[논문리뷰] Buffer Anytime: Zero-Shot Video Depth and Normal from Image Priors
CVPR 2025. [Paper] [Github]
Zhengfei Kuang, Tianyuan Zhang, Kai Zhang, Hao Tan, Sai Bi, Yiwei Hu, Zexiang Xu, Milos Hasan, Gordon Wetzstein, Fujun Luan
Stanford University | MIT | Adobe Research
26 Nov 2024
Introduction
이미지/동영상 diffusion model과 LLM을 포함한 foundation model의 최근 발전은 이미지 및 동영상 buffer 추정을 위한 강력한 모델 개발을 가속화했다. Buffer란 픽셀별 깊이, normal, 조명(lighting), 재질 속성과 같은 정보를 의미하며, 본 논문에서는 깊이와 normal, 즉 geometry buffer에 중점을 두었다. 최근 연구들은 이미지에서 다양한 유형의 buffer를 예측하는 데 있어 인상적인 결과를 보여주었으며, 동영상 buffer 예측을 위한 대규모 모델의 활용을 더욱 확대하여, 프레임 전반에 걸쳐 높은 충실도와 일관성을 유지하면서 탁월한 동영상 깊이 예측을 보여주었다.
저차원 입력(텍스트, 단일 프레임)을 조건으로 받아 고차원 출력(이미지, 동영상)을 생성하는 일반적인 이미지/동영상 생성 모델과 달리, buffer 추정 모델은 일반적으로 원하는 결과와 동일한 크기의 RGB 이미지/동영상을 조건으로 한다. 입력에는 이미 풍부한 구조적 및 semantic 정보가 포함되어 있다. 결과적으로, 이미지 변환 모델은 text-to-image/video 생성 모델에 비해 유사한 입력 조건에서 일관된 콘텐츠를 생성할 가능성이 훨씬 높다. 저자들은 이러한 관찰을 바탕으로 동영상 buffer 생성을 위해 기존 이미지 모델을 업그레이드할 가능성을 모색하게 되었다.
본 논문에서는 GT 동영상 데이터로부터 어떠한 supervision도 없이 이미지 prior로부터 학습된 효과적인 동영상 geometry buffer 모델을 제시하였다. 본 논문에서는 이미지 형상 모델에 대한 지식과 기존 optical flow 기법을 결합하여 학습된 모델 예측의 시간적 일관성과 정확성을 모두 보장하는 유연한 zero-shot 학습 전략인 Buffer Anytime을 제안하였다. 저자들은 Buffer Anytime을 두 가지 SOTA 이미지 모델, 즉 depth 추정용 Depth Anything V2와 normal 추정용 Marigold-E2E-FT에 적용하여 다양한 동영상 형상 추정에서 상당한 개선을 보였다.
Method
- 입력: $K$ 프레임으로 구성된 RGB 동영상 $I_{1, \ldots, K} \in \mathbb{R}^{K \times H \times W \times 3}$
- 출력: Depth map \(\mathcal{D}_{1, \ldots, K} \in \mathbb{R}^{K \times H \times W}\) 또는 카메라 좌표계에서의 normal map \(\mathcal{N}_{1, \ldots, K} \in \mathbb{R}^{K \times H \times W \times 3}\)
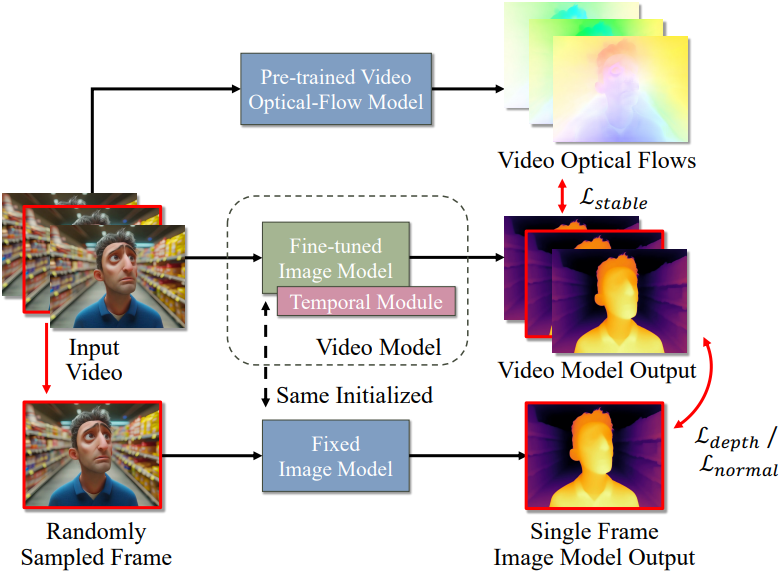
본 논문의 핵심 통찰력은 이미지 기반 diffusion prior와 optical flow 기반 시간 안정화 제어를 결합하는 것이다. 대규모 이미지 쌍 데이터셋으로 학습되어 데이터 prior $p^\textrm{image} (\mathcal{D} \vert I)$ / $p^\textrm{image} (\mathcal{N} \vert I)$를 재구성하는 이미지 깊이/normal 예측 모델 \(f_\theta^\textrm{image} (I) = \mathcal{D}^\textrm{image}\)가 주어졌을 때, 본 논문의 목표는 \(f_\theta^\textrm{image}\)에 기반하고 동영상에서 depth/normal map을 예측할 수 있는 업그레이드된 동영상 모델 \(f_\theta^\textrm{video}\)를 개발하는 것이다.
\(f_\theta^\textrm{video}\)의 예측은 두 가지 조건을 충족해야 한다.
- 각 프레임의 깊이/normal 예측은 이미지 데이터 prior $p^\textrm{image} (\mathcal{D} \vert I)$ / $p^\textrm{image} (\mathcal{N} \vert I)$를 수용해야 한다.
- 예측 프레임은 시간적으로 안정적이고 서로 일관성이 있어야 한다.
1. Training Pipeline
저자들은 두 가지 조건을 달성하기 위해, 두 가지 유형의 loss를 사용하는 새로운 학습 전략을 설계했다.
- 모델이 이미지 모델에 맞춰 결과를 생성하도록 강제하는 정규화 loss
- Optical flow 기반 안정화 loss
깊이 추정에서 정규화 loss는 affine-invariant relative loss를 기반으로 한다.
\[\begin{equation} \mathcal{L}_\textrm{depth} = \frac{1}{HW} \| \hat{\mathcal{D}}_k^\prime - \mathcal{D}_k^\prime \|_2 \end{equation}\]\(\mathcal{D}^\prime\)은 offset \(t = \textrm{median}(\mathcal{D})\)와 scale \(s = \frac{1}{HW} \sum_x \vert \mathcal{D}(x) - t \vert\)로 정규화된 예측 depth map이며, $\hat{\mathcal{D}}$는 이미지 모델의 정규화된 depth map이다.
Normal 추정에서는 backbone 모델의 latent 표현을 활용하고, 예측된 latent map $z$에 L2 loss를 적용한다.
\[\begin{equation} \mathcal{L}_\textrm{normal} = \frac{1}{HW} \| \hat{z}_k - z_k \|_2 \end{equation}\]학습 속도를 높이기 위해, 각 iteration마다 동영상에서 하나의 프레임을 무작위로 선택하고 이 프레임에 대해서만 정규화 loss를 계산한다. 전체 학습 loss는 다음과 같다.
\[\begin{equation} \mathcal{L} = \omega_\textrm{reg} \cdot \mathcal{L}_\textrm{depth/normal} + \mathcal{L}_\textrm{stable} \end{equation}\](\(\omega_\textrm{reg} = 1\), \(\mathcal{L}_\textrm{stable}\)은 optical flow 기반 시간 안정화 loss)
학습 과정에서는 동영상 모델 외에도 고정된 사전 학습된 이미지 모델과 optical flow 모델이 함께 사용된다. 단일 프레임 예측과 optical flow map은 just-in-time 방식으로 계산된다. Normal 모델의 경우, 시간 안정화 loss를 계산하려면 먼저 출력 latent map을 RGB 프레임으로 디코딩해야 하는데, 메모리 제한으로 인해 모든 프레임에 한 번에 적용하기는 어렵다. 따라서 ARF에서 도입된 deferred back-propagation을 적용한다. 구체적으로, 먼저 latent map을 4개 프레임의 청크로 분할한 다음, 각 청크에 대한 안정화 loss를 한 번에 계산하고 gradient를 back-propagation한다. 모든 청크의 gradient를 concat하여 전체 latent map의 기울기를 얻는다.
2. Optical Flow Based Stabilization
단일 시점 이미지 예측 모델은 예측의 affine transformation 모호성과 모델의 불확실성으로 인해 프레임 간 결과가 일관되지 않은 경우가 많다. 이 문제를 해결하기 위한 합리적인 접근법은 여러 프레임에 걸쳐 해당 픽셀 간의 깊이 예측을 정렬하는 것이다. 시간적 일관성 안정화를 위해 사전 학습된 optical flow 추정 모델을 적용하여 인접 프레임 간의 correspondence를 계산한다.
구체적으로, 두 인접 프레임 $I_k$, \(I_{k+1}\) 간의 예측된 optical flow map이 각각 \(\mathcal{O}_{k \rightarrow k+1}\)과 \(\mathcal{O}_{k+1 \rightarrow k}\)일 때, 두 프레임 간의 안정화 loss는 다음과 같이 정의할 수 있다.
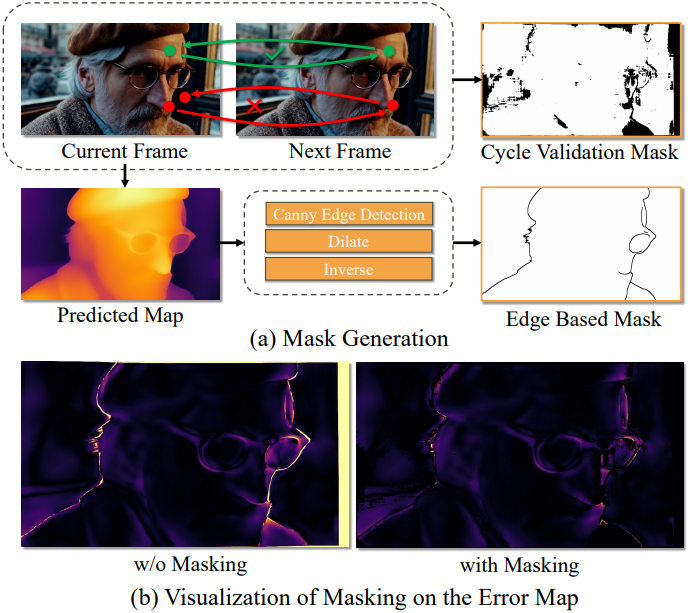
\[\begin{aligned} \mathcal{L}_\textrm{stable} &= \frac{1}{2HW} \sum_x \vert I_k (x) - I_{k+1} (\mathcal{O}_{k \rightarrow k+1} (x)) \vert_1 \\ &+ \frac{1}{2HW} \sum_x \vert I_{k+1} (x) - I_k (\mathcal{O}_{k+1 \rightarrow k} (x)) \vert_1 \\ \end{aligned}\]그러나 실제로는 사전 학습된 모델의 한계로 인해 optical flow 예측이 부정확하거나 잘못될 수 있으며, 이는 loss function의 효율성을 저해한다. 이를 방지하기 위해 두 가지 필터링 방법을 추가하여 프레임 전체에서 올바르게 대응되는 픽셀을 선별한다. 첫 번째 필터링 방법은 많은 image correspondence 방법에서 일반적으로 사용되는 cycle-validation 기법이며, 다음 식을 만족하는 $I_k$의 픽셀만 선택한다.
\[\begin{equation} \| \mathcal{O}_{k \rightarrow k+1} (\mathcal{O}_{k+1 \rightarrow k} (x)) - x \|_2 \le \tau_c \end{equation}\](\(\tau_c\)는 hyperparameter threshold)
두 번째 필터링 방법은 optical flow의 부정확성으로 인해 깊이 프레임의 경계 영역 근처에서 \(\mathcal{L}_\textrm{stable}\)이 잘못 평가될 수 있다는 관찰 결과에 기반한다. 구체적으로, 예측된 depth map에 Canny edge detector를 적용한 후, 검출된 edge와 가까운 픽셀 (맨해튼 거리가 3픽셀 미만인 픽셀)의 loss를 필터링한다. 이 두 필터를 조합하면 outlier를 효과적으로 제거하고 모델의 robustness를 향상시킬 수 있다.
3. Model Architecture
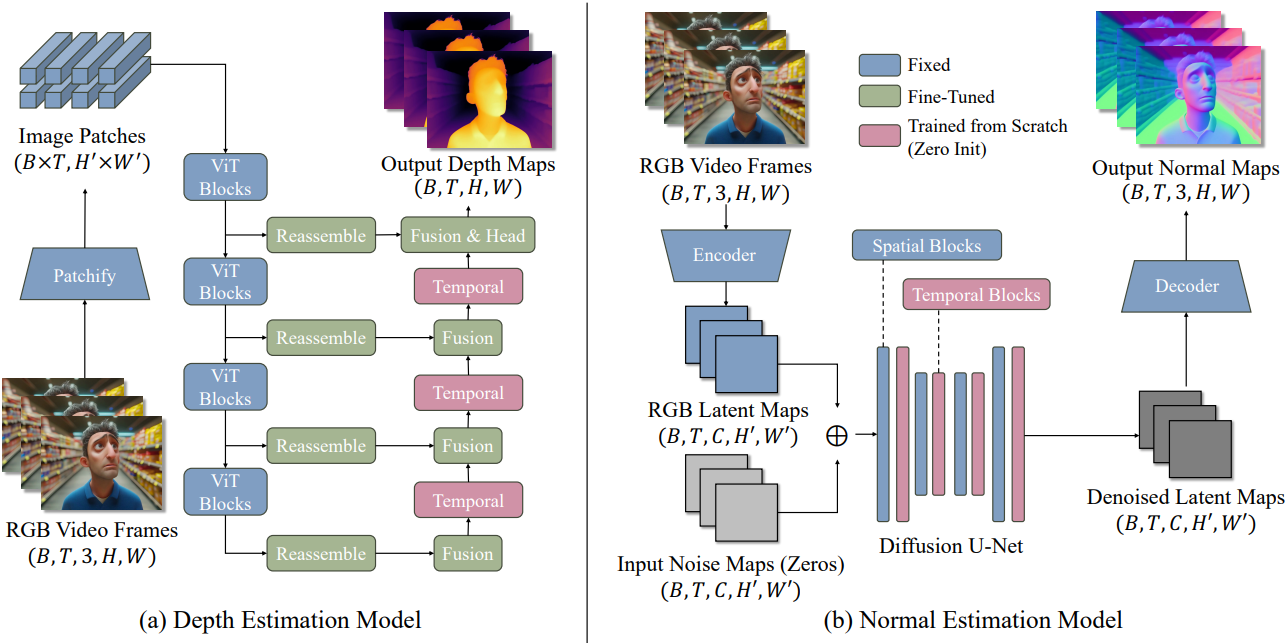
여러 프레임에서 일관되고 충실도가 높은 동영상 결과를 생성하려면 입력 프레임의 구조를 견고하게 보존하는 강력하고 안정적인 이미지 기반 backbone 모델을 선택하는 것이 매우 중요하다. 이는 이미지 결과의 불일치와 모호성을 크게 줄여 동영상 모델 학습 과정을 용이하게 한다. 본 논문에서는 깊이 예측 모델의 백본 모델로 Depth Anything V2를, normal 예측 모델에는 Marigold-E2E-FT를 사용하였다.
Depth Anything V2는 인코더 역할을 하는 ViT와 여러 ViT 블록의 feature 출력을 융합하여 최종 결과를 생성하는 가벼운 refinement 네트워크로 구성된 DPT이다. 저자들은 ViT backbone을 고정하고 refinement 네트워크만 fine-tuning하였다. 또한 fusion block 사이에 세 개의 temporal block을 삽입하여 서로 다른 프레임에 걸쳐 있는 latent map을 연결한다. ViT 블록은 gradient 흐름에서 완전히 분리되어 있어 학습 중 메모리 비용을 줄이고 긴 동영상을 지원할 수 있다.
Marigold-E2E-FT는 Stable-Diffusion V2.0을 기반으로 구축된 latent diffusion model이다. 저자들은 spatial layer 사이에 temporal layer를 삽입하였으며, 원래 U-Net layer와 오토인코더는 모두 학습 중 고정된다.
두 모델의 temporal block은 여러 개의 temporal attention block과 그 뒤의 projection layer로 구성된다. 각 블록의 최종 projection layer는 학습 시작 시 모델이 이미지 모델과 동일하게 동작하도록 0으로 초기화된다.
가벼운 temporal block은 동영상 시퀀스의 효율적인 처리를 가능하게 하며, backbone을 고정하고 시간적인 구성 요소만 학습함으로써, 사전 학습된 모델의 강력한 기하학적 이해 능력을 유지하면서도 시간적 추론 능력을 향상시킨다.
Experiments
- 구현 디테일
- GPU: NVIDIA H100 80GB 24개
- 최대 프레임: 깊이 추정은 110, normal 추정은 32
- optimizer: AdamW
- learning rate: 깊이 추정은 $10^{-4}$, normal 추정은 $10^{-5}$
- 전체 batch size: 24
- iteration: 2만 (약 1일 소요)
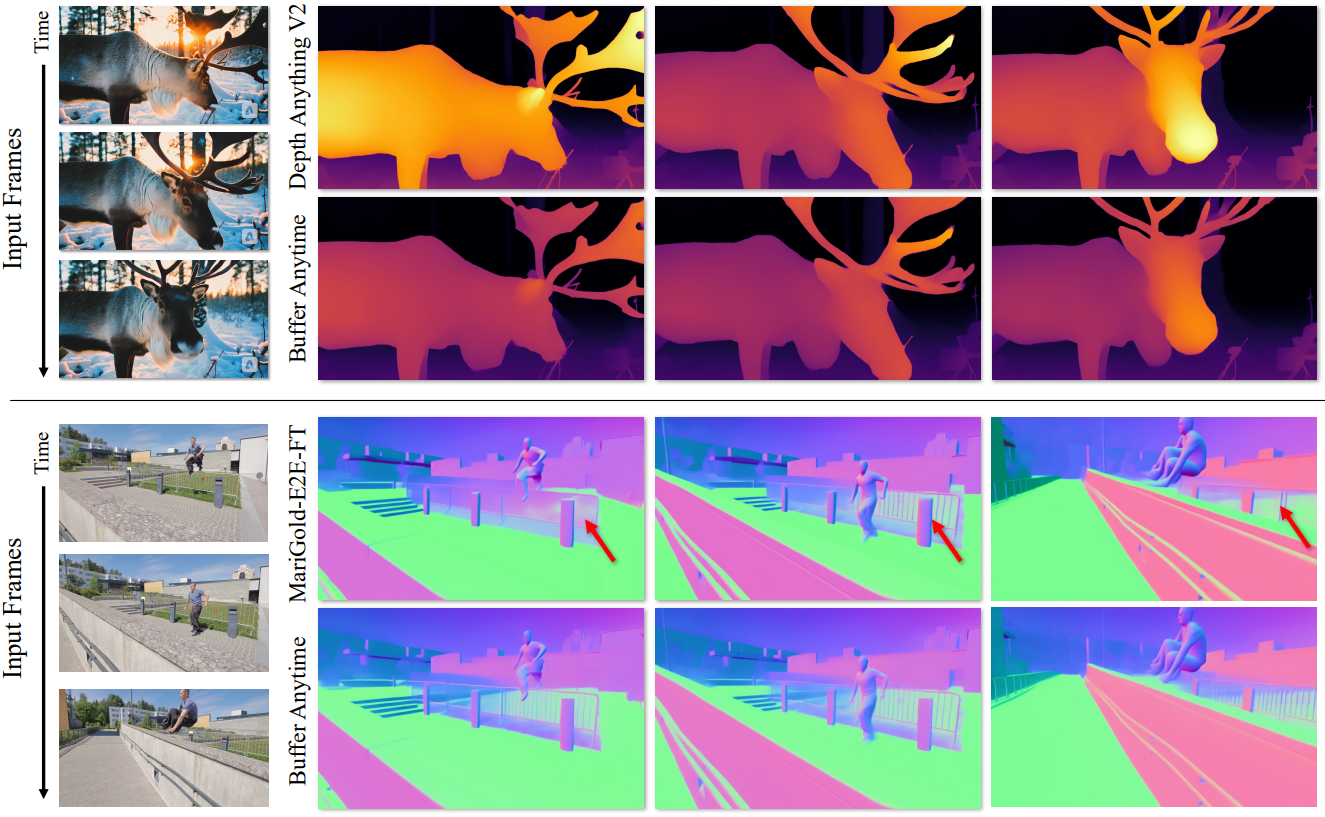
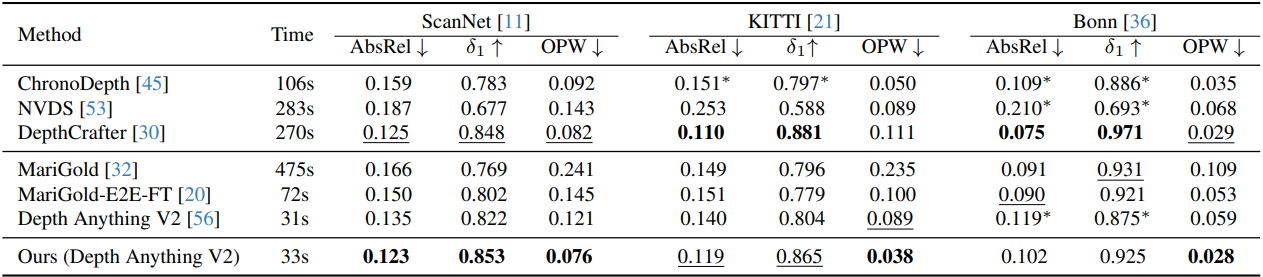
1. Video Depth Estimation Results
다음은 동영상 깊이 추정 성능을 비교한 결과이다.

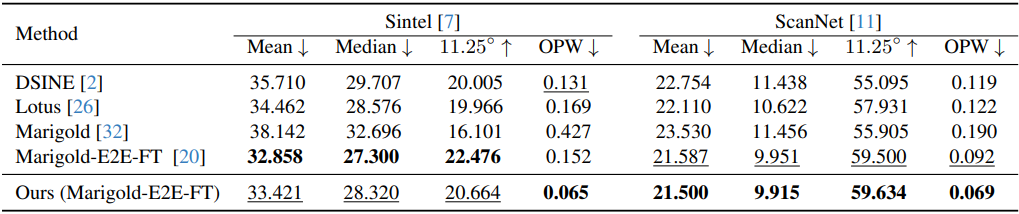
2. Video Normal Estimation Results
다음은 동영상 normal 추정 성능을 비교한 결과이다.

3. Ablation Study
다음은 ablation 결과이다. (KITTI 깊이 추정)