[논문리뷰] Cavia: Camera-controllable Multi-view Video Diffusion with View-Integrated Attention
ICML 2025. [Paper] [Page]
Dejia Xu, Yifan Jiang, Chen Huang, Liangchen Song, Thorsten Gernoth, Liangliang Cao, Zhangyang Wang, Hao Tang
University of Texas at Austin | Apple | Google
14 Oct 2024
Introduction
최근 여러 연구에서 동영상 diffusion model에 카메라 제어 기능을 도입하여 생성된 프레임이 시점 명령을 준수하도록 하고, 이를 통해 3D 일관성을 향상시키려는 시도가 있었다. 이러한 연구들은 더 나은 컨디셔닝 신호를 사용하거나 기하학적 prior를 활용하여 시점 제어를 향상시켰다. 그러나 이러한 노력에도 불구하고, 생성된 동영상은 종종 정밀한 3D 일관성이 부족하거나 물체 움직임이 거의 없거나 전혀 없는 정적인 장면으로 제한되었다. 또한, monocular 동영상 생성 모델이 서로 다른 카메라 궤적에서 동일한 장면의 멀티뷰 일관성이 있는 동영상을 생성하는 것은 여전히 어려운 과제이다.
여러 시퀀스를 독립적으로 샘플링하면 장면이 상당히 일관되지 않은 경우가 많기 때문에 여러 동영상 시퀀스를 동시에 생성하는 것이 바람직하다. 그러나 야외 멀티뷰 동영상 데이터가 부족하여 멀티뷰 생성이 일관되지 않은 거의 정적인 장면이나 합성 물체로 제한되어 매우 어렵다. 최신 방법들은 제한된 데이터 소스로 인해 결과가 주로 고정된 시점에서의 물체 중심 프레임이며 사실적인 배경이 부족하다.
본 논문에서는 Stable Video Diffusion(SVD)을 확장하여 정밀한 카메라 제어를 통해 멀티뷰 일관성을 가진 동영상을 생성하는 새로운 프레임워크인 Cavia를 제안하였다. Spatial attention 모듈과 temporal attention 모듈을 각각 cross-view 3D attention과 cross-frame 3D attention으로 향상시켜 시점과 프레임 간 일관성을 개선하였다.
Cavia의 모델 아키텍처는 정적, monocular, 멀티뷰 동적 동영상을 완전히 활용하는 새로운 공동 학습 전략을 가능하게 한다. 정적 동영상은 생성된 프레임의 기하학적 일관성을 보장하기 위해 멀티뷰 형식으로 변환된다. 그런 다음, 동적 3D 물체의 렌더링된 합성 멀티뷰 동영상을 통합하여 모델이 합리적인 물체 동작을 생성하도록 학습시켰다. 합성 데이터에 대한 overfitting을 방지하기 위해, 포즈 주석이 있는 monocular 동영상에서 모델을 fine-tuning하여 복잡한 장면에서의 성능을 향상시켰다.
Cavia로 생성된 동영상은 기존 방법들에 비해 품질이 우수하다. 또한, inference 과정에서 4개의 시점을 생성하도록 extrapolation하고 생성된 프레임의 3D 재구성이 가능하다.
Method
1. Overview
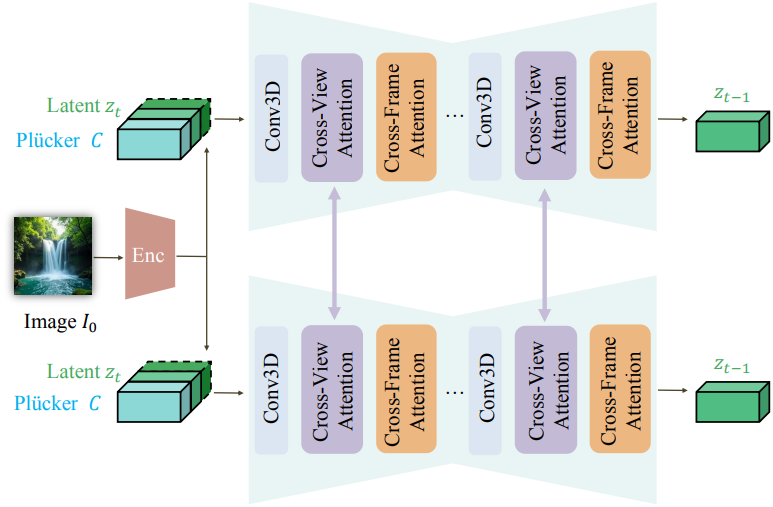
Image-to-video 생성은 단일 이미지 $I_0$를 입력으로 사용하여 동영상 시퀀스 $O_1, \cdots, O_n$을 출력한다. 카메라 제어를 도입하기 위해, 모델은 각 출력 시퀀스에 대하여 원하는 시점 변경을 결정하는 카메라 정보 $C_1, \cdots C_n$을 추가로 가져온다. 멀티뷰 시나리오에서 카메라 제어 신호와 출력 동영상 시퀀스의 각 batch를 $V$개의 시퀀스로 확장한다.
2. Camera Controllable Video Diffusion Model
Cavia는 사젼 학습된 SVD를 기반으로 한다. EDM의 continuous-time noise scheduler로 학습되었으며, EDM-preconditioning 프레임워크를 따른다.
카메라 컨디셔닝
SVD는 다양한 고품질 동영상과 이미지 데이터로 사전 학습되었지만 정확한 카메라 제어 명령을 직접 지원하지는 않는다. 이를 해결하기 위해, 다음과 같이 정의되는 Plücker 좌표를 통해 모델에 카메라 컨디셔닝을 도입했다.
\[\begin{equation} P = (d^\prime, o \times d^\prime), \quad \textrm{where} \; d^\prime = \frac{d}{\| d \|} \end{equation}\]($\times$는 외적)
카메라 extrinsic을 $E = [\textbf{R} \vert \textbf{T}]$, intrinsic을 $\textbf{K}$라고 하면 $(x, y)$에 위치한 2D 픽셀의 광선 방향 $d$는 다음과 같이 계산된다.
\[\begin{equation} d = \textbf{R} \textbf{K}^{-1} \begin{pmatrix} x & y & z & 1 \end{pmatrix} + \textbf{T} \end{equation}\]이러한 Plücker 좌표는 SVD의 원래 latent 입력과 channel-wise로 concat된다. 이에 따라 첫 번째 레이어의 convolution kernel을 확장한다. 새로 도입된 행렬은 학습 안정성을 보장하기 위해 0으로 초기화된다.
상대적인 카메라 좌표계를 사용하는데, 첫 번째 프레임은 단위 행렬을 사용하여 world coordinate의 원점에 위치한다. 이후 프레임들은 그에 따라 회전한다. 학습을 안정화하기 위해 멀티뷰 카메라 시퀀스에서 원점까지의 최대 거리를 1로 조정한다.
시간적 일관성을 위한 cross-frame attention
SVD backbone의 기본 1D temporal attention은 시점이 변경될 때 발생하는 큰 픽셀 이동을 모델링하기에 충분하지 않다. 기본 1D temporal attention에서 attention 행렬은 프레임 차원에 대해 계산되며, latent feature는 프레임 전체에서 동일한 공간적 위치에 있는 feature와만 상호 작용한다. 이는 서로 다른 시공간적 위치 간의 정보 흐름을 제한한다. 움직임이 제한적인 동영상 생성에서는 큰 문제가 아닐 수 있지만, 시점 변화는 일반적으로 상당한 픽셀 이동을 유발하므로, 더 효율적인 정보 전파를 위한 더 나은 아키텍처가 필요하다.
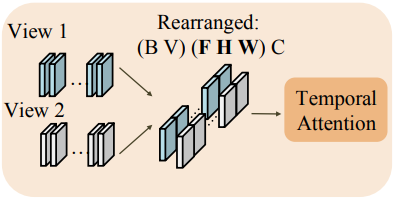
이 문제를 극복하기 위해 SVD 네트워크의 원래 1D temporal attention 모듈을 3D cross-frame temporal attention 모듈로 팽창시켜 시공간적 feature 일관성을 공동으로 모델링한다. 팽창 연산은 attention 행렬 계산 전에 latent feature를 재배열하여 얻을 수 있다. Shape이 $(B V F C H W)$인 latent feature를 고려하자 ($F$는 프레임 길이, $V$는 뷰 수). $((B V H W) F C)$으로 재배열 한 후 1D attention을 사용하는 대신, $((B V ) (F H W) C)$으로 재배열한 후 1D attention을 사용하여 공간적 feature를 attention 행렬에 통합한다.
재배열 연산은 feature 차원을 수정하지 않고 attention 입력의 시퀀스 길이만 변경하므로, SVD backbone에서 사전 학습된 가중치를 원활하게 상속받아 목적에 맞게 사용할 수 있다. 이 재배열 연산 덕분에, 팽창된 temporal attention은 이제 시공간적 feature의 유사도를 동시에 계산하여 더 큰 픽셀 이동을 수용하면서도 시간적 일관성을 유지한다.
3. Consistent Multi-view Video Diffusion Model
멀티뷰 생성의 경우, 독립적으로 샘플을 생성하는 monocular 동영상 diffusion model은 여러 시퀀스에 걸쳐 시점 일관성을 보장할 수 없다. 저자들은 monocular 동영상 diffusion model을 멀티뷰 생성 task로 확장하는 새로운 디자인 메커니즘과 학습 전략을 도입하였다.
멀티뷰 일관성을 위한 cross-view attention
멀티뷰 동영상에서 cross-view 일관성을 개선하기 위해 생성 프로세스 동안 정보 교환을 장려하는 것을 목표로 한다. Cross-frame attention 모듈이 이미 각 동영상 시퀀스 내에서 뷰 내의 feature 연결을 처리하므로 공간적 cross-view 모듈을 통해 뷰 간 신호를 교환하는 데 중점을 둔다.
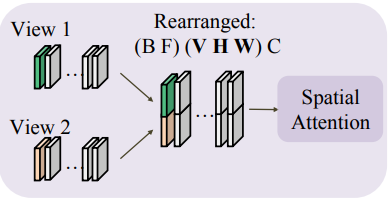
저자들은 MVDream에서 영감을 얻어 SVD의 spatial attention block에서 팽창된 3D cross-view attention 모듈을 도입하였다. 각 timestep의 프레임이 attention 모듈로 전송되기 전에 $V$개의 뷰가 concat되도록 latent feature를 재배열한다. 구체적으로, $(B V F C H W)$에서 $((B V F) (H W) C)$ 대신에 $((B F) (V H W) C)$로 재배열한다.
토큰 길이를 나타내는 마지막에서 두 번째 차원만 확장되고 다른 차원은 변경되지 않으므로, 팽창된 spatial attention은 monocular 설정에서 모델 가중치를 상속할 수 있다. 이러한 유연성 덕분에 모델은 다양한 뷰 개수를 가진 학습 데이터를 활용하고, inference 시 추가 뷰로 extrapolation할 수 있다.
저자들은 멀티뷰 생성을 처리하기 위해 입력 데이터에 뷰 차원을 추가하였다. 단순성을 유지하기 위해 다른 block을 처리하는 동안 뷰 차원을 batch 차원에 통합하여 다양한 뷰 개수를 처리하는 유연성을 확보하였다.
Joint Training Strategy on Curated Data Mixtures
모듈 가중치 상속을 가능하게 하는 뷰 통합 attention 메커니즘 덕분에, 본 논문의 프레임워크는 정적 동영상, 멀티뷰 동적 동영상, monocular 동영상 등 다양한 데이터 소스를 활용할 수 있다. 이는 기존 방법들에서는 달성하기 어려웠던 부분이다.
정적 동영상
정적 장면을 캡처하는 동영상의 경우, 모든 프레임이 시간적으로 동기화되어 있다고 가정한다. 원본 동영상에서 길이가 $(F−1) \times V + 1$인 임의의 부분 시퀀스를 공통된 시작 프레임과 뷰별로 $F$개의 프레임을 갖는 총 $V$개의 시퀀스로 재구성할 수 있다. 정적 장면은 프레임 순서 반전을 허용하여 추가적인 augmentation 가능성을 제공한다.
멀티뷰 동적 동영상
저자들은 Objaverse에서 애니메이션 가능한 물체를 렌더링하여 멀티뷰 동적 동영상을 준비하였다. 간단한 카메라 움직임에 대한 overfitting을 방지하기 위해 다양한 고도 및 방위각 변화를 갖는 부드러운 랜덤 궤적을 사용하였다. 이러한 궤적은 공통된 랜덤한 시작점에서 시작하여 총 $n \times v$개의 프레임을 생성한다.
Monocular 동영상
단순한 배경을 가진 합성 이미지에서 모델의 overfitting을 방지하기 위해, 저자들은 monocular로 촬영한 in-the-wild 동영상을 일부 사용하였다. 하지만, monocular 동영상에서 멀티뷰 카메라 제어를 학습하는 것은 매우 어렵다.
저자들은 이 문제를 극복하기 위해 모든 데이터 소스의 풍부한 물체 모션 정보를 효과적으로 활용하기 위해 monocular 동영상과 멀티뷰 동영상에서 모델을 공동으로 학습하였다. Monocular 동영상에 Particle-SfM을 사용하여 카메라 포즈를 얻고, 노이즈가 많거나 부자연스러운 콘텐츠가 포함되는 클립을 제거하기 위해 엄격한 필터링 파이프라인을 적용하였다.
이러한 큐레이팅된 동영상 클립은 풍부한 물체 모션과 복잡한 배경을 제공하여 장면 수준의 정적 데이터와 물체 수준의 동적 데이터 간의 차이를 완화한다. Monocular 동영상은 $V = 1$인 샘플로 재배열되며, 다양한 토큰 길이를 수용하는 attention 모듈 덕분에 이는 학습 프로세스에 영향을 미치지 않는다.
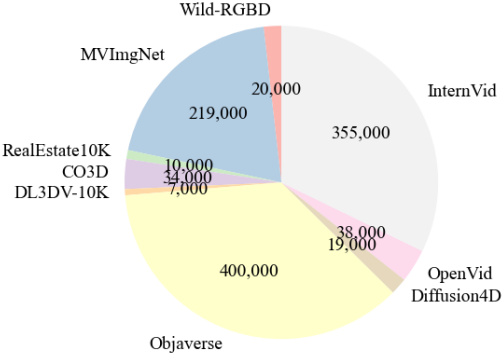
Experiments
1. Comparison
다음은 동영상별로 정성적으로 비교한 결과이다.

다음은 기하학적 일관성을 비교한 결과이다. (RealEstate10K test set)
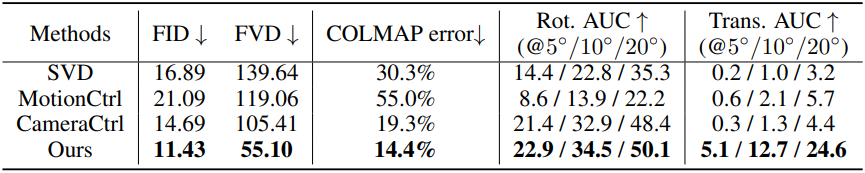
다음은 2-view 동영상 생성에 대한 비교 결과이다.

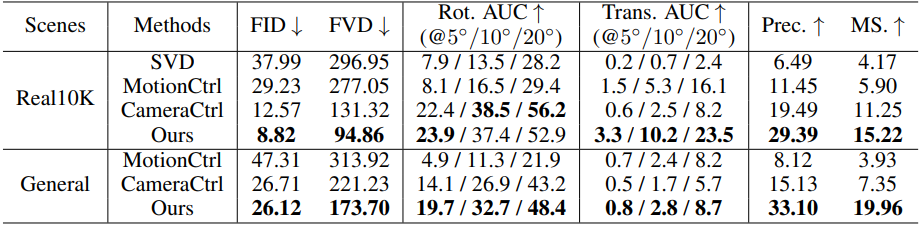
다음은 4-view 동영상 생성에 대한 비교 결과이다.

2. Ablation Study
다음은 Plücker 좌표와 cross-frame attention에 대한 ablation study 결과이다.

다음은 cross-view attention에 대한 ablation study 결과이다.

다음은 공동 학습 전략에 대한 ablation study 결과이다.
