[논문리뷰] Block-NeRF: Scalable Large Scene Neural View Synthesis
CVPR 2022. [Paper] [Page]
Matthew Tancik, Vincent Casser, Xinchen Yan, Sabeek Pradhan, Ben Mildenhall, Pratul P. Srinivasan, Jonathan T. Barron, Henrik Kretzschmar
UC Berkeley | Waymo | Google Research
10 Feb 2022

Introduction
NeRF와 같은 뉴럴 렌더링의 최근 발전으로 포즈를 아는 카메라 이미지셋을 바탕으로 사실적인 재구성과 novel view synthesis가 가능해졌다. 이전 연구들은 소규모 및 물체 중심 재구성에 초점을 맞추는 경향이 있었다. 일부 방법들은 하나의 방이나 건물 크기의 장면을 처리하지만 일반적으로 여전히 제한적이며 순전히 도시 규모 환경으로 확장되지 않았다. 대규모 환경에 이러한 방법을 적용하면 일반적으로 제한된 모델 용량으로 인해 상당한 아티팩트가 발생하고 시각적 충실도가 낮아진다.
대규모 환경을 재구성하면 자율 주행과 항공 측량과 같은 도메인에서 몇 가지 중요한 사용이 가능해진다. 한 가지 예시는 로봇 위치 파악, 내비게이션 및 충돌 회피를 포함한 다양한 문제에 대하여 강력한 prior 역할을 하기 위해 전체 운영 영역에 대한 충실도가 높은 맵을 생성하는 매핑이다. 또한 closed-loop 로봇 시뮬레이션을 위해 대규모 장면 재구성을 사용할 수 있다. 자율 주행 시스템은 일반적으로 이전에 발생한 시나리오를 다시 시뮬레이션하여 평가된다. 그러나 기록에서 벗어나면 차량의 궤적이 변경될 수 있으므로 변경된 경로를 따라 충실도가 높고 새로운 뷰 렌더링이 필요하다. 기본 뷰 합성 외에도 장면 조절 NeRF는 카메라 노출, 날씨 또는 시간과 같은 환경 조명 조건을 변경할 수도 있으며, 이는 시뮬레이션 시나리오를 더욱 강화하는 데 사용할 수 있다.
이러한 대규모 환경을 재구성하면 임시 개체(자동차, 보행자)의 존재, 모델 용량 제한, 메모리 및 컴퓨팅 제약 조건 등 추가적인 문제가 발생한다. 또한 이러한 대규모 환경에 대한 학습 데이터는 일관된 조건에서 단일 캡처로 수집될 가능성이 거의 없다. 오히려 환경의 다양한 부분에 대한 데이터는 다양한 데이터 수집 노력을 통해 소스로 제공되어야 하며 장면 형상과 외형에 차이가 발생할 수 있다.
저자들은 수집된 데이터의 환경 변화와 포즈 오차를 해결하기 위해 모양 임베딩과 학습된 포즈 개선을 통해 NeRF를 확장하였다. Inference 중에 노출(exposure)을 수정하는 기능을 제공하기 위해 노출 조건을 추가로 추가한다. 이 수정된 모델을 Block-NeRF라고 부른다. Block-NeRF의 네트워크 용량을 확장하면 점점 더 큰 장면을 표현할 수 있다. 그러나 이 접근 방식에는 여러 가지 제한 사항이 있다. 렌더링 시간은 네트워크 크기에 따라 증가하고, 네트워크는 더 이상 단일 컴퓨팅 장치에 적합하지 않으며, 환경을 업데이트하거나 확장하려면 전체 네트워크를 재학습해야 한다.
이러한 문제를 해결하기 위해 저자들은 대규모 환경을 개별적으로 학습된 Block-NeRF로 분할한 다음 inference 시 동적으로 렌더링하고 결합할 것을 제안하였다. 이러한 Block-NeRF를 독립적으로 모델링하면 유연성이 최대화되고 임의의 대규모 환경으로 확장되며 전체 환경을 재학습하지 않고도 조각별 방식으로 새로운 영역을 업데이트하거나 도입할 수 있게 된다. 타겟\ 뷰를 계산하려면 Block-NeRF의 부분 집합이 렌더링된 다음 카메라와 비교된 지리적 위치를 기반으로 합성된다. 저자들은 보다 원활한 합성을 위해 외형 임베딩을 최적화하여 다양한 Block-NeRF를 시각적 정렬로 가져오는 외형 매칭 기술을 제안하였다.
Method
단일 NeRF 학습은 도시만큼 큰 장면을 표현하려고 할 때 확장되지 않는다. 대신 저자들은 독립적으로 병렬로 학습하고 inference 중에 합성할 수 있는 Block-NeRF 집합으로 환경을 분할하는 것을 제안하였다. 이러한 독립성 덕분에 전체 환경을 재학습시키지 않고도 추가 Block-NeRF 또는 업데이트 블록을 사용하여 환경을 확장할 수 있다. 렌더링을 위해 관련 Block-NeRF를 동적으로 선택하고 장면을 탐색할 때 부드러운 방식으로 합성된다. 이 합성을 돕기 위해 조명 조건과 일치하도록 외형 코드를 최적화하고 각 Block-NeRF의 새로운 뷰까지의 거리를 기반으로 계산된 interpolation 가중치를 사용한다.
1. Block Size and Placement
개별 Block-NeRF는 대상 환경의 전체 범위를 전체적으로 보장하도록 배열되어야 한다. 저자들은 각 교차로에 일반적으로 하나의 Block-NeRF를 배치하여 교차로 자체와 연결된 거리가 다음 교차로로 수렴될 때까지 75%를 덮는다. 이로 인해 연결하는 거리 부분에 있는 인접한 두 블록 사이에 50%가 겹치게 되어 두 블록 사이의 외형 정렬이 더 쉬워진다. 이 절차를 따르면 블록 크기가 가변적이다. 필요한 경우 교차점 사이에 추가 블록을 도입할 수 있다. 저자들은 지리적 필터를 적용하여 각 블록의 학습 데이터가 의도한 범위 내에 정확하게 유지되도록 보장하였다. 이 절차는 자동화될 수 있으며 OpenStreetMap과 같은 기본 지도 데이터에만 의존한다.
전체 환경이 하나 이상의 Block-NeRF에 포함되는 한 다른 배치도 가능하다. 예를 들어, 일부 실험에서는 하나의 거리 세그먼트를 따라 균일한 거리에 블록을 배치하고 블록 크기를 Block-NeRF Origin 주변의 구형으로 정의하였다.
2. Training Individual Block-NeRFs
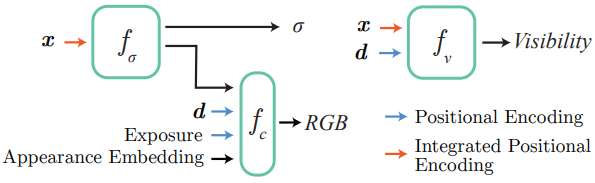
Appearance Embeddings
데이터의 서로 다른 부분이 서로 다른 환경 조건에서 캡처될 수 있다는 점을 고려하여 위 그림과 같이 NeRF-W를 따르고 Generative Latent Optimization을 사용하여 이미지별 외형 임베딩 벡터를 최적화한다. 이를 통해 NeRF는 날씨와 조명 등 여러 외형 변경 조건을 설명할 수 있다. 학습 데이터에서 관찰된 다양한 조건(ex. 흐린 하늘과 맑은 하늘, 낮과 밤) 사이를 interpolation하기 위해 이러한 외형 임베딩을 추가로 조작할 수 있다. 다양한 모양으로 렌더링하는 예시는 아래 그림에서 볼 수 있다. 이러한 임베딩에 대한 테스트 시간 최적화를 사용하여 인접한 Block-NeRF의 외형을 일치시킨다. 이는 여러 렌더링을 결합할 때 중요하다.

Learned Pose Refinement
카메라 포즈가 제공된다고 가정하지만 추가 정렬을 위해 정규화된 포즈 오프셋을 학습하는 것이 유리하다. 포즈 개선은 이전 NeRF 기반 모델에서 탐구되었다. 이러한 오프셋은 세그먼트별로 학습되며 translation 및 rotation 성분을 모두 포함한다. 저자들은 NeRF 자체와 함께 이러한 오프셋을 최적화하여 학습 초기 단계에서 오프셋을 상당히 정규화하여 네트워크가 포즈를 수정하기 전에 대략적인 구조를 먼저 학습할 수 있도록 하였다.
Exposure Input

학습 이미지는 광범위한 노출 레벨에서 캡처될 수 있으며, 이를 설명하지 않은 채 남겨두면 NeRF 학습에 영향을 미칠 수 있다. 저자들은 모델의 외형 예측 부분에 카메라 노출 정보를 제공하면 NeRF가 시각적 차이를 보상할 수 있음을 발견했다. 구체적으로 노출 정보는 \(\gamma_\textrm{PE}\) (셔터 속도 $\times$ 아날로그 gain / $t$)로 처리된다. 여기서 \(\gamma_\textrm{PE}\)는 4레벨의 sinusoidal positional encoding이고 $t$는 scaling factor(실제로 1,000 사용)이다. 다양한 학습된 노출의 예시는 위 그림과 같다.
Transient Objects
본 논문의 방법은 외형 임베딩을 사용하여 외형의 변화를 설명하지만 장면의 형상이 학습 데이터 전체에서 일관된다고 가정한다. 움직이는 물체(ex. 자동차, 보행자)는 일반적으로 이 가정을 위반한다. 따라서 semantic segmentation model(Panoptic-DeepLab)을 사용하여 일반적인 이동 가능한 물체의 마스크를 생성하고 학습 중에 마스킹된 영역을 무시한다. 이는 건설 현장과 같은 환경의 정적 부분의 변경 사항을 설명하지 않으며 가장 일반적인 유형의 기하학적 불일치를 수용한다.
Visibility Prediction
여러 Block-NeRF를 병합할 때 학습 중에 특정 NeRF에 특정 공간 영역이 표시되었는지 여부를 아는 것이 유용할 수 있다. 샘플링된 지점의 visibility에 대한 근사치를 학습한 추가적인 작은 MLP $f_v$를 사용하여 모델을 확장한다. 학습 광선을 따른 각 샘플에 대해 $f_v$는 위치와 시야 방향을 취하고 점의 해당 투과율을 회귀한다. 모델은 supervision을 제공하는 $f_\sigma$와 함께 학습된다. 투과율은 특정 입력 카메라에서 점이 얼마나 보이는지를 나타낸다. 비어있는 공간이나 처음 교차되는 물체의 표면에 있는 점은 1에 가까운 투과율을 가지며, 처음 보이는 물체 내부 또는 뒤에 있는 점은 0에 가까운 투과율을 갖는다. 일부 시점에서는 보이지만 다른 시점에서는 볼 수 없는 경우 회귀된 투과율 값은 모든 학습 카메라의 평균이 되며 0과 1 사이에 위치하여 해당 지점이 부분적으로 관찰되었음을 나타낸다.
Visibility 네트워크는 규모가 작으며 색상 및 밀도 네트워크와 독립적으로 실행될 수 있다. 이는 특정 NeRF가 주어진 위치에 대해 의미 있는 출력을 생성할 가능성이 있는지 여부를 결정하는 데 도움이 될 수 있으므로 여러 NeRF를 병합할 때 유용하다. Visibility 예측은 두 NeRF 간의 외형 일치를 수행하기 위한 위치를 결정하는 데에도 사용될 수 있다.
3. Merging Multiple Block-NeRFs
Block-NeRF Selection
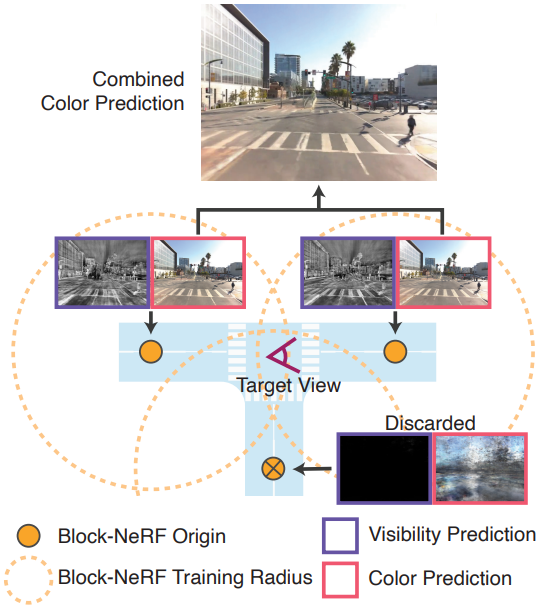
환경은 임의의 수의 Block-NeRF로 구성될 수 있다. 효율성을 위해 두 가지 필터링 메커니즘을 사용하여 주어진 타겟 뷰에 대한 관련 블록만 렌더링한다. 대상 시점의 설정된 반경 내에 있는 Block-NeRF만 고려한다. 또한 이러한 각 후보에 대해 visibility를 계산한다. 평균 visibility가 threshold보다 낮으면 Block-NeRF를 제거한다. 위 그림은 visibility 필터링의 예시이다. Visibility는 해당 네트워크가 색상 네트워크와 독립적이고 대상 이미지 해상도로 렌더링할 필요가 없기 때문에 신속하게 계산할 수 있다. 필터링 후에는 일반적으로 병합할 Block-NeRF가 1~3개 남는다.
Block-NeRF Compositing
필터링된 각 BlockNeRF에서 컬러 이미지를 렌더링하고 카메라 원점 $c$와 각 Block-NeRF의 중심 $x_i$ 사이의 역 거리 가중치를 사용하여 이미지 사이를 interpolation한다. 구체적으로, 각각의 가중치를
\[\begin{equation} w_i \propto \textrm{distance}(c, x_i)^{-p} \end{equation}\]로 계산한다. 여기서 $p$는 Block-NeRF 렌더 간의 혼합 비율에 영향을 미친다. Interpolation은 2D 이미지 공간에서 수행되며 Block-NeRF 간의 원활한 전환을 생성한다.
Appearance Matching
학습된 모델의 모양은 Block-NeRF가 학습된 후 외형 latent code에 의해 제어될 수 있다. 이 latent code는 학습 중에 랜덤하게 초기화되므로 일반적으로 동일한 코드가 다른 Block-NeRF에 입력되면 모양이 달라진다. 이는 뷰 간의 불일치로 이어질 수 있으므로 합성 시 바람직하지 않다. Block-NeRF 중 하나의 타겟 외형이 주어지면 나머지 블록의 외형과 일치하는 것을 목표로 한다. 이를 먼저 인접한 Block-NeRF 쌍 사이의 3D 매칭 위치를 선택한다. 이 위치의 visibility 예측은 두 Block-NeRF 모두에 대해 높아야 한다.

일치하는 위치가 주어지면 Block-NeRF 네트워크 가중치를 동결하고 각 영역 렌더링 간의 $\ell_2$ loss를 줄이기 위해 대상의 외형 코드만 최적화한다. 이 최적화는 100번의 iteration 내에서 수렴되므로 빠르다. 이 절차는 반드시 완벽한 정렬을 제공하지는 않지만 성공적인 합성을 위한 전제 조건인 시간, 색상 균형, 날씨 등 장면의 대부분의 글로벌 및 저주파 속성을 정렬한다. 위 그림은 외형 매칭이 주간 장면을 야간 장면으로 바꾸어 인접한 Block-NeRF와 일치시키는 최적화 예시를 보여준다.
최적화된 외형은 장면 전체에 반복적으로 전파된다. 하나의 루트 Block-NeRF에서 시작하여 이웃 루트의 외형을 최적화하고 거기서부터 프로세스를 계속한다. 대상 Block-NeRF를 둘러싼 여러 블록이 이미 최적화된 경우 loss를 계산할 때 각 블록을 고려한다.
Experiments
- 데이터셋
- San Francisco Alamo Square Dataset
- 이미지 개수: 총 2,818,745개, 각 Block-NeRF마다 64,575 ~ 108,216개
- 데이터 컬렉션 수: 총 1,330개, 각 Block-NeRF마다 38 ~ 48개
- 커버 범위: 960m $\times$ 570m
- San Francisco Mission Bay Dataset
- 이미지 개수: 12,000
- 녹화 시간: 100초
- 주행 거리: 1.08km
- 카메라 개수: 12
- San Francisco Alamo Square Dataset
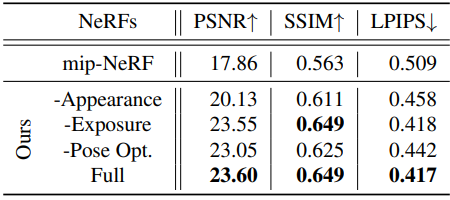
1. Model Ablations
다음은 각 Block-NeRF에 대한 ablation study 결과이다. (Alamo Square)
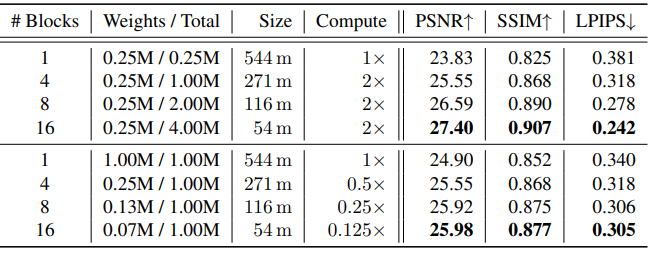
2. Block-NeRF Size and Placement
다음은 Block-NeRF 수에 재구성 결과를 비교한 표이다. (Mission Bay)
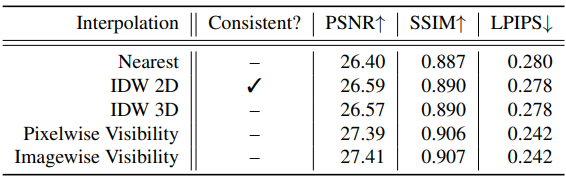
3. Interpolation Methods
다음은 interpolation 방법에 대한 비교 결과이다. (IDW: inverse distance weighting)
Limitations
- 본 논문의 방법은 segmentation 알고리즘을 사용하여 마스킹을 통해 학습 중에 동적 물체를 필터링하여 처리한다. 물체가 적절하게 마스킹되지 않으면 결과 렌더링에 아티팩트가 발생할 수 있다. 예를 들어 자동차 자체를 올바르게 제거한 경우에도 자동차의 그림자가 남아 있는 경우가 많다. 식물은 또한 잎사귀가 계절에 따라 변하고 바람에 따라 움직이기 때문에 이러한 가정을 깨뜨린다. 이로 인해 나무와 식물이 흐릿하게 표현된다. 마찬가지로 건설 현장과 같은 학습 데이터의 시간적 불일치는 자동으로 처리되지 않으며 영향을 받는 블록을 수동으로 재학습해야 한다. 또한 동적 물체가 포함된 장면을 렌더링할 수 없기 때문에 현재 로봇 공학의 closed-loop 시뮬레이션 task에 Block-NeRF를 적용하는 것이 제한된다.
- 장면의 멀리 있는 물체가 근처 물체와 동일한 밀도로 샘플링되지 않아 더 흐릿하게 재구성된다. 이는 제한되지 않은 볼륨 표현을 샘플링할 때 발생하는 문제이다.
- 많은 애플리케이션에서 실시간 렌더링이 핵심이지만 NeRF는 렌더링하는 데 계산 비용이 많이 든다. (이미지당 최대 몇 초)