[논문리뷰] Caption Anything: Interactive Image Description with Diverse Multimodal Controls
arXiv 2023. [Paper] [Github]
Teng Wang, Jinrui Zhang, Junjie Fei, Hao Zheng, Yunlong Tang, Zhe Li, Mingqi Gao, Shanshan Zhao
SUSTech VIP Lab
4 May 2023

Introduction
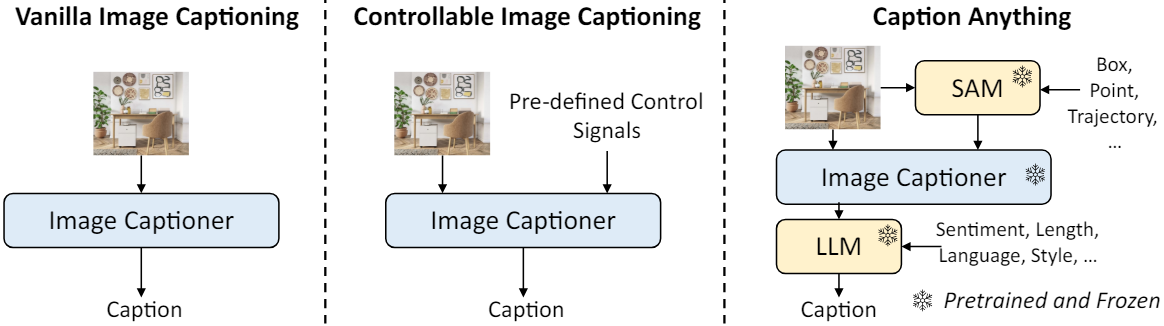
Controllable Image Captioning (CIC)는 언어 출력을 사용자 의도에 맞추는 유망한 연구 방향이다. 다양한 제어 신호를 이미지 캡션 모델에 통합하기 위한 방법들이 제안되었지만 두 가지 주요 요인에 의해 적용 가능성이 제한되었다.
- 기존 CIC 모델은 일반적으로 사람이 주석을 추가한(이미지, 텍스트, 제어 신호) 튜플을 사용한 학습에 의존한다. 데이터셋의 제한된 규모로 인해 모델의 제어 신호를 이해하는 능력이 제한된다.
- 모델은 사전 정의된 단일 또는 여러 제어 신호만 지원하므로 다양한 제어를 결합하고 새로운 차원의 제어 가능성을 도입하는 유연성이 제한된다.
이러한 문제를 해결하기 위해 본 논문은 사전 학습된 foundation model로 강화된 zero-shot CIC 프레임워크인 Caption AnyThing (CAT)을 제안하였다. 특히 CAT는 사전 학습된 이미지 captioner를 SAM, instruction tuning된 LLM과 통합한다. 이미지와 visual control은 먼저 SAM에 의해 처리된다. SAM은 선택한 영역에 해당하는 픽셀 레벨의 마스크를 생성하여 사용자가 관심 있는 object를 중심으로 한 인식을 용이하게 한다. CAT은 SAM에 사용되는 다양한 비주얼 프롬프트(ex. 점, bounding box)를 지원한다. 출력 문장은 GPT-4나 FLAN-T5와 같은 LLM을 통해 더욱 구체화된다. LLM은 사람의 피드백에 맞춰 튜닝되므로 CAT이 다양한 language control을 수용하고 사용자 의도에 더욱 효과적으로 맞출 수 있다.
기존의 CIC 방법과 달리 CAT는 foundation model을 활용하여 제어 가능성을 설정한다. 이 접근 방식은 사람이 주석을 추가한 데이터에 대한 의존도를 줄여 학습이 필요 없는 모델을 만들 뿐만 아니라 방대한 사전 학습 데이터에 내장된 지식을 활용하여 모델의 transferability를 향상시킨다. 또한 CAT는 다양한 범위의 제어 신호를 지원하므로 적응성과 확장성이 뛰어나다. CAT는 3가지 visual control (클릭, 박스, 궤적)과 4가지 language control (감정, 길이, 언어, 사실성)을 지원하며 이를 유연하게 결합해 다양하고 개인화된 캡션을 생성할 수 있다. 또한 두 가지 유형의 제어 모두에 대한 통합 표현을 제공한다. Visual control과 language control은 각각 픽셀 레벨 마스크와 텍스트 프롬프트로 통합된다. 이를 통해 CAT는 이러한 통합 표현으로 변환될 수 있는 모든 제어 신호로 쉽게 확장될 수 있으므로 유연성과 확장성이 향상된다.
CAT는 다양한 visual control을 통해 관심 있는 object를 선택하여 선호하는 스타일로 캡션을 생성할 수 있다. 또한 추가 OCR 및 VQA 도구를 통합함으로써 object 중심 채팅과 이미지 단락 캡션이라는 두 가지 멀티모달 애플리케이션으로 쉽게 확장될 수 있다. 전자는 사용자가 특정 object에 대해 채팅할 수 있게 하여 관심 있는 object에 대한 더 깊은 이해를 촉진한다. 후자는 별개의 foundation model에서 비롯된 다양한 영역의 지식을 효과적으로 통합하여 상세하고 논리적으로 일관된 설명을 생성할 수 있다.
Method
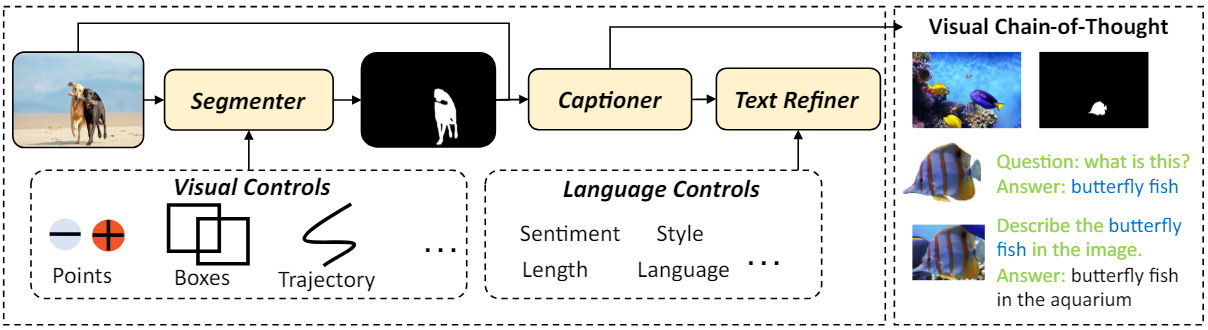
현재 이미지 캡션 시스템의 사용자 중심 상호 작용을 향상시키기 위해 다양한 멀티모달 제어 신호를 사용하여 이미지 captioner를 수용할 수 있는 foundation model 확대 전략을 사용한다. CAT는 segmenter, captioner, text refiner로 구성되어 있다. 위 그림에서 볼 수 있듯이 segmenter는 먼저 대화형 visual control (ex. 점, 상자, 궤적)을 사용하고 픽셀 레벨 마스크를 통해 사용자 관심 영역을 나타낸다. 이후, captioner는 원본 이미지와 제공된 마스크를 기반으로 특정 영역과 관련된 설명을 생성한다. 저자들은 captioner가 사용자가 관심 있는 object에 집중할 수 있도록 하기 위해 단계별 inference를 통한 visual chain-of-thought을 설계했다. 마지막으로, text refiner는 사용자 정의 language control을 통합하여 설명을 구체화하고 이를 통해 사용자 기본 설정에 따라 언어 스타일을 조정한다.
Segmenter
이상적인 segmenter는 visual control에 따라 이미지의 모든 부분을 분할할 수 있어야 한다. SAM은 이 요구 사항을 잘 충족하며 새로운 이미지 도메인으로의 인상적인 zero-shot transferability를 갖추고 있다. SAM은 interactive segmentation을 적용하여 프롬프트 및 상호 작용(ex. 점, 상자)을 사용하여 SAM이 유효한 segmentation mask를 생성하도록 유도한다. 사용자가 지정한 segmentation mask를 얻으면 원본 이미지와 마스크 프롬프트에 따라 원하는 캡션을 쉽게 생성할 수 있다.
Captioner
Captioner는 강력한 zero-shot 캡션 능력을 가져야 한다. 즉, 이상적인 captioner는 다양한 새로운 object와 다양한 이미지 분포 사이에서 합리적인 설명을 생성해야 한다. 저자들은 BLIP2를 captioner로 사용하였다. 고정된 사전 학습된 이미지 인코더와 고정된 LLM을 querying transformer와 함께 활용한다.
Text Refiner
대부분의 경우 이미지 관련 설명은 사용자의 선호도를 따라야 한다. 그러나 사용자 명령에 따라 captioner가 생성한 캡션을 수정하는 것은 간단하지 않다. 이를 달성하기 위해 ChatGPT를 API로 도입하여 captioner가 생성한 캡션에서 보다 표현력 있고 제어 가능한 설명을 생성한다. Text refiner는 LLaMA, OPT-IML, BLOOM과 같은 오픈 소스 LLM으로 쉽게 대체될 수 있다.
Visual Chain-of-Thought
저자들은 생성된 캡션이 배경 정보에 의해 쉽게 영향을 받는다는 것을 경험적으로 발견했다. NLP의 chain-of-thought (CoT) prompting에서 영감을 받아 생성된 설명이 사용자가 선택한 영역에 초점을 맞추도록 단계별 텍스트 생성으로 captioner를 부트스트랩한다. 먼저 사용자가 선택한 object를 유지하고 배경을 흰색으로 대체한 다음 captioner에게 관심 있는 object의 카테고리를 식별하도록 요청한다. 그 후, captioner는 생성된 텍스트와 배경이 있는 이미지를 최종 캡션을 생성하기 위한 프롬프트로 사용한다. 이러한 방식으로 captioner는 캡션 생성 과정에서 선택한 object에 집중할 수 있다.
Object-Centric Chatting
저자들은 비주얼 프롬프트로 식별된 object를 대상으로 하는 시각적 대화의 잠재력을 조사하였다. 전체 이미지를 전체적으로 이해하도록 설계된 채팅 시스템과 달리 로컬 영역 채팅은 복잡하고 정보가 풍부한 고해상도 이미지에 대해 더 폭넓게 적용된다. Object 및 사용자 쿼리의 segmentation mask가 주어지면 ChatGPT가 질문을 통해 자세한 시각적 단서를 이해할 수 있도록 지원하는 visual API로 VQA 모델 (Blip-2)을 사용한다. 특히 생성된 캡션을 초기 프롬프트에 포함하고 LangChain을 제어 허브로 사용하여 API 호출 체인을 예측한다.
Paragraph Captioning
CAT는 ChatGPT를 활용하여 이미지의 dense한 캡션과 장면 텍스트를 단락으로 요약함으로써 image paragraph captioning task에 적응할 수 있다. 구체적으로, 처음에 SAM을 사용하여 이미지 내의 모든 것을 분할한 다음 CAT을 사용하여 각 object에 캡션을 추가하여 dense한 캡션을 생성한다. 장면 텍스트 정보를 단락에 통합하기 위해 추가 OCR 도구(ex. EasyOCR)를 활용하여 이미지에 있는 텍스트를 식별한다. Dense한 캡션과 장면 텍스트는 사전 정의된 프롬프트 템플릿으로 병합된 후 장면 정보를 응집력 있는 단락으로 요약하도록 ChatGPT에 지시하는 데 사용된다.
Experiments
Visual Controls
다음은 점을 visual control로 하여 생성된 캡션들을 시각화한 것이다.

다음은 궤적과 박스를 visual control로 하여 생성된 캡션들을 시각화한 것이다.

Language Controls
다음은 language control로 생성된 캡션들을 시각화한 것이다. (위: 언어, 아래: 감정 & 사실성)

Object-Centric Chatting
다음은 object-centric chatting의 예시이다.

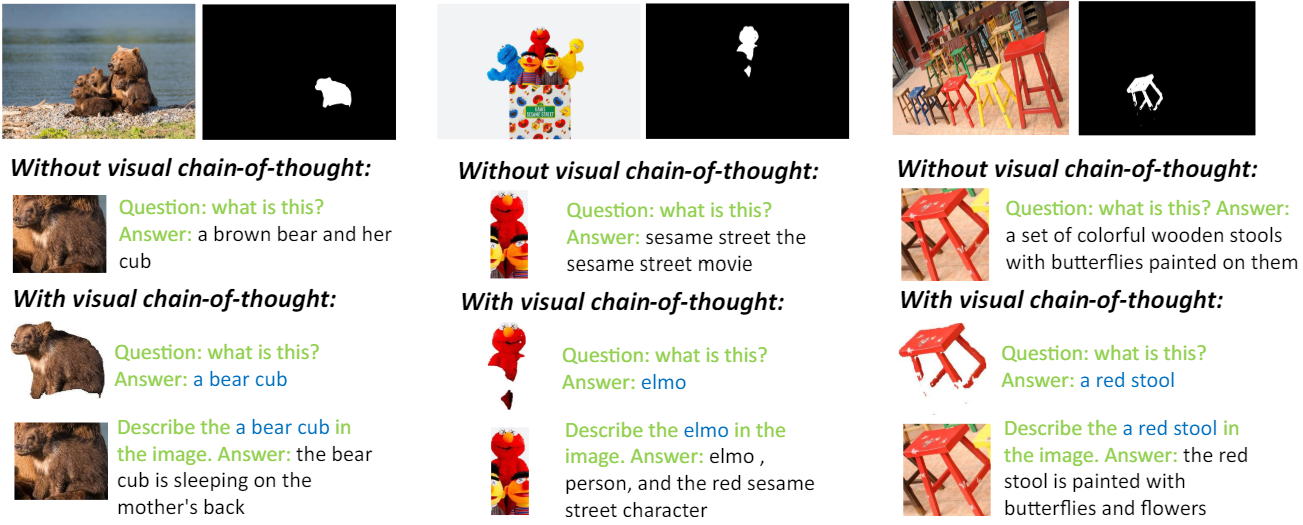
Visual Chain-of-Thought
다음은 visual chain-of-thought의 예시이다.
Caption Everything in a Paragraph
다음은 image paragraph captioning의 예시이다.
