[논문리뷰] BEiT: BERT Pre-Training of Image Transformers
ICLR 2022. [Paper] [Github]
Hangbo Bao, Li Dong, Songhao Piao, Furu Wei
Harbin Institute of Technology | Microsoft Research
15 Jun 2021
Introduction
Transformer는 컴퓨터 비전에서 유망한 성능을 달성했다. 그러나 경험적 연구에 따르면 ViT는 CNN보다 더 많은 학습 데이터가 필요하다. 이 문제를 해결하기 위해 self-supervised 학습은 대규모 이미지 데이터를 활용하는 유망한 솔루션이다. Contrastive learning이나 self-distillation 등 ViT에 대한 여러 가지 방법이 탐색되었다.
동시에 BERT는 자연어 처리에서 큰 성공을 거두었다. Masked language modeling (MLM) task는 먼저 텍스트 내의 일부 토큰을 랜덤하게 마스킹한 다음 손상된 텍스트의 Transformer 인코딩 결과를 기반으로 마스킹된 토큰을 복구한다. BERT에 동기를 부여하여 본 논문은 ViT를 사전 학습하기 위해 denoising autoencoding 아이디어로 전환한다. 이미지 데이터에 BERT 스타일의 사전 학습을 직접 적용하는 것은 어렵다. 우선, ViT의 입력 단위, 즉 이미지 패치에 대한 기존 vocabulary가 없다. 따라서 마스킹된 패치에 대한 모든 가능한 후보를 예측하기 위해 단순히 softmax classifier를 사용할 수 없다. 대조적으로, 단어나 BPE와 같은 언어 vocabulary는 잘 정의되어 있으며 오토인코딩 예측을 용이하게 한다. 간단한 대안은 task를 마스킹된 패치의 픽셀을 예측하는 회귀 문제로 간주하는 것이다. 그러나 이러한 픽셀 레벨의 복구 task는 단거리 의존성과 고주파수 디테일을 사전 학습하는 데 모델링 능력을 낭비하는 경향이 있다. 본 논문의 목표는 ViT의 사전 학습을 위해 위의 문제를 극복하는 것이다.
본 논문에서는 self-supervised 비전 표현 모델인 Bidirectional Encoder representation from Image Transformers (BEiT)를 소개한다. BERT에서 영감을 받아 masked image modeling (MIM)이라는 사전 학습 task를 제안한다. MIM은 각 이미지에 대해 이미지 패치와 visual token이라는 두 가지 방법을 사용한다. 이미지를 backbone Transformer의 입력 표현인 패치 그리드로 분할한다. 또한 이미지를 discrete VAE의 latent code로 얻은 discrete한 visual token으로 “토큰화”한다. 사전 학습 중에 이미지 패치의 일부를 랜덤하게 마스킹하고 손상된 입력을 Transformer에 공급한다. 모델은 마스킹된 패치의 픽셀 대신 원본 이미지의 visual token을 복구하는 방법을 학습한다.
Self-supervised 학습을 수행한 다음 두 가지 다운스트림 task, 즉 image classification과 semantic segmentation에서 사전 학습된 BEiT를 fine-tuning한다. 실험 결과는 BEiT가 처음부터 시작하는 학습과 이전의 강력한 self-supervised 모델 모두를 능가한다. 또한 BEiT는 supervised 사전 학습을 보완한다. BEiT의 성능은 ImageNet 레이블을 사용한 중간 fine-tuning을 통해 더욱 향상될 수 있다. 저자들이 제안한 기술이 이미지 데이터에 대한 BERT 스타일 사전 학습의 효과에 중요하다. 성능 외에도 수렴 속도 향상과 fine-tuning의 안정성으로 최종 task에 대한 학습 비용이 절감된다. 또한 self-supervised BEiT는 사전 학습을 통해 합리적인 semantic 영역을 학습하여 이미지에 포함된 풍부한 supervision 신호를 방출할 수 있다.
Methods
입력 이미지 $x$가 주어지면 BEiT는 이를 상황에 맞는 벡터 표현으로 인코딩한다. BEiT는 self-supervised learning 방식으로 masked image modeling (MIM) task에 의해 사전 학습된다. MIM은 인코딩 벡터를 기반으로 마스킹된 이미지 패치를 복구하는 것을 목표로 한다. 다운스트림 task (ex. image classification, semantic segmentation)의 경우 사전 학습된 BEiT에 task layer를 추가하고 특정 데이터셋에서 파라미터를 fine-tuning한다.
1. Image Representations
이미지에는 이미지 패치와 visual token의 두 가지 표현 방법이 있다. 두 가지 유형은 각각 사전 학습 중에 입력 및 출력 표현으로 사용된다.
Image Patch
2D 이미지는 표준 Transformer가 이미지 데이터를 직접 수용할 수 있도록 일련의 패치로 분할된다. 이미지 $x \in \mathbb{R}^{H \times W \times C}$를 $N = HW / P^2$개의 패치 $x^p \in \mathbb{R}^{N \times (P^2 C)}$로 재구성한다. 여기서 $C$는 채널 수이고 $(H, W)$는 입력 이미지 해상도이고 $(P, P)$는 각 패치의 해상도이다. 이미지 패치 \(\{x_i^p\}_{i=1}^N\)은 벡터로 flatten되고 선형으로 project되며, 이는 BERT의 단어 임베딩과 유사하다. 이미지 패치는 픽셀을 보존하며 BEiT에서 입력 feature로 사용된다.
본 논문의 실험에서 각 224$\times$224 이미지를 14$\times$14 그리드의 이미지 패치로 분할했으며 각 패치는 16$\times$16이다.
Visual Token
자연어와 유사하게 이미지를 픽셀 대신 “image tokenizer”에서 얻은 discrete한 토큰 시퀀스로 나타낸다. 구체적으로 이미지 $x \in \mathbb{R}^{H \times W \times C}$를 $z = [z_1, \cdots, z_N] \in \mathcal{V}^{h \times w}$로 토큰화한다. 여기서 vocabulary \(\mathcal{V} = \{1, \cdots, \vert \mathcal{V} \vert \}\)는 discrete한 토큰 인덱스를 포함한다.
Zero-Shot Text-to-Image Generation 논문을 따라, discrete variational autoencoder (dVAE)에서 학습한 이미지 토크나이저를 사용한다. Visual token 학습에는 tokenizer와 디코더라는 두 가지 모듈이 있다. Tokenizer $q_\phi (z \vert x)$는 visual codebook (즉, vocabulary)에 따라 이미지 픽셀 $x$를 discrete한 토큰 $z$로 매핑한다. 디코더 $p_\psi (x \vert z)$는 visual token $z$를 기반으로 입력 이미지 $x$를 재구성하는 방법을 학습한다. 재구성 목적 함수는
\[\begin{equation} \mathbb{E}_{z \sim q_\phi (z \vert x)} [\log p_\psi (x \vert z)] \end{equation}\]로 쓸 수 있다. Latent visual token은 discrete하기 때문에 모델 학습은 미분할 수 없다. 따라서 Gumbel-softmax relaxation은 모델 파라미터를 학습시키는 데 사용된다. 더욱이 dVAE 학습 동안 균일한 prior가 $q_\phi$에 놓인다.
각 이미지를 visual token의 14$\times$14 그리드로 토큰화한다. 하나의 이미지에 대한 visual token의 수와 이미지 패치의 수는 동일하다. Vocabulary 크기는 $\vert \mathcal{V} \vert = 8192$이다. 본 논문에서는 공개적으로 사용 가능한 Zero-Shot Text-to-Image Generation 논문의 image tokenizer를 직접 사용하였다.
2. Backbone Network: Image Transformer
ViT를 따라 표준 Transformer를 backbone 네트워크로 사용한다. 따라서 결과는 네트워크 아키텍처 측면에서 이전 연구들과 직접 비교할 수 있다.
Transformer의 입력은 일련의 이미지 패치 \(\{x_i^p\}_{i=1}^N\)이다. 그런 다음 패치를 선형으로 project하여 패치 임베딩 $Ex_i^p$를 얻는다. 여기서 $E \in \mathbb{R}^{(P^2 C) \times D}$이다. 또한 입력 시퀀스 앞에 특수 토큰을 추가한다. 또한 패치 임베딩에 학습 가능한 표준 1D 위치 임베딩 \(E_\textrm{pos} \in \mathbb{R}^{N \times D}\)를 추가한다. 입력 벡터
\[\begin{equation} H_0 = [e_{[S]}, Ex_i^p, \cdots, Ex_N^p] + E_\textrm{pos} \end{equation}\]가 Transformer에 공급된다. 인코더는 Transformer 블록 $H^l = \textrm{Transformer} (H^{l-1})$의 $L$개의 레이어를 포함한다. 여기서 $l = 1, \cdots, L$이다. 마지막 레이어의 출력 벡터
\[\begin{equation} H^L = [h_{[S]}^L, h_1^L, \cdots, h_N^L] \end{equation}\]은 이미지 패치에 대한 인코딩된 표현으로 사용되며 여기서 $h_i^L$는 $i$번째 이미지 패치의 벡터이다.
3. Pre-Training BEIT: Masked Image Modeling
본 논문은 masked image modeling (MIM) task를 제안하였다. 이미지 패치의 일부 비율을 임의로 마스킹한 다음 마스킹된 패치에 해당하는 visual token을 예측한다.
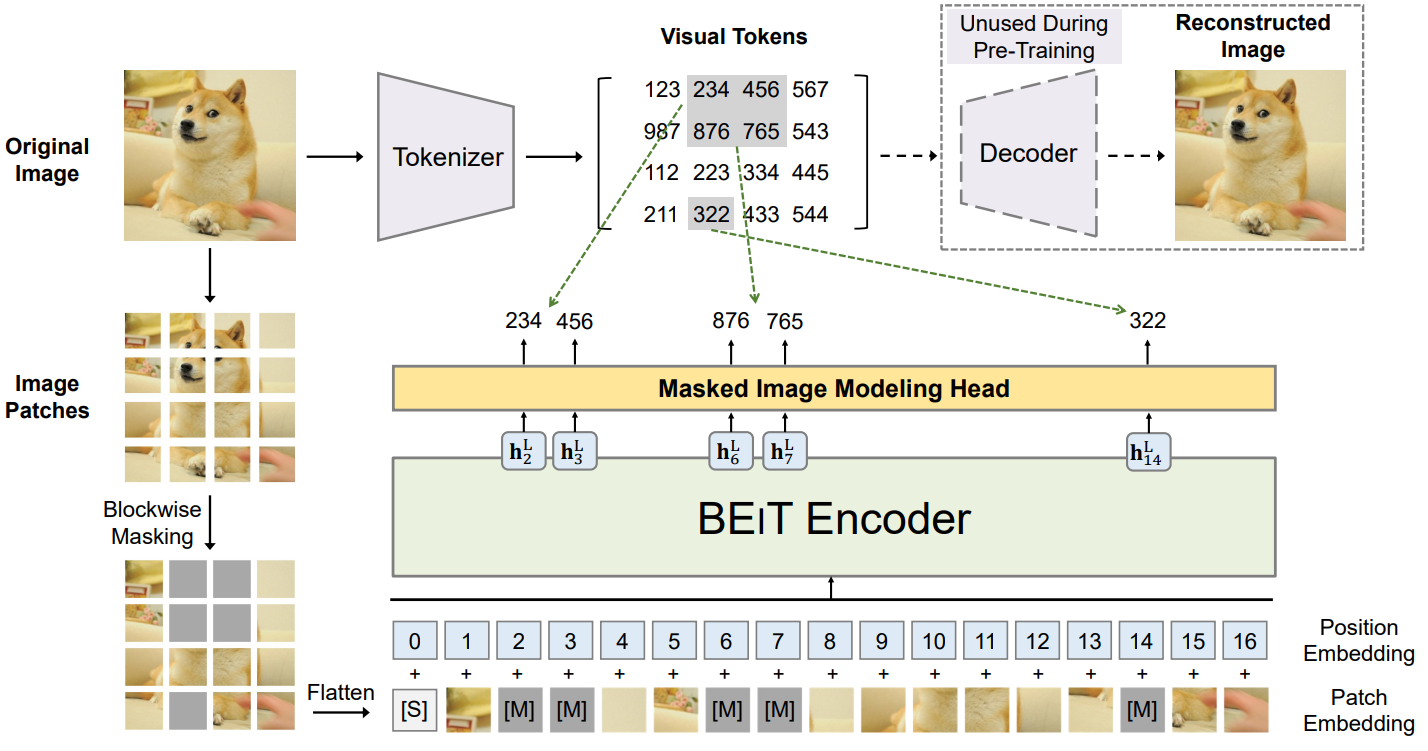
위 그림은 본 논문의 방법의 개요를 보여준다. 입력 이미지 $x$가 주어지면 이를 $N$개의 이미지 패치 (\(\{x_i^p\}_{i=1}^N\))로 분할하고 $N$개의 visual token (\(\{z_i\}_{i=1}^N\))으로 토큰화한다. 약 40%의 이미지 패치를 랜덤하게 마스킹한다. 여기서 마스킹된 위치는 \(M \in \{1, \cdots, N\}^{0.4N}\)이다. 다음으로 마스킹된 패치를 학습 가능한 임베딩 $e_{[M]} \in \mathbb{R}^D$로 교체한다. 손상된 이미지 패치
은 $L$-layer Transformer로 공급된다. 최종 hidden 벡터 \(\{h_i^L\}_{i=1}^N\)은 입력 패치의 인코딩된 표현으로 간주된다. 마스킹된 각 위치 \(\{h_i^L : i \in \mathcal{M}\}_{i=1}^N\)에 대해 softmax classifier를 사용하여 해당 visual token
\[\begin{equation} p_\textrm{MIM} (z' \vert x^\mathcal{M}) = \textrm{softmax}_{z'} (W_c h_i^L + b_c) \end{equation}\]를 예측한다. 여기서 $x^\mathcal{M}$은 손상된 이미지이며, $W_c \in \mathbb{R}^{\vert \mathcal{V} \vert \times D}$이고 $b_c \in \mathbb{R}^{\vert \mathcal{V} \vert}$. 사전 학습 목적 함수는 손상된 이미지가 주어졌을 때 올바른 visual token $z_i$의 log-likelihood를 최대화하는 것이다.
\[\begin{equation} \max \sum_{x \in \mathcal{D}} \mathbb{E}_\mathcal{M} \bigg[ \sum_{i \in \mathcal{M}} \log p_\textrm{MIM} (z_i \vert x^\mathcal{M}) \bigg] \end{equation}\]여기서 $\mathcal{D}$는 학습 corpus, $\mathcal{M}$은 랜덤하게 마스킹된 위치, $x^\mathcal{M}$은 $\mathcal{M}$에 따라 손상된 이미지이다.
마스킹된 위치 $\mathcal{M}$에 대해 랜덤하게 패치를 선택하는 대신 본 논문에서는 블록별 마스킹을 사용한다.

Algorithm 1에 요약된 것처럼 이미지 패치 블록이 매번 마스킹된다. 각 블록에 대해 최소 패치 수를 16으로 설정한다. 그런 다음 마스킹 블록의 종횡비를 무작위로 선택한다. 충분한 마스킹된 패치, 즉 $0.4N$을 얻을 때까지 위의 두 단계를 반복한다. 여기서 $N$은 총 이미지 패치 수이고 0.4는 마스킹 비율이다.
MIM task는 자연어 처리에서 가장 성공적인 사전 학습 목적 함수 중 하나인 masked language modeling (MLM)에서 크게 영감을 받았다. 또한 블록별 (또는 n-gram) 마스킹도 BERT와 같은 모델에 널리 적용되었다. 그러나 비전 사전 학습을 위해 픽셀 레벨 오토인코딩 (즉, 마스킹된 패치의 픽셀 복구)을 직접 사용하면 모델이 단거리 의존성과 고주파수 디테일에 집중하도록 한다. BEiT는 디테일을 높은 수준의 추상화로 요약하는 discrete한 visual token을 예측하여 위의 문제를 극복한다.
4. From the Perspective of Variational Autoencoder
BEiT 사전 학습은 VAE 학습으로 볼 수 있다. $x$를 원본 이미지, $\tilde{x}$를 마스킹된 이미지, $z$를 visual token이라 하자. Log-likelihood $p (x \vert \tilde{x})$의 ELBO를 고려하여 손상된 버전에서 원본 이미지를 복구한다.
\[\begin{equation} \sum_{(x_i, \tilde{x}_i) \in \mathcal{D}} \log p (x_i \vert \tilde{x}_i) \ge \sum_{(x_i, \tilde{x}_i) \in \mathcal{D}} (\underbrace{\mathbb{E}_{z_i \sim q_\phi (z \vert x_i)} [\log p_\psi (x_i \vert z_i)]}_{\textrm{Visual Token Reconstruction}} - D_\textrm{KL} [q_\phi (z \vert x_i), p_\theta (z \vert \tilde{x}_i)]) \end{equation}\]여기서 $q_\phi (z \vert x)$는 visual token을 얻는 image tokenizer이며 $p_\psi (x \vert z)$는 주어진 입력 visual token에 대한 원본 이미지이다. $p_\theta (z \vert \tilde{x})$는 마스킹된 이미지를 기반으로 visual token을 복구한다.
2단계 절차에 따라 모델을 학습시킨다. 첫 번째 단계에서 image tokenizer를 dVAE로 얻는다. 구체적으로, 첫 번째 단계는 균일한 prior로 재구성 loss
\[\begin{equation} − \mathbb{E}_{z_i \sim q_\phi (z \vert x_i)} [\log p_\psi (x_i \vert z_i)] \end{equation}\]를 최소화한다. 두 번째 단계에서는 $q_\phi$와 $p_\psi$를 고정한 상태에서 prior $p_\theta$를 학습한다. 가장 가능성이 높은 visual token
\[\begin{equation} \hat{z}_i = \underset{z}{\arg \max} q_\phi (z \vert x_i) \end{equation}\]를 사용하여 $q_\phi (z \vert x_i)$를 one-point 분포로 단순화한다. 그러면 ELBO 식은 다음과 같이 다시 쓸 수 있다.
\[\begin{equation} \sum_{(x_i, \tilde{x}_i) \in \mathcal{D}} (\underbrace{\mathbb{E}_{z_i \sim q_\phi (z \vert x_i)} [\log p_\psi (x_i \vert z_i)]}_{\textrm{Stage 1: Visual Token Reconstruction}} + \underbrace{\log p_\theta (\hat{z}_i \vert \tilde{x}_i)}_{\textrm{Stage 2: Masked Image Modeling}}) \end{equation}\]여기서 두 번째 항은 BEiT 사전 학습 목적 함수이다.
5. Pre-Training Setup
- 네트워크 아키텍처
- 공정한 비교를 위해 ViT-Base의 네트워크 아키텍처를 따름
- hidden size가 768이고 12개의 attention head가 있는 12-layer Transformer를 사용
- feed-forward network의 중간 크기: 3072
- 기본 입력 패치 크기: 16$\times$16
- visual token의 vocabulary 크기: 8192
- 데이터셋: ImageNet-1K
- augmentation: random resized cropping, horizontal flipping, color jittering
- self-supervised learning에는 레이블을 사용하지 않음
- 해상도: 224$\times$224
- 입력은 14$\times$14 이미지 패치와 동일한 양의 visual token으로 분할됨
- 최대 75개의 패치 (즉, 전체 이미지 패치의 약 40%)를 랜덤하게 마스킹
- 학습 디테일
- 50만 step (800 epochs)
- batch size: 2048
- optimizer: Adam ($\beta_1$ = 0.9, $\beta_2$ = 0.999)
- learning rate: $1.5 \times 10^{-3}$, warmup 10 epochs, cosine decay
- weight decay: 0.05
- stochastic depth rate: 0.1
- dropout 제거
- 16개의 Nvidia Telsa V100 32GB GPU에서 5일 소요
Transformer를 안정시키기 위해 적적한 초기화가 중요하다. 먼저 모든 파라미터를 작은 범위 (ex. [-0.02, 0.02])로 랜덤하게 초기화한다. 그런 다음 $l$번째 Transformer layer의 self-attention 모듈과 feed-forward network를 $\frac{1}{\sqrt{2l}}$로 rescale한다.
6. Fine-Tuning BEIT on Downstream Vision Tasks
BEiT를 사전 학습한 후 Transformer에 task layer를 추가하고 BERT와 같은 다운스트림 task의 파라미터를 fine-tuning한다. 본 논문에서는 image classification과 semantic segmentation을 예로 들었다. BEiT를 사용하여 다른 비전 task에 대한 사전 학습 후 fine-tuning 패러다임을 활용하는 것은 간단하다.
Image classification
Image classification task의 경우 간단한 linear classifier를 task layer로 직접 사용한다. 특히 average pooling을 사용하여 표현을 집계하고 softmax classifier에 공급한다. 카테고리 확률은
\[\begin{equation} \textrm{softmax} (\textrm{avg} (\{h_i^L\}_{i=1}^N W_c)) \end{equation}\]로 계산되며 여기서 $h_i^L$는 $i$번째 이미지 패치의 최종 인코딩 벡터이고 $W_c \in \mathbb{R}^{D \times C}$는 파라미터 행렬이며 $C$는 레이블 수이다. BEiT와 softmax classifier의 파라미터를 업데이트하여 레이블이 지정된 데이터의 likelihood를 최대화한다.
Semantic segmentation
Semantic segmentation의 경우 SETR-PUP에서 사용되는 task layer를 따른다. 구체적으로, 사전 학습된 BEiT를 backbone 인코더로 사용하고 여러 deconvolution layer를 디코더로 통합하여 segmentation을 생성한다. 이 모델은 또한 image segmentation과 유사하게 end-to-end로 fine-tuning된다.
Intermediate fine-tuning
Self-supervised 사전 학습 후 데이터가 풍부한 중간 데이터셋 (ImageNet-1K)에서 BEiT를 추가로 학습한 다음 타겟 다운스트림 task에서 모델을 fine-tuning할 수 있다. 이러한 중간 fine-tuning은 NLP에서 BERT fine-tuning의 일반적인 관행이다. 본 논문은 BEiT의 방법을 직접 따른다.
Experiments
1. Image Classification
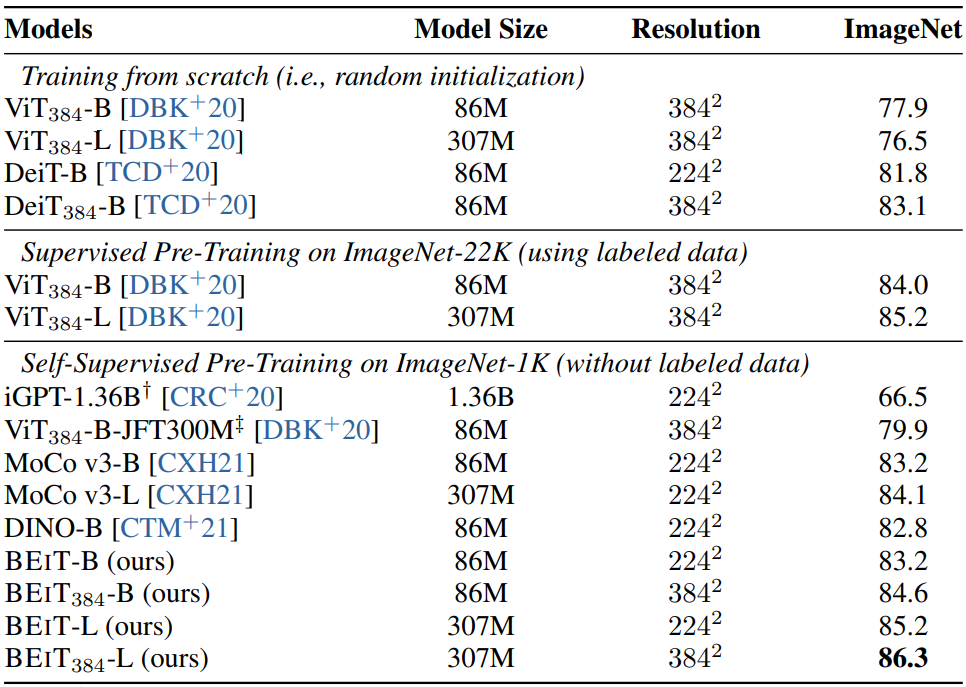
다음은 ImageNet-1K에서 top-1 accuracy를 비교한 표이다.
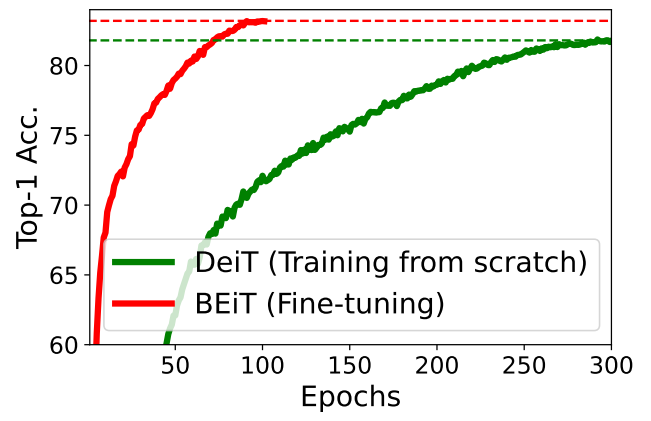
다음은 DeiT와 BEiT의 수렴 곡선을 비교한 것이다.
2. Semantic Segmentation
다음은 ADE20K에서의 semantic segmentation 결과를 비교한 표이다.

3. Ablation Studies
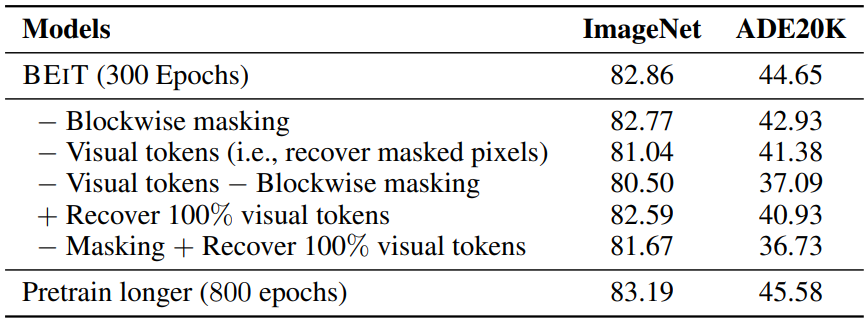
다음은 ImageNet과 ADE20K에서의 ablation study 결과이다.
4. Analysis of Self-Attention Map
다음은 다양한 레퍼런스 포인트에 대한 self-attention map이다.
