[논문리뷰] From Slow Bidirectional to Fast Autoregressive Video Diffusion Models
CVPR 2025. [Paper] [Page]
Tianwei Yin, Qiang Zhang, Richard Zhang, William T. Freeman, Fredo Durand, Eli Shechtman, Xun Huang
MIT | Adobe
10 Dec 2024

Introduction
최신 동영상 diffusion model의 대부분은 일반적으로 모든 동영상 프레임에서 양방향 attention을 사용하는 diffusion transformer (DiT) 아키텍처에 의존한다. 양방향 attention으로 인해 하나의 프레임을 생성하려면 전체 동영상을 처리해야 한다. 이로 인해 대기 시간이 길어지며, 모델이 시간이 지남에 따라 변경되는 사용자 입력을 기반으로 프레임을 생성해야 하는 대화형 및 스트리밍 애플리케이션에 적용되지 못한다. 현재 프레임의 생성은 아직 사용할 수 없는 미래의 조건부 입력에 따라 달라진다. 또한 현재 동영상 diffusion model은 컴퓨팅 및 메모리 비용이 프레임 수의 제곱에 비례하여 증가하며, inference 중에 많은 수의 denoising step과 결합되어 긴 동영상을 생성하는 것이 엄청나게 느리고 비싸다.
Autoregressive video model은 모든 프레임을 동시에 생성하는 대신 프레임을 순차적으로 생성한다. 사용자는 전체 동영상이 완료될 때까지 기다리지 않고도 첫 번째 프레임이 생성되자마자 동영상을 시청할 수 있다. 이를 통해 대기 시간이 단축되고 동영상 길이에 대한 제한이 제거되며 대화형 제어가 가능해진다. 그러나 autoregressive model은 오차 누적에 취약하다. 생성된 각 프레임은 잠재적으로 결함이 있는 이전 프레임을 기반으로 하여 시간이 지남에 따라 오차가 확대되고 악화된다. 게다가 대기 시간이 단축되었지만 기존 autoregressive video model은 여전히 빠른 속도로 사실적인 동영상을 생성할 수 없다.
본 논문에서는 빠르고 상호작용적인 인과적 동영상 생성을 위해 설계된 CausVid를 소개한다. 저자들은 동영상 프레임 간의 인과적 종속성(causal dependency)을 가진 autoregressive DiT 아키텍처를 설계하였다. LLM과 유사하게, CausVid는 각 iteration에서 모든 입력 프레임의 supervision을 활용하고 KV caching을 통한 효율적인 autoregressive inference를 통해 효율적인 학습이 가능하다.
생성 속도를 더욱 개선하기 위해 원래 이미지 diffusion model용으로 설계된 few-step distillation 방법인 distribution matching distillation (DMD)를 동영상 데이터에 적용한다. Autoregressive diffusion model을 단순하게 few-step student로 distillation하는 대신, 양방향 attention을 사용하는 사전 학습된 teacher model의 지식을 causal attention을 사용하는 student model로 distillation하는 비대칭 distillation 전략을 제안하였다. 이 비대칭 distillation 방식은 autoregressive한 inference 중의 오차 누적을 크게 줄여 준다. 이를 통해 학습 중에 본 것보다 훨씬 긴 동영상을 autoregressive하게 생성할 수 있다.
CausVid는 SOTA 양방향 diffusion model과 동등한 동영상 품질을 달성하는 동시에 향상된 상호 작용성과 속도를 제공한다. 이는 품질 면에서 양방향 diffusion과 경쟁하는 최초의 autoregressive한 동영상 생성 방법이다. 또한 image-to-video, video-to-video, 동적 프롬프팅 등 다양한 task에 CausVid를 사용할 수 있으며, 모두 매우 낮은 대기 시간으로 달성할 수 있다.
Methods
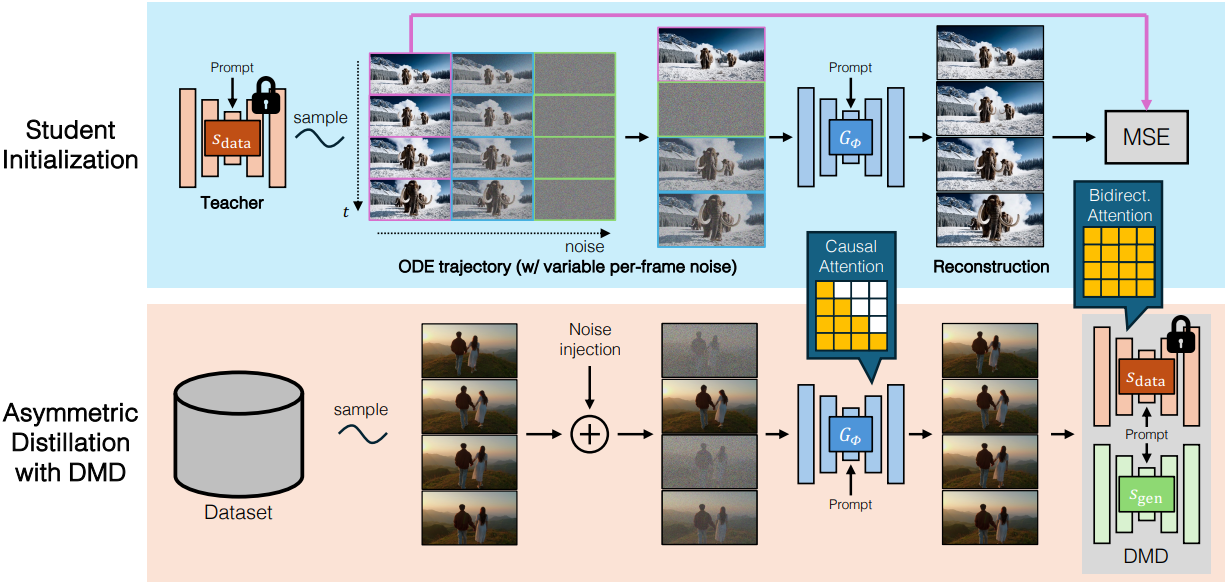
1. Causal Architecture
3D VAE를 사용하여 동영상을 latent space로 압축하는 것으로 시작한다. VAE 인코더는 동영상 프레임의 각 chunk를 독립적으로 처리하여 더 짧은 latent chunk로 압축한다. 그런 다음, 디코더는 각 latent chunk에서 원래 동영상 프레임을 재구성한다. 본 논문의 causal DiT는 이 latent space에서 작동하여 latent 프레임을 순차적으로 생성한다.
저자들은 autoregressive model과 diffusion model을 결합한 이전 작업에서 영감을 받은 block-wise causal attention 메커니즘을 설계하였다. 각 chunk 내에서 latent 프레임 간에 양방향 attention을 적용하여 로컬 시간 의존성을 포착하고 일관성을 유지한다. 인과성을 강제하기 위해 chunk 간에 causal attention을 적용한다. 이렇게 하면 현재 chunk의 프레임이 미래 chunk의 프레임에 attention되지 않는다. 이 디자인은 VAE 디코더가 픽셀을 생성하기 위해 여전히 최소한 한 블록의 latent 프레임이 필요하기 때문에 causal attention과 동일한 대기 시간을 유지한다. Attention mask $M$을 다음과 같이 정의한다.
\[\begin{equation} M_{i,j} = \begin{cases} 1, & \textrm{if} \; \left\lfloor \frac{j}{k} \right\rfloor \le \left\lfloor \frac{i}{k} \right\rfloor \\ 0, & \textrm{otherwise} \end{cases} \end{equation}\]($i$와 $j$는 프레임의 인덱스, $k$는 chunk 크기)
Diffusion model \(G_\phi\)는 autoregressive한 동영상 생성을 위해 DiT 아키텍처를 확장한다. Block-wise causal attention mask를 self-attention layer에 도입하여, 핵심 구조를 유지하면서도 사전 학습된 양방향 가중치를 활용하여 더 빠른 수렴을 가능하게 한다.
2. Bidirectional → Causal Generator Distillation
Few-step causal generator를 학습시키는 간단한 방법은 causal teacher model에서 distillation하는 것이다. 즉, 위에서 설명한 causal attention 메커니즘을 사전 학습된 양방향 DiT 모델을 적용하고, denoising loss를 사용하여 fine-tuning하는 것이다. 학습 과정에서, 모델은 $L$개의 chunk \(\{x_t^i\}_{i=1}^L\)로 나뉜 $N$개의 noise가 추가된 동영상 프레임 시퀀스를 입력으로 받는다. Diffusion Forcing에 따라, 각 chunk $x_t^i$에는 고유한 denoising step $t^i \sim [0, 999]$가 있다. Inference 시에 모델은 이전에 생성된 깨끗한 chunk를 조건으로 각 chunk의 noise를 순차적으로 제거한다.
이 fine-tuning된 causal teacher model을 distillation하는 것이 이론적으로는 유망해 보이지만, 이 단순한 접근 방식은 좋지 못한 결과를 낳는다. Causal diffusion model은 일반적으로 양방향 diffusion model보다 성능이 낮기 때문에, 약한 causal teacher model로부터 student model을 학습시키면 본질적으로 student model의 역량이 제한된다. 게다가 오차 누적과 같은 문제가 teacher model에서 student model로 전파된다.
저자들은 causal teacher model의 한계를 극복하기 위해, 비대칭 distillation 방법을 제안하였다. 즉, teacher model은 SOTA 동영상 모델과 같이 양방향 attention을 사용하고, student model은 causal attention으로 제한한다

3. Student Initialization
DMD loss를 사용하여 causal student model을 직접 학습시키는 것은 구조적 차이로 인해 불안정할 수 있다. 학습을 안정화하기 위해 효율적인 초기화 전략을 도입한다.
저자들은 다음과 같은 방법으로 양방향 teacher model에 의해 생성된 ODE 솔루션 쌍을 얻어 작은 데이터셋을 생성하였다.
- 표준 Gaussian 분포 $\mathcal{L}(0, I)$에서 noise 입력 \(\{x_T^i\}_{i=1}^L\)의 시퀀스를 샘플링한다.
- 사전 학습된 양방향 teacher model을 사용하여 ODE solver로 reverse process를 시뮬레이션하여 모든 timestep을 포함하는 ODE 궤적 \(\{x_t^i\}_{i=1}^L\)을 얻는다.
ODE 궤적에서 student generator에서 사용된 $t$ 값의 부분집합을 선택한다. 그런 다음 student model은 이 데이터셋에서 학습된다.
\[\begin{equation} \mathcal{L}_\textrm{init} = \mathbb{E}_{x, t^i} \| G_\phi (\{x_{t^i}^i\}_{i=1}^N, \{t^i\}_{i=1}^N) - \{x_0^i\}_{i=1}^N \|^2 \end{equation}\]여기서 few-step generator \(G_\phi\)는 teacher model에서 초기화된다. ODE 초기화는 계산적으로 효율적이며, 비교적 적은 수의 ODE 솔루션 쌍에 대한 적은 수의 학습 iteration만 필요하다.
4. Efficient Inference with KV Caching
Inference 시에는 효율적인 계산을 위해 KV caching을 사용한 autoregressive DiT를 사용하여 동영상 프레임을 순차적으로 생성한다. 주목할 점은 KV caching을 사용하기 때문에 inference 시간에 block-wise causal attention이 더 이상 필요하지 않다는 것이다. 이를 통해 빠른 양방향 attention 구현을 활용할 수 있다.

Experiments
- Teacher model
- 아키텍처: CogVideoX와 비슷한 양방향 DiT
- 3D VAE: 16개의 동영상 프레임을 latent 프레임 5개로 구성된 chunk로 인코딩
- 해상도가 640$\times$352이고 12 FPS인 10초 길이의 동영상으로 학습
- Student model
- 아키텍처: causal attention을 사용하는 것을 제외하고는 teacher model과 동일
- denoising step: 4개 (999, 748, 502, 247)
- 학습 디테일
- 64개의 H100 GPU에서 2일 동안 학습
- optimizer: AdamW
- 1단계: student 초기화
- iteration: 3,000
- learning rate: $5 \times 10^{-6}$
- 2단계: DMD
- iteration: 6,000
- learning rate: $2 \times 10^{-6}$
- guidance scale: 3.5
- DMD2의 two time-scale update rule을 적용 (ratio: 5)
1. Text to Video Generation
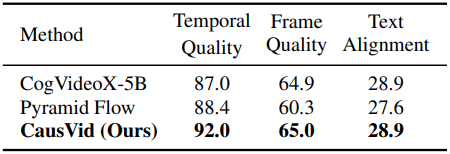
다음은 짧은 동영상 생성에 대한 평가 결과이다.
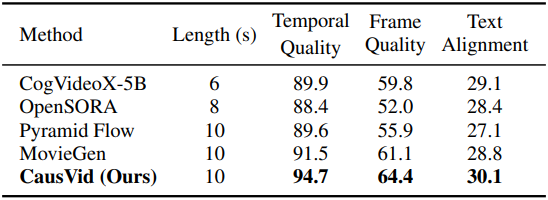
다음은 user study 결과이다.
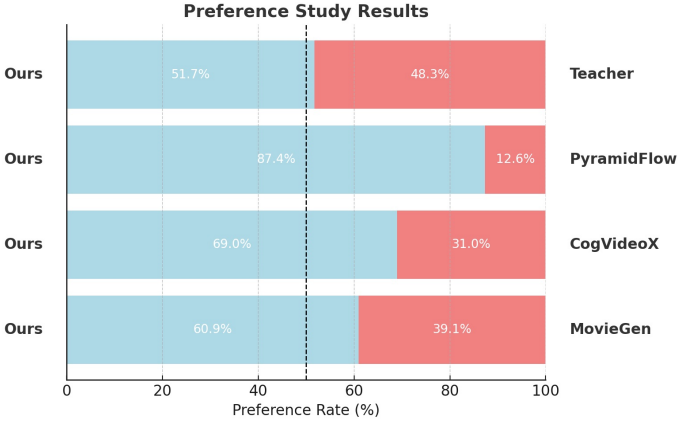
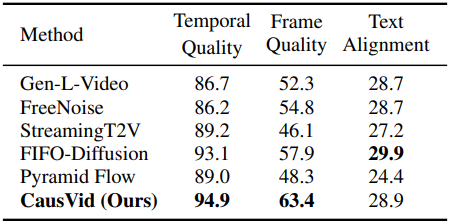
다음은 긴 동영상 생성에 대한 평가 결과이다.
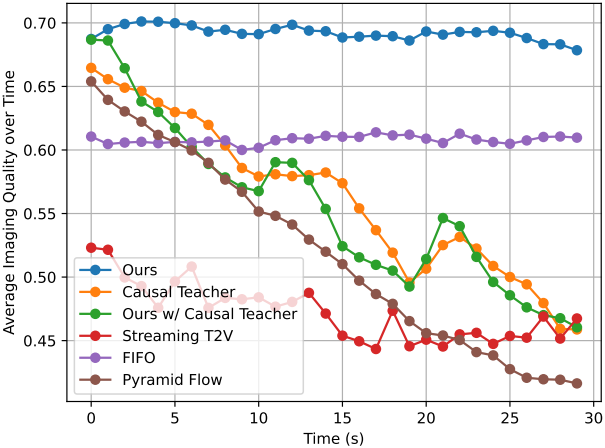
다음은 생성된 동영상의 30초 동안의 품질을 비교한 그래프이다.
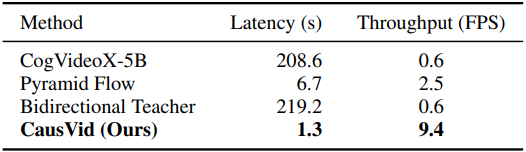
다음은 10초 길이의 640$\times$352 동영상 120프레임을 생성하는 데 소요되는 시간과 처리량을 비교한 표이다.
2. Ablation Studies
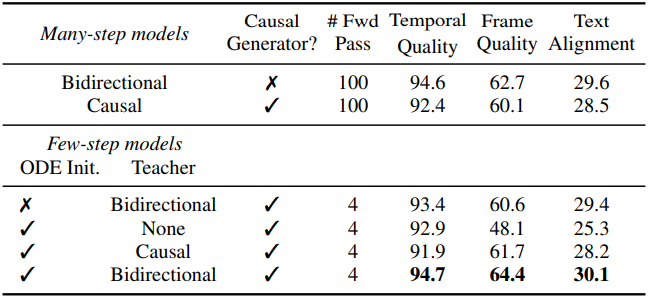
다음은 ablation study 결과이다.
3. Applications
다음은 다양한 동영상 생성 task에 대한 CausVid의 생성 결과들이다.

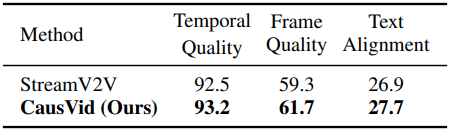
다음은 스트리밍 동영상 편집 성능을 비교한 표이다. 스트리밍 동영상은 무제한 길이의 프레임을 가질 수 있다.
다음은 image-to-video 생성 품질을 비교한 표이다. (CogVideoX는 6초 길이로 생성, 나머지는 10초)