[논문리뷰] BlockDance: Reuse Structurally Similar Spatio-Temporal Features to Accelerate Diffusion Transformers
CVPR 2025. [Paper] [Page] [Github]
Hui Zhang, Tingwei Gao, Jie Shao, Zuxuan Wu
Fudan University | ByteDance Intelligent Creation
20 Mar 2025

Introduction
DiT는 놀라운 성능에도 불구하고 반복적인 denoising process로 인해 inference 속도가 느리다. 기존 가속 방법은 주로 두 가지 패러다임에 초점을 맞춘다.
- 새로운 스케줄러 설계 또는 step distillation을 통해 샘플링 step 수를 줄인다.
- 모델 pruning, 모델 distillation, 중복 계산 완화를 사용하여 step당 계산 오버헤드를 최소화한다.
본 논문은 중복 계산을 완화하여 DiT를 가속화하는 것을 목표로 하였다. 이 패러다임은 다양한 모델과 task에 plug-and-play가 가능하다. Feature 중복성은 비전 task에서 널리 사용되며, 최근 diffusion model의 denoising process에서 그 존재를 확인했지만 DiT 내의 feature 중복성과 이 중복 계산을 완화하기 위한 잠재적 전략은 여전히 다뤄지지 않았다.
이를 위해 저자들은 인접한 timestep에서 DiT 블록 간의 feature 간 거리를 다시 살펴보고, 매우 유사한 feature를 캐싱하고 재사용하여 중복 계산을 줄이는 학습이 필요 없는 가속 방법인 BlockDance를 제안하였다. 이전의 feature 재사용 방법은 유사도 수준이 다른 다양한 스케일의 feature에 대한 맞춤형 재사용 전략이 부족하다. 결과적으로 종종 유사도가 낮은 feature가 재사용되어 이미지의 구조적 왜곡과 프롬프트와의 정렬 불량이 발생한다.
반면 BlockDance는 재사용 전략을 강화하고 가장 유사한 feature, 즉 구조적으로 유사한 시공간적 feature에 초점을 맞추었다. 구체적으로, denoising process 동안 구조적 콘텐츠는 일반적으로 noise level이 높은 초기 step에서 생성되는 반면, 텍스처 및 디테일한 콘텐츠는 noise level이 낮은 후속 step에서 자주 생성된다. 따라서 구조가 안정화되면 구조적 feature가 최소한의 변화를 겪을 것이라고 가설을 세울 수 있다.
이 가설을 검증하기 위해, 저자들은 다양한 스케일에서 DiT의 feature를 분리하였다. 관찰 결과, coarse한 구조적 콘텐츠에 집중하는 얕은 블록과 중간 블록은 인접한 step에서 최소한의 변화를 보인다. 반면에, 세밀한 텍스처와 복잡한 패턴을 우선시하는 깊은 블록은 더 눈에 띄는 변화를 보인다. 따라서 저자들은 구조적으로 안정화된 이후에 매우 유사한 구조적 feature를 캐싱하고 재사용하여 DiT를 가속화하는 동시에 원래 모델의 생성된 결과와의 일관성을 극대화하는 전략을 제안하였다.
본 논문은 생성된 콘텐츠의 다양한 특성과 중복된 feature의 다양한 분포를 고려하여 BlockDance에 맞게 조정된 가벼운 의사결정 네트워크인 BlockDance-Ada를 도입하였다. 물체 수가 제한된 간단한 콘텐츠에서 중복된 feature가 더 많이 나타난다. 따라서 이러한 시나리오에서 빈번한 feature 재사용은 만족스러운 결과를 얻는 동시에 가속 이점을 증가시키기에 충분하다. 반대로, 수많은 물체와 복잡한 상호 관계를 특징으로 하는 경우 재사용 가능한 높은 유사도의 feature가 적다.
이 적응 전략을 학습시키는 것은 미분 불가능한 의사결정 프로세스를 포함하기 때문에, BlockDance-Ada는 강화 학습 프레임워크를 기반으로 구축되었다. BlockDance-Ada는 policy gradient 방법을 사용하여 프롬프트와 중간 latent를 기반으로 feature를 캐싱하고 재사용하는 전략을 구동하여 품질을 유지하면서 계산을 최소화하도록 하는 신중하게 설계된 reward function을 극대화한다. 따라서 BlockDance-Ada는 리소스를 적응적으로 할당할 수 있다.
Method
1. Feature Similarity and Redundancy in DiTs
DiT의 inference 속도는 본질적으로 반복적인 특성에 의해 제한된다. 본 논문은 중복 계산을 줄여 DiT를 가속화하는 것을 목표로 한다.
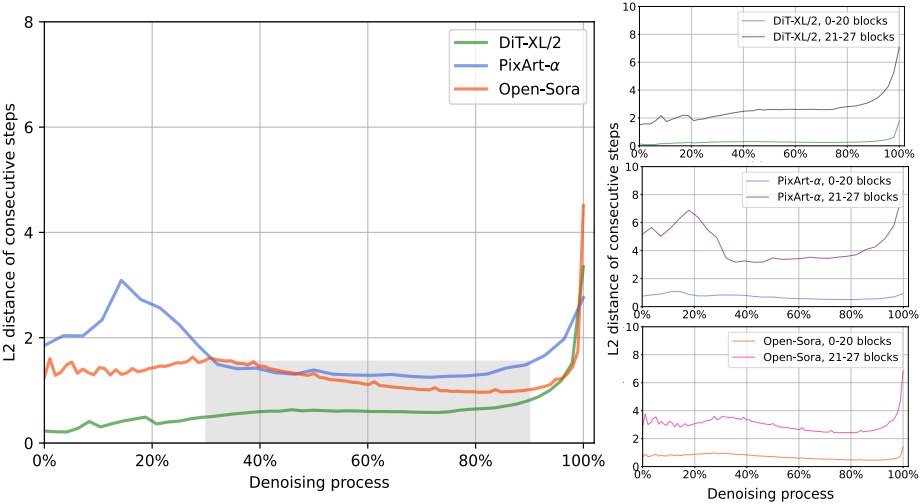
DiT-XL/2, PixArt-α, Open-Sora를 포함한 다양한 DiT 모델에서 denoising process를 다시 살펴보면 두 가지 주요 결과가 나타났다.
- 연속되는 step 간에 상당한 feature 유사성이 있어 denoising process에서 중복된 계산이 있었음을 알 수 있다.
- 이 높은 유사성은 주로 transformer의 얕고 중간 블록(0~20)에서 나타나는 반면, 더 깊은 블록(21~27)은 더 많은 변형을 보인다.
이 현상은 구조적 콘텐츠가 일반적으로 초기 step에서 생성되는 반면 텍스처와 디테일은 나중 단계에서 생성되기 때문이다.

이를 확인하기 위해, 저자들은 PCA를 사용하여 PixArt-α의 블록 feature를 시각화하였다. 초기 denoising step에서 네트워크는 주로 인간 포즈와 기타 기본 형태와 같은 구조적 콘텐츠를 생성하는 데 중점을 둔다. Denoising process가 진행됨에 따라 네트워크의 얕은 블록과 중간 블록은 여전히 저주파 구조적 콘텐츠를 생성하는 데 집중하는 반면, 더 깊은 블록은 구름이나 군중과 같은 더 복잡한 고주파 텍스처 정보를 생성하는 데 중점을 둔다.
결과적으로 구조가 확립된 후 위 그림에서 파란색 상자로 강조 표시된 feature map은 인접한 step에서 높은 일관성을 보인다. 이 계산을 중복 계산으로 정의하고, 이러한 매우 유사한 feature를 활용하여 중복 계산을 줄이고 denoising process를 가속화하는 전략을 설계할 수 있다.
2. Training-free acceleration approach
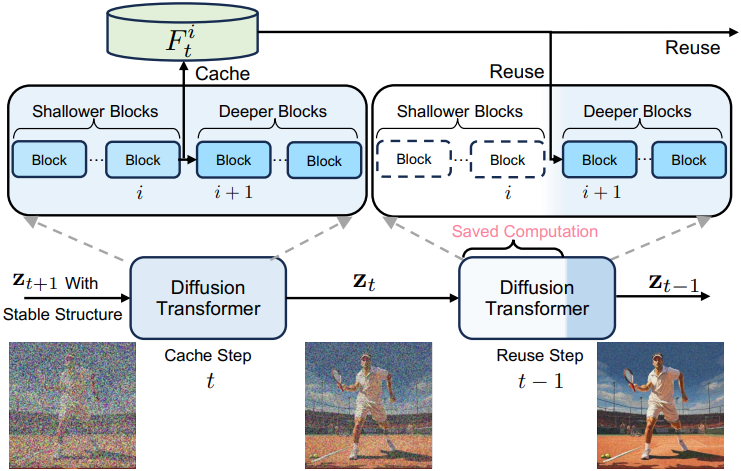
본 논문은 denoising process의 step 간의 feature 유사성을 활용하여 DiT를 가속화하는 간단하면서도 효과적인 방법인 BlockDance를 소개한다. 매우 유사한 구조적 feature를 전략적으로 캐싱하고 후속 step에서 재사용함으로써 중복된 계산을 줄일 수 있다.
구체적으로, denoising step을 cache step과 reuse step의 두 가지 유형으로 설계하였다. 연속적인 timestep 동안, cache step는 먼저 \(\textbf{z}_{t+1}\)에 기반하여 전체 네트워크 forward를 수행하여 \(\textbf{z}_t\)를 출력하고, $i$번째 블록의 feature $F_t^i$를 저장한다. 그 다음 timestep인 reuse step에서는 전체 네트워크 forward를 수행하지 않고, cache step의 캐싱된 feature $F_t^i$를 reuse step의 $(i + 1)$번째 블록에 대한 입력으로 재사용한다. 따라서 reuse step의 처음 $i$개 블록의 계산은 저장될 수 있으며, $i$보다 더 깊은 블록만 재계산이 필요하다.
이를 위해 최적의 블록 인덱스와 재사용을 집중해야 하는 denoising process의 step을 결정하는 것이 중요하다. 저자들은 앞에서의 분석들을 기반으로 인덱스를 20으로 설정하고 구조가 안정화된 후 denoising process의 후반 60%에 재사용을 집중하였다. 이러한 설정을 통해 feature 재사용을 분리하고 특히 구조적으로 유사한 시공간적 feature를 재사용할 수 있다.
구체적으로, denoising step의 처음 40%를 cache step로 설정하고 나머지 60%를 각각 $N$개의 step으로 구성된 여러 그룹으로 균등하게 나눈다. 각 그룹의 첫 번째 step은 cache step이고, 이후 $N-1$개의 step은 reuse step이다. 새로운 그룹이 도착하면 새로운 cache step이 캐싱된 feature를 업데이트한 다음, 해당 그룹 내의 reuse step에 활용한다. 이 프로세스는 denoising process가 완료될 때까지 반복된다. $N$이 클수록 재사용 빈도가 높아진다. 이러한 전략을 BlockDance-N이라고 부른다. 이 전략은 학습이 필요 없으며 생성된 콘텐츠의 품질을 유지하면서도 여러 유형의 DiT를 효과적으로 가속화할 수 있다.
3. Instance-specific acceleration approach
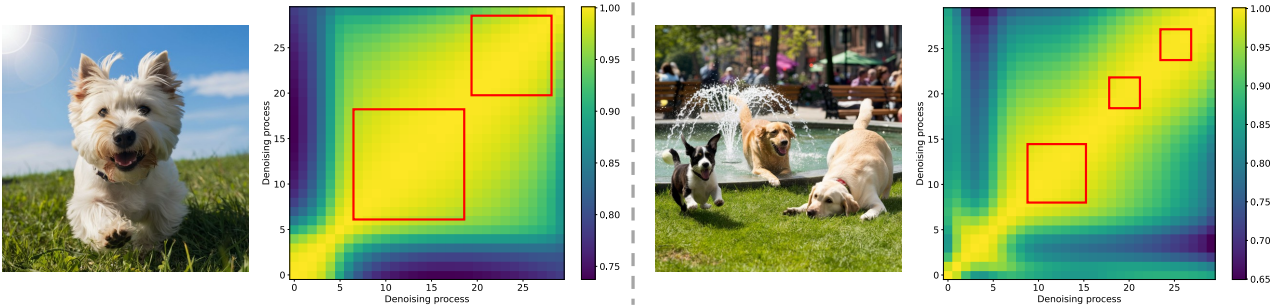
그러나 생성된 콘텐츠는 위 그림에서 볼 수 있듯이 다양한 feature 유사도 분포를 보인다. 저자들은 유사한 feature의 분포가 생성된 콘텐츠의 구조적 복잡성과 관련이 있음을 발견했다. 구조적 복잡성이 증가함에 따라 재사용에 적합한 유사한 feature의 수가 감소한다. 본 논문은 BlockDance 전략을 개선하기 위해 인스턴스별 캐싱 및 재사용 전략을 학습하는 가벼운 프레임워크인 BlockDance-Ada를 도입하였다.
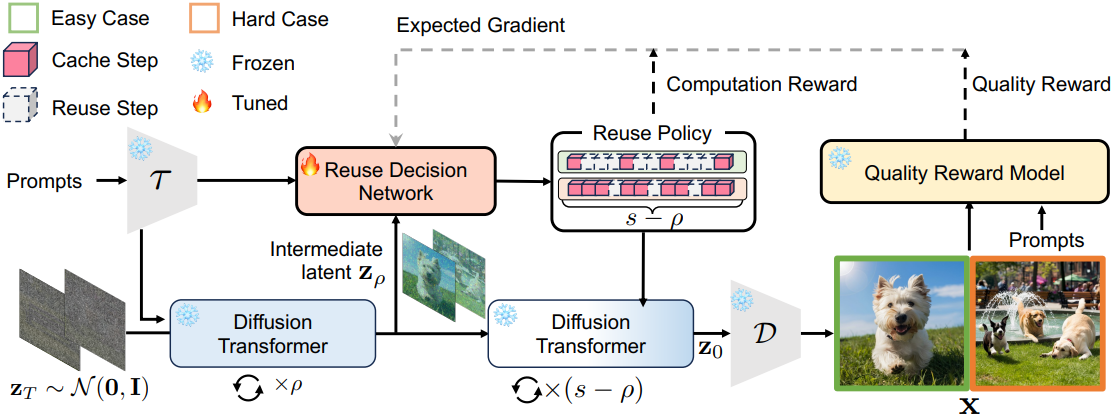
BlockDance-Ada는 강화 학습을 활용하여 미분 불가능한 이진 결정을 처리하여 denoising process의 각 단계가 cache step인지 reuse step인지 동적으로 판별한다. 총 $s$개의 denoising step에 대해 latent \(\textbf{z}_T \sim \mathcal{N}(0,I)\)와 프롬프트 $\textbf{p}$의 텍스트 임베딩 $\textbf{c} = \tau (\textbf{p})$가 주어지면 처음에는 $\rho$개의 cache step을 수행하여 중간 latent \(\textbf{z}_\rho\)를 얻는다.
State space는 \(\textbf{z}_\rho\)와 $\textbf{c}$로 정의되고, 의사결정 모델 내의 action은 나머지 $s − \rho$ step의 각 단계가 cache step인지 reuse step인지 판별하도록 정의된다. 파라미터가 $w$인 의사결정 네트워크 $f_d$는 feature 유사도 분포를 학습한 다음, 이를 벡터 $m \in \mathbb{R}^{(s−\rho)}$에 매핑한다.
\[\begin{equation} \textbf{m} = \textrm{sigmoid}(f_d (\textbf{z}_\rho, \textbf{c}; \textbf{w})) \end{equation}\]여기서 $m$의 각 entry는 [0, 1] 범위 내에 있도록 정규화되어 cache step를 수행할 가능성을 나타낸다. 저자들은 다음과 같이 $(s − \rho)$차원 베르누이 분포를 갖는 reuse policy $\pi^f (\textbf{u} \vert \textbf{z}_\rho, \textbf{c})$를 정의하였다.
\[\begin{equation} \pi^f (\textbf{u} \vert \textbf{z}_\rho, \textbf{c}) = \prod_{t=1}^{s-\rho} \textbf{m}_t^{\textbf{u}_t} (1 - \textbf{m}_t)^{1 - \textbf{u}_t} \end{equation}\](\(\textbf{u} \in \{0, 1\}^{(s-\rho)}\)는 $m$에 기반한 action, \(\textbf{u}_t = 1\)과 \(\textbf{u}_t = 0\)은 $t$번째 step이 각각 cache step과 reuse step임을 나타냄)
학습 중에 $\textbf{u}$는 해당 policy에서 샘플링하여 생성되고, 테스트 시에는 greedy 방식이 사용된다. DiT는 reuse policy에 따라 latent \(\textbf{z}_0\)을 생성하고, 디코더 $\mathcal{D}$가 latent를 이미지 $\textbf{x}$로 디코딩한다.
이를 바탕으로, 저자들은 이미지 품질을 유지하면서 계산 절감을 극대화하도록 $f_d$를 위한 reward function을 설계하였다. Reward function은 두 가지 부분으로 구성된다.
- image quality reward $\mathcal{Q}(\textbf{u})$: quality reward model $f_q$를 사용하여 시각적 미학과 프롬프트 준수에 따라 생성된 이미지에 점수를 매긴다.
- computation reward $\mathcal{C}(\textbf{u})$: 다음 식에 따라 reuse step들의 정규화된 수로 정의된다.
전체 reward function은 다음과 같다.
\[\begin{equation} \mathcal{R} (\textbf{u}) = \mathcal{C} (\textbf{u}) + \lambda \mathcal{Q} (\textbf{u}) \end{equation}\]의사결정 네트워크 $f_d$는 reward의 기대값을 최대화하도록 최적화된다.
\[\begin{equation} \max_\textbf{w} \mathcal{L} = \mathbb{E}_{\textbf{u} \sim \pi^f} \mathcal{R} (\textbf{u}) \end{equation}\]Policy gradient 방법을 사용하여 $f_q$의 파라미터 $\textbf{w}$를 학습하고 gradient의 기대값은 다음과 같이 도출된다.
\[\begin{equation} \nabla_\textbf{w} \mathcal{L} = \mathbb{E}[\mathcal{R}(\textbf{u}) \nabla_\textbf{w} \log \pi^f (\textbf{u} \vert \textbf{z}_\rho, \textbf{c})] \end{equation}\]실제로는 mini-batch의 샘플을 사용하여 위 식을 다음과 같이 근사한다.
\[\begin{equation} \nabla_\textbf{w} \mathcal{L} \approx \frac{1}{B} \sum_{i=1}^B [\mathcal{R}(\textbf{u}_i) \nabla_\textbf{w} \log \pi^f (\textbf{u}_i \vert \textbf{z}_{\rho_i}, \textbf{c}_i)] \end{equation}\]그런 다음 gradient를 다시 전파하여 $f_d$를 학습시킨다. 이 학습 프로세스에 따라 의사결정 네트워크는 인스턴스별 캐싱 및 재사용 전략을 인식하여 효율적인 동적 inference가 가능해진다.
Experiments
- 모델
- 클래스 조건부 이미지 생성: DiT-XL/2
- 해상도: 512$\times$512
- 샘플러: DDIM
- Text-to-Image 생성: PixArt-α
- 해상도: 1024$\times$1024
- 샘플러: DPMSolver (guidance scale = 4.5)
- Text-to-Video 생성: Open-Sora 1.0
- 해상도: 512$\times$512, 16 프레임
- 샘플러: DDIM (guidance scale = 7.0)
- 클래스 조건부 이미지 생성: DiT-XL/2
- 구현 디테일
- BlockDance
- PixArt-α: 전체 denoising step의 40% ~ 95%에 적용
- DiT-XL/2, Open-Sora: 전체 denoising step의 25% ~ 95%에 적용
- 블록 인덱스: $i = 20$
- BlockDance-Ada
- $\rho$: 전체 denoising step 수의 40%
- $\lambda$: 2
- optimizer: Adam
- learning rate: $10^{-5}$
- 학습 데이터셋 중 10,000개의 부분집합에 대해 100 epoch 학습
- BlockDance
1. Main Results
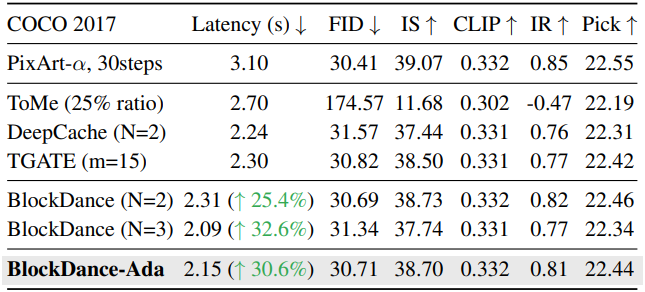
다음은 PixArt-α에 대한 text-to-image 생성 결과를 비교한 표이다.
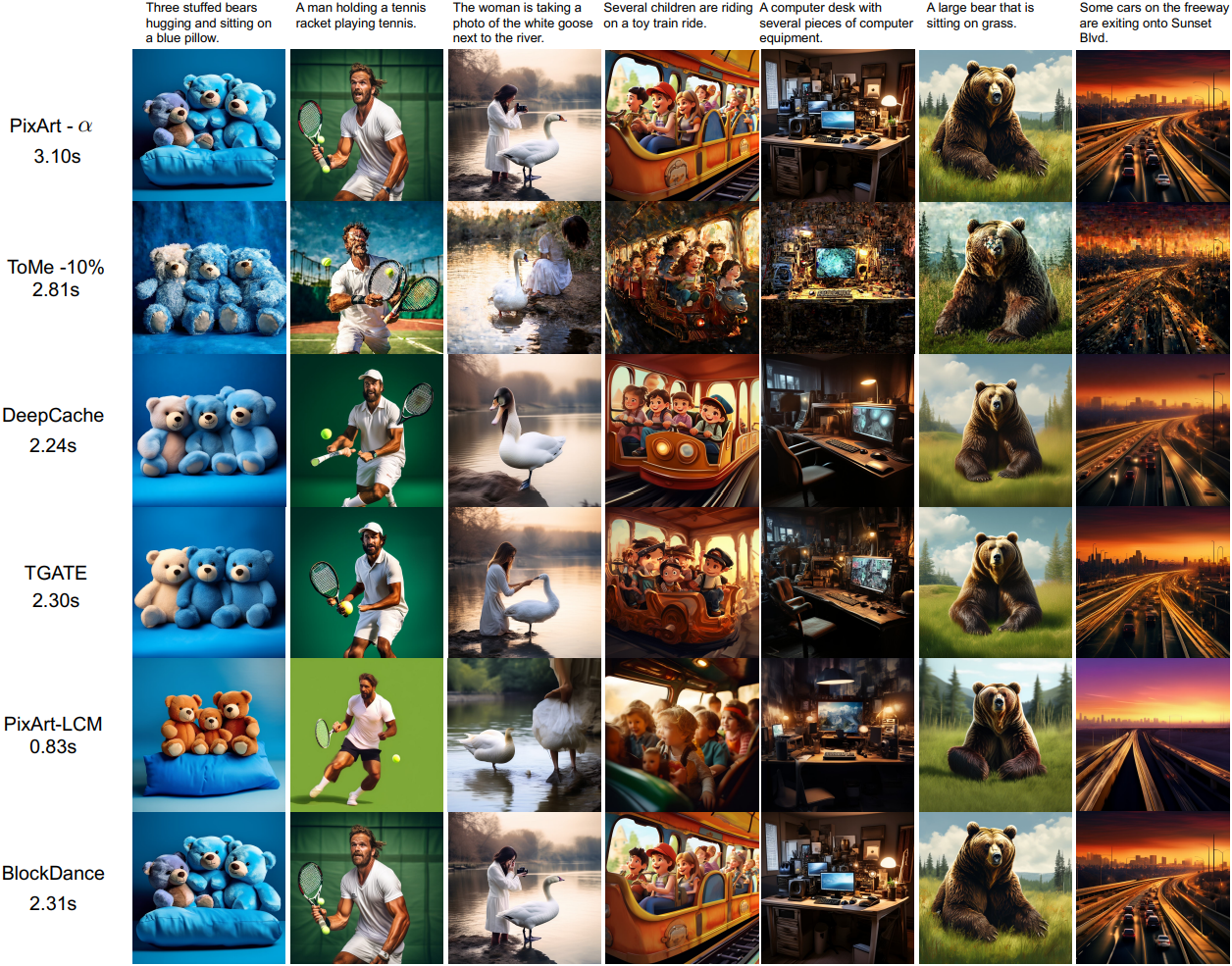
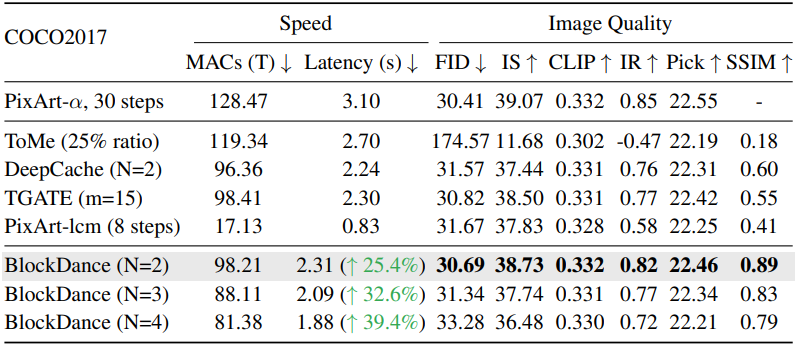
다음은 DiT/XL-2에 대한 클래스 조건부 이미지 생성 결과를 비교한 표이다.
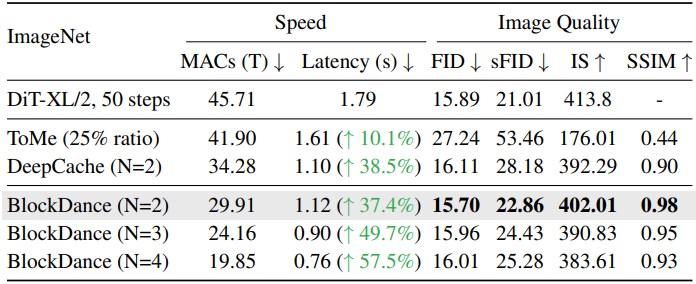
다음은 Open-Sora에 대한 text-to-video 생성 결과를 비교한 표이다.
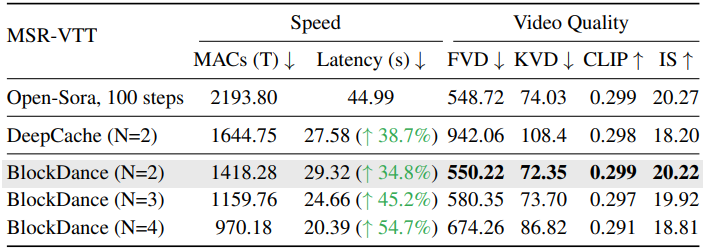
다음은 PixArt-α에 대한 BlockDance-Ada의 성능을 비교한 표이다.
2. Ablation Study
다음은 재사용 빈도에 대한 ablation 결과이다.

다음은 BlockDance를 적용하는 denoising step에 대한 ablation 결과이다.

다음은 재사용하는 블록 깊이에 대한 ablation 결과이다.

Limitation
Denoising step 수가 매우 적은 (1 ~ 4 step) 모델은 인접한 step들 사이의 유사도가 감소하여 BlockDance를 적용하는 데 한계가 있다.