[논문리뷰] Image and Video Tokenization with Binary Spherical Quantization
ICLR 2025. [Paper] [Github]
Yue Zhao, Yuanjun Xiong, Philipp Krähenbühl
UT Austin | MThreads AI
11 Jun 2024
Introduction
본 논문에서는 ViT와 Binary Spherical Quantization (BSQ)를 기반으로 하는 통합된 visual tokenizer를 제안하였다. Transformer 기반 인코더-디코더는 blockwise causal mask를 활용하고 재구성을 위해 현재 또는 과거 타임스탬프의 visual token만을 사용한다. BSQ는 transformer 인코더의 고차원 임베딩을 저차원 hypersphere로 projection한 후 binary quantization을 적용한다. Transformer 인코더, 디코더, BSQ는 VQ-GAN 프레임워크에 원활하게 통합되어 end-to-end 학습이 수행된다.
본 논문에서 제안하는 visual tokenizer는 여러 가지 장점을 가지고 있다.
- Transformer 기반 인코더/디코더는 표준 CNN에 비해 재구성 품질과 계산 효율성에서 개선을 보인다.
- Blockwise causal 디자인은 학습 시 이미지와 동영상을 입력으로 통합하고 inference 시 가변 길이 동영상을 지원한다.
- 학습된 파라미터 없이 hypersphere 차원에 따라 유효한 vocabulary가 기하급수적으로 증가하는 implicit codebook을 구축한다.
- Codebook 크기가 증가할수록 재구성 결과가 일관되게 향상된다.
- Soft quantization 확률이 여러 베르누이 분포의 단순 곱으로 축소되어 학습 중 효율적인 엔트로피 정규화를 가능하게 한다.
Method

본 논문에서 제시하는 동영상 tokenizer는 discretization bottleneck을 갖는 인코더-디코더 아키텍처를 따른다. 이 아키텍처는 transformer 기반 인코더, transformer 기반 디코더, 그리고 BSQ layer를 결합한 것이다.
1. Binary Spherical Quantization
BSQ는 단위 구에 projection된 hypercube인 implicit codebook \(\textbf{C}_\textrm{BSQ} = \{ -\frac{1}{\sqrt{L}}, \frac{1}{\sqrt{L}} \}^L\)에 대해 최적화된다. Hypercube의 각 꼭짓점 \(\textbf{c}_k \in \textbf{C}_\textrm{BSQ}\)는 고유한 토큰 $k$에 해당한다.
구체적으로, 인코딩된 입력 \(\textbf{z} = \mathcal{E}(x) \in \mathbb{R}^d\)에서 시작한다. 먼저 latent 임베딩 $\textbf{z}$를 $L$차원 벡터 $\textbf{v}$로 linear projection한다 ($L \ll d$). 그런 다음, $\textbf{v}$를 단위 구에 projection한 $\textbf{u}$를 얻는다. 그리고 $\textbf{u}$의 각 차원에 대해 독립적으로 binary quantization을 수행햔다. 출력을 단위 구면에 유지하기 위해 $\textrm{sign}(0) \rightarrow 1$로 매핑한다.
\[\begin{equation} \textbf{v} = \textrm{Linear}(\textbf{z}), \quad \textbf{u} = \frac{\textbf{v}}{\vert \textbf{v} \vert}, \quad \hat{\textbf{u}} = \frac{1}{\sqrt{L}} \textrm{sign} (\textbf{u}) \end{equation}\]연산자를 미분 가능하게 하기 위해 Straight-Through Estimator (STE)를 사용한다.
\[\begin{equation} \textrm{sign}_\textrm{STE} (x) = \textrm{stop-gradient} ( \textrm{sign}(x) - x) + x \end{equation}\]마지막으로, quantize된 $\hat{\textbf{u}}$를 $d$차원 공간으로 back-projection한다.
\[\begin{equation} \hat{\textbf{z}} = \textrm{Linear}(\hat{\textbf{u}}) \in \mathbb{R}^d \end{equation}\]BSQ는 몇 가지 매력적인 속성을 가지고 있다.
- Implicit codebook entry는 파라미터가 없으며 계산하기 쉽다.
- Soft quantization이 간단한 확률적 해석을 가지므로 entropy loss \(\mathcal{L}_\textrm{entropy}\)에서 효율적인 엔트로피 계산이 가능하다.
- Quantization error가 제한되어 있어 빠르고 우수한 수렴을 보인다.
효율적인 implicit code 할당
Inference 시에, projection된 임베딩 $\textbf{v}$를 다음과 같은 간단한 binarization을 통해 토큰으로 매핑한다.
\[\begin{equation} k = \sum_{i=1}^L 1_{[v_i > 0]} 2^{i-1} \end{equation}\]역 매핑에는 bitshift와 bitwise AND 연산이 사용된다.
Soft BSQ와 엔트로피
Implicit codebook \(\textbf{C}_\textrm{BSQ}\)의 전체 범위를 최대한 활용하기 위해 entropy loss를 사용한다.
\[\begin{equation} \mathcal{L}_\textrm{entropy} = \mathbb{E}_\textbf{u} [H (q (\textbf{u}))] - \gamma H [\mathbb{E}_\textbf{u} [q(\textbf{u})]] \end{equation}\]이 entropy loss를 계산하기 위해 soft quantization 방식을 사용한다. Codebook entry와 quantizer의 입력 모두 단위 벡터이므로 soft quantization은 다음과 같은 분포이다.
\[\begin{equation} \hat{q} (\textbf{c} \vert \textbf{u}) = \frac{\exp (\tau \textbf{c}^\top \textbf{u})}{\sum_{\textbf{c} \in \textbf{C}_\textrm{BSQ}} \exp (\tau \textbf{c}^\top \textbf{u})} = \prod_{d=1}^L \sigma (2 \tau c_d u_d) \end{equation}\]($\sigma$는 sigmoid function)
증명)
$\Omega = \{ - \frac{1}{\sqrt{L}}, \frac{1}{\sqrt{L}} \}$라 하자. $$ \begin{aligned} \sum_{\textbf{c} \in \textbf{C}_\textrm{BSQ}} \exp (\tau \textbf{c}^\top \textbf{u}) &= \sum_{\textbf{c} \in \textbf{C}_\textrm{BSQ}} \prod_{d=1}^L \exp (\tau u_d c_d) \\ &= \sum_{c_1 \in \Omega} \sum_{c_2 \in \Omega} \cdots \sum_{c_L \in \Omega} \prod_{d=1}^L \exp (\tau u_d c_d) \\ &= \sum_{c_1 \in \Omega} \sum_{c_2 \in \Omega} \cdots \sum_{c_L \in \Omega} \exp (u_L c_L) \prod_{d=1}^{L-1} \exp (\tau u_d c_d) \\ &= \sum_{c_1 \in \Omega} \sum_{c_2 \in \Omega} \cdots \sum_{c_{L-1} \in \Omega} \left( \prod_{d=1}^{L-1} \exp (\tau u_d c_d) \right) \left( \sum_{c_L \in \Omega} \exp (\tau u_L c_L) \right) \\ &= \cdots \\ &= \left( \sum_{c_1 \in \Omega} \exp (\tau u_1 c_1) \right) \left( \sum_{c_2 \in \Omega} \exp (\tau u_2 c_2) \right) \cdots \left( \sum_{c_L \in \Omega} \exp (\tau u_L c_L) \right) \\ &= \prod_{d=1}^L \sum_{c_d \in \Omega} \exp (\tau u_d c_d) \\ \hat{q} (\textbf{c} \vert \textbf{u}) &= \frac{\exp (\tau \textbf{c}^\top \textbf{u})}{\sum_{\textbf{c} \in \textbf{C}_\textrm{BSQ}} \exp (\tau \textbf{c}^\top \textbf{u})} = \frac{\prod_{d=1}^L \exp (\tau u_d c_d)}{\prod_{d=1}^L \sum_{c_d \in \Omega} \exp (\tau u_d c_d)} \\ &= \prod_{d=1}^L \frac{\exp (\tau u_d c_d)}{\exp (\tau u_d c_d) + \exp (\tau u_d (-c_d))} = \prod_{d=1}^L \frac{1}{1 + \exp (- 2 \tau u_d c_d)} \\ &= \prod_{d=1}^L \sigma (2 \tau c_d u_d) \end{aligned} $$
전체 soft quantizer는 각 차원에 대해 독립적이다. 이는 첫 번째 엔트로피 항을 효율적으로 계산할 수 있도록 해준다.
기하급수적으로 커지는 전체 codebook에 대한 분포를 고려하는 대신, 각 차원을 독립적으로 처리한다. 그 결과, 엔트로피 계산은 bottleneck의 차원 $L$에 대해 선형적으로 증가한다.
두 번째 엔트로피 항은 기대값 \(\mathbb{E}_\textbf{u} [\hat{q} (\textbf{c} \vert \textbf{u})]\)의 차원이 $\textbf{u}$의 분포를 통해 상관관계를 가지므로 동일한 독립성 가정을 직접 사용할 수 없다. 저자들은 \(\mathbb{E}_\textbf{u} [\hat{q} (\textbf{c} \vert \textbf{u})]\)에 가장 가까운 \(\tilde{q} (\textbf{c}) = \prod_{d=1}^K \tilde{q}(c_d)\)를 찾고, 대신 근사 분포의 엔트로피를 최소화하였다. KL-divergence 측면에서 최적의 근사치는 \(\tilde{q} = \mathbb{E}_{u_d} [\hat{q} (c_d \vert u_d)]\)이다. 최종적으로 최대화해야 할 근사 엔트로피 항은 다음과 같다.
\[\begin{equation} H (\mathbb{E}_\textbf{u} [\hat{q} (\textbf{c} \vert \textbf{u})]) \approx H (\tilde{q}(\textbf{c})) = \sum_{d=1}^L H (\mathbb{E}_{u_d} [\hat{q} (c_d \vert u_d)]) \end{equation}\]이 근사값은 실제 엔트로피의 상한값이지만, 경험적으로 실제 엔트로피를 매우 잘 따라간다. 이 엔트로피 항은 계산에 있어서도 효율적이다.
BSQ의 quantization error
대부분의 quantizer는 학습 중에 pass-through gradient 추정치를 사용한다. 구현은 간단하지만, 이는 quantization되지 않은 $\textbf{u}$와 quantization된 $\hat{\textbf{u}}$에 대한 gradient가 거의 같다고 가정하는데, 이는 quantization error \(d(\textbf{u}, \hat{\textbf{u}}) = \| \textbf{u} − \hat{\textbf{u}} \|\)가 작을 때만 성립한다. BSQ의 경우 다음과 같은 조건이 충족된다.
\[\begin{equation} \mathbb{E}_\textbf{u} [d(\textbf{u}, \hat{\textbf{u}})] < \sqrt{2 - \frac{2}{\sqrt{L}}} < \sqrt{2} \end{equation}\]2. Tokenization Network with Causal Video Transformer
본 논문에서는 계산 효율성이 더 높고 재구성 품질이 더 우수하기 때문에 인코더와 디코더 모두를 모델링하는 ViT를 사용하였다.
Video Transformer
ViT-VQGAN을 기반으로 동영상을 입력으로 받도록 확장한다. 입력 동영상 $\textbf{X} \in \mathbb{R}^{T \times H \times W \times 3}$를 $1 \times p \times p$ 크기의 겹치지 않는 패치 \(\textbf{x}_i \in \mathbb{R}^{1 \times p \times p \times 3}\)로 나눈다. Visual token은 1D 시퀀스로 flatten되고, linear projection된 후, $N$개의 Transformer 인코더 레이어를 통과하여 latent 표현 \((\textbf{z}_1, \cdots, \textbf{z}_N)\)을 생성한다. 디코더는 동일한 아키텍처를 사용하여 latent 임베딩 \(\hat{\textbf{z}}\)를 픽셀 공간으로 다시 매핑하고 원래 shape으로 재구성한다.
\[\begin{aligned} (\textbf{z}_1, \cdots, \textbf{z}_N) &= \textrm{TransformerEncoder} \left( \textbf{x}_1, \cdots, \textbf{x}_N \right) \\ (\hat{\textbf{z}}_1, \cdots, \hat{\textbf{z}}_N) &= q \left( \textbf{z}_1, \cdots, \textbf{z}_N \right) \\ (\textbf{x}_1, \cdots, \textbf{x}_N) &= \textrm{MLP} \left( \textrm{TransformerEncoder} \left( \hat{\textbf{z}}_1, \cdots, \hat{\textbf{z}}_N \right) \right) \end{aligned}\](\(\textrm{MLP}(\cdot)\)는 2-layer MLP (Linear, Tanh, Linear)를 사용하는 디코딩 head)
Blockwise Causal Attention
학습 과정에서는 입력 동영상이 항상 $T$ 프레임으로 구성되어 있다고 가정하지만, inference 시에는 그렇지 않을 수 있다. 짧은 동영상 세그먼트를 $T$ 프레임으로 패딩하는 방법은 효과적이지만, 특히 압축의 맥락에서 많은 bit를 낭비한다.
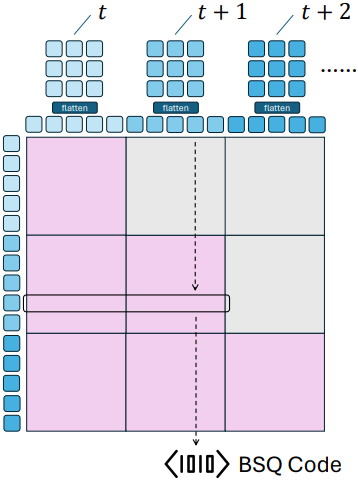
저자들은 가변 길이 동영상을 처리하기 위해, 언어 모델링의 causal attention과 유사한 간단한 blockwise causal masked attention을 제안하였다. 이 attention은 시간 $t$ 또는 그 이전의 토큰만 시간 \(t \in \{1, \cdots, T\}\)에서의 visual token을 재구성하는 데 사용할 수 있도록 지정한다.
이는 blockwise lower triangle matrix로 표현된 blockwise causal attention mask를 사용하여 효율적으로 구현할 수 있다. $T=1$일 때, 제안된 인코더-디코더는 전체 attention mask를 사용하는 ViT가 된다. 따라서 이미지와 동영상이 혼합된 환경에서도 쉽게 학습시킬 수 있다.
본 논문에서는 시간적 위치 정보를 인코딩하기 위해 시간과 공간이 분해된 위치 임베딩을 사용한다. 구체적으로, 이미지 tokenizer에서 원래의 공간적 위치 임베딩 \(\textrm{PE}_s \in \mathbb{R}^{N \times d}\)에 0으로 초기화된 시간적 위치 임베딩 \(\textrm{PE}_t \in \mathbb{R}^{T \times d}\)를 더한다.
\[\begin{equation} \textrm{PE}[i, :, :] = \textrm{PE}_t [i, \textrm{None}, :] + \textrm{PE}_s [\textrm{None}, :, :] \end{equation}\]이미지 tokenizer를 사용하여 동영상 tokenizer를 학습
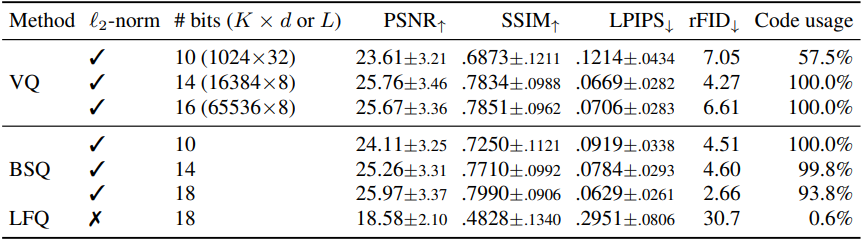
기존 동영상 데이터셋의 다양성 부족으로 인해, 먼저 이미지 데이터로 이미지 tokenizer를 학습시킨 후 이를 fine-tuning하여 동영상 tokenizer로 만든다. 사전 학습된 이미지 tokenizer를 동영상에 그대로 사용하는 것에 비해, fine-tuning을 거친 동영상 tokenizer가 동영상 벤치마크에서 훨씬 높은 복원 품질을 보여주었다. 유효 vocabulary 크기가 커질수록 이러한 성능 향상은 더욱 두드러진다. 제안된 BSQ를 통해 가능해진 이러한 vocabulary 크기 증가는 동영상 특유의 모션과 blur 현상을 학습하는 데 유용하다. 반면, 기존 VQ 방식은 codebook 크기가 16K를 초과하면 높은 codebook 사용률을 유지하지 못한다.
Visual tokenizer 최적화
VQ-GAN을 따라 perceptual loss와 adversarial loss를 사용한다. Discriminator로는 StyleGAN을 사용하는데, ViT-VQGAN에 따르면 StyleGAN이 PatchGAN보다 학습이 훨씬 쉽다고 한다. 동영상에 대한 tokenizer를 fine-tuning할 때는 StyleGAN을 3D로 확장하지 않는다. 대신, 재구성된 모든 프레임을 개별적으로 일반 StyleGAN에 입력하고 loss를 합산한다.
Experiments
- 데이터셋
- 이미지: ImageNet ILSVRC2012
- 동영상: UCF-101
1. Main Results
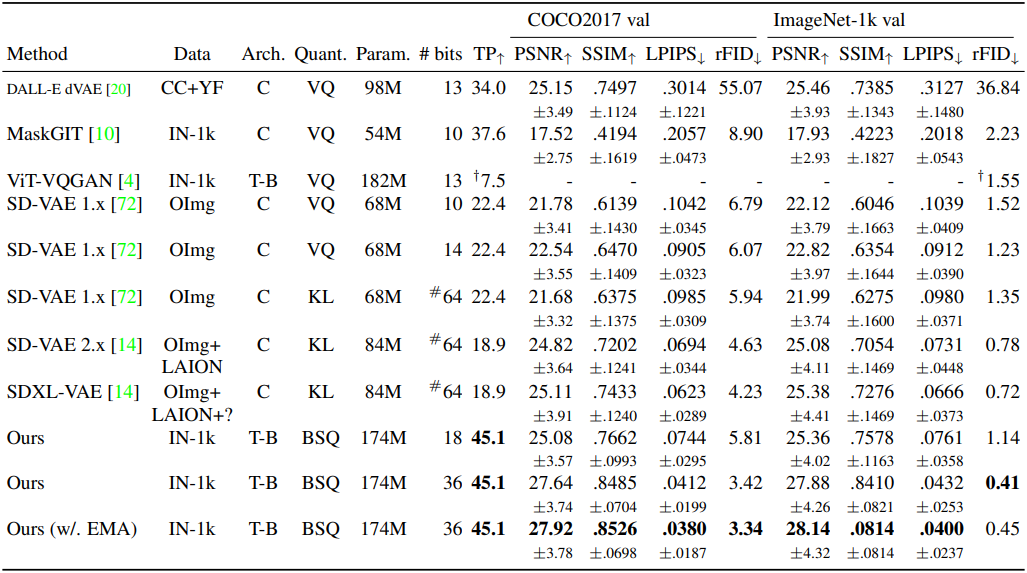
다음은 COCO2017과 ImageNet-1K 256$\times$256에서의 이미지 재구성 결과이다.
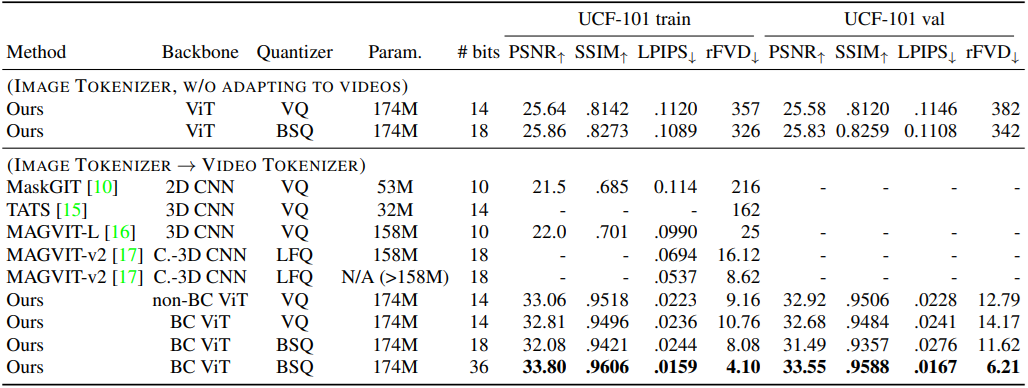
다음은 UCF-101 (split 1)에서의 동영상 재구성 결과이다.
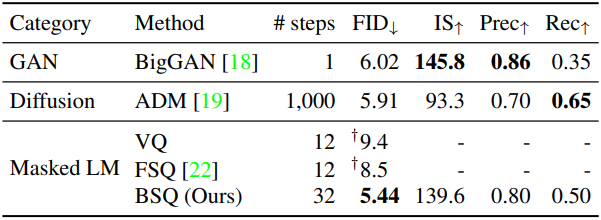
다음은 ImageNet-1K 128$\times$128에서의 이미지 생성 결과이다.
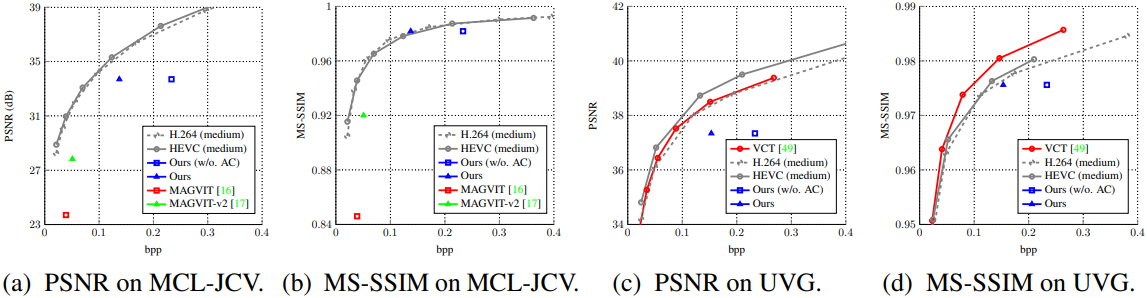
다음은 MCL-JCV 640$\times$360와 UVG 1920$\times$1080에서의 동영상 압축 결과이다.
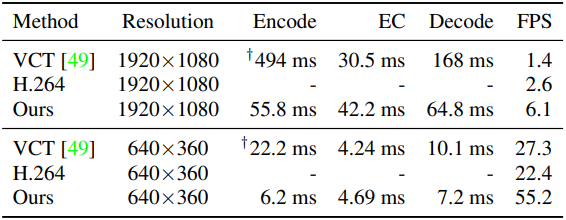
다음은 인코딩/디코딩 속도를 비교한 결과이다.
2. Ablation Studies
다음은 ablation study 결과이다. (ImageNet-1k val 128$\times$128)
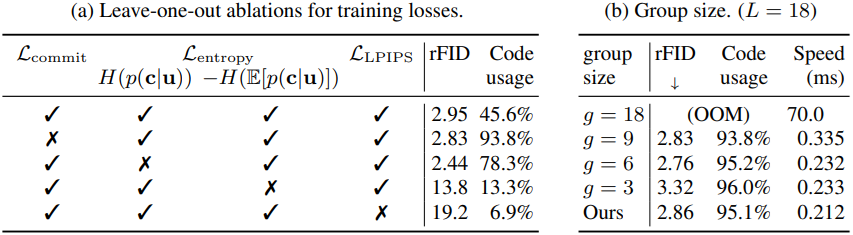
다음은 loss 설계에 대한 ablation study 결과이다.