[논문리뷰] AudioGPT: Understanding and Generating Speech, Music, Sound, and Talking Head
arXiv 2023. [Paper] [Github]
Rongjie Huang, Mingze Li, Dongchao Yang, Jiatong Shi, Xuankai Chang, Zhenhui Ye, Yuning Wu, Zhiqing Hong, Jiawei Huang, Jinglin Liu, Yi Ren, Zhou Zhao, Shinji Watanabe
Zhejiang University | Peking University | Carnegie Mellon University | Remin University of China
25 Apr 2023
Introduction
오늘날 대규모 언어 모델(Large language model, LLM)은 AI 커뮤니티에 큰 영향을 미치고 있으며 ChatGPT와 GPT-4의 출현은 자연어 처리의 발전으로 이어졌다. 방대한 웹 텍스트 데이터 모음과 강력한 아키텍처를 기반으로 LLM은 사람처럼 읽고 쓰고 의사소통할 수 있다.
텍스트 처리 및 생성 분야의 성공적인 응용에도 불구하고 오디오 modality(음성, 음악, 소리, talking head)에 LLM의 성공을 복제하는 것은 제한적이지만 다음과 같은 이유로 매우 유익하다.
- 실제로 인간은 음성 언어를 사용하여 통신한다. 일상 대화에서 음성 비서(ex. Siri)를 활용하여 삶의 편의성을 높인다.
- 오디오 정보를 처리하는 것은 인공 일반 지능을 달성하는 데 필요하다. 오디오 정보를 이해하고 생성하는 것은 고급 AI 시스템을 향한 LLM의 중요한 단계가 될 수 있다.
오디오 modality의 이점에도 불구하고 오디오 처리를 지원하는 LLM 학습은 다음과 같은 문제로 인해 여전히 어려운 과제이다.
- 데이터: 사람이 레이블을 지정한 음성 데이터를 얻는 것은 비용이 많이 들고 시간이 많이 걸리는 작업이며, 실제 음성 대화를 제공하는 사용할 수 있는 리소스가 거의 없다. 게다가 방대한 웹 텍스트 데이터에 비해 데이터의 양은 제한적이며, 다국어 대화 음성 데이터는 더욱 부족하다.
- 계산 리소스: 처음부터 multi-modal LLM을 학습시키는 것은 계산 집약적이고 시간이 많이 걸린다. 오디오 foundation model이 이미 존재한다는 점을 감안할 때 처음부터 학습을 시작하는 것은 낭비이다.
본 논문에서는 음성 대화에서 오디오 형식을 이해하고 생성하는 데 탁월하도록 설계된 시스템인 “AudioGPT”를 소개한다. 구체적으로,
- Multi-modal LLM을 처음부터 학습시키는 대신 다양한 오디오 foundation model을 활용하여 LLM(즉, ChatGPT)이 범용 인터페이스로 간주되는 오디오 정보를 처리하며, AudioGPT가 수많은 오디오 이해 및 생성 작업을 해결할 수 있도록 지원한다.
- 음성 언어 모델을 학습시키는 대신 음성 대화를 위해 LLM을 입력/출력 인터페이스(ASR, TTS)와 연결한다.

위 그림에서 볼 수 있듯이 AudioGPT의 전체 프로세스는 네 단계로 나눌 수 있다.
- Modality Transformation: 음성과 텍스트 간의 modality 변환을 위한 입력/출력 인터페이스를 사용하여 음성 언어 LLM과 ChatGPT 간의 격차를 해소한다.
- Task Analysis: 대화 엔진과 prompt manager를 활용하여 ChatGPT가 오디오 정보를 처리하려는 사용자의 의도를 이해하도록 돕는다.
- Model Assignment: 운율, 음색, 언어 제어에 대한 구조화된 argument를 받은 ChatGPT는 이해와 생성을 위한 오디오 foundation model을 할당한다.
- Response Generation: 오디오 foundation model을 실행한 후 사용자에게 최종 응답을 생성하고 반환한다.
인간의 의도를 이해하고 여러 base model으 협력을 조직화하는 데 있어서 multi-modal LLM의 성능을 평가해야 한다는 요구가 증가하고 있다. 본 논문에서는 일관성, 능력, robustness(견고성) 측면에서 AudioGPT를 평가하는 설계 원칙과 프로세스를 설명한다. 실험 결과는 음성, 음악, 소리 및 talking head 생성 및 이해를 포함하는 일련의 AI 작업을 다루는 multi-round 대화에서 복잡한 오디오 정보를 처리하기 위한 AudioGPT의 능력을 보여준다.
AudioGPT
1. System Formulation
AudioGPT는 다음과 같이 정의되는 프롬프트 기반 시스템이다.
\[\begin{equation} \textrm{AudioGPT} = (\mathcal{T}, \mathcal{L}, \mathcal{M}, \mathcal{H}, \{\mathcal{P}_i\}_{i=1}^P) \end{equation}\]여기서 $\mathcal{T}$는 modality transformer, $\mathcal{L}$은 대화 엔진 (즉, LLM), $\mathcal{M}$은 prompt manager, $\mathcal{H}$는 task handler, \(\{\mathcal{P}_i\}_{i=1}^P\)는 $P$개의 오디오 foundation model들의 집합이다.
$(n − 1)$-round 상호 작용이 있는 컨텍스트를
\[\begin{equation} C = \{(q_1, r_1), (q_2, r_2), \cdots, (q_{n−1}, r_{n−1})\} \end{equation}\]로 정의한다. 여기서 $q_i$는 $i$번째 round의 query이고 $r_i$는 $i$번째 round의 response(응답)이다. 새 query $q_n$으로 나태낼 수 있는 AudioGPT의 실행은 다음과 같은 response $r_n$을 생성하는 것이다.
\[\begin{equation} r_n = \textrm{AudioGPT} (q_n, C) \end{equation}\]Inference 중에 AudioGPT는 네 가지 주요 단계로 분해될 수 있다.
- Modality transformation: $q_n$ 내의 다양한 입력 modality를 일관된 modality의 query $q’_n$으로 변환한다.
- Task analysis: 대화 엔진 $\mathcal{L}$과 prompt manager $\mathcal{M}$을 활용하여 $(q’_n, C)$를 task handler $\mathcal{H}$을 위해 구조화된 argument $a_n$으로 파싱한다.
- Model assignment: Task handler $\mathcal{H}$는 구조화된 argument $a_n$을 받아 argument를 해당 오디오 task 프로세서 $\mathcal{P}_s$로 보낸다. 여기서 $s$는 선택된 task의 인덱스이다.
- Response generation: \(\mathcal{P}_s (a_n)\) 실행 후 최종 response $r_n$은 \((q'_n, C, \mathcal{P}_s (a_n))\)의 정보를 결합하여 $\mathcal{L}$을 통해 생성된다.
2. Modality Transformation
첫 번째 단계는 query $q_n$을 일관된 modality의 새로운 query $q’_n$으로 변환하는 것을 목표로 한다. 사용자 입력 query $q_n$은 query description $q_n^{(d)}$와 크기가 $k$인 query 관련 리소스 집합 \(\{q_n^{(s_1)}, q_n^{(s_2)}, \cdots, q_n^{(s_k)}\}\)으로 구성된다. AudioGPT에서 $q_n^{(d)}$는 텍스트 또는 오디오 modality일 수 있다. 그리고 modality transformer $\mathcal{T}$는 먼저 $q_n^{(d)}$의 modality를 확인한다. $q_n^{(d)}$가 오디오인 경우 $\mathcal{T}$는 $q_n^{(d)}$을 다음과 같이 오디오에서 텍스트로 변환해야 한다.
\[\begin{equation} q'_n = ({q'_n}^{(d)}, \{q_n^{(s_1)}, \cdots, q_n^{(s_k)}\}) = \begin{cases} (q_n^{(d)}, \{q_n^{(s_1)}, \cdots, q_n^{(s_k)}\}) & \quad \textrm{if } q_n^{(d)} \textrm{ is text} \\ (\mathcal{T}(q_n^{(d)}), \{q_n^{(s_1)}, \cdots, q_n^{(s_k)}\}) & \quad \textrm{if } q_n^{(d)} \textrm{ is audio} \end{cases} \end{equation}\]3. Task Analysis
Task 분석 단계는 $(q’_n , C)$에서 구조화된 argument $a_n$을 추출하는 데 중점을 둔다. 특히 컨텍스트 $C$는 argument 추출에 앞서 대화 엔진 $\mathcal{L}$에 공급된다. $q’_n$의 query resource \(\{q_n^{(s_1)}, \cdots, q_n^{(s_k)}\}\)의 유형에 따라 task handler $\mathcal{H}$는 먼저 query를 입출력 modality를 통해 분류되는 여러 task family로 분류한다. 그런 다음 선택된 task family가 주어지면 query description ${q’_n}^{(d)}$가 prompt manager $\mathcal{M}$으로 전달되어 선택된 오디오 foundation model \(\mathcal{P}_p\)와 해당 task 관련 argument \(h_{\mathcal{P}_p}\)를 포함하는 argument $a_n$을 생성한다. 여기서 $p$는 오디오 모델 집합 \(\{\mathcal{P}_i\}_{i=1}^P\)에서 선택된 오디오 모델의 인덱스다.
\[\begin{equation} (\mathcal{P}_p, h_{\mathcal{P}_p}) = \mathcal{L} (\mathcal{M} (\mathcal{H} (q'_n), {q'_n}^{(d)}), C) \end{equation}\]여기서 $\mathcal{H} (q’_n)$은 $\mathcal{H}$에 의해 선택된 task family이다. 오디오/이미지-입력 task family의 경우 \(h_{\mathcal{P}_p}\)는 이전 컨텍스트 $C$의 필수 리소스들을 포함한다.
앞서 언급했듯이 task handler $\mathcal{H}$는 입출력 modality를 고려하여 task family를 결정한다. 구체적으로 task modality에는 다음과 같은 것들이 있다.
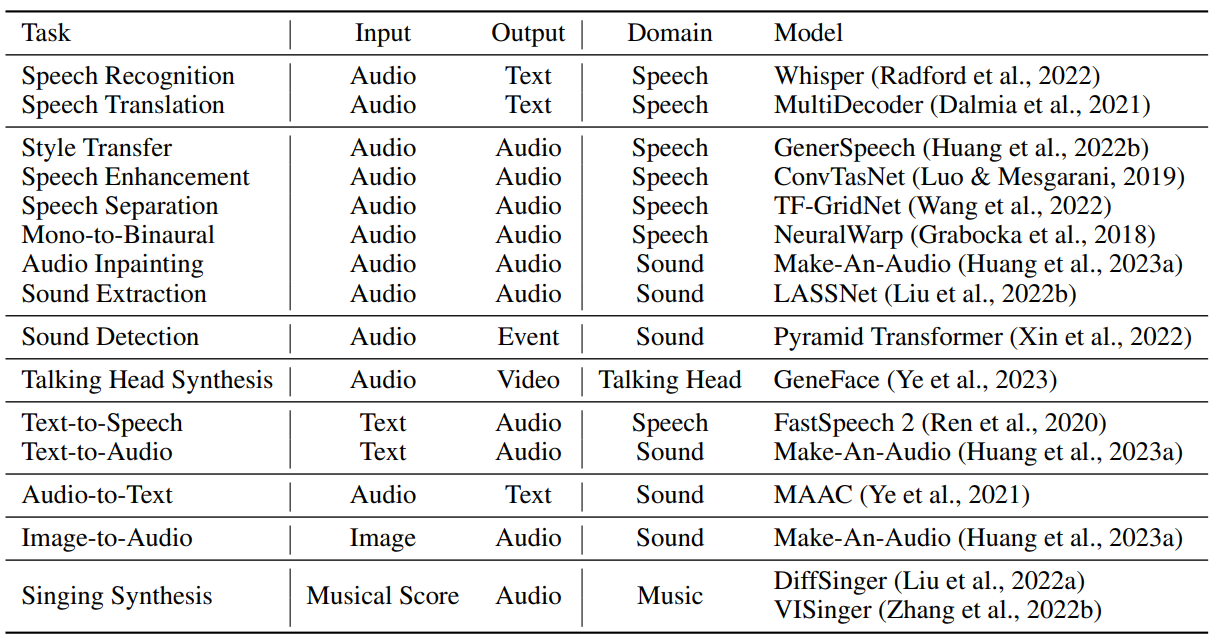
4. Model Assignment
선택된 모델 \(\mathcal{P}_p\)와 argument \(h_{\mathcal{P}_p}\)가 주어지면 모델 할당 단계는 모델에 관련된 리소스를 할당하고 \(\mathcal{P}_p\)를 실행하여 task 출력 \(o_{\mathcal{P}_p}\)를 얻는다.
\[\begin{equation} o_{\mathcal{P}_p} = \mathcal{P}_p (\{q_n^{(s_1)}, q_n^{(s_2)}, \cdots, q_n^{(s_k)}\}, h_{\mathcal{P}_p}) \end{equation}\]AudioGPT의 효율성을 유지하기 위해 환경 설정 또는 서버 초기화 중에 오디오 모델 초기화를 수행한다.
5. Response Generation
응답 생성은 \(\mathcal{P}_p\)와 해당 출력 \(o_{\mathcal{P}_p}\)와 밀접한 관련이 있다. 특히 오디오 생성 task의 경우 AudioGPT는 waveform을 이미지와 다운로드/재생을 위한 해당 오디오 파일을 모두 보여준다. 텍스트를 생성하는 task의 경우 모델은 transcribe된 텍스트를 직접 return한다. 동영상 생성 task의 경우 출력 동영상과 일부 관련 이미지 프레임을 보여준다. Classification task의 경우 카테고리의 posteriorgram이 시간 범위에 걸쳐 보여진다.
Evaluating Multi-Modal LLMs
1. Overview
구체적으로 다음 세 가지 측면에서 LLM을 평가한다.
- Consistency: LLM이 사용자의 의도를 제대로 이해하고 인간의 인지 및 문제 해결과 밀접하게 일치하는 오디오 foundation model을 할당하는지 여부를 평가한다.
- Capabilitity: 복잡한 오디오 task를 처리하고, zero-shot 방식으로 음성, 음악, 소리, talking head를 이해하고 생성하는 오디오 foundation model의 성능을 측정한다.
- Robustness: special case들을 다루는 LLM의 능력을 측정한다.
2. Consistency
Zero-shot 세팅에 대한 일관성 평가에서 모델은 특정 task의 prior example을 제공받지 않고 질문에 대해 직접 평가되며, 이는 multi-modal LLM이 명시적 학습 없이 문제를 추론하고 해결할 수 있는지 여부를 평가한다.
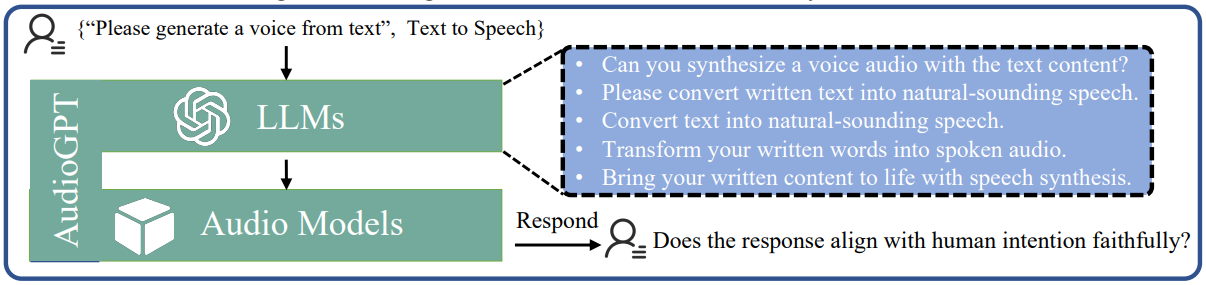
보다 구체적으로, 위 그림에서와 같이 consistency 평가는 벤치마크의 각 task에 대해 3단계로 수행된다.
첫 번째 단계에서 human annotator들에게 {prompts, task_name} 형식으로 각 task에 대한 프롬프트를 제공하도록 요청한다. 이를 통해 복잡한 task를 이해하는 모델의 능력을 평가하고 성공적인 task 할당에 필요한 필수 프롬프트를 식별할 수 있다.
두 번째 단계에서는 LLM의 뛰어난 언어 생성 능력을 활용하여 다른 표현을 사용하면서 동일한 semantic 의미로 설명을 생성하여 LLM이 더 많은 사용자의 의도를 이해하는지 여부를 종합적으로 평가할 수 있다.
마지막으로 Amazon Mechanical Turk를 통해 크라우드 소싱된 human evaluation을 사용한다. 여기서 AudioGPT는 다양한 task와 의도에 해당하는 이러한 자연어 설명과 함께 프롬프트된다. 인간 평가자는 multi-modal LLM의 응답과 즉각적인 입력을 보여주고 “응답이 인간의 인지 및 의도와 밀접하게 일치합니까?”라는 질문을 받는다. 평가자는 “완전히”, “대부분” 또는 “다소”로 응답해야 한다. (95% 신뢰 구간(CI), 20-100 Likert scale)

3. Capability
복잡한 오디오 정보를 처리하기 위한 task 실행자로서 오디오 foundation model은 복잡한 하위 task를 처리하는 데 상당한 영향을 미친다. AudioGPT의 경우 음성, 음악, 소리, talking head를 이해하고 생성하기 위한 평가 metric들과 하위 데이터셋은 아래 표와 같다.
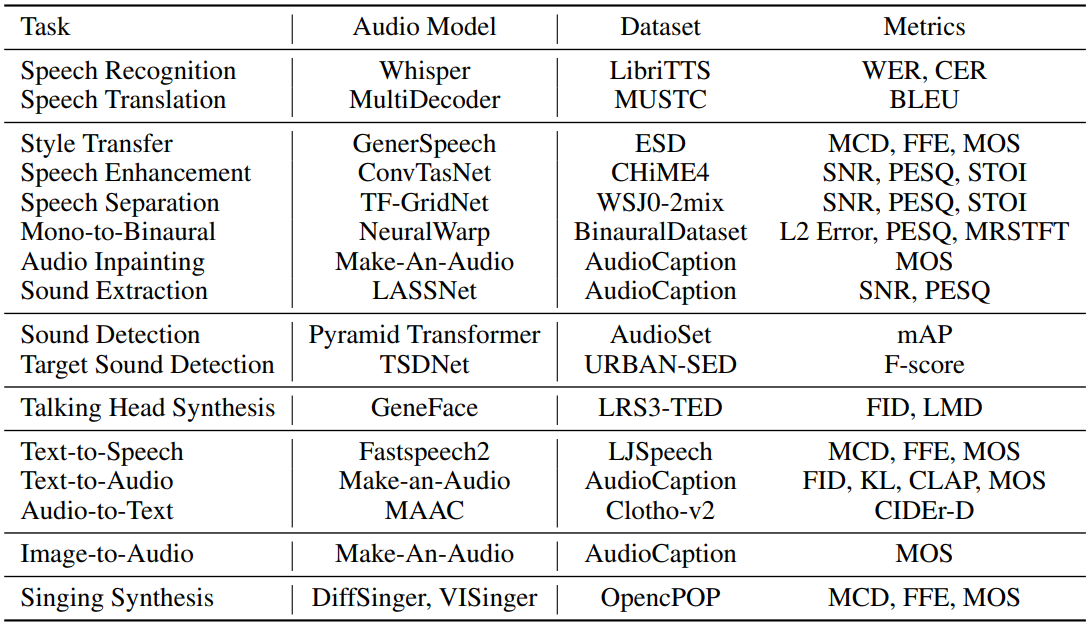
4. Robustness
Special case를 처리하는 능력을 평가하여 multi-modal LLM의 robustness를 평가한다. 이러한 케이스들은 다음 카테고리로 분류할 수 있다.
- Long chains of evaluation: Multi-modal LLM은 multi-modal 생성과 재사용에서 단기 및 장기 컨텍스트 종속성을 고려하면서 긴 평가 체인을 처리할 것으로 예상된다. Task의 체인은 후보 오디오 모델의 순차적 적용이 필요한 query나 다른 task를 요청하는 연속 query 또는 두 가지 유형의 혼합으로 표시될 수 있다.
- Unsupported tasks: Multi-modal LLM은 foundation model에서 다루지 않는 지원하지 않는 task가 필요한 query에 합리적인 피드백을 제공할 수 있어야 한다.
- Error handling of multi-modal models: Multi-modal foundation model은 지원하지 않는 argument 또는 지원하지 않는 입력 modality와 같은 다양한 이유로 인해 실패할 수 있다. 이러한 시나리오에서 multi-modal LLM은 발생한 문제를 설명하고 잠재적 해결책을 제안하는 query에 합리적인 피드백을 제공해야 한다.
- Breaks in context: Multi-modal LLM은 논리적 순서가 아닌 query를 처리할 것으로 예상된다. 예를 들어, 사용자는 query 시퀀스에서 임의의 query를 제출할 수 있지만 더 많은 task가 있는 이전 query를 계속 진행할 수 있다.
Robustness을 평가하기 위해 Consistency 평가와 유사하게 3단계의 주관적 사용자 평가 프로세스를 수행한다. 첫 번째 단계에서 human annotator들은 위의 네 가지 카테고리를 기반으로 프롬프트를 제공한다. 두 번째 단계에서는 프롬프트가 LLM에 입력되어 완전한 상호 작용 세션을 구성한다. 마지막으로, 모집된 다른 피험자들은 Consistency 평가와 동일한 20-100 scale로 상호 작용을 평가한다.
Experiments
GPT 모델의 gpt-3.5-turbo를 LLM으로 사용하고 LangChain으로 LLM을 안내한다. 오디오 foundation model의 배포에는 허깅페이스에 유연한 NVIDIA T4 GPU만 필요하다. Greedy search를 사용하여 출력을 생성하기 위해 0의 temperature를 사용하고 생성을 위한 최대 토큰 수를 2048로 설정한다.
1. Case Study on Multiple Rounds Dialogue

위 그림은 AudioGPT의 12-round 대화 사례이다. 음성, 음악, 소리, talking head를 생성하고 이해하는 일련의 AI task를 다루는 오디오 modality 처리를 위한 AudioGPT의 능력을 보여준다. 대화에는 오디오 정보를 처리하기 위한 여러 요청이 포함되며 AudioGPT가 현재 대화의 컨텍스트를 유지하고 후속 질문을 처리하며 사용자와 적극적으로 상호 작용함을 보여준다.
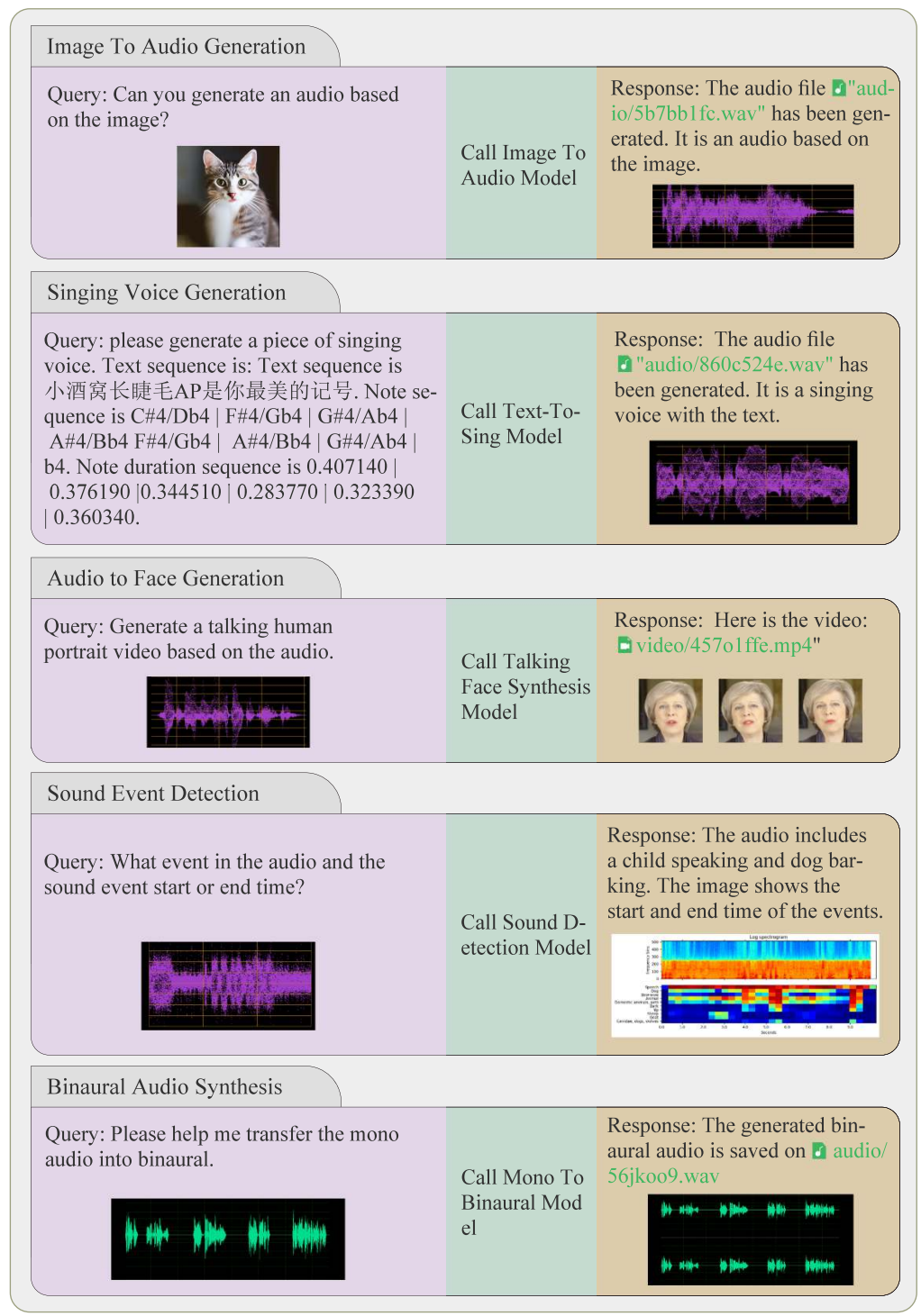
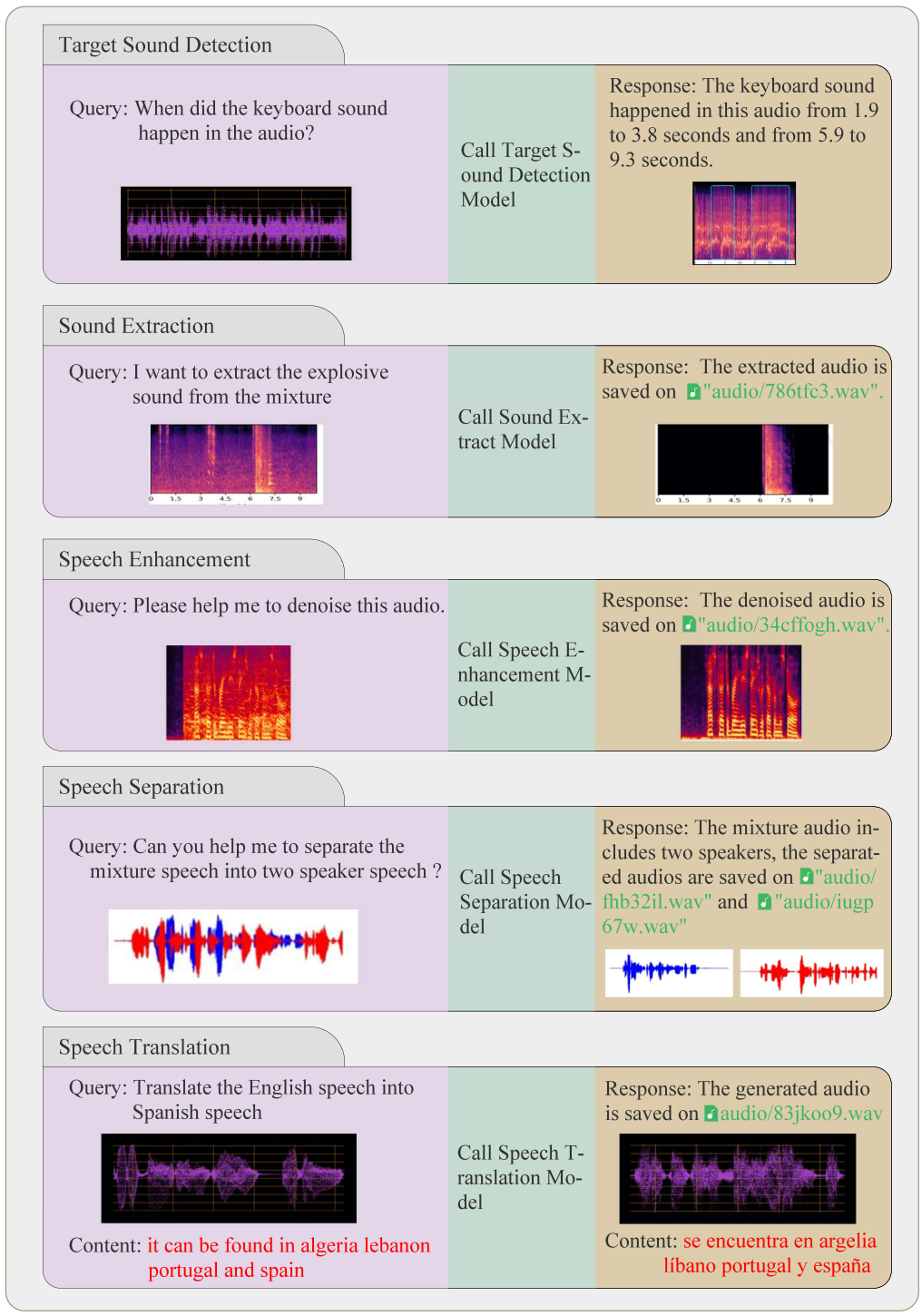
2. Case Study on Simple Tasks
다음은 AudioGPT의 간단한 task들에 대한 사례들이다.
Limitation
- 신속한 엔지니어링: AudioGPT는 ChatGPT를 사용하여 많은 foundation model을 연결하므로 오디오 foundation model을 자연어로 설명하기 위해 신속한 엔지니어링이 필요하며 이는 시간이 많이 걸리고 전문 지식이 필요할 수 있다.
- 길이 제한: ChatGPT의 최대 토큰 길이는 multi-round 대화를 제한할 수 있으며, 이는 사용자의 컨텍스트 지침에도 영향을 미친다.
- 능력 제한: AudioGPT는 오디오 정보를 처리하기 위해 오디오 foundation model에 크게 의존하며, 이러한 모델의 정확성과 효율성에 크게 영향을 받는다.