[논문리뷰] CAT3D: Create Anything in 3D with Multi-View Diffusion Models
NeurIPS 2024 (Oral). [Paper] [Page]
Ruiqi Gao, Aleksander Holynski, Philipp Henzler, Arthur Brussee, Ricardo Martin-Brualla, Pratul Srinivasan, Jonathan T. Barron, Ben Poole
Google DeepMind | Google Research
16 May 2024

Introduction
본 논문에서는 관찰이 제한된 설정에서 기존 3D 재구성 방법의 사용을 제한하는 근본적인 문제, 즉 학습 뷰의 수가 부족하다는 점에 초점을 맞추었다. 다양한 입력 방식에 대한 각각의 솔루션을 고안하는 대신 단순히 더 많은 관찰을 만든다. 즉, 덜 제약되고 결정이 부족한 3D 생성 문제를 완전히 제약되고 완전히 관찰되는 3D 재구성 세팅으로 축소한다. 이런 식으로 재구성 문제를 생성 문제로 재구성한다.
입력 이미지가 아무리 많아도 3D 장면에 대한 일관된 새로운 관찰 결과를 모아 생성한다. 최근의 동영상 생성 모델은 그럴듯한 3D 구조가 있는 동영상 클립을 합성하는 능력을 보여주기 때문에 이 과제를 해결하는 데 유망한 것으로 보인다. 그러나 이러한 모델은 종종 샘플링하는 데 비용이 많이 들고 제어하기 어렵고 부드럽고 짧은 카메라 궤적으로 제한된다.
본 논문의 시스템인 CAT3D는 새로운 뷰 합성을 위해 특별히 학습된 multi-view diffusion model을 통해 이를 달성한다. 임의의 개수의 입력 뷰와 새로운 시점들이 주어지면 CAT3D는 효율적인 병렬 샘플링 전략을 통해 여러 개의 3D 일관된 이미지를 생성한다. 생성된 이미지는 이후 강력한 3D 재구성 파이프라인에 공급되어 모든 시점에서 실시간으로 렌더링할 수 있는 3D 표현을 생성한다.
CAT3D는 캡처되거나 합성된 입력 뷰의 수에 관계없이 임의의 물체 또는 장면의 사실적인 결과를 단 1분 만에 생성할 수 있다. CAT3D는 sparse한 멀티뷰 캡처, 단일 캡처 이미지, 심지어 텍스트 프롬프트에 이르기까지 다양한 입력 설정에서 작동하며, 이전 방법들보다 성능이 뛰어나며 훨씬 빠르다.
Method
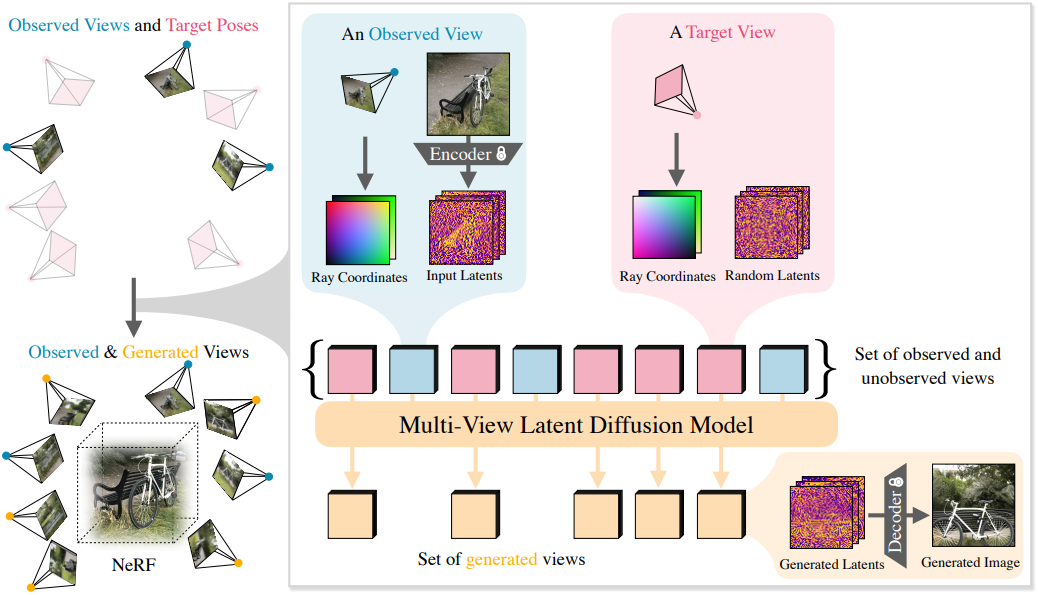
CAT3D는 3D 생성을 위한 2단계 접근 방식이다.
- Multi-view diffusion model을 사용하여 하나 이상의 입력 뷰와 일치하는 많은 수의 새로운 뷰를 생성한다.
- 생성된 뷰에서 강력한 3D 재구성 파이프라인을 실행한다.
1. Multi-View Diffusion Model
3D 장면의 하나 또는 여러 뷰를 입력으로 받고 카메라 포즈를 고려하여 여러 출력 이미지를 생성하는 multi-view diffusion model을 학습시킨다.
구체적으로, $M$개의 이미지 $\textbf{I}^\textrm{cond}$와 해당 카메라 파라미터 $\textbf{p}^\textrm{cond}$, $N$개의 타겟 카메라 파라미터 $\textbf{p}^\textrm{tgt}$가 주어지면, 모델은 $N$개의 타겟 이미지 $\textbf{I}^\textrm{tgt}$의 joint distribution을 캡처하는 법을 학습한다.
\[\begin{equation} p (\textbf{I}^\textrm{tgt} \vert \textbf{I}^\textrm{cond}, \textbf{p}^\textrm{cond}, \textbf{p}^\textrm{tgt}) \end{equation}\]모델 아키텍처
모델 아키텍처는 video latent diffusion model (LDM)과 유사하지만, 시간 임베딩 대신 각 이미지에 대한 카메라 포즈 임베딩을 사용한다. 조건부 및 대상 이미지 세트가 주어지면, 모델은 이미지 VAE를 통해 모든 개별 이미지를 latent 표현으로 인코딩한다. 그런 다음, diffusion model은 조건 신호가 주어진 latent 표현의 공동 분포를 추정하도록 학습된다.
모델은 text-to-image 생성을 위해 학습된 LDM으로 초기화되었으며, 이 LDM은 512$\times$512$\times$3의 입력 이미지 해상도와 64$\times$64$times$8 모양의 latent 이미지를 사용하여 웹 스케일의 이미지 데이터에서 학습되었다. 모델의 주요 backbone은 사전 학습된 2D diffusion model로 남아 있지만, 여러 입력 이미지의 latent를 연결하는 추가 레이어가 있다.
MVDream에서와 같이, 공간에서 2D, 이미지 전체에서 1D인 3D self-attention을 사용한다. 사전 학습된 모델의 파라미터를 상속하면서 latent를 3D self-attention layer와 연결하기 위해 원래 LDM의 모든 2D 잔여 블록 뒤에 기존 2D self-attention layer를 직접 팽창시켜 최소한의 추가 모델 파라미터를 도입한다. 3D self-attention layer를 통한 입력 뷰에 대한 컨디셔닝이 ReconFusion에서 사용된 PixelNeRF 및 CLIP 이미지 임베딩의 필요성을 제거한다. 빠른 학습과 샘플링을 위해 FlashAttention을 사용하고 LDM의 모든 가중치를 fine-tuning한다.
사전 학습된 이미지 diffusion model에서 더 높은 차원의 데이터를 캡처하는 multi-view diffusion model로 이동함에 따라 noise schedule을 높은 noise level로 전환하는 것이 중요하다. 구체적으로, 타겟 이미지의 개수인 $N$에 대해 $\log(N)$만큼 log-SNR을 이동한다. 학습을 위해 타겟 이미지의 latent는 noise가 더해지는 반면 조건부 이미지의 latent는 깨끗하게 유지되고, diffusion loss는 타겟 이미지에서만 정의된다.
채널 차원을 따라 latent에 바이너리 마스크를 concat하여 컨디셔닝 이미지와 타겟 이미지를 나타낸다. 여러 설정을 처리하기 위해 총 8개의 컨디셔닝 및 타겟 뷰($N + M = 8$)를 모델링할 수 있는 하나의 모델을 학습시키고 학습 중에 조건부 뷰의 개수 $N$을 1 또는 3으로 무작위로 선택한다 (각각 타겟 뷰 7개와 5개).
카메라 컨디셔닝
카메라 포즈를 컨디셔닝하기 위해, latent 표현과 같은 높이와 너비를 가진 카메라 광선 표현(raymap)을 사용하고 각 공간 위치에서 광선 원점과 방향을 인코딩한다. 광선은 첫 번째 조건 이미지의 카메라 포즈를 기준으로 계산되므로, 카메라 포즈 표현은 3D world 좌표의 rigid transformation에 invariant하다. 각 이미지의 raymap은 해당 이미지의 latent 이미지에 channel-wise로 concat된다.
2. Generating Novel Views
입력 뷰 집합이 주어지면, 장면을 완전히 커버하고 정확한 3D 재구성을 가능하게 하는 일관된 뷰 집합을 대량으로 생성하는 것이 목표이다. 이를 위해 샘플링할 카메라 포즈 집합을 결정해야 하며, 적은 수의 뷰에서 학습된 multi-view diffusion model을 사용하여 훨씬 더 큰 일관된 뷰 집합을 생성할 수 있는 샘플링 전략을 설계해야 한다.
카메라 궤적
궤도 경로의 카메라 궤적이 효과적일 수 있는 3D 물체 재구성과 비교했을 때, 3D 장면 재구성의 과제는 장면을 완전히 커버하는 데 필요한 뷰가 복잡할 수 있고 장면 콘텐츠에 따라 달라질 수 있다는 것이다. 저자들은 경험적으로 다양한 유형의 장면에 대해 합리적인 카메라 궤적을 설계하는 것이 매력적인 3D 재구성을 달성하는 데 중요하다는 것을 발견했다. 카메라 경로는 재구성 문제를 완전히 제한할 만큼 충분히 철저하고 조밀해야 하지만, 장면의 물체를 통과하거나 특이한 각도에서 장면 콘텐츠를 보지 않아야 한다.
저자들은 장면의 특성에 따라 네 가지 유형의 카메라 경로를 탐구하였다.
- 장면 중앙 주변으로의 다양한 scale과 높이의 궤도 경로
- 다양한 scale과 offset의 앞을 향한 원형 경로
- 다양한 offset의 스플라인 경로
- 원통형 경로를 따라 장면 안팎으로 이동하는 나선형 궤적
더 많은 합성 뷰들을 생성
Novel view synthesis (NVS)에 multi-view diffusion model을 적용하는 데 있어서의 과제는 총 8개에 불과한 작고 유한한 입력/출력 뷰 집합으로 학습된다는 것이다. 출력 뷰의 총 개수를 늘리기 위해 타겟 시점들을 더 작은 그룹으로 클러스터링하고 컨디셔닝 뷰에 따라 각 그룹을 독립적으로 생성한다. 가까운 카메라 위치를 가진 타겟 뷰들이 일반적으로 가장 종속적이기 때문에 이러한 뷰들을 그룹화한다.
단일 이미지 컨디셔닝의 경우 autoregressive 샘플링 전략을 채택하여 먼저 장면을 포함하는 7개의 앵커 뷰 집합을 생성한 다음 관찰된 뷰와 앵커 뷰가 주어지면 나머지 뷰 그룹을 병렬로 생성한다. 이를 통해 앵커 뷰 간의 장거리 일관성과 근처 뷰 간의 로컬 유사성을 모두 유지하면서도 효율적으로 대규모 합성 뷰 집합을 생성할 수 있다.
입력이 단일 이미지인 경우 80개의 뷰를 생성하고, 여러 이미지인 경우 480 ~ 960개의 뷰를 사용한다.
더 많은 입력 뷰와 정사각형이 아닌 이미지들을 컨디셔닝
컨디셔닝할 수 있는 뷰의 수를 늘리기 위해, 가장 가까운 $M$개의 뷰를 컨디셔닝 세트로 선택한다. 저자들은 이 방법이 multi-view diffusion 아키텍처의 시퀀스 길이를 단순히 늘리는 것보다 더 나은 성과를 거두는 것을 발견했다. 넓은 종횡비의 이미지를 처리하기 위해, 정사각형으로 자른 입력 뷰에서 나온 정사각형 샘플과, 정사각형으로 패딩된 입력 뷰에서 잘라낸 넓은 샘플을 결합한다.
3. Robust 3D reconstruction
Multi-view diffusion model은 서로 합리적으로 일관성이 있는 고품질의 합성 뷰 세트를 생성한다. 그러나 생성된 뷰는 일반적으로 완벽하게 3D 일관성이 없다. 3D 재구성 방법은 사진들을 입력으로 사용하도록 설계되었으므로 표준 NeRF 학습 절차를 수정하여 일관되지 않은 입력 뷰에 대한 robustness를 개선한다.
저자들은 Zip-NeRF를 기반으로 구축하였으며, photometric reconstruction loss, distortion loss, interlevel loss, 정규화된 L2 가중치 regularizer의 합계를 최소화하는 학습 절차를 사용한다. 또한 렌더링된 이미지와 입력 이미지 간의 LPIPS를 포함한다.
Reconstruction loss와 비교하여 LPIPS는 렌더링된 이미지와 관찰된 이미지 간의 높은 수준의 semantic 유사성을 강조하는 반면, 낮은 수준의 고주파 디테일의 잠재적 불일치를 무시한다. 관찰된 뷰에 더 가까운 생성된 뷰는 불확실성이 적고 따라서 더 일관성이 있으므로 가장 가까운 관찰된 뷰까지의 거리를 기준으로 생성된 뷰의 loss에 가중치를 둔다. 이 가중치는 학습 시작 시 균일하며 관찰된 뷰 중 하나에 더 가까운 뷰의 reconstruction loss에 더 강하게 페널티를 부여하는 가중치 함수로 점진적으로 어닐링된다.
Experiments
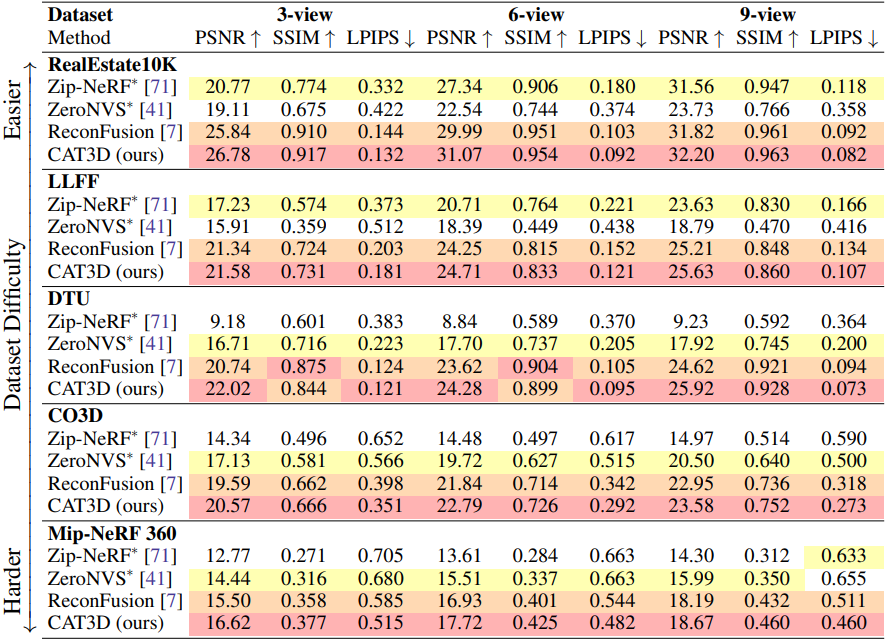
1. Few-View 3D Reconstruction
적은 수의 뷰에서 장면을 재구성한 결과를 비교한 것이다.

2. Single image to 3D
다음은 image-to-3D에 대한 비교 결과이다.