[논문리뷰] Feed-Forward Bullet-Time Reconstruction of Dynamic Scenes from Monocular Videos
arXiv 2024. [Paper] [Page]
Hanxue Liang, Jiawei Ren, Ashkan Mirzaei, Antonio Torralba, Ziwei Liu, Igor Gilitschenski, Sanja Fidler, Cengiz Oztireli, Huan Ling, Zan Gojcic, Jiahui Huang
NVIDIA | University of Cambridge | Nanyang Technological University | University of Toronto | MIT | Vector Institute
4 Dec 2024

Introduction
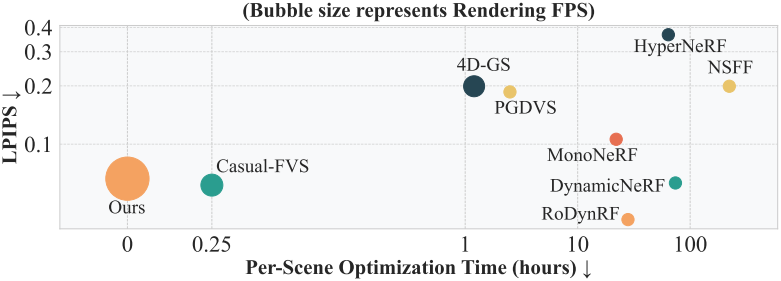
정적 장면 재구성을 위한 현재의 방법은 크게 최적화 기반과 학습 기반 접근 방식의 두 가지 카테고리로 나눌 수 있다. 그러나 이 두 가지를 모두 동적 장면으로 확장하는 것은 간단하지 않다. 장면 역학의 모호성을 줄이기 위해 많은 최적화 기반 방법은 깊이나 optical flow와 같은 데이터 prior로 문제를 제한하는 것을 목표로 한다. 그러나 이러한 prior를 데이터와 균형 잡는 것은 여전히 어려운 일이다. 게다가 장면별 최적화는 시간이 많이 걸리기 때문에 확장하기 어렵다.
반면, 학습 기반 접근법은 feed-forward 방식으로 재구성을 직접 예측하기 위해 대규모 데이터셋에서 학습되어 데이터에서 강력한 prior를 학습한다. 이러한 고유한 prior는 복잡한 모션으로 인한 모호성을 해결하는 데 도움이 될 수 있지만 아직 동적 장면으로 확장되지 않았다. 이러한 제한은 동적 장면을 모델링하는 복잡성과 4D 학습 데이터의 부족에서 비롯된다. 따라서 유일한 feed-forward 동적 재구성 모델은 물체 중심의 합성 데이터셋에서 학습되고 고정된 카메라 시점과 멀티뷰 학습이 필요하며 실제 장면 시나리오로 일반화할 수 없다.
본 논문은 동적 장면을 효과적으로 처리할 수 있는 feed-forward 재구성 모델을 구축하기 위해, 픽셀 정렬된 3D Gaussian Splatting (3DGS) 예측 모델의 최근 성공을 바탕으로 feed-forward 동적 재구성을 위한 새로운 bullet-time 방법을 제안하였다.
핵심 아이디어는 컨텍스트(입력) 프레임에 bullet-time 임베딩을 추가하여 출력된 3DGS 표현에 대한 원하는 타임스탬프를 나타내는 것이다. 모델은 bullet 타임스탬프에서 장면을 반영하도록 컨텍스트 프레임의 예측을 집계하도록 학습되어 공간적으로 완전한 3DGS 장면을 생성한다. 이 디자인은 정적 및 동적 재구성 시나리오를 자연스럽게 통합할 뿐만 아니라 장면 역학을 캡처하는 방법을 학습하는 동안 모델이 암시적으로 모션을 인식할 수 있도록 한다. 제안된 방법은 다음과 같은 장점이 있다.
- 대량의 정적 장면 데이터에서 모델을 사전 학습할 수 있게 해준다.
- 입력 동영상의 길이와 프레임 속도에 제약받지 않고 데이터셋에서 효과적으로 확장된다.
- 본질적으로 여러 시점을 지원하는 볼류메트릭 동영상 표현을 출력한다.
빠른 모션이 있는 경우, 메인 모델에 공급하기 전에 중간 프레임을 예측하기 위해 추가적인 Novel Time Enhancer (NTE) 모듈을 도입하였다.
Method
- 입력
- Monocular 동영상 ($N$개의 이미지): \(\mathcal{I} = \{\mathbf{I}_i \in \mathbb{R}^{H \times W \times 3}\}_{i=1}^N\)
- 카메라 포즈: \(\mathcal{P} = \{\mathbf{P}_i \in \mathbb{SE}(3)\}_{i=1}^N\)
- intrinsic
- 타임스탬프: $\mathcal{T} = {t_i \in \mathbb{R}}_{i=1}^N$
- 목표: 임의의 타임스탬프 $t \in [t_1, t_N]$에서 고품질의 새로운 뷰를 렌더링할 수 있는 feed-forward 모델을 구축
본 논문의 핵심은 BTimer라는 이름의 transformer 기반 bullet-time 재구성 모델로, 컨텍스트 프레임 \(\mathcal{I}_c \subset \mathcal{I}\)과 해당 포즈 \(\mathcal{P}_c \subset \mathcal{P}\)과 타임스탬프 \(\mathcal{T}_c \subset \mathcal{T}\)를 받아 지정된 bullet 타임스탬프 \(t_b \in [\min_{\mathcal{T}_c}, \max_{\mathcal{T}_c}]\)에서 고정된 완전한 3DGS 장면을 출력한다. 모든 $t_b \in \mathcal{T}$를 반복하면 3DGS 시퀀스로 표현된 전체 동영상 재구성이 생성된다.
또한 보간된 프레임을 타임스탬프 $t \notin \mathcal{T}$로 합성하는 Novel Time Enhancer (NTE) 모듈을 도입하였다. NTE 모듈의 출력은 다른 컨텍스트 뷰와 함께 BTimer의 입력으로 사용되어 임의의 중간 타임스탬프에서 재구성을 향상시킨다. 모델을 효과적으로 학습시키기 위해, 저자들은 정적, 동적 장면을 모두 포함하는 방대한 양의 데이터셋을 통합하는 학습 커리큘럼을 신중하게 설계하여, 모델의 모션 인식과 시간적 일관성을 강화했다.
1. BTimer Reconstruction Model
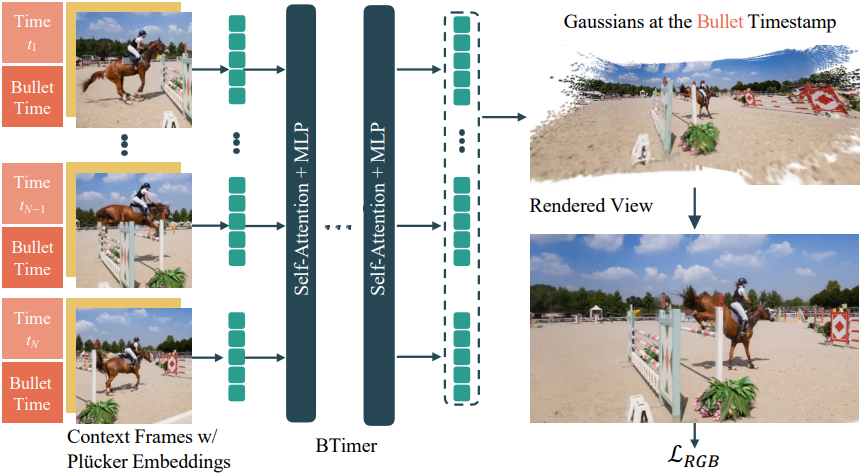
모델 디자인
GS-LRM에서 영감을 얻은 BTimer 모델은 ViT 기반 네트워크를 backbone으로 사용하며, 모델의 시작과 끝에 모두 LayerNorm이 적용된 24개의 self-attention block으로 구성된다.
각 입력 컨텍스트 프레임 \(\mathbf{I}_i \in \mathcal{I}_c\)를 8$\times$8 패치로 나누고, linear embedding layer를 사용하여 feature space \(\{\mathbf{f}_{ij}^\textrm{rgb}\}_{j=1}^{HW/64}\)로 projection한다. 카메라 포즈 \(\mathbf{P}_i \in \mathcal{P}_c\)에서 얻은 카메라 Plucker embedding과 시간 임베딩은 각각 컨텍스트 프레임과 비슷한 방법으로 카메라 포즈 feature \(\{\mathbf{f}_{ij}^\textrm{pos}\}\)와 시간 feature \(\{\mathbf{f}_i^\textrm{time}\}\)를 형성한다. 이러한 feature를 모두 더해 컨텍스트 프레임의 패치에 대한 입력 토큰을 형성한다.
\[\begin{equation} \mathbf{f}_{ij} = \mathbf{f}_{ij}^\textrm{rgb} + \mathbf{f}_{ij}^\textrm{pose} + \mathbf{f}_i^\textrm{time} \end{equation}\]모든 컨텍스트 프레임의 입력 토큰은 concat되어 Transformer block에 입력된다.
각각의 출력 토큰 \(\mathbf{f}_{ij}^\textrm{out}\)은 하나의 linear layer를 통과하여 3DGS 파라미터 \(\mathbf{G}_{ij} \in \mathbb{R}^{8 \times 8 \times 12}\)로 디코딩된다. 각 3D Gaussian은 12개의 파라미터로 구성된다.
- RGB 색상: $\mathbf{c} \in \mathbb{R}^{3}$
- scale: $\mathbf{s} \in \mathbb{R}^{3}$
- rotation quaternion: $\mathbf{q} \in \mathbb{R}^{4}$
- opacity: $\sigma \in \mathbb{R}$
- ray distance: $\tau \in \mathbb{R}$
각 Gaussian의 3D 위치는 \(\boldsymbol{\mu} = \mathbf{o} + \tau \mathbf{d}\)로 계산되며, 광선의 원점과 방향 $\mathbf{o}$와 $\mathbf{d}$는 카메라 포즈 \(\mathbf{P}_i\)에서 계산된다.
시간 임베딩
입력으로 주어지는 시간 feature \(\mathbf{f}_i^\textrm{time}\)은 각 컨텍스트 프레임 \(\mathbf{I}_i\)에 대해 별도의 컨텍스트 타임스탬프 $t_i$와, 모든 컨텍스트 프레임에서 공유되는 bullet 타임스탬프 $t_b$에서 얻어진다. 두 타임스탬프는 각각표준 Positional Encoding (PE)을 사용하여 인코딩된 다음 각각 두 개의 linear layer를 통과하여 feature \(\mathbf{f}_i^\textrm{ctx}\)와 \(\mathbf{f}_i^\textrm{bullet}\)이 된다. 마지막으로 두 feature를 더해 시간 feature를 계산한다.
\[\begin{equation} \mathbf{f}_i^\textrm{time} = \mathbf{f}_i^\textrm{ctx} + \mathbf{f}_i^\textrm{bullet} \end{equation}\]Supervision Loss
BTimer는 RGB 이미지 공간에서 정의된 loss에 의해서만 학습되며, 실제 데이터에서 얻기 어려운 3D ground-truth 소스에 대한 필요성을 피한다. 최종 loss는 3DGS 출력에서 렌더링된 이미지와 ground-truth 이미지 간의 MSE loss와 LPIPS loss의 가중 합이다.
\[\begin{equation} \mathcal{L}_\textrm{RGB} = \mathcal{L}_\textrm{MSE} + \lambda \mathcal{L}_\textrm{LPIPS} \end{equation}\]($\lambda = 0.5$)
학습 중에 입력 컨텍스트 프레임과 bullet 타임스탬프를 신중하게 선택하는 것은 안정적인 학습과 수렴에 필수적이다. 저자들은 다음 두 가지 전략을 결합하는 것이 특히 효과적이라는 것을 알게 되었다.
- In-context Supervision: 컨텍스트 프레임에서 bullet 타임스탬프를 무작위로 선택하여 모델이 컨텍스트 타임스탬프를 정확하게 localize하고 재구성하도록 한다. 멀티뷰 동영상 데이터셋의 경우 추가 뷰의 이미지도 loss에 기여할 수 있다.
- Interpolation Supervision: Bullet 타임스탬프가 두 개의 인접한 컨텍스트 프레임 사이에 있도록 하여, 모델이 정적 영역의 일관성을 유지하면서 동적 부분을 보간하도록 한다. 이 전략이 없으면 모델은 3D Gaussian을 컨텍스트 뷰에 가깝게 배치하고 다른 뷰에서는 숨겨서 local minima에 빠지며, 최종 성능에 중요한 역할을 한다.
Inference
동영상의 모든 타임스탬프에 bullet 타임스탬프 $t_b$를 반복적으로 설정하여 전체 동영상을 간단하게 재구성할 수 있으며, 이는 병렬로 효율적으로 수행할 수 있게 해준다. 학습 컨텍스트 뷰 수 \(\vert \mathcal{I}_c \vert\)보다 긴 동영상의 경우, 타임스탬프 $t$에서 $t_b = t$로 설정하는 것 외에도, 나머지 \(\vert \mathcal{I}_c \vert - 1\)개의 컨텍스트 프레임들을 동영상 전체에 걸쳐 균일하게 분배하여 \(\vert \mathcal{I}_c \vert\)개의 프레임이 있는 입력 batch를 형성한다.
2. Novel Time Enhancer (NTE) Module
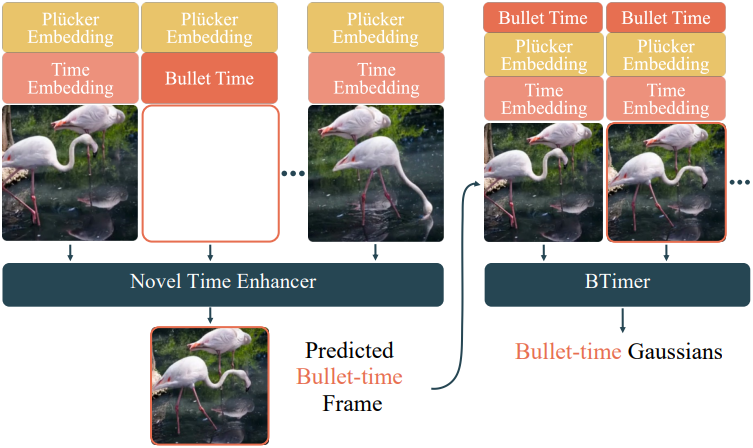
BTimer 모델은 이미 모든 관찰된 타임스탬프에 대한 3DGS 표현을 재구성할 수 있지만, 새로운 중간 타임스탬프에서 재구성하도록 강제하는 것, 즉 $t_b \notin \mathcal{T}$에서 보간을 수행하는 것은 좋지 못한 결과로 이어진다. 이러한 경우 정확한 bullet-time 프레임은 존재하지 않기 때문에 컨텍스트 프레임에 포함할 수 없다. 모델은 특히 모션이 복잡하고 빠를 때 인접한 동영상 프레임 간의 원활한 전환을 예측하는 데 실패한다. 이는 주로 픽셀 정렬된 3D Gaussian 예측의 inductive bias로 인해 발생한다.
저자들은 이 문제를 완화하기 위해, 주어진 타임스탬프에서 이미지를 직접 출력하는 Novel Time Enhancer (NTE) 모듈을 제안하였다. 이 모듈은 BTimer 모델의 입력으로 사용된다.
NTE 모듈 디자인
NTE 모듈의 디자인은 decoder-only LVSM 모델에서 많은 영감을 받았다. 구체적으로, NTE는 BTimer 모델에서 동일한 ViT 아키텍처를 사용하지만, 입력 컨텍스트 토큰의 시간 feature는 해당 컨텍스트 타임스탬프만 인코딩한다.
\[\begin{equation} \mathbf{f}_i^\textrm{time} = \mathbf{f}_i^\textrm{ctx} \end{equation}\]또한, 입력 토큰에 추가로 타겟 토큰을 concat하는데, 이는 타겟 타임스탬프와 RGB 이미지를 생성하려는 타겟 포즈를 인코딩한다. LVSM을 따라 QK-norm을 사용하여 학습을 안정화한다. 구현 측면에서 타겟 토큰에 대한 모든 attention을 마스킹하는 attention mask를 적용하므로, KV-Cache를 사용하여 더 빠른 inference가 가능하다. Transformer backbone의 출력에서 타겟 토큰만 유지하고, unpatchify한 다음, 하나의 linear layer를 사용하여 원래 이미지 해상도의 RGB 값으로 projection한다. NTE 모듈은 기본 BTimer 모델과 동일한 loss로 학습되지만, 출력 이미지는 네트워크에서 직접 디코딩되며 3DGS 표현에서 렌더링되지 않는다.
BTimer와 통합
NTE 모듈은 단독으로 사용하여 새로운 뷰를 생성할 수 있지만, 생성 품질이 떨어지는 것으로 나타났다. 따라서 저자들은 NTE 모듈을 기본 BTimer 모델과 통합하였다. $t_b \notin \mathcal{T}$에서 bullet-time 3DGS를 재구성하기 위해 먼저 NTE를 사용하여 타임스탬프 $t_b$에서 \(\mathbf{I}_b\)를 합성한다. 여기서 타겟 포즈 \(\mathcal{P}_b\)는 $\mathcal{P}$의 근처 컨텍스트 포즈에서 linear interpolation되고 컨텍스트 프레임은 $t_b$에 가장 가까운 프레임들로 선택된다. Inference를 가속화하기 위해 KV-Cache 전략을 사용하며, 실제로 전체 런타임에 무시할 수 있는 오버헤드만 추가한다.
3. Curriculum Training at Scale
신경망 학습에서 중요한 것은 학습을 스케일링하는 것이고, 모델의 일반화 능력은 주로 데이터 다양성에 의해 결정된다. 본 논문의 bullet-time 재구성 방법은 자연스럽게 정적과 동적 장면을 모두 지원하고, RGB loss만 필요하기 때문에, 수많은 정적 데이터셋의 가용성을 활용하여 모델을 사전 학습시킬 수 있는 잠재력이 있다.
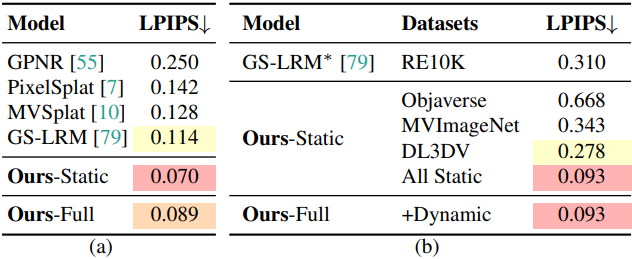
따라서 저자들은 어떤 데이터셋에도 특화되지 않은 재구성 모델을 학습시켜 정적 및 동적 장면 모두로 일반화하고, 실내 및 실외 장면뿐만 아니라 물체를 처리할 수 있도록 하는 것을 목표로 하였다. 이는 다른 도메인에서는 다른 모델이 필요한 GS-LRM이나 MVSplat과는 대조적이다.
Stage 1: Low-res to High-res Static Pretraining
보다 일반화 가능한 3D prior로 모델을 초기화하기 위해, 먼저 정적 데이터셋들을 혼합하여 모델을 사전 학습시킨다.
- 데이터셋: Objaverse (물체 중심), RE10K, MVImgNet, DL3DV (실내/실외 장면)
- 39만 개의 학습 샘플로 구성
- 스케일을 $10^3$ 정육면체로 대략적으로 제한되도록 정규화
- 컨텍스트 뷰: 4개
- 시간 임베딩은 사용하지 않음
- 해상도: 처음에는 128$\times$128로 학습 후 256$\times$256, 512$\times$512로 점차적으로 fine-tuning
Stage 2: Dynamic Scene Co-training
정적 장면에서 학습한 후, 동적 장면에 대하여 시간 임베딩 projection layer와 함께 모델을 fine-tuning한다.
- 데이터셋: Kubric, PointOdyssey, DynamicReplica, Spring
- 4D 데이터가 부족하기 때문에 정적 데이터셋을 유지
- 인터넷 동영상에서 카메라 포즈를 레이블링하는 파이프라인을 구축하고 학습 세트에 추가
Stage 3: Long-context Window Fine-tuning
긴 동영상을 재구성할 때 더 많은 컨텍스트 프레임을 포함하는 것은 필수적이다. 따라서 마지막 단계로 컨텍스트 뷰의 수 \(\vert \mathcal{I}_c \vert\)를 4에서 12로 늘려 더 많은 프레임을 포함시킨다. NTE는 근처 프레임만 입력으로 사용하기 때문에 이 단계는 적용되지 않는다.
Annotating Internet Videos
- PANDA-70M 데이터셋에서 무작위로 부분집합을 선택
- 동영상을 약 20초 길이의 짧은 클립으로 자름
- Segment Anything Model로 동영상의 동적 물체를 마스킹
- DROID-SLAM으로 카메라 포즈를 추정
- 낮은 품질의 동영상이나 포즈는 reprojection error를 측정하여 필터링
최종 데이터셋에는 고품질 카메라 궤적이 있는 4만 개 이상의 클립이 포함된다.
Experiments
- 학습 디테일
- 전체 학습에 NVIDIA A100 64개로 4일 정도 소요
- cosine annealing schedule로 learning rate가 0으로 감소하도록 설정
- Stage 1
- iteration: BTimer는 9만, 9만, 5만 / NTE는 14만, 6만, 3만
- 초기 learning rate: $4 \times 10^{-4}$
- Stage 2
- iteration: BTimer는 1만 / NTE는 2만
- 초기 learning rate: $2 \times 10^{-4}$
- Stage 3
- iteration: 5천
- 초기 learning rate: $1 \times 10^{-4}$
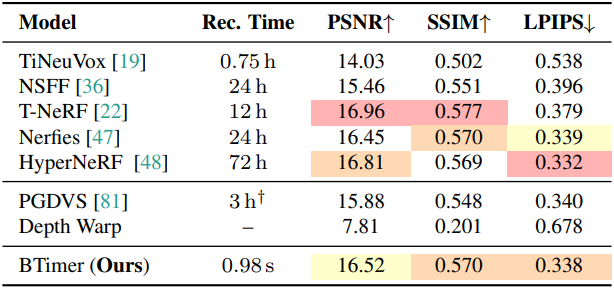
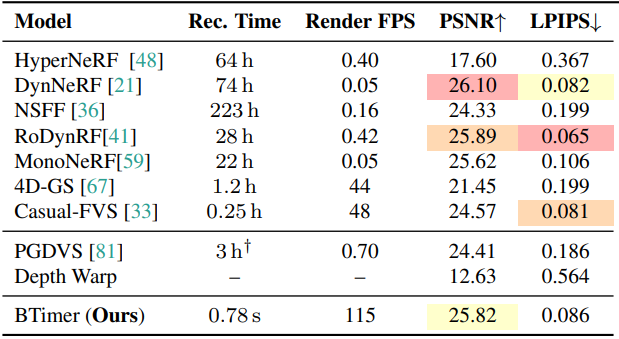
1. Dynamic Novel View Synthesis
다음은 (왼쪽) DyCheck와 (오른쪽) NVIDIA dynamic scene에서의 결과를 비교한 것이다.

다음은 DAVIS 데이터셋에서의 결과를 시각화한 것이다.

2. Compatibility with Static Scenes
다음은 (a) RE10K와 (b) Tanks and Temples에서의 결과를 비교한 것이다.
다음은 Tanks & Temples에서의 비교 결과이다.

3. Ablation Study
다음은 커리큘럼 학습에 대한 ablation 결과이다.

- (a) 3D 사전 학습 없음
- (b) Re10K만 3D 사전 학습
- (c) Stage 2에서 정적 공동 학습이 없음
- (d) Interpolation Supervision 없음
- (e) Novel Time Enhancer 모델
- (f) 전체 모델
다음은 컨텍스트 프레임의 수에 대한 ablation 결과이다.

다음은 NTE 모듈에 대한 ablation 결과이다.

Limitations
- 복구된 장면의 depth map은 일반적으로 가장 최근의 깊이 예측 모델만큼 정확하지 않다.
- 뷰 extrapolation에 대한 지원이 제한적이다.