[논문리뷰] BLIP-Diffusion: Pre-trained Subject Representation for Controllable Text-to-Image Generation and Editing
arXiv 2023. [Paper] [Page] [Github]
Dongxu Li, Junnan Li, Steven C.H. Hoi
Salesforce AI Research
24 May 2023

Introduction
Text-to-image 생성 모델은 크게 발전하여 텍스트 프롬프트를 기반으로 고품질 이미지를 생성할 수 있게 되었다. 그 애플리케이션 중 하나는 입력 피사체의 모양을 유지하면서 새로운 표현을 렌더링하는 것을 목표로 하는 피사체 중심 생성이다. 피사체 중심 생성에 대한 일반적인 접근 방식은 피사체 시각 자료를 텍스트 삽입 공간으로 반전시키는 것이다. 특히 사전 학습된 text-to-image 생성 모델을 사용하면 placeholder 텍스트 임베딩이 피사체 이미지 세트를 재구성하도록 최적화된다. 그런 다음 임베딩은 자연어 프롬프트로 구성되어 다양한 피사체 표현을 생성한다. 이 접근 방식의 알려진 비효율성 중 하나는 각각의 새로운 피사체에 대해 수백 또는 수천 개의 지루한 fine-tuning을 반복해야 하므로 광범위한 피사체로 효율적으로 확장하는 데 방해가 된다는 것이다.
이러한 비효율성은 사전 학습된 대부분의 text-to-image 모델이 기본적으로 이미지와 텍스트를 모두 제어 입력으로 사용하는 멀티모달 제어를 지원하지 않는다는 사실에 기인한다. 결과적으로, 피사체의 시각적 요소를 높은 충실도로 캡처하면서 텍스트 공간과 일치하는 피사체 표현을 배우는 것이 어려워진다. 본 논문은 이러한 한계를 극복하기 위해 사전 학습된 일반적인 피사체 표현을 갖춘 최초의 피사체 중심 text-to-image 생성 모델인 BLIP-Diffusion을 소개한다. 이 모델은 zero-shot 또는 몇 step의 fine-tuning을 통해 피사체 중심 생성을 가능하게 한다. 본 논문의 모델은 비전-언어 인코더 (ex. BLIP-2)와 latent diffusion model (ex. Stable Diffusion)을 기반으로 구축되었다. BLIP-2 인코더는 파시체 이미지와 해당 카테고리 텍스트를 입력으로 사용하며, 텍스트 정렬된 피사체 표현을 출력으로 생성한다. 그런 다음 latent diffusion model을 가이드하기 위해 프롬프트 임베딩에 피사체 표현을 삽입한다.
본 논문은 제어 가능하고 충실도가 높은 생성을 가능하게 하기 위해 일반적인 피사체 표현을 학습하기 위한 새로운 2단계 사전 학습 전략을 제안한다. 첫 번째 사전 학습 단계에서는 입력 이미지를 기반으로 텍스트 정렬된 시각적 feature를 생성하도록 BLIP-2를 강제하는 멀티모달 표현 학습을 수행한다. 두 번째 사전 학습 단계에서는 diffusion model이 입력된 시각적 feature를 기반으로 새로운 피사체 표현을 생성하는 방법을 학습하는 피사체 표현 학습 task를 설계한다. 이를 위해 서로 다른 맥락에서 나타나는 동일한 피사체를 가진 입력 타겟 이미지 쌍을 선별한다. 구체적으로, 랜덤 배경으로 피사체를 구성하여 입력 이미지를 합성한다. 사전 학습 중에 BLIP-2를 통해 합성 입력 이미지와 피사체 클래스 레이블을 공급하여 피사체 표현으로 멀티모달 임베딩을 얻는다. 그런 다음 피사체 표현이 텍스트 프롬프트와 결합되어 타겟 이미지 생성을 가이드한다.
본 논문은 사전 학습된 피사체 표현의 이점을 활용하여 BLIP-Diffusion은 유망한 zero-shot 피사체 중심 생성 결과와 탁월한 fine-tuning 효율성을 달성하였다. 예를 들어 BLIP-Diffusion은 특정 피사체를 전문화하기 위해 40~120개의 fine-tuning step을 거쳐 DreamBooth에 비해 최대 20배의 속도 향상을 달성한다. 또한 BLIP-Diffusion은 latent diffusion model의 동작을 상속하고 추가 학습 없이도 다양한 피사체 중심 생성 애플리케이션을 지원하도록 유연하게 확장할 수 있다. Prompt-to-prompt 접근 방식에 따라 BLIP-Diffusion을 사용하면 피사체별 시각 자료로 이미지를 편집할 수 있다. ControlNet과 결합하면 다양한 추가 구조 제어로 피사체 중심 생성이 가능하다.
Method
본 논문은 내장된 사전 학습된 피사체 표현을 통해 멀티모달 제어 기능을 갖춘 최초의 이미지 diffusion model인 BLIP-Diffusion을 제안한다. 특히, BLIP-2 인코더를 적용하여 멀티모달 피사체 표현을 추출하고 나중에 생성을 가이드하기 위해 텍스트 프롬프트와 함께 사용된다. 피사체별 시각적 외형을 포착하는 동시에 텍스트 프롬프트와 잘 어울리는 피사체 표현을 배우는 것을 목표로 한다. 이를 위해 2단계 사전 학습 전략을 제안한다. 먼저, 멀티모달 표현 학습 단계는 텍스트 정렬된 일반 이미지 표현을 생성한다. 둘째, 피사체 표현 학습 단계에서는 피사체 중심 생성을 위한 텍스트 및 피사체 표현을 갖춘 diffusion model을 촉발한다.
1. Multimodal Representation Learning with BLIP-2
본 논문은 CLIP 텍스트 인코더를 사용하여 프롬프트 임베딩을 생성하는 latent diffusion model로 Stable Diffusion을 사용한다. 텍스트와 피사체 표현을 모두 프롬프트로 사용하는 생성을 가이드하기 위해서는 피사체 임베딩과 텍스트 임베딩이 잘 정렬되어 서로 협력할 수 있도록 하는 것이 중요하다. 저자들은 고품질의 텍스트 정렬 시각적 표현을 생성하는 최근 비전-언어 사전 학습 모델 BLIP-2에서 영감을 받아 텍스트 정렬 피사체 표현을 추출하기 위해 이를 적용하기로 결정했다.
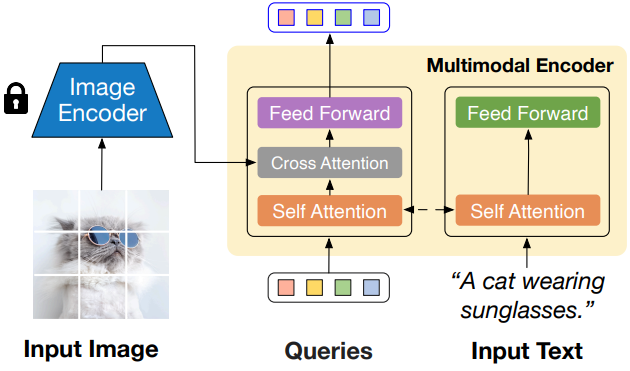
특히 위 그림에서 볼 수 있듯이 멀티모달 표현을 학습하기 위해 BLIP-2의 두 가지 주요 모듈을 사용한다. 즉, 일반 이미지 feature를 추출하기 위한 고정된 사전 학습된 이미지 인코더와 이미지-텍스트 정렬을 위한 멀티모달 인코더 (ex. Q-Former)이다. 멀티모달 인코더는 고정된 수의 학습 가능한 query 토큰과 입력 텍스트를 허용하는 transformer이다. Query 토큰은 self-attention 레이어를 통해 텍스트와 상호 작용하고, cross-attention 레이어를 통해 고정된 이미지 feature와 상호 작용하며, 텍스트 정렬된 이미지 feature를 출력으로 생성한다. 출력은 query 토큰 수와 동일한 차원이다. 저자들은 경험적으로 원래 구현된 32개의 출력 feature가 이미지 생성을 위해 조합하여 사용될 때 CLIP 텍스트 임베딩을 압도하는 경우가 많다는 것을 발견했다. 따라서 대신 query 토큰 수를 절반으로 줄이고 16개의 feature를 출력한다.
BLIP-2 사전 학습을 따라 다음과 같은 3가지 비전-언어 사전 학습 목적 함수를 공동으로 학습한다.
- Image-text contrastive learning (ITC) loss: 상호 정보를 최대화하여 텍스트와 이미지 표현을 정렬
- Image-grounded text generation (ITG) loss: 입력 이미지에 대한 텍스트를 생성
- Image-text matching (ITM) loss: 이진 예측을 통해 세밀한 이미지 텍스트 정렬을 캡처
일반적인 이미지-텍스트 쌍 데이터에 대해 멀티모달 표현 학습을 수행하여 모델이 다양한 시각적 및 텍스트 개념을 학습할 수 있도록 한다.
2. Subject Representation Learning with Stable Diffusion
멀티모달 표현 학습의 결과로 입력 이미지의 텍스트 정렬된 시각적 표현을 얻는다. 이러한 feature는 입력 이미지의 일반적인 semantic 정보를 캡처한다. 그러나 이는 diffusion model에 대한 guidance 역할을 하도록 특별히 맞춤화되지 않았다. 이를 위해 피사체 표현 학습 단계에서는 diffusion model이 이러한 시각적 표현을 활용하고 텍스트 프롬프트와 결합할 때 피사체의 다양한 표현을 생성할 수 있도록 하는 것을 목표로 한다. 특히 피사체 표현을 diffusion model에 주입할 때 원하는 두 가지 속성을 고려한다.
첫째, 피사체 표현이 텍스트 프롬프트와 잘 조화되어야 한다. 이와 관련하여, 이전 방법들은 학습 중에 텍스트 프롬프트를 다루지 않는다. 따라서 확장 가능한 사전 학습에 사용하기에 직접적으로 적합하지 않다. 둘째, foundation diffusion model의 동작이 이상적으로 유지되어야 한다. 이를 통해 피사체 중심 생성 모델은 이미지 편집 및 구조 제어 생성과 같이 원본 모델 위에 구축된 기술을 즉석에서 활용할 수 있다.
Model Architecture
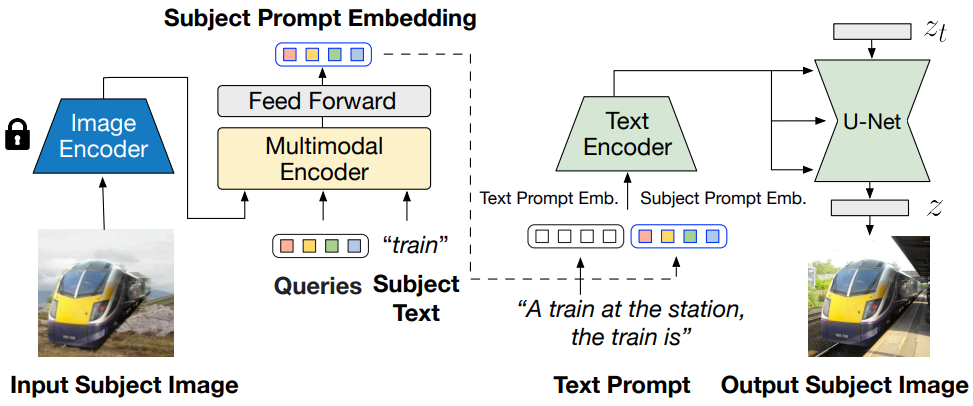
제안된 모델 아키텍처는 위 그림에 나와 있다. BLIP-2 멀티모달 인코더의 출력을 diffusion model의 텍스트 인코더의 입력에 연결한다. 사전 학습 중에 멀티모달 인코더는 피사체 이미지와 피사체 카테고리의 텍스트를 입력으로 사용하고 카테고리를 인식하는 시각적 표현을 생성한다. 그런 다음 GELU가 중간에 있는 두 개의 linear layer로 구성된 feed-forward layer를 사용하여 피사체 표현을 변환한다. Project된 feature는 부드러운 시각적 피사체 프롬프트로 텍스트 프롬프트 토큰 임베딩에 추가된다. 구체적으로 텍스트 토큰과 피사체 임베딩을 결합할 때
“[텍스트 프롬프트], the [피사체 텍스트] is [피사체 프롬프트]”
템플릿을 사용한다. 마지막으로 결합된 텍스트와 피사체 임베딩은 CLIP 텍스트 인코더를 통과하여 diffusion model에 대한 guidance 역할을 하여 출력 이미지를 생성한다. 부드러운 시각적 프롬프트는 foundation diffusion model의 아키텍처 변경을 최소화하여 피사체 표현을 주입하는 효과적인 솔루션을 렌더링하는 동시에 foundation diffusion model의 모델링 능력을 크게 상속한다.
Subject-generic Pre-training with Prompted Context Generation
입력 이미지에서 일반적인 피사체를 표현하는 방법을 학습하도록 모델을 사전 학습하는 것을 목표로 한다. 이를 위해 순진한 접근 방식은 멀티모달 인코더에 대한 입력과 diffusion model에 대한 출력 모두에 동일한 이미지를 사용하는 것이다. 그러나 저자들은 예비 실험에서 이것이 입력의 배경에 의해 생성이 크게 방해를 받거나 입력 이미지를 출력으로 복사하는 모델이 텍스트 프롬프트를 존중하지 않는 생성을 렌더링하는 자명한 솔루션으로 이어진다는 것을 발견했다. 반면, 서로 다른 컨텍스트에서 동일한 피사체에 대한 여러 이미지를 수집하여 서로 다른 이미지를 입력 및 타겟으로 사용할 수 있지만 이러한 접근 방식은 일반적인 피사체로 확장하기가 어렵다.
본 논문은 이러한 문제를 해결하기 위해 prompted context generation이라고 불리는 피사체 표현 학습을 위한 새로운 사전 학습 task를 제안한다. 랜덤 배경에서 피사체의 이미지를 합성하여 입력-타겟 학습 쌍을 선별한다. 모델은 합성된 피사체 이미지를 입력으로 사용하고 텍스트 프롬프트에 따라 원본 피사체 이미지를 출력으로 생성하는 것을 목표로 한다. 구체적으로, 피사체가 포함된 이미지가 있는 경우 먼저 신뢰도 임계값을 사용하여 피사체의 이미지와 카테고리 텍스트를 text-prompted segmentation model인 CLIPSeg에 공급한다. 그런 다음 신뢰도가 높은 segmentation map을 알려진 전경으로, 신뢰도가 낮은 것을 불확실한 영역으로, 나머지를 알려진 배경으로 사용하여 trimap을 구축한다. Trimap이 주어지면 closed-form matting을 사용하여 전경, 즉 피사체를 추출한다. 그런 다음 추출된 피사체를 alpha blending을 통해 임의의 배경 이미지로 구성한다. 마지막으로 합성 이미지를 입력으로 사용하고 원본 타겟 이미지를 출력으로 사용하여 하나의 학습 이미지 쌍으로 사용한다.

위 그림에서 볼 수 있듯이 이러한 합성 쌍은 전경 피사체와 배경 컨텍스트를 효과적으로 분리하여 피사체와 관련 없는 정보가 피사체 프롬프트에서 인코딩되는 것을 방지한다. 이러한 방식으로 diffusion model이 생성을 위해 피사체 프롬프트와 텍스트 프롬프트를 공동으로 고려하도록 장려하며, 이는 피사체 이미지와 텍스트 프롬프트 모두에 의해 충실하고 유연하게 제어될 수 있는 사전 학습된 모델로 이어진다.
사전 학습 중에는 이미지 인코더를 고정하고 텍스트 인코더와 latent diffusion model의 U-Net과 BLIP-2 멀티모달 인코더를 공동으로 학습시킨다. 원래의 text-to-image 생성 능력을 더 잘 보존하려면 diffusion을 가이드하기 위해 텍스트 프롬프트만 사용하면서 피사체 프롬프트를 15% 확률로 무작위로 삭제하는 것이 유익하다.
3. Fine-tuning and Controllable Inference
사전 학습된 피사체 표현을 통해 zero-shot 생성과 특정 사용자 지정 피사체에 대한 효율적인 fine-tuning이 모두 가능하다. 또한, foundation diffusion model의 모델링 능력을 상속하면서 높은 수준의 시각적 제어를 제공한다. 이를 통해 BLIP-Diffusion을 기반 생성 모델로 사용하여 이미지 생성 및 편집 기술을 즉시 활용할 수 있다.
Subject-specific Fine-tuning and Inference
사전 학습된 일반적인 피사체 표현을 통해 고도로 개인화된 피사체에 대한 효율적인 fine-tuning이 가능하다. 몇 개의 피사체 이미지와 피사체 카테고리 텍스트가 주어지면 먼저 멀티모달 인코더를 사용하여 피사체 표현을 개별적으로 얻는다. 그런 다음 모든 피사체 이미지의 평균 피사체 표현을 사용하여 피사체 프롬프트 임베딩을 초기화한다. 이러한 방식으로 fine-tuning 중에 멀티모달 인코더의 forward pass 없이 피사체 프롬프트 임베딩을 캐싱한다. Diffusion model은 텍스트 프롬프트 임베딩과 평균 피사체 임베딩을 고려하여 피사체 이미지를 타겟으로 생성하도록 fine-tuning되었다. 또한 diffusion model의 텍스트 인코더를 고정하면 타겟 이미지에 대한 overfitting을 방지하는 데 도움이 된다. 모든 피사체에 걸쳐 AdamW optimizer, batch size 3, 5e-5의 일정한 learning rate를 사용했으며, 일반적으로 하나의 A100 GPU에서 완료하는 데 20-40초가 걸리는 40-120개의 학습 단계 후에 괜찮은 결과를 관찰했다.
Structure-controlled Generation with ControlNe
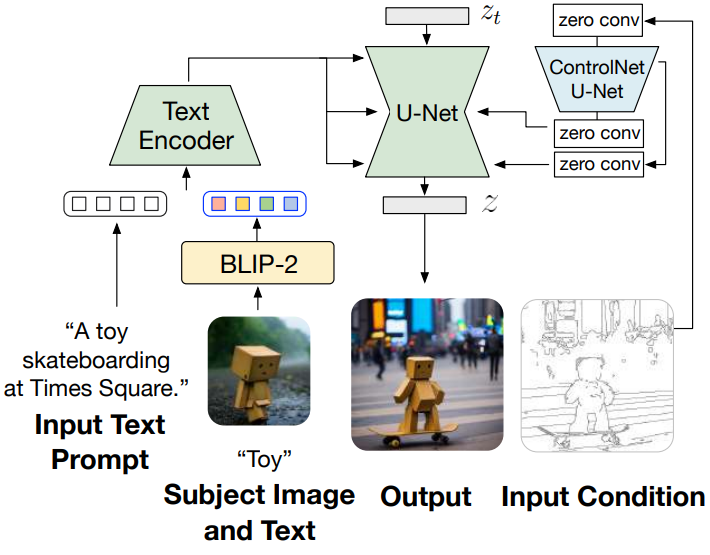
BLIP-Diffusion은 피사체 제어를 위한 멀티모달 컨디셔닝 메커니즘을 도입한다. 동시에 이 아키텍처는 ControlNet과 통합하여 구조 제어 및 피사체 제어 생성을 동시에 달성할 수 있다. 위 그림은 사전 학습된 ControlNet의 U-Net을 residual을 통해 BLIP-Diffusion의 U-Net에 연결하는 통합을 보여준다. 이러한 방식으로 모델은 피사체 단서 외에도 가장자리 맵, 깊이 맵과 같은 입력 구조 조건을 고려한다. BLIP-Diffusion은 원래 latent diffusion model의 아키텍처를 상속하기 때문에 추가 학습 없이 사전 학습된 ControlNet과의 통합을 사용하여 만족스로운 생성을 관찰할 수 있다.
Subject-driven Editing with Attention Control
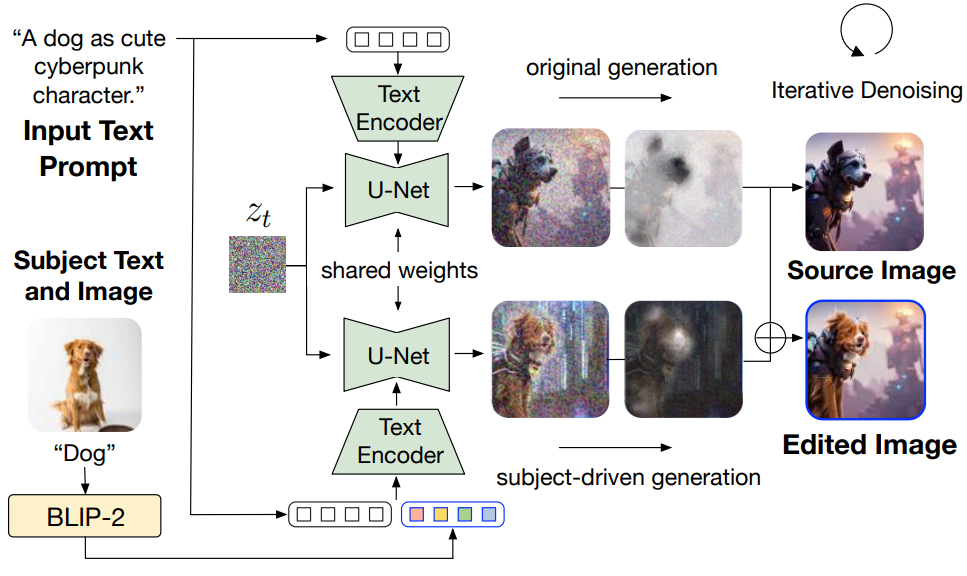
BLIP-Diffusion은 멀티모달 제어 생성을 위해 피사체 프롬프트 임베딩과 텍스트 프롬프트 임베딩을 결합한다. Prompt-to-prompt에서 영감을 받아, BLIP-Diffusion은 프롬프트 토큰의 cross-attention map을 조작하여 피사체 중심 이미지 편집을 가능하게 한다. 위 그림에서는 모델이 피사체별 시각적 요소로 원본 이미지를 편집하는 능력을 보여준다. 이를 위해 원본 이미지의 생성 프로세스가 알려져 있거나 실제 이미지에 대한 inversion을 통해 파생될 수 있다고 가정한다.
이미지를 편집하려면 먼저 편집할 텍스트 토큰 (ex. “dog” 토큰)을 지정한다. 다음으로, 지정된 토큰의 cross-attention map을 사용하여 편집할 영역의 마스크를 자동으로 추출한다. 편집되지 않은 영역의 레이아웃과 semantic을 보존하기 위해 원래 생성의 attention map을 유지하는 동시에 삽입된 피사체 임베딩에 대한 새로운 attention map을 생성한다. 추출된 편집 마스크를 기반으로 각 step에서 denoising latent를 혼합한다. 즉, 편집되지 않은 영역의 latent는 원본 생성에서 나온 반면, 편집된 영역의 latent는 피사체 중심 생성에서 나온 것이다. 이런 방식으로 편집되지 않은 영역을 보존하면서 편집된 이미지를 얻는다.
Experiments
- 멀티모달 표현 학습
- 피사체 표현 학습
- 데이터셋: OpenImage-V6의 29.2만 개의 이미지를 사용
- 인간과 관련된 피사체가 포함된 이미지는 삭제
- 텍스트 프롬프트: BLIP-2 OPT6.7B로 캡션 생성
- 웹에서 5.9만 개의 배경 이미지를 수집
- Foundation diffusion model: Stable Diffusion v1-5
- batch size: 16
- learning rate: $2 \times 10^{-6}$
- step 수: 50만
- optimizer: AdamW
- 16개의 A100 40Gb GPU로 6일 소요
- 데이터셋: OpenImage-V6의 29.2만 개의 이미지를 사용
1. Experimental Results
Main Qualitative Results
다음은 BLIP-Diffusion의 결과들이다.

Comparisons on DreamBooth Dataset
다음은 BLIP-Diffusion을 Textual Inversion, DreamBooth, InstructPix2Pix와 비교한 결과이다.

다음은 DreamBench에서의 정량적 비교 결과이다.
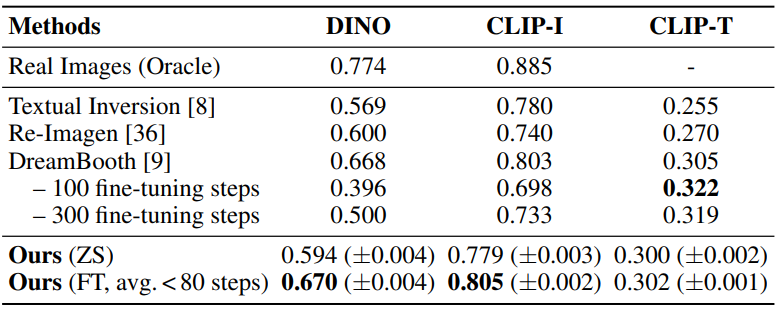
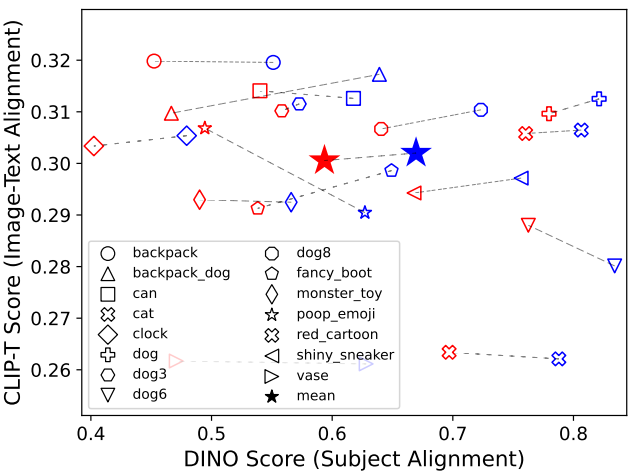
다음은 샘플 피사체에 대한 zero-shot (빨간색) 및 fine-tuning (파란색) 설정의 정렬 메트릭을 나타낸 그래프이다.
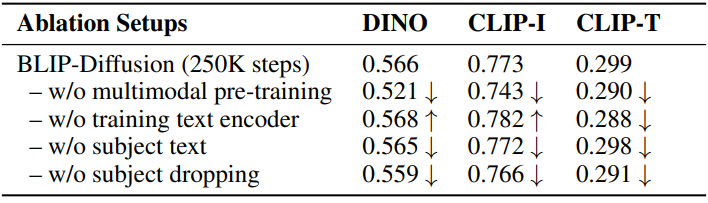
Ablation Studies
다음은 ablation 결과이다.
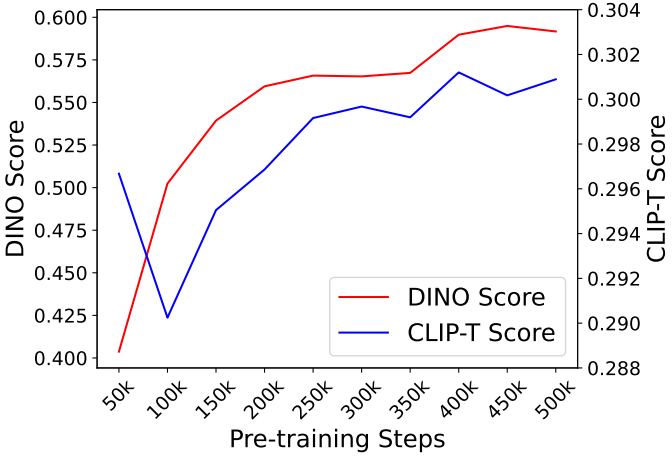
다음은 사전 학습 단계에 따른 피사체 표현 학습의 효과를 나타낸 그래프이다.
Subject Representation Visualization
다음은 피사체 표현의 attention을 시각화한 것이다.

Zero-shot Subject-driven Image Manipulation
다음은 zero-shot 피사체 중심 style transfer 결과이다.

다음은 zero-shot 피사체 보간 결과이다.

Limitations

BLIP-Diffusion은 잘못된 컨텍스트 합성, 학습 세트에 대한 overfitting과 같은 피사체 중심 생성 모델의 일반적인 실패로 인해 어려움을 겪는다. 또한 텍스트 프롬프트와 세밀한 구성 관계를 이해하지 못할 수 있는 foundation diffusion model의 일부 약점을 상속받았다. 위 그림 10에서는 이러한 실패 사례 중 일부를 보여준다.