[논문리뷰] BrushNet: A Plug-and-Play Image Inpainting Model with Decomposed Dual-Branch Diffusion
ECCV 2024. [Paper] [Page] [Github]
Xuan Ju, Xian Liu, Xintao Wang, Yuxuan Bian, Ying Shan, Qiang Xu
Tencent PCG | The Chinese University of Hong Kong
11 Mar 2024

Introduction
이미지 인페인팅의 목적은 전체적인 일관성을 유지하면서 이미지의 누락된 영역을 복원하는 것이다. 최근 diffusion model은 이미지 생성에서 인상적인 성능을 보여주어 의미론적 및 구조적 조건으로 유연한 제어가 가능하다. 연구자들은 주어진 텍스트 프롬프트에 맞춘 고품질 이미지 인페인팅을 위해 diffusion 기반 파이프라인을 사용하였다.
일반적으로 diffusion model을 사용한 텍스트 기반 인페인팅 방법은 대략 두 가지 카테고리로 나눌 수 있다.
- 샘플링 전략 수정: 사전 학습된 diffusion model에서 마스킹된 영역을 샘플링하여 denoising process를 수정한 후 마스킹되지 않은 영역은 단순히 각 denoising step에서 주어진 이미지를 복사하여 붙여넣는 방법이다. 임의의 diffusion backbone에 사용될 수 있지만 마스크 경계와 마스킹되지 않은 이미지 영역 컨텍스트에 대한 제한된 지식으로 인해 일관되지 않은 인페인팅 결과가 발생한다.
- 전용 인페인팅 모델: 제공된 손상된 이미지와 마스크를 통합하기 위해 diffusion model의 입력 채널 차원을 확장하여 특별히 설계된 이미지 인페인팅 모델을 fine-tuning하는 방법이다.
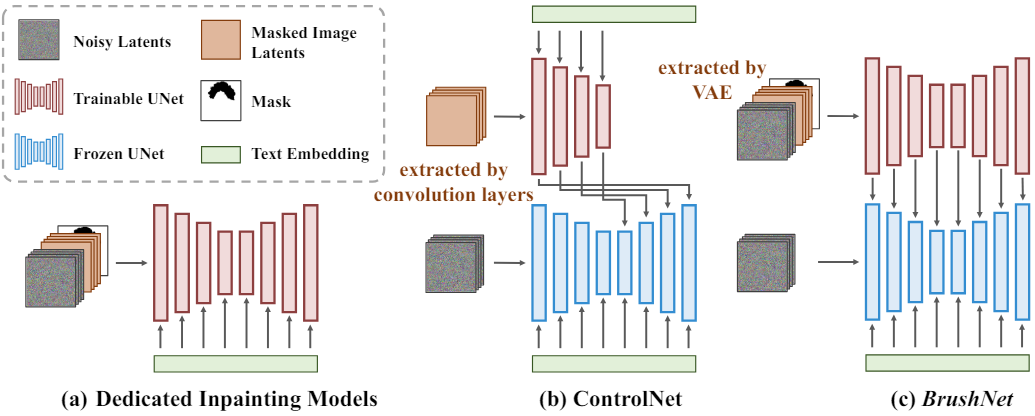
위 그림에서 볼 수 있듯이 전용 인페인팅 모델은 초기 step에서 noisy latent, 마스킹된 이미지의 latent, 마스크, 텍스트를 융합한다. 이 아키텍처 디자인은 마스킹된 이미지 feature가 텍스트 임베딩의 영향을 쉽게 받도록 하여 UNet의 후속 레이어가 텍스트의 영향으로 인해 순수한 마스킹된 이미지 feature를 얻는 것을 방지한다. 또한 하나의 branch에서 컨디셔닝과 생성을 처리하면 UNet 프레임워크에 추가 부담이 부과된다. 이러한 접근 방식은 backbone에 대한 fine-tuning도 필요하며, 이는 시간이 많이 걸릴 수 있다.
마스킹된 이미지 feature 추출 전용 branch를 추가하는 것은 위의 문제를 해결하는 유망한 접근 방식이 될 수 있다. 그러나 ControlNet과 같은 기존 방법은 인페인팅에 직접 적용할 때 부적절한 정보 추출 및 삽입으로 이어지며, 이는 제어 가능한 이미지 생성과 인페인팅 간의 차이에서 비롯된다. 인페인팅은 텍스트에 의존하는 sparse한 구조적 제어에 의존하는 대신 강력한 제한적 정보를 사용한 픽셀 간 제약이 필요하다. 결과적으로 ControlNet은 전용 인페인팅 모델에 비해 만족스럽지 못한 결과를 산출한다.
본 논문은 이 문제를 해결하기 위해 diffusion 프레임워크에 추가 branch를 도입하여 이미지 인페인팅에 더 적합한 아키텍처를 만드는 BrushNet을 제안하였다. 본 논문의 디자인은 세 가지로 구성된다.
- UNet 분포에 적응하기 위한 이미지 feature 추출을 개선하기 위해 랜덤하게 초기화된 convolution layer 대신 VAE 인코더를 사용하여 마스킹된 이미지를 처리한다.
- Dense한 픽셀별 제어를 위해 사전 학습된 UNet에 전체 UNet feature를 레이어별로 점진적으로 통합하는 계층적 접근 방식을 채택한다.
- 추가 branch에서 순수한 이미지 정보가 고려되도록 하기 위해 UNet에서 텍스트 cross-attention을 제거한다.
이 디자인은 인페인팅 프로세스에 plug-and-play 기능과 유연한 마스킹되지 않은 영역 제어 기능을 추가로 제공한다. 더 나은 일관성과 더 넓은 범위의 마스캉되지 않은 영역 제어를 위해 흐린 혼합 전략을 추가한다.
Motivation
1. Previous Inpainting Models
샘플링 전략 수정. 마스킹된 이미지를 생성된 결과와 점진적으로 혼합하여 인페인팅한다. 그 중에서 가장 많이 사용되는 방법은 Blended Latent Diffusion (BLD)이다. 바이너리 마스크 $m$, 마스킹된 이미지 $x_0^\textrm{masked}$가 주어지면 BLD는 먼저 VAE를 사용하여 마스킹된 이미지의 latent 표현 $z_0^\textrm{masked}$를 추출한다. 이어서, 마스크 $m$은 latent 표현의 크기와 일치하도록 $m^\textrm{resized}$로 크기가 조정된다. 각 샘플링 단계는 다음과 같다.
\[\begin{equation} z_{t-1} \leftarrow z_{t-1} \cdot (1 - m^\textrm{resized}) + z_{t-1}^\textrm{masked} \cdot m^\textrm{resized} \end{equation}\]구현이 단순함에도 불구하고 BLD는 마스킹되지 않은 영역 보존 및 생성 콘텐츠 정렬 측면에서 좋지 못한 성능을 나타낸다. 이는 마스크의 크기 조정으로 인해 noisy latent를 올바르게 혼합하지 못하고, diffusion model에 마스크 경계와 마스킹되지 않은 이미지 영역 컨텍스트에 대한 지식이 부족하기 때문이다.
전용 인페인팅 모델. 인페인팅 성능을 향상시키기 위해 이전 연구들에서는 마스크와 마스킹된 이미지 입력을 포함하도록 입력 UNet 채널을 확장하여 base model을 fine-tuning하고 이를 이미지 인페인팅용으로 특별히 설계된 아키텍처로 전환했다. BLD에 비해 더 나은 생성 결과를 제공하지만 여전히 몇 가지 단점이 있다.
- 이 모델은 UNet 아키텍처의 초기 convolution layer에서 noisy latent, 마스킹된 이미지의 latent, 마스크를 병합하며, 여기서 텍스트 임베딩에 의해 집합적으로 영향을 받는다. 결과적으로 UNet 모델의 후속 레이어는 텍스트의 영향으로 인해 마스킹된 이미지의 feature를 얻는 데 어려움을 겪는다.
- 조건 처리와 생성을 하나의 branch에 통합하면 UNet 프레임워크에 추가적인 부담이 가해진다.
- 이러한 접근 방식은 광범위한 fine-tuning이 필요하며, 이는 계산 집약적이며 맞춤형 diffusion model로의 전송 가능성(transferability)이 부족하다.
2. Motivation
인페인팅의 보다 효과적인 아키텍처 디자인은 특별히 마스킹된 이미지를 처리하기 위한 전용 branch를 도입하는 것이다. ControlNet은 이러한 아이디어를 채택하였다. 그러나 원래 제어 가능한 이미지 생성을 위해 설계된 ControlNet을 인페인팅 task에 직접 fine-tuning하면 만족스럽지 못한 결과가 나온다. ControlNet은 도메인 외부 구조 조건을 통합하기 위해 인코더를 설계하고 콘텐츠 생성을 위한 텍스트 guidance에 의존한다. 이는 픽셀 수준의 인페인팅에 적합하지 않다. 또한 ControlNet은 일반적으로 sparse한 제어에 의존한다. 즉, UNet 프레임워크의 residual에 제어를 추가하는 것만으로도 충분하지만 인페인팅에는 강력한 제한 정보가 포함된 픽셀간 제약 조건이 필요하다. 따라서 인페인팅을 위해 특별히 설계된 새로운 아키텍처가 필요하다.
Method
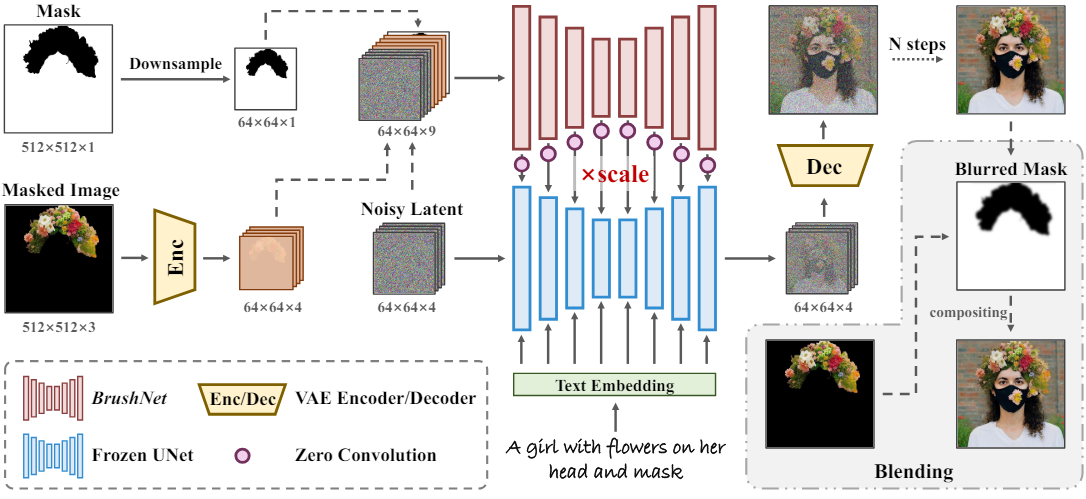
1. Masked Image Guidance
사전 학습된 diffusion model에 마스킹된 이미지의 feature를 삽입하는 것은 이미지 생성 프로세스에서 마스킹된 이미지의 feature 추출을 명시적으로 분리하는 추가 branch를 통해 수행된다. Noisy latent, 마스킹된 이미지의 latent, 다운샘플링된 마스크가 concatenate되어 추가 branch에 대한 입력을 형성한다. 특히, noisy latent는 현재 생성 프로세스 중에 생성 정보를 제공하여 BrushNet이 마스킹된 이미지의 feature의 semantic 일관성을 향상시키는 데 도움을 준다. 마스킹된 이미지의 latent는 사전 학습된 UNet의 데이터 분포와 정렬되는 VAE를 사용하여 마스킹된 이미지에서 추출된다. 마스크 크기와 noisy latent 및 마스킹된 이미지의 정렬을 보장하기 위해 cubic interpolation을 사용하여 마스크를 다운샘플링한다.
BrushNet은 마스킹된 이미지의 feature를 처리하기 위해 cross-attention layer를 제거한 사전 학습된 diffusion model의 복제본을 활용한다. Diffusion model의 사전 학습된 가중치는 마스킹된 이미지의 feature를 추출하기 위한 강력한 prior 역할을 하는 반면, cross-attention layer를 제거하면 이 추가 branch 내에서 순수한 이미지 정보만 고려되도록 보장된다. BrushNet feature는 고정된 diffusion model에 레이어별로 삽입되어 dense한 픽셀별 제어를 계층적으로 가능하게 한다. ControlNet과 유사하게 고정된 모델과 학습 가능한 BrushNet 사이의 연결을 위해 zero-convolution layer를 사용한다. 이렇게 하면 학습 초기 단계에서 유해한 noise가 학습 가능한 복사본에 영향을 주지 않는다.
Feature 삽입 연산은 다음과 같다.
\[\begin{equation} \epsilon_\theta (z_t, t, C)_i = \epsilon_\theta (z_t, t, C)_i + w \cdot \mathcal{Z} (\epsilon_\theta^\textrm{BrushNet} ([z_t, z_0^\textrm{masked}, m^\textrm{resized}], t)_i) \end{equation}\]\(\epsilon_\theta (z_t, t, C)_i\)는 네트워크 $\epsilon_\theta$의 $i$번째 레이어의 feature를 나타낸다. $[\cdot]$은 concatenatation 연산이고 $\mathcal{Z}$는 zero-convolution 연산이다. $w$는 사전 학습된 diffusion model에 대한 BrushNet의 영향을 조정하는 데 사용되는 보존 스케일이다.
2. Blending Operation
Latent space에서 수행되는 블렌딩 연산은 마스크 크기 조정으로 인해 부정확한 결과를 초래할 수 있다. 또한 VAE 인코딩 및 디코딩 연산에는 고유한 한계가 있으며 완전한 이미지 재구성을 보장하지 못할 수 있다.
마스킹되지 않은 영역의 완전히 일관된 이미지 재구성을 보장하기 위해 먼저 마스크를 블러링한 다음 블러링된 마스크를 사용하여 복사/붙여넣기를 수행하여 이 문제를 해결한다. 이 접근 방식으로 인해 마스크 경계의 디테일을 보존하는 데 약간의 정확도가 손실될 수 있지만 육안으로는 오차를 거의 인지할 수 없으며 마스크 경계의 일관성이 크게 향상된다.
3. Flexible Control
BrushNet의 아키텍처 디자인은 본질적으로 다양한 사전 학습된 diffusion model에 대한 plug-and-play 통합에 적합하고 유연한 보존 스케일을 사용할 수 있다. 특히 BrushNet의 유연한 제어에는 다음이 포함된다.
- 사전 학습된 diffusion model의 가중치를 수정하지 않으므로 plug-and-play 구성 요소로 쉽게 통합될 수 있다. 이를 통해 사전 학습된 다양한 모델을 쉽게 채택할 수 있다.
- 가중치 $w$를 갖는 고정된 diffusion model에 BrushNet feature를 통합하여 마스킹되지 않은 영역의 보존 스케일을 제어할 수 있다. 이 가중치는 보존 스케일에 대한 BrushNet의 영향을 결정하여 원하는 보존 수준을 조정할 수 있다.
- 블러링 스케일을 조정하고 블렌딩 연산 적용 여부를 결정함으로써 마스킹되지 않은 영역의 보존 스케일을 더욱 맞춤화할 수 있다. 이러한 기능을 사용하면 인페인팅 프로세스를 유연하고 세밀하게 제어할 수 있다.
Experiments
- 데이터셋: BrushData (Laion-Aesthetic에 segmentation mask 추가)
- 구현 디테일
- Base model: Stabe Diffusion v1.5
- step 수: 50
- guidance scale: 7.5
- iteration: 43만
- GPU: NVIDIA Tesla V100 8개 (약 3일 소요)
- 벤치마크
- EditBench
- BrushBench: 사람이 직접 마스크와 캡션을 단 600장의 이미지
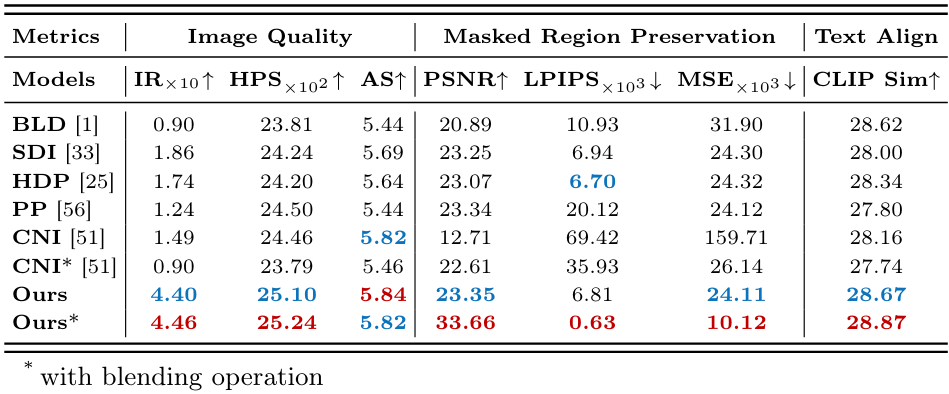
1. Quantitative Comparison
다음은 BrushBench에서 정량적으로 비교한 표이다.
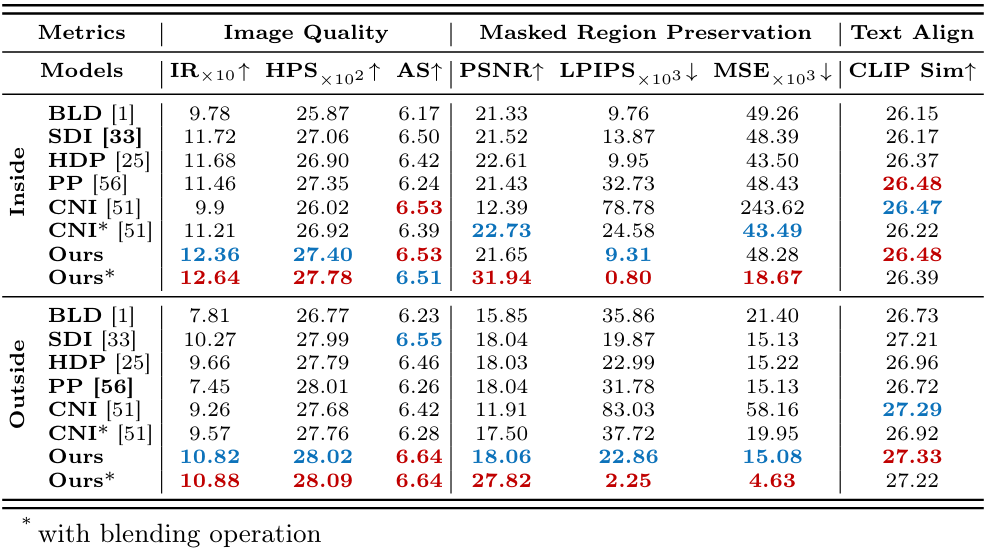
다음은 EditBench에서 정량적으로 비교한 표이다.
2. Qualitative Comparison
다음은 다양한 이미지 도메인에서의 정성적 비교 결과이다.

3. Flexible Control Ability
다음은 다양한 fine-tuning된 diffusion model에 BrushNet을 통합한 결과들이다.

다음은 보존 스케일 $w$에 따른 인페인팅 결과를 비교한 것이다.

4. Ablation Study
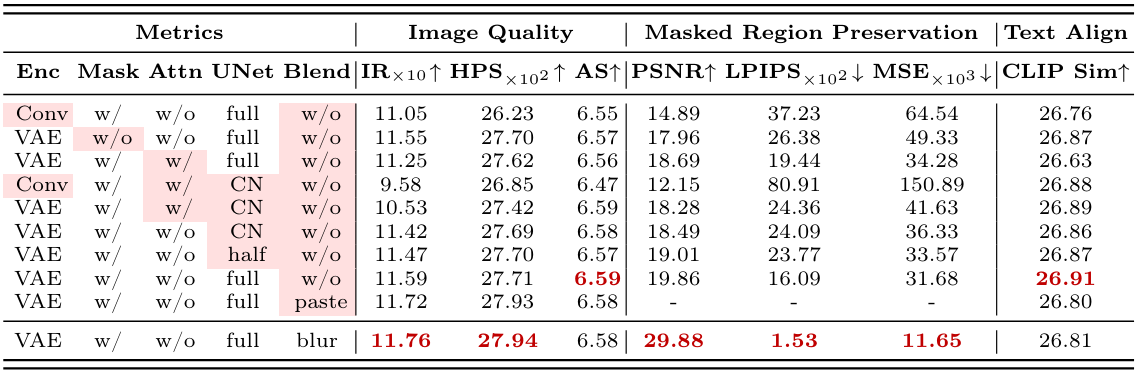
다음은 이중 branch 디자인에 대한 ablation 결과이다.

다음은 모델 아키텍처에 대한 ablation 결과이다.