}_\textrm{CE} (\hat{\mathcal{M}}, \mathcal{M}) \end{equation}\]Inference 시에 각 픽셀은 프로토타입 \(T_{\hat{\mathcal{M}}(v)}\)를 검색하여 정제된 semantic feature $\tilde{F} (v)$를 형성한다. 텍스트 쿼리 $\tau$가 주어지면, VLM의 텍스트 인코더를 통해 임베딩 $\phi (\tau)$를 계산하여 relevance map을 계산한다.
\[\begin{equation} p (\tau \, \vert \, v) = \frac{\exp \left( \frac{\tilde{F}(v) \cdot \phi (\tau)}{\| \tilde{F}(v) \| \| \phi (\tau) \|} \right)}{\sum_{s \in \mathcal{T}} \exp \left( \frac{\tilde{F}(v) \cdot \phi (s)}{\| \tilde{F}(v) \| \| \phi (s) \|} \right)} \end{equation}\]\(p (\tau \, \vert \, v)\)를 thresholding하여 쿼리된 개념에 대한 semantic mask를 생성한다.
Experiments
- 구현 디테일
- \(\lambda_\textrm{pull} = \lambda_\textrm{push} = 0.25\), $m = 0.7$, $d_f = 8$
- iteration: 30,000
- optimizer: Adam (learning rate = 0.001, beta = (0.9, 0.999))
1. Experiments on LERF
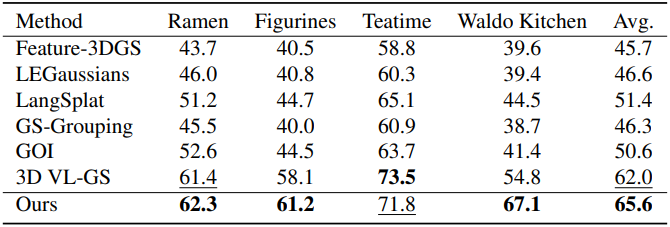
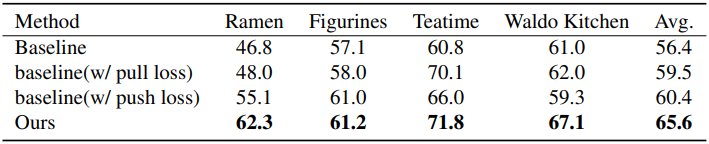
다음은 LERF 데이터셋에서의 비교 결과이다.
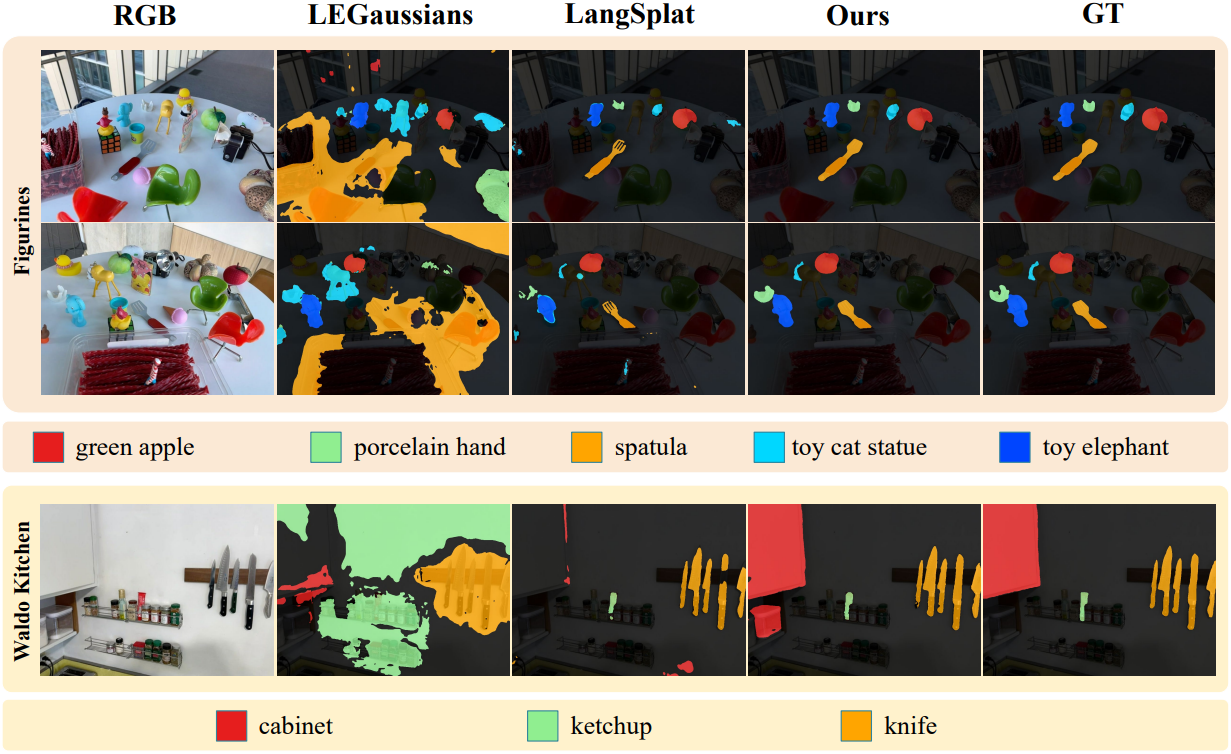
다음은 CCL 모듈 유무에 따른 2D feature map을 비교한 것이다.

다음은 pull loss와 push loss에 대한 ablation 결과이다.

2. Experiments on 3D-OVS
다음은 3D-OVS 데이터셋에서의 비교 결과이다.