[논문리뷰] CAT4D: Create Anything in 4D with Multi-View Video Diffusion Models
arXiv 2024. [Paper] [Page]
Rundi Wu, Ruiqi Gao, Ben Poole, Alex Trevithick, Changxi Zheng, Jonathan T. Barron, Aleksander Holynski
Google DeepMind | Columbia University | UC San Diego
27 Nov 2024

Introduction
정적인 3D 재구성의 경우 3D 장면의 멀티뷰에서 일관된 이미지가 대량으로 필요하다. 이는 신중한 캡처와 제한된 설정을 통해 달성할 수 있으며, 대부분 환경에서는 달성하기 어렵지만 충분한 시간과 연습으로 종종 실현 가능하다. 그러나 4D 콘텐츠를 재구성하려면 동기화된 멀티뷰 동영상이 필요하며 일반 사용자에게는 거의 불가능하다.
이러한 까다로운 캡처 요구 사항에 대한 의존도를 줄이기 위해 여러 방법이 학습된 3D generative prior를 활용하여 3D 재구성의 품질을 개선하는 데이터 기반 접근 방식으로 전환되었다. 이러한 방법의 성공의 핵심은 generative prior를 학습할 수 있는 고품질의 멀티뷰 이미지 데이터셋이다.
이러한 데이터는 정적인 환경에서는 대량으로 존재하지만 4D의 경우에는 그렇지 않다. 동기화된 멀티뷰 캡처 설정을 구축하는 복잡성으로 인해 사용 가능한 데이터의 양과 다양성이 모두 제한되고 따라서 데이터 기반의 4D prior를 구축하는 것은 상당히 어렵다. 대신, 다른 방법들은 기하학적 제약 조건, 추정된 depth map, optical flow field, 2D track을 통해 4D 재구성을 정규화하려고 시도했다. 그러나 이러한 모든 추가 신호가 있어도 새로운 시점에서 볼 때 여전히 눈에 띄는 아티팩트를 보여준다. 특히 입력이 대상 장면을 부분적으로만 관찰하는 경우 더욱 그렇다.
본 논문에서는 다양한 실제 및 합성 데이터 소스를 활용하여 4D 재구성을 가능하게 하는 generative prior를 학습하였다. 입력 동영상을 멀티뷰 동영상으로 변환할 수 있는 multi-view video diffusion model을 학습시킨 다음 이를 사용하여 동적인 3D 장면을 재구성한다.
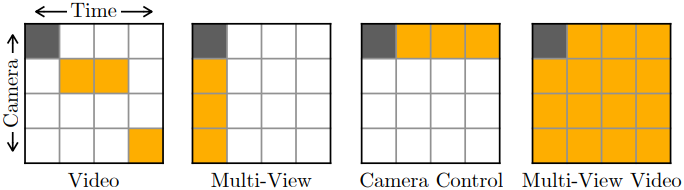
구체적으로, 모델은 다른 시점과 시간에 캡처한 아무리 많은 입력 이미지라도 허용하고 지정된 새로운 시점과 새로운 시간에서 장면의 모습을 출력한다. 동적 장면의 실제 멀티뷰 학습 데이터가 거의 없기 때문에 정적 장면의 멀티뷰 이미지, 역학을 포함하는 고정 시점 동영상, 합성 4D 데이터, 사전 학습된 동영상 모델과 멀티뷰 이미지 합성 모델로 보강된 추가 데이터 소스를 혼합하여 모델을 학습시킨다.
모델은 지정된 시점과 타임스탬프에서 일관된 프레임 컬렉션을 생성하도록 학습되었지만, 리소스 제약으로 인해 한 번에 16개의 프레임만 생성하도록 학습되었다. 고품질 4D 재구성에는 많은 새로운 시점에서 많은 프레임이 필요하므로 diffusion model의 기본 출력 길이를 넘어 일관된 멀티뷰 동영상의 무제한 컬렉션을 생성하기 위한 샘플링 전략을 추가로 제안하였다. 마지막으로, 생성된 멀티뷰 동영상을 사용하여 변형 가능한 3D Gaussian 표현을 최적화하여 동적인 3D 모델을 재구성한다.
Method
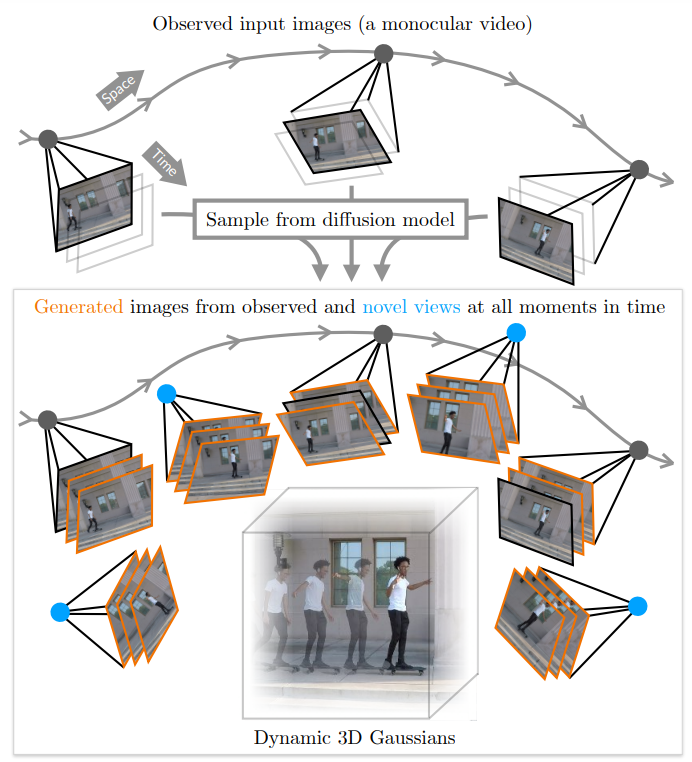
CAT4D는 입력 동영상에서 동적인 3D 장면을 만드는 2단계 접근 방식이다.
- Multi-view video diffusion model을 사용하여 입력 동영상을 멀티뷰 동영상으로 변환한다.
- 생성된 멀티뷰 동영상으로 변형 가능한 3D Gaussian 표현을 최적화하여 동적 3D 장면을 재구성한다.
1. Multi-view Video Diffusion Model
동적 3D 장면의 뷰 세트를 취하고 지정된 시점과 시간에 대상 프레임을 생성하는 diffusion model을 학습시킨다. 여기서 “뷰”는 (이미지, 카메라 파라미터, 시간)을 의미한다. 이미지 세트 $I^\textrm{cond}$, 카메라 파라미터 $P^\textrm{cond}$, 시간 $T^\textrm{cond}$를 갖는 $M$개의 입력 조건 뷰가 주어지면, 모델은 주어진 카메라 파라미터 $P^\textrm{tgt}$와 시간 $T^\textrm{tgt}$에 대한 $N$개의 타겟 이미지 $I^\textrm{tgt}$의 공동 분포를 학습한다.
\[\begin{equation} p (I^\textrm{tgt} \; \vert \; I^\textrm{cond}, P^\textrm{cond}, T^\textrm{cond}, P^\textrm{tgt}, T^\textrm{tgt}) \end{equation}\]모델은 CAT3D의 diffusion model을 기반으로 구축되었으며, 이 diffusion model은 모든 이미지의 latent를 연결하기 위해 3D self-attention을 적용하는 multi-view latent diffusion model이다. 저자들은 동일한 아키텍처를 채택하였으며, 추가로 다음과 같이 시간 조건을 모델에 주입하였다.
- 각 시간 조건 $t \in T^\textrm{cond} \cup T^\textrm{tgt}$에 sinusoidal positional embedding을 적용한다.
- 2-layer MLP를 입력하여 인코딩한다.
- 인코딩 결과를 diffusion timestep 임베딩에 더한다.
- 이 임베딩을 projection하여 U-Net의 각 residual block에 추가한다.
카메라와 시간에 대한 별도의 guidance를 위해, 학습 중에 $c_T = (T^\textrm{cond}, T^\textrm{tgt})$ 또는 $c_T$와 $c_I = (P^\textrm{cond}, I^\textrm{cond})$를 모두 무작위로 삭제한다. 각 경우에 대한 확률은 7.5%이다. 4DiM에서와 같이 classifer-free guidance를 사용하여 모델에서 샘플링한다.
\[\begin{aligned} &\epsilon_\theta (z^\textrm{tgt} (i), P^\textrm{tgt}, \varnothing, \varnothing) \\ +&\; s_I \cdot [\epsilon_\theta (z^\textrm{tgt} (i), P^\textrm{tgt}, c_I, \varnothing) - \epsilon_\theta (z^\textrm{tgt} (i), P^\textrm{tgt}, \varnothing, \varnothing)] \\ +&\; s_T \cdot [\epsilon_\theta (z^\textrm{tgt} (i), P^\textrm{tgt}, c_I, c_T) - \epsilon_\theta (z^\textrm{tgt} (i), P^\textrm{tgt}, c_I, \varnothing)] \end{aligned}\]($\epsilon_\theta$는 denoising network, $z^\textrm{tgt}(i)$는 diffusion timestep $i$에서의 모든 타겟 이미지의 latent, $s_I$와 $s_T$는 guidance scale)
직관적으로 $s_T$는 생성된 샘플의 시간 정렬을 강화하며, $s_I$는 시간 외의 다른 조건 정보와의 일관성을 장려한다.
CAT3D의 체크포인트로 모델을 초기화하고 $M = 3$개의 입력 뷰와 $N = 13$개의 타겟 뷰로 학습시킨다. 모든 실험에서 $s_I = 3.0$, $s_T = 4.5$이다.
2. Dataset Curation
$P^\textrm{tgt}$는 카메라 모션만 제어하고 $T^\textrm{tgt}$는 장면 모션만 제어하기 위해서는 이상적으로 여러 시점에서 동적 3D 장면을 캡처하는 대규모 멀티뷰 동영상 데이터셋이 필요하다. 그러나 이러한 종류의 데이터셋은 여러 동기화된 카메라에서 동영상 캡처를 수집하는 데 드는 비용으로 인해 아직 대규모로 존재하지 않는다. 에셋에서 이러한 데이터셋을 렌더링하는 것은 간단하지만 까다로운 실제 장면으로 일반화되는 모델을 학습하기에 충분히 다양하거나 현실적이지 않다.
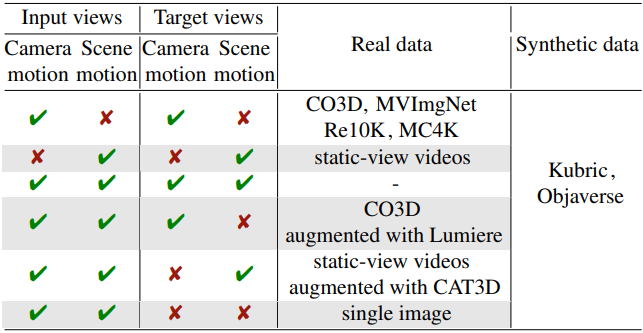
따라서 저자들은 카메라 모션과 장면 모션의 다양한 조합을 최대한 포괄하도록 학습을 위해 사용 가능한 데이터셋을 신중하게 큐레이팅하였다. 입력 및 타겟 뷰의 모션 특성에 따라 그룹화된 실제 및 합성 학습 데이터셋에 대한 개요는 위 표와 같다.
다행히도, 정적 장면의 멀티뷰 이미지와 정적 시점에서 촬영한 실제 동영상은 많이 있으며, 각각은 카메라 또는 시간이라는 제어 신호 중 하나에 해당한다. 따라서 합성 4D 데이터셋, 멀티뷰 이미지 데이터셋, 단안 동영상 데이터셋을 혼합하여 사용한다. 정적 시점의 동영상만 포함하도록 동영상 데이터셋을 필터링하여 모델이 시간 제어 $T^\textrm{tgt}$를 카메라 모션과 혼동하지 않도록 한다. 각 동영상의 네 모서리 패치가 시간에 따라 일정한지 확인하여 이 필터링을 수행한다.
입력 뷰에서 카메라와 장면이 모두 움직이지만 둘 중 하나는 타겟 뷰에서 고정되어 있는 실제 데이터는 존재하지 않는다. 이 문제를 해결하기 위해 data augmentation을 수행한다.
- CO3D 데이터셋에서 샘플을 가져와 동영상 생성 모델인 Lumiere가 카메라를 움직이지 않고 입력 프레임에 애니메이션을 적용하도록 한다.
- 필터링된 동영상 데이터셋에서 샘플을 가져와 CAT3D를 실행하여 입력 프레임의 새로운 뷰를 생성한다.
이런 식으로 증강된 이미지는 종종 완벽하지는 않지만, 모델이 카메라 제어와 시간 제어를 각각 학습하는 데 도움이 된다.
3. Sparse-View Bullet-Time 3D Reconstruction
본 논문의 모델의 한 가지 응용 분야는 동적인 장면 모션이 있는 경우에 대한 sparse-view 정적 3D 재구성이다. 동적 장면의 이미지가 몇 개만 주어지면, 하나의 입력 뷰의 시간에 해당하는 정적 3D 장면을 재구성하여 “bullet-time” 효과를 만들 수 있다.
이를 달성하기 위해 CAT3D와 유사한 2단계 접근 방식을 따른다. 먼저 앵커 샘플링 전략를 사용하는 diffusion model을 사용하여 특정 타겟 시간에 $K$개의 새로운 뷰를 생성한 다음, 해당 이미지에서 강력한 3D 재구성 파이프라인을 실행한다.
구체적으로, 먼저 모든 타겟 시간 $T^\textrm{tgt}$를 입력 $t \in T^\textrm{cond}$ 중 하나와 동일하게 지정하여 $N$개의 앵커 뷰를 생성한다. 그런 다음, 모든 $K$개의 타겟 뷰를 $N$개의 뷰 batch로 분할하고 가장 가까운 $M$개의 앵커 뷰를 조건으로 하여 각 batch를 생성한다. 마지막으로, LPIPS loss를 사용하는 3DGS 모델을 사용하여 3D 장면을 재구성한다.
4. Generating Consistent Multi-view Videos
4D 재구성을 가능하게 하기 위해 입력 동영상을 멀티뷰 동영상으로 변환한다. 입력 동영상에 충분한 카메라 움직임이 있는 경우 관찰된 카메라의 부분집합에서 멀티뷰 동영상을 생성하는 것을 목표로 한다.
카메라가 $P_{1:L}$인 $L$개 프레임 $I_{1:L}$의 입력 동영상이 주어지면 farthest point sampling을 통해 $K$개 카메라 시점 \(\{P_{k_i}\}_{i=1}^{K} \subseteq P_{1:L}\)을 선택한다. 목표는 이러한 $K$개 카메라에서 멀티뷰 동영상, 즉 $K \times L$ 이미지 그리드 \(G_{K,L}\)을 생성하는 것이다. 모델은 $N$개의 프레임만 생성하도록 학습되었지만 일반적으로 $KL \gg N$이다.
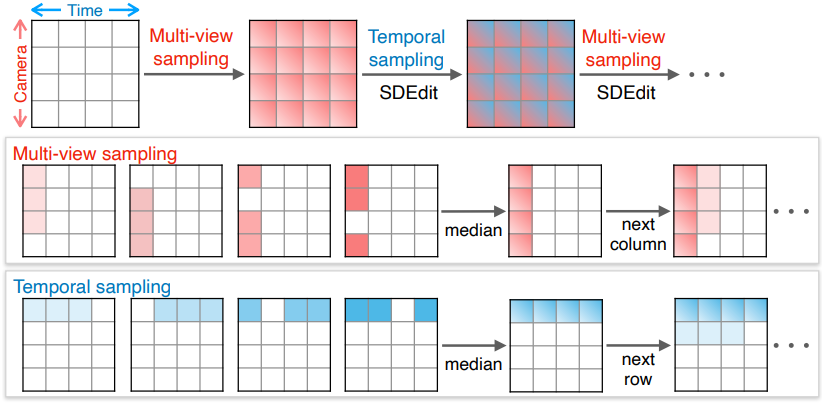
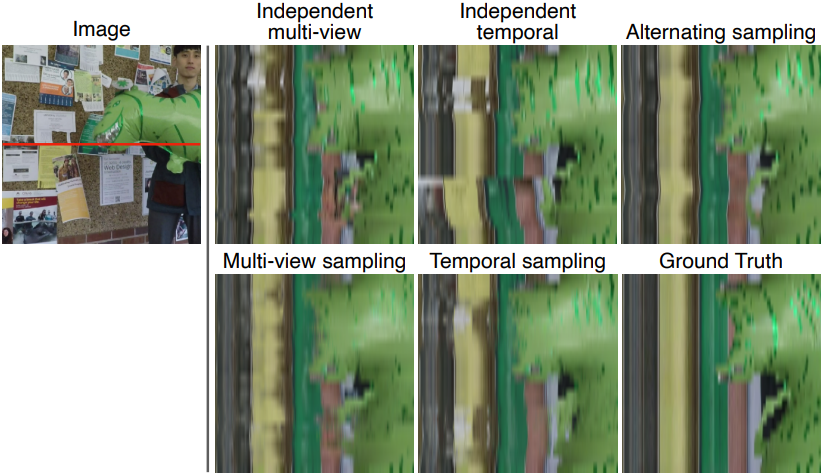
저자들은 이러한 이미지 그리드를 생성하기 위해 이미지 그리드의 각 열을 독립적으로 생성하는 멀티뷰 샘플링과 이미지 그리드의 각 행을 독립적으로 생성하는 시간적 샘플링을 교대로 수행하는 샘플링 전략을 설계하였다. 여기서 컨디셔닝 프레임 수 $M$이 타겟 프레임 수 $N+1$과 같은 제한된 설정을 사용한다. 더 많은 입력 프레임을 조절하기 위해 $M = 9$개의 뷰를 입력받고 $N = 8$개의 뷰를 출력하도록 학습된 모델의 fine-tuning된 버전을 사용한다.
멀티뷰 샘플링
각 시간 $t$에 대해, 먼저 크기 $N$의 각 sliding window를 생성한 다음, 결과의 픽셀별 중간값을 구하여 모든 $K$개의 카메라에서 이미지 \(G_{\cdot,t}\)를 생성한다. $j$번째 window의 생성은 타겟 카메라 \(\{I_c \; \vert \; c \in \{k_{i \textrm{ mod } K}\}_{i=j}^{j+N}\}\)의 $N$개의 입력 프레임과 타겟 시간 $I_t$의 1개의 입력 프레임으로 컨디셔닝된다. 여러 window의 픽셀별 중간값을 구하면 더 많은 조건 프레임에서 정보를 집계하고 분산을 줄이는 데에도 도움이 된다. 멀티뷰 샘플링의 결과는 멀티뷰에서는 일관되지만 시간적으로는 일관되지는 않는다.
시간적 샘플링
각 카메라 $P_{k_i}$에 대해, 멀티뷰 샘플링과 유사한 sliding window 접근 방식을 사용하여 모든 $L$개의 시간에 이미지 \(G_{i,\cdot}\)를 생성한다. $j$번째 window의 생성은 타겟 타임스탬프 \(\{I_{t \textrm{ mod } L}\}_{t=j}^{j+N}\)의 $N$개의 입력 프레임과 타겟 카메라 \(I_{k_i}\)의 1개의 입력 프레임으로 컨디셔닝된다. 시간적 샘플링의 결과는 시간적으로는 일관되지만 멀티뷰에서는 일관되지 않는다.
교대 샘플링
멀티뷰 및 시간적 일관성을 모두 달성하기 위해 SDEdit을 사용하여 멀티뷰 샘플링과 시간적 샘플링을 번갈아가며 사용한다. 다음과 같이 세 가지 샘플링 단계를 실행한다.
- 멀티뷰 샘플링: 랜덤 noise에서 시작, 25 DDIM step
- 시간적 샘플링: 이전 단계의 결과로 초기화하여 noise level 16/25에서 시작
- 멀티뷰 샘플링: 이전 단계의 결과로 초기화하여 noise level 8/25에서 시작
이러한 전략으로 생성된 멀티뷰 동영상은 충분히 일관성이 있어, 입력 동영상이 장면을 충분히 포괄하는 경우 정확한 4D 재구성이 가능하다.
정지 동영상
카메라 움직임이 거의 없거나 전혀 없는 입력 동영상의 경우, 4D 재구성을 충분히 제한하기 위해 새로운 시점에서 이미지를 생성해야 한다. 이를 위해 먼저 $t = 0$에서 $K$개의 새로운 뷰를 생성하고, 생성된 프레임을 입력 프레임 세트에 추가한 다음, 이전에 설명한 교대 샘플링 전략을 실행한다.
Dense view sampling
생성된 멀티뷰 동영상의 범위를 더욱 확장하기 위해, 각 시간마다 $K$개의 생성된 뷰를 조건으로 $K^\prime$개의 추가 뷰를 생성한다. 이 과정에서 앞서 설명한 nearest-anchoring 전략을 사용한다.
실험에서는 $K = 13$, $K^\prime = 128$로 설정되었다. MonST3R를 사용하여 포즈가 없는 입력 동영상에 대한 카메라 파라미터를 얻는다.
5. 4D Reconstruction
교대 샘플링 방법은 기존 4D 재구성 파이프라인에서 사용할 수 있을 만큼 충분히 일관된 멀티뷰 동영상을 생성한다. K-Planes로 parameterize된 deformation field에 의해 움직이는 일련의 3D Gaussian으로 동적 3D 장면을 나타내는 4DGS를 기반으로 한다.
Experiments
1. Separate Control over Camera and Time
다음은 카메라와 시간을 각각 제어한 결과를 비교한 것이다.

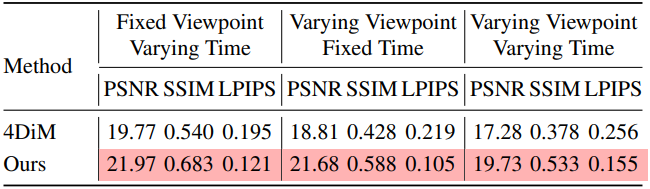
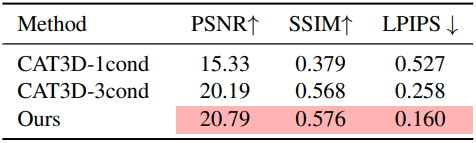
2. Sparse-View Bullet-Time 3D Reconstruction
다음은 sparse-view “bullet-time” 재구성에 대한 비교 결과이다.

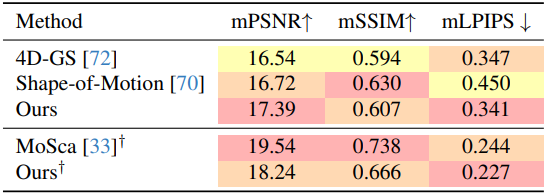
3. 4D Reconstruction
다음은 4D 재구성에 대하여 다른 방법들과 비교한 결과이다.

4. 4D Creation
다음은 생성된 콘텐츠에 대한 4D 재구성 결과이다.

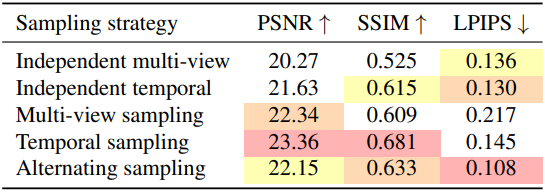
5. Ablation Study
다음은 샘플링 전략에 대한 비교 결과이다.
Limitations
- Diffusion model은 입력 프레임을 넘어서는 시간 외삽(extrapolation)에 어려움을 겪고, 특히 동적 물체가 가려지는 경우에 카메라 시점을 시간적 진행에서 완전히 분리할 수 없다.
- 생성된 4D 장면이 새로운 시점에서 그럴듯해 보이지만, 복구된 3D motion field는 물리적으로 정확하지 않을 수 있다.