[논문리뷰] Blended Diffusion for Text-driven Editing of Natural Images
CVPR 2022. [Paper] [Page] [Github]
Omri Avrahami, Dani Lischinski, Ohad Fried
The Hebrew University of Jerusalem | Reichman University
29 Nov 2021
Introduction
텍스트 기반 이미지 조작 분야에서 가장 인상적인 결과는 GAN의 강한 생성 능력을 활용한 것이다. 하지만 GAN 기반의 방식은 일반적으로 제한된 도메인에서 학습된 GAN의 이미지로 제한된다. 또한 실제 이미지를 조작하기 위해서 먼저 GAN의 latent space로 invert하여야 한다. 많은 GAN inversion 테크닉이 최근 떠오르고 있음에도 불구하고 reconstruction 정확도와 이미지 편집 능력 사이의 trade-off를 보인다. 이미지 조작을 특정 이미지 영역으로 제한하는 것도 문제이다.
본 논문에서는 자연어 텍스트 guidance를 사용하여 일반적인 실제 이미지의 영역 기반 편집을 위한 새로운 접근 방식을 제시한다. 구체적으로 텍스트 기반 방법은 목표는 다음과 같다.
- 실제 이미지에서 작동
- 특정 도메인으로 제한되지 않음
- 사용자가 선택한 영역만 수정하고 다른 영역은 보존
- 전역적으로 일관된 수정
- 같은 입력에 대해 다양한 결과를 생성하는 능력
다음은 편집의 다양한 예시들이다.

목표들을 달성하기 위하여 2개의 사전 학습된 모델을 사용한다. 하나는 DDPM이고 다른 하나는 CLIP이다. DDPM은 최근 state-of-the-art GAN보다 나은 이미지 생성 품질을 보여주는 확률적 생성 모델이다. 저자들은 DDPM을 backbone으로 사용하여 자연스러운 결과를 보장한다. CLIP은 인터넷에서 수집된 4억 개의 (이미지, 텍스트) 쌍으로 학습되어 이미지와 텍스트에 대한 풍부한 공유 임베딩 space를 학습한다. 저자들은 CLIP을 사용하여 사용자가 제공한 텍스트 프롬프트를 일치시키도록 이미지 조작을 guide한다.
저자들은 DDPM과 CLIP의 naive한 조합이 이미지 배경을 보존하는 데 실패하고 덜 자연스러운 결과를 초래한다는 것을 보여준다. 대신 각 diffusion step에서 CLIP-guided diffusion latent를 noise가 적절하게 추가된 입력 이미지와 혼합하는 diffusion process를 활용한다. 이 방법이 입력의 변경되지 않은 부분과 일관성 있는 자연스러운 결과를 생성한다는 것을 보여준다. 또한 diffusion process의 각 step에서 extending augmentation를 사용하면 적대적 결과가 감소한다. 이 방법은 추가 학습 없이 사전 학습된 DDPM과 CLIP 모델을 활용한다.
Method
이미지 $x$, 텍스트 프롬프트 $d$, 관심 영역을 나타내는 binary mask $m$이 주어질 때 $\hat{x} \odot m$이 $d$와 일관되고 나머지 부분이 $x$와 가깝게 유지되도록 수정된 이미지 $\hat{x}$ 생성하는 것이 목표이다. $\odot$은 element-wise multiplication이다. 추가로 $\hat{x}$의 두 영역은 이상적으로 매끄럽게 나타나야 한다.
1. Local CLIP-guided diffusion
Diffusion models beat gans on image synthesis 논문은 noisy한 이미지에서 사전 학습된 classifier를 사용하여 타겟 클래스에 맞게 생성하도록 guide하였다. 이와 비슷하게 사전 학습된 CLIP 모델을 사용하여 타겟 프롬프트에 맞게 생성하도록 guide할 수 있을 것이다. CLIP 모델은 깨끗한 이미지에서 학습되었기 때문에 각 noisy latent $x_t$로부터 깨끗한 이미지 $x_0$를 추정하는 방법이 필요하다. 각 denoising process는 $x_0$에 더해진 noise $\epsilon_\theta (x_t,t)$를 예측한다. 따라서 $x_0$는 다음 식으로 얻을 수 있을 것이다.
\[\begin{equation} \hat{x}_0 = \frac{x_t}{\sqrt{\vphantom{1} \bar{\alpha}_t}} - \frac{\sqrt{1 - \bar{\alpha}_t}\epsilon_\theta (x_t, t)}{\sqrt{\vphantom{1} \bar{\alpha}_t}} \end{equation}\]CLIP 기반 loss \(D_{CLIP}\)는 텍스트 프롬프트의 CLIP 임베딩과 추정된 깨끗한 이미지 $\hat{x}_0$의 임베딩 사이의 cosine distance $D_c$로 정의할 수 있을 것이다.
\[\begin{equation} D_{CLIP} (x, d, m) = D_c (CLIP_{img} (x \odot m), CLIP_{txt} (d)) \end{equation}\]비슷한 접근이 CLIP-guided diffusion에서 사용되었다. CLIP-guided diffusion은 $x_t$와 \(\hat{x}_0\)의 선형 결합을 사용하여 전역적인 guidance를 제공하였다. \(D_{CLIP}\)의 기울기를 mask에 대해서만 고려하여 guidance는 원하는 영역만 줄 수 있다. 이 방식으로 CLIP-guided diffusion을 영역 편집에 효과적으로 적용할 수 있다.
이 프로세스는 가우시안 noise에서 시작하며 배경 제약이 없다. 따라서 \(D_{CLIP}\)이 마스킹된 영역 안에서 평가되지만 전체 이미지에 영향을 준다. 주변 영역을 입력 이미지에 맞게 조정하기 위하여 background preservation loss \(D_{bg}\)가 추가되어 mask 밖을 guide한다.
\[\begin{equation} D_{bg} (x_1, x_2, m) = d (x_1 \odot (1-m), x_2 \odot (1-m)) \\ d (x_1, x_2) = \frac{1}{2} (MSE(x_1, x_2) + LPIPS (x_1, x_2)) \end{equation}\]MSE는 pixel-wise 차이의 $L_2$ norm이고, LPIPS는 Learned Perceptual Image Patch Similarity이다.
따라서 diffusion guidance loss는 두 loss의 가중치 합
\[\begin{equation} D_{CLIP} (\hat{x}_0, d, m) + \lambda D_{bg} (x, \hat{x}_0, m) \end{equation}\]이며 local CLIP-guided diffusion의 알고리즘은 아래와 같다.

실제로는 아래 그림과 같이 두 guidance 항 사이에 고유의 trade-off가 존재한다고 한다.

2. Text-driven blended diffusion
Forward process는 이미지 manifold의 진행을 정의하며, 각 manifold는 더 noisy한 이미지로 구성된다. Reverse process의 각 step은 noisy한 이미지를 다음의 덜 noisy한 manifold로 project한다. 이어지는 이미지를 생성하기 위하여 CLIP-guided process에 의해 점진적으로 생성된 각 noisy한 이미지를 입력 이미지의 noisy한 버전과 공간적으로 혼합한다. 저자들의 핵심 아이디어는 각 step에서 두 개의 noisy한 이미지를 혼합한 결과가 일관성이 보장되지는 않지만 각 혼합을 따르는 denoising diffusion step은 다음 manifold에 project하여 일관성을 복원한다는 것이다.
이 프로세스는 다음 그림으로 묘사된다.
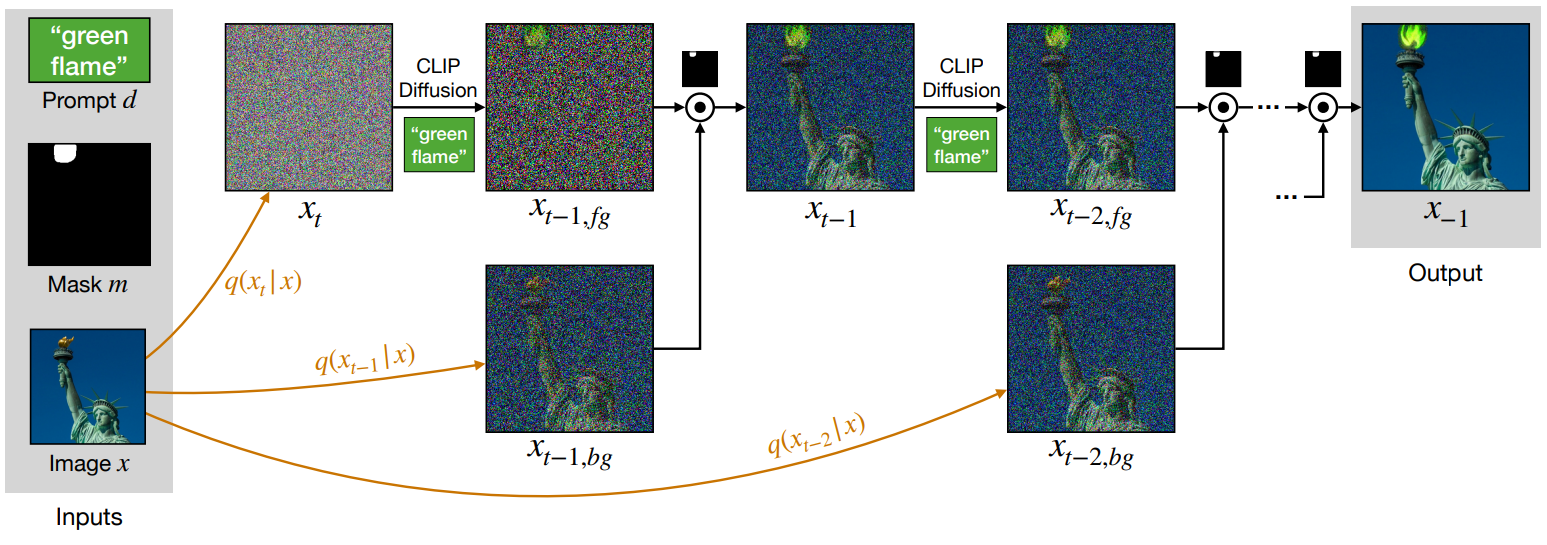
전체 알고리즘은 다음과 같다.

Background preserving blending
배경을 보존하는 navie한 방법은 CLIP-guided diffusion process가 어떤 배경 제약도 없이 $\hat{x}$를 생성하도록 하는 것이다. 그런 다음 생성된 배경을 원본 이미지의 배경으로 대체한다.
\[\begin{equation} \hat{x} \odot m + x \odot (1-m) \end{equation}\]문제는 두 이미지를 이 방식으로 결합하면 일관되고 이어지는 이미지를 생성하는 데 실패한다는 것이다. The Laplacian pyramid as a compact image code 논문에서는 두 이미지를 부드럽게 혼합하기 위해서는 Laplacian pyramid의 각 레벨에서 각각 혼합해야 함을 보였다. 이 테크닉에 영감을 받아 저자들은 diffusion process의 각 noise level에서 혼합하는 것을 제안한다.
저자들의 주요 가정은 각 step에서 noisy한 latent가 자연스러운 이미지에 noise를 더한 것들의 manifold로 project된다는 것이다. 두 noisy한 이미지를 혼합하면 manifold 외부에 있을만한 결과가 생성되지만 다음 diffusion step에서는 결과를 다음 레벨 manifold에 project하여 비일관성을 개선한다.
따라서 각 stage에서 latent $x_t$에서 시작하여 텍스트 프롬프트에 따라 latent를 denoising하는 single CLIP-guided diffusion step를 수행하여 \(x_{t-1, fg}\)로 표시된 latent을 생성한다. 추가로, 입력 이미지로부터 noise가 추가된 배경 \(x_{t-1, bg}\)를 얻는다. 그런 다음 두 latent를 mask를 사용하여 혼합한다.
\[\begin{equation} x_{t-1} = x_{t-1, fg} \odot m + x_{t-1, bg} \odot (1-m) \end{equation}\]이 프로세스를 반복한다.
마지막 step에서는 mask 밖의 전체 영역이 입력 이미지의 해당 부분과 교체되어 배경이 보존된다.
Extending augmentations
Adversarial examples는 이미지의 픽셀 값을 직접 최적화할 때 발생하는 잘 알려진 현상이다. 예를 들어, 이미지의 픽셀을 잘못된 클래스에 대한 기울기 방향으로 약간 바꾸면 classifier는 이미지를 부정확하게 분류하도록 쉽게 속을 수 있다. 이렇게 작은 adversarial noise를 추가해도 인간이 보았을 때는 큰 차이가 없지만, classifier의 분류는 잘못된 결과를 나타낸다.
이와 비슷하게 CLIP-guided diffusion으로 점진적으로 픽셀 값을 바꾸면 원하는 높은 레벨의 semantic 변화를 생성하지 않은 채 CLIP loss가 줄어든 결과가 나올 수 있다. 실제로 이러한 현상이 자주 발생한다.
저자들은 이 문제가 각 diffusion step에서 추정된 중간 결과에 대해 여러 가지 augmentation을 수행하고 각 augmentation에 개별적으로 CLIP을 사용하여 기울기를 계산함으로써 완화될 수 있다는 가설을 세웠다. 이런 식으로 CLIP을 “속이기” 위한 조작은 모든 augmentation에 대해 수행되어야 한다. 이는 이미지의 높은 레벨의 변경 없이는 달성하기 어렵다. 실제로 저자들은 간단한 augmentation 테크닉이 이 문제를 완화한다는 것을 발견했다. $\hat{x}_0$가 주어지면 CLIP loss의 기울기를 직접 사용하는 대신 projective하게 변환된 여러 복사본에 대해 계산한다. 그런 다음 이러한 기울기를 함께 평균화한다. 이런 전략을 “extending augmentation”이라 부른다.
Result ranking
Algorithm 2는 동일한 입력에 대해 다양한 출력을 생성할 수 있으며, 이는 저자들이 원하는 기능이다. 저자들은 여러 예측을 생성하고 순위를 매기고 더 높은 점수를 가진 예측을 선택하는 것이 좋다는 것을 알아냈다. Extending augmentation 없이 \(D_{CLIP}\)을 사용하는 CLIP 모델을 사용하여 순위를 매긴다.
Results
1. Comparisons
다음은 텍스트 기반 편집을 수행한 결과를 비교한 것이다. PaintByWord의 implementation이 현재 존재하지 않으므로 논문의 예시에 대한 비교를 진행한 것이다.

(1)은 PaintByWord, (2)는 $\lambda = 1000$으로 Algorithm 1을 사용한 local CLIP-guided diffusion, (3)은 VQGAN-CLIP + PaintByWord (PaintByWord++) 이다.
다음 표는 본 논문의 방법이 위의 baseline들의 성능을 뛰어 넘었다는 것을 보여준다.

다음은 실제 이미지에 대한 텍스트 기반 편집 결과를 비교한 것이다.

(1)은 local CLIP-guided diffusion이고 (2)는 PaintByWord++이다.
2. Ablation of extending augmentations
다음 그림은 extending augmentation의 중요성을 확인하기 위하여 extending augmentation을 사용하는 경우(1)와 완전히 사용하지 않은 경우(2)의 결과를 비교한 것이다.

3. Applications
본 논문의 방법은 일반적인 현실 이미지에 적용 가능하며 다양한 application에 사용할 수 있다.
Text-driven object editing
다음 그림은 이미지에 새로운 물체를 추가하는 능력을 보여준다.

Background replacement
다음 그림은 배경을 text guidance로 변경하는 것이 가능함을 보여준다.

Scribble-guided editing
다음은 사용자가 갈겨 그린 그림을 guide로 사용하여 생성한 이미지들이다.

Text-guided image extrapolation
다음 그림은 텍스트 설명으로 guide하여 이미지를 경계 밖으로 확장시키는 능력을 보여준다.

텍스트 설명으로 왼쪽은 “hell”이 주어졌고 오른쪽은 “heaven”이 주어졌다.
Limitations
다른 DDPM 모델들과 같이 가장 큰 한계점은 inference 시간이다. 최신 GPU로 이미지 한 장을 생성하는 데 30초가 걸린다고 한다. 본 논문에서는 여러 샘플을 생성하고 순위를 매겨 가장 높은 순위를 기록한 샘플을 선택하기 때문에 실시간 application과 모바일 기기와 같은 약한 end-user device에 적용하는 데 한계가 있다.
또한, 이미지의 전체 컨텍스트가 아닌 편집된 영역에 대해서만 순위를 매기기 때문에 랭킹 시스템이 완벽하지 않다. 따라서 아래 예시 (1)과 같이 목표 물체의 일부분만 포함하는 결과가 높은 순위에 들 수 있다.

그러므로 매력적이고 일관된 결과를 생성하기 위해서는 더 나은 랭킹 시스템이 필요하다.
추가로, 본 논문의 모델이 CLIP을 기반으로 하기 때문에 CLIP의 약점과 편향을 모두 가지고 있다. CLIP은 타이포그래피 공격에 취약하여 손글씨 사진만으로도 모델을 속일 수 있다고 한다. 이러한 현상이 위의 예시 (2)에서 볼 수 있다. 위 예시에서는 “rubber toy”를 생성하라고 했는 데 “rubber”라는 단어 자체를 생성하고 있다.
그 밖에도 예시 (3)과 같이 가끔 텍스트에 알맞는 물체 대신 이상한 그림자를 생성할 때도 있다고 한다.