[논문리뷰] Break-A-Scene: Extracting Multiple Concepts from a Single Image
SIGGRAPH Asia 2023. [Paper] [Page] [Github]
Omri Avrahami, Kfir Aberman, Ohad Fried, Daniel Cohen-Or, Dani Lischinski
Google Research | The Hebrew University of Jerusalem | Tel Aviv University | Reichman University
2 Dec 2021
Introduction
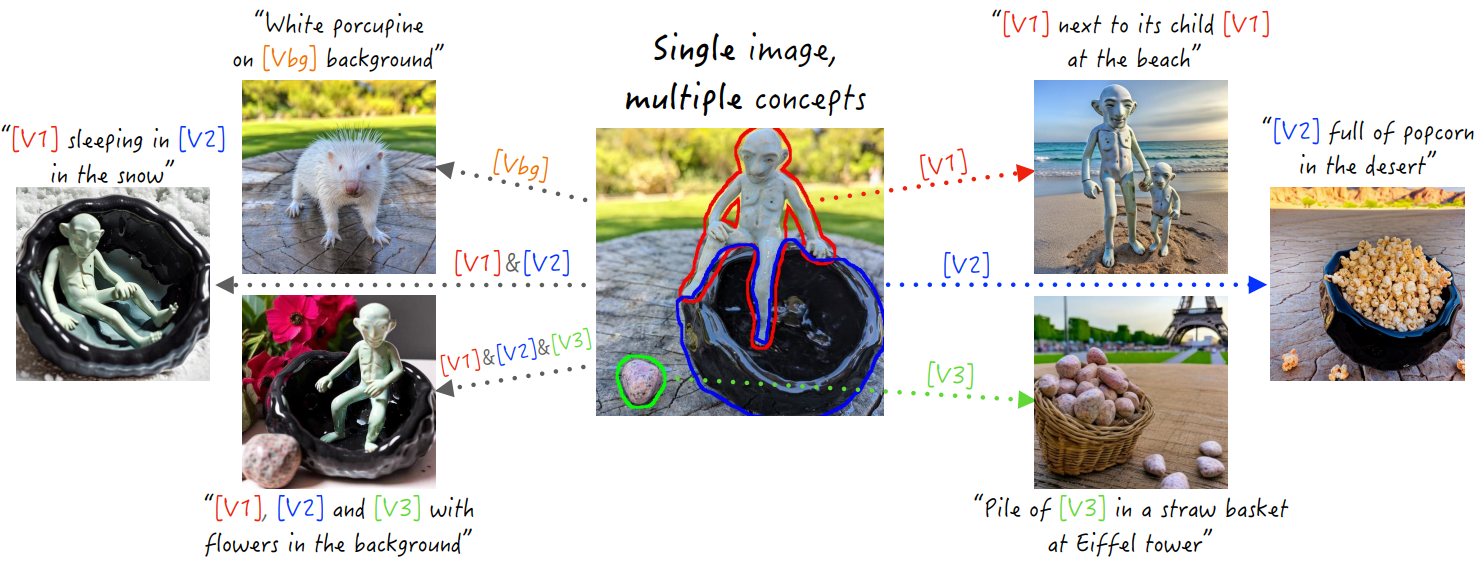
인간은 복잡한 장면을 구성 부분으로 분해하고 이를 다양한 맥락에서 상상하는 타고난 능력을 가지고 있다. 예를 들어, 그릇 위에 앉아 있는 생물을 묘사한 도자기 예술 작품 사진이 있으면 동일한 생물이 다양한 자세와 위치에 있는 것을 쉽게 상상하거나 동일한 그릇이 새로운 환경에 있는 것을 상상할 수 있다. 그러나 오늘날의 생성 모델은 이러한 유형의 task에 직면할 때 어려움을 겪는다.

Textual Inversion (TI)와 DreamBooth (DB)에서는 대규모 text-to-image 모델의 개인화가 제안되었다. 단일 개념의 여러 이미지가 제공되면 새로 추가된 전용 텍스트 임베딩을 최적화하거나 모델 가중치를 fine-tuning하여 새로운 맥락에서 이 개념의 인스턴스를 합성할 수 있다.
본 논문에서는 텍스트 장면 분해의 새로운 시나리오를 소개한다. 즉, 다양한 종류의 여러 개념을 포함할 수 있는 장면의 단일 이미지가 제공된다. 본 논문의 목표는 각 개념에 대한 전용 텍스트 토큰을 추출하는 것이다. 이를 통해 개별 개념이나 여러 개념의 조합을 특징으로 하는 텍스트 프롬프트에서 새로운 이미지를 생성할 수 있다.
개인화 task는 본질적으로 모호할 수 있다. 어떤 개념을 추출/학습하려는지 항상 명확하지 않다. 이전 연구들에서는 한 번에 하나의 개념을 추출하고 다양한 맥락에서 개념을 묘사하는 여러 가지 이미지를 활용하여 이러한 모호성을 해결했다. 그러나 단일 이미지 시나리오로 전환하는 경우 task를 명확하게 하기 위해 다른 수단이 필요하다. 구체적으로 본 논문은 추출하려는 개념을 나타내는 마스크 집합으로 입력 이미지를 강화할 것을 제안한다. 이러한 마스크는 사용자가 제공한 느슨한 마스크이거나 자동 분할 방법에 의해 생성될 수 있다. 그러나 두 가지 주요 접근 방식인 TI와 DB를 이 설정에 적용하면 재구성-편집 가능성 trade-off가 드러난다. TI는 새로운 컨텍스트에서 개념을 정확하게 재구성하지 못하는 반면 DB는 overfitting 때문에 컨텍스트를 제어하는 능력을 잃는다.
본 논문에서는 학습된 개념의 정체성 보존과 overfitting 방지의 균형을 효과적으로 유지하는 새로운 커스터마이징 파이프라인을 제안한다. 파이프라인은 두 단계로 구성된다. 첫 번째 단계에서는 전용 텍스트 토큰 (핸들) 집합을 지정하고, 모델 가중치를 고정하고, 핸들을 최적화하여 입력 이미지를 재구성한다. 두 번째 단계에서는 모델 가중치를 fine-tuning하는 동시에 핸들을 계속 최적화한다.
또한, 컨셉의 조합을 보여주는 이미지를 생성하기 위해 각 컨셉별로 개별적으로 커스터마이징 프로세스를 수행할 수 없다. 이러한 관찰을 통해 저자들은 이러한 요구 사항을 해결하고 개념 조합 생성을 향상시키는 학습 전략인 union-sampling을 도입하였다.
본 논문의 중요한 초점은 분리된 개념 추출, 즉 각 핸들이 하나의 대상 개념에만 연결되도록 하는 것이다. 이를 위해 각 커스텀 핸들이 지정된 개념을 생성할 수 있도록 보장하는 표준 diffusion loss의 마스킹된 버전을 사용한다. 그러나 이 loss는 핸들을 여러 개념과 연관시키는 모델에 페널티를 주지 않는다. 저자들의 주요 통찰력은 장면 레이아웃과 상관 관계가 있는 것으로 알려진 cross-attention map에 loss를 추가로 부과하여 이러한 entanglement에 페널티를 줄 수 있다는 것이다. 이러한 추가 loss로 인해 각 핸들은 대상 개념이 적용되는 영역에만 attend하게 된다.
Method
하나의 입력 이미지 $I$와 이미지의 관심 개념을 나타내는 $N$개의 마스크 집합 \(\{M_i\}_{i=1}^N\)이 주어지면 $N$개의 텍스트 핸들 \(\{v_i\}_{i=1}^N\)을 추출하는 것을 목표로 한다. 여기서 $i$번째 핸들 $v_i$는 $M_i$로 표시된 개념을 나타낸다. 결과 핸들은 텍스트 프롬프트에서 각 개념의 새로운 인스턴스 합성이나 여러 개념의 새로운 조합을 가이드하는 데 사용될 수 있다.
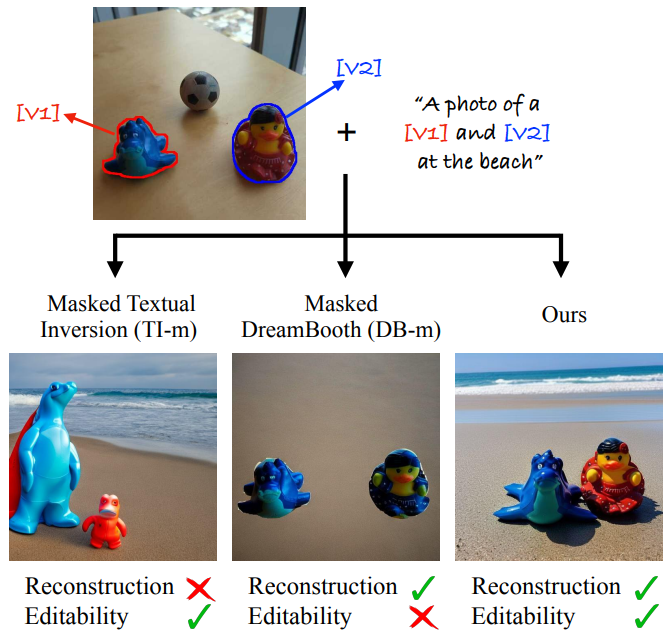
하나의 이미지에서 여러 개념을 추출하도록 TI 또는 DB를 적용하려는 시도는 본질적인 재구성-편집 가능성 trade-off를 드러낸다. 위 그림에서 볼 수 있듯이 TI는 추출된 개념을 새로운 컨텍스트에 포함할 수 있지만 해당 정체성을 충실하게 유지하지 못하는 반면, DB에서 모델을 fine-tuning하면 편집 가능성을 잃는 대신 가이드하는 텍스트 프롬프트를 따르지 못하는 지점까지 정체성을 캡처한다. 저자들은 개별 토큰만을 최적화하는 것은 좋은 재구성을 위해 표현력이 충분하지 않은 반면, 단일 이미지를 사용하여 모델을 fine-tuning하는 것은 overfitting에 매우 취약하다는 것을 관찰했다. 본 논문에서는 두 세계의 장점을 결합하는 “중간 수준” 솔루션을 위해 노력하였다. 즉, 편집 가능성을 포기하지 않고 대상 개념의 정체성을 포착할 수 있다. 본 논문의 접근 방식은 아래 그림에 나와 있고 네 가지 주요 구성 요소를 결합하였다.
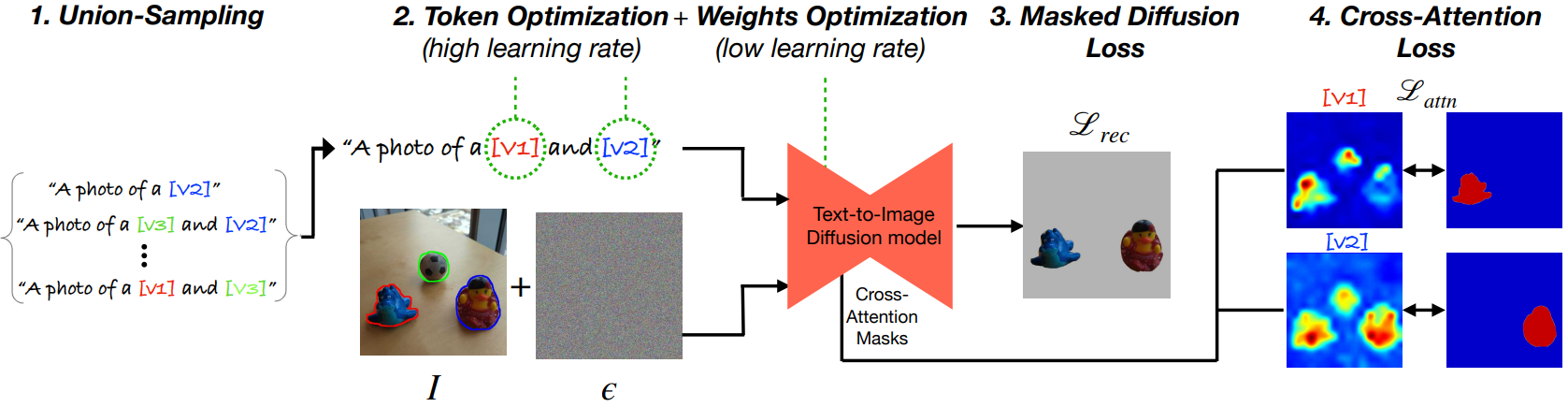
재구성과 편집 가능성 사이의 균형: 텍스트 임베딩과 모델 가중치를 모두 최적화하지만 이를 두 가지 다른 단계로 진행한다. 첫 번째 단계에서는 모델이 고정되고 마스킹된 개념에 해당하는 텍스트 임베딩이 높은 learning rate를 사용하여 최적화된다. 따라서 모델의 일반성을 손상시키지 않고 초기 근사 임베딩이 빠르게 달성되며, 이는 다음 단계의 좋은 시작점이 된다. 두 번째 단계에서는 상당히 낮은 learning rate를 사용하여 모델 가중치를 고정 해제하고 텍스트 토큰과 함께 최적화한다. 가중치와 토큰을 부드럽게 fine-tuning하면 편집 가능성 저하를 최소화하면서 새로운 맥락에서 추출된 개념을 충실하게 재구성할 수 있다.
Union-sampling: 또한 위의 프로세스에서 각 개념을 개별적으로 고려하는 경우 결과 커스터마이징된 모델은 여러 개념의 조합을 나타내는 이미지를 생성하는 데 어려움을 겪는다. 따라서 저자들은 두 가지 최적화 단계 각각에 대해 union-sampling을 제안하였다. 구체적으로 마스크 $M_i$로 표시된 각 개념에 대해 초기 텍스트 임베딩 (핸들) $v_i$를 지정하는 것으로 시작한다. 다음으로, 각 학습 단계에서 개념의 하위 집합인 \(s = \{i_1, \ldots, i_k\} \subseteq [N]\)를 랜덤하게 선택하고 ($k \le N$), 텍스트 프롬프트 “a photo of $[v_{i_1}]$ and $\ldots [v_{i_k}]$”를 구성한다. 그런 다음 최적화 loss는 해당 마스크의 합집합인 \(M_s = \cup M_{i_k}\)과 관련하여 계산된다.
Masked diffusion loss: 핸들과 두 번째 단계의 모델 가중치는 표준 diffusion loss의 마스킹된 버전을 사용하여 최적화된다. 즉, 개념 마스크로 덮힌 픽셀에 대해서만 페널티를 적용하여 최적화된다.
\[\begin{equation} \mathcal{L}_\textrm{rec} = \mathbb{E}_{z, s, \epsilon \sim \mathcal{N}(0,1), t} [\| \epsilon \odot M_s - \epsilon_\theta (z_t, t, p_s) \odot M_s \|_2^2] \end{equation}\]여기서 $z_t$는 timestep $t$의 noisy latent, $p_s$는 텍스트 프롬프트, $M_s$는 해당 마스크의 합집합, $\epsilon$은 추가된 noise, $\epsilon_\theta$는 denoising network이다. 픽셀 공간에서 마스킹된 diffusion loss를 사용하면 프로세스가 개념을 충실하게 재구성할 수 있지만 단일 핸들을 여러 개념과 연관시키는 데에는 페널티가 부과되지 않는다. 따라서 이 loss만으로는 결과 핸들이 해당 개념을 깔끔하게 분리하는 데 실패한다.

이 문제의 원인을 이해하려면 위 그림의 상단에 시각화된 것처럼 학습된 핸들과 생성된 이미지 간의 cross-attention map을 조사하는 것이 도움이 된다. 두 핸들 $[v_1]$과 $[v_2]$ 모두 각 핸들이 하나의 개념에만 attend하는 대신 생성된 이미지에서 두 가지 개념을 포함하는 영역의 합집합에 attend하는 것을 볼 수 있다.
Cross-Attention loss: 따라서 모델이 학습된 개념의 픽셀을 재구성할 뿐만 아니라 각 핸들이 해당 개념이 차지하는 이미지 영역에만 attend하도록 보장하는 또 다른 loss 항을 도입한다. 새로 추가된 토큰에 대한 cross-attention map을 활용하고 입력 마스크에서 MSE 편차에 페널티를 적용한다. 두 학습 단계 모두에서 loss에 다음 항을 추가한다.
\[\begin{equation} \mathcal{L}_\textrm{attn} = \mathbb{E}_{z, k, t} [\| \textrm{CA}_\theta (v_i, z_t) - M_{i_k} \|_2^2] \end{equation}\]여기서 \(\textrm{CA}_\theta (v_i, z_t)\)는 토큰 $v_i$와 noisy latent $z_t$ 사이의 cross-attention map이다. Cross-attention map은 denoising UNet 모델의 여러 레이어에 걸쳐 계산된다. 따라서 사용된 총 loss는 다음과 같다.
\[\begin{equation} \mathcal{L}_\textrm{total} = \mathcal{L}_\textrm{rec} + \lambda_\textrm{attn} \mathcal{L}_\textrm{attn} \end{equation}\]여기서 \(\lambda_\textrm{attn} = 0.01\)이다. 위 그림의 하단에서 볼 수 있듯이 loss에 \(\mathcal{L}_\textrm{attn}\)을 추가하면 $[v_1]$과 $[v_2]$가 생성된 이미지의 적절한 공간 위치에 해당하는 두 개의 개별 영역에 attend하도록 보장하는 데 성공한다.
Experiments
저자들은 의미있는 비교를 위해 다른 방법들을 본 논문의 문제 설정에 적응시켰다.

저자들은 위 그림과 같이 여러 개념 마스크가 있는 단일 입력 이미지를 이미지-텍스트 쌍의 작은 컬렉션으로 변환하였다. 특히 각 쌍은 개념 하위 집합 $i_1, \ldots, i_k$을 무작위로 선택하여 구성된다. 저자들은 random flip augmentation을 사용하여 랜덤한 단색 배경에 배치하였으며, 각 이미지와 함께 제공되는 텍스트 프롬프트는 “a photo of $[v_{i_1}]$ and $\ldots [v_{i_k}]$”이다. 이와 같은 컬렉션에서 학습된 DB와 TI를 각각 DB-m과 TI-m로 부른다.
1. Comparisons
다음은 여러 방법들과 정성적으로 비교한 결과이다.

다음은 정량적 비교 결과이다.
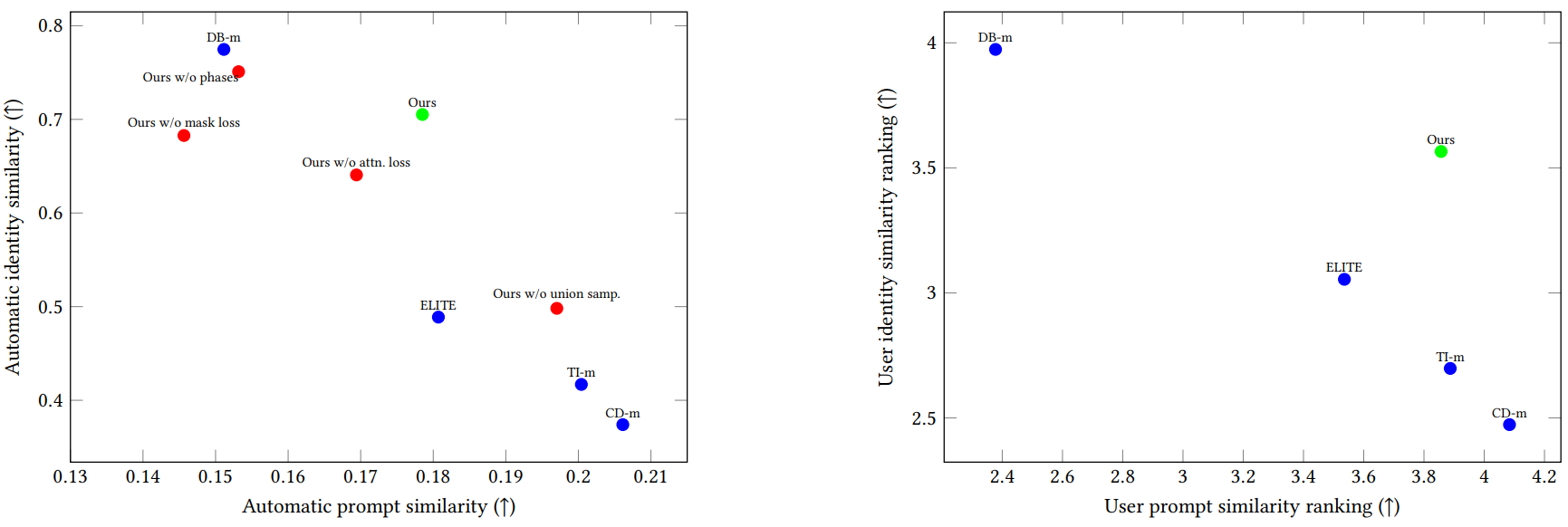
다음은 정성적 ablation 결과이다.

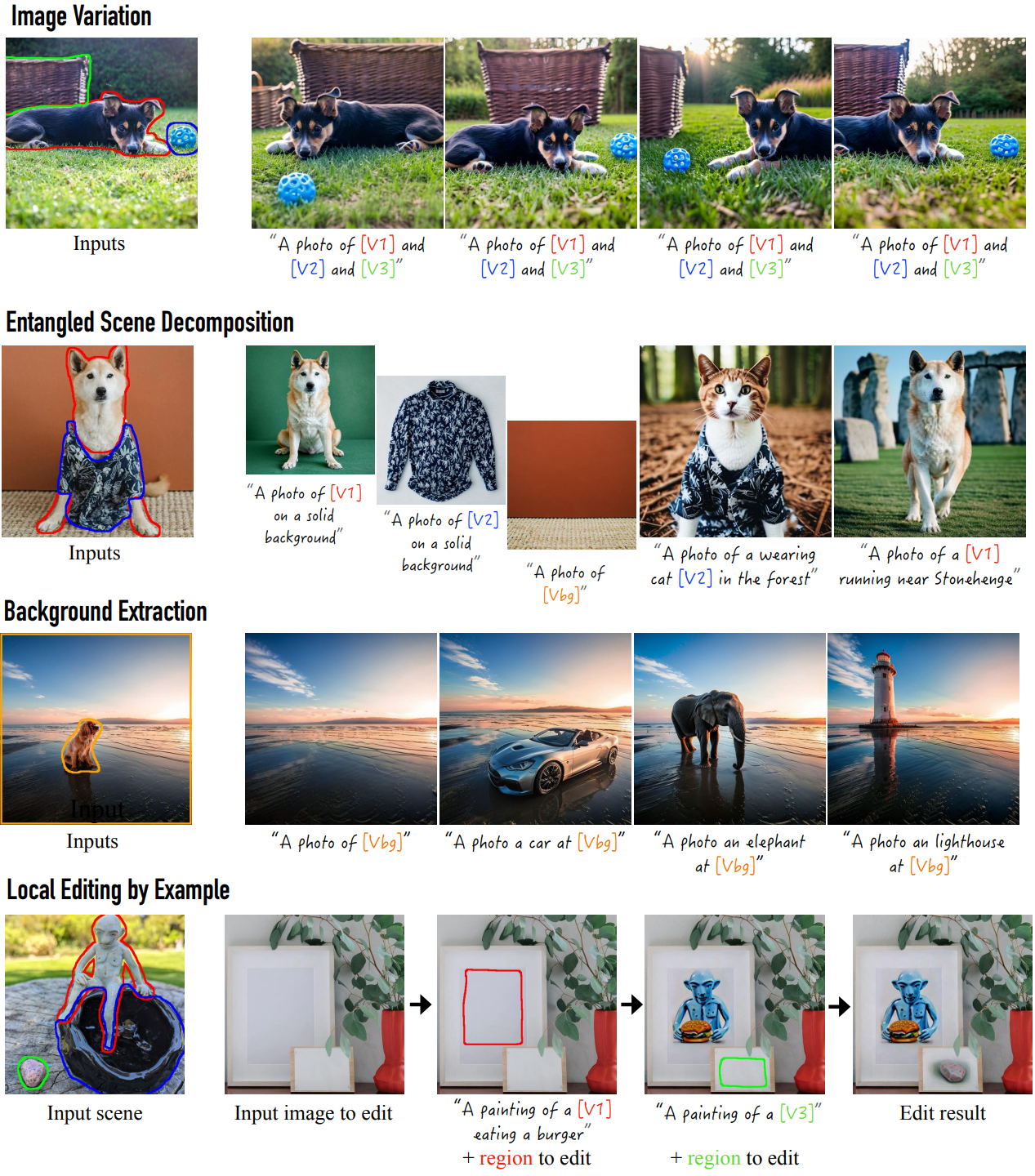
2. Applications
다음은 여러 다운스트림 task에 대하여 본 논문의 방법을 적용한 것이다.
Limitations

- 일관되지 않은 조명: 입력이 단일 이미지이기 때문에 학습된 정체성들에서 조명을 분리하는 데 때때로 어려움을 겪는다.
- 고정된 포즈: 단일 입력이므로 모델이 개체의 포즈와 개체의 정체성 사이를 얽히게 만드는 방법을 학습하는 경우가 있다.
- 여러 개념의 underfitting: 최대 네 가지 개념이 주어졌을 때 가장 효과적이며, 많은 개념에 대해서는 학습에 어려움을 겪는다.
- 상당한 계산 비용과 파라미터 사용: 하나의 장면에서 개념을 추출하고 전체 모델을 fine-tuning하는 데 약 4.5분이 소요된다.