[논문리뷰] Attend-and-Excite: Attention-Based Semantic Guidance for Text-to-Image Diffusion Models
SIGGRAPH 2023. [Paper] [Page] [Github]
Hila Chefer, Yuval Alaluf, Yael Vinker, Lior Wolf, Daniel Cohen-Or
Tel Aviv University
31 Jan 2023

Introduction
텍스트 기반 이미지 생성의 최근 발전은 자유 형식 텍스트 프롬프트를 제공하여 다양하고 창의적인 이미지를 생성할 수 있는 전례 없는 능력을 보여주었다. 그러나 그러한 모델에 의해 생성된 이미지는 항상 대상 프롬프트의 semantic 의미를 충실하게 반영하지 않는 것으로 나타났다.
SOTA 텍스트 기반 이미지 생성 모델에서 두 가지 주요 semantic 문제가 있다.
- Catastrophic neglect: 프롬프트의 피사체 중 하나 이상이 생성되지 않는 문제
- 잘못된 속성 바인딩: 모델이 속성을 잘못된 피사체에 바인딩하거나 완전히 바인딩하지 못하는 문제

위 그림은 SOTA Stable Diffusion 모델에 의해 생성된 이미지이다. 왼쪽에는 모델이 파란색 고양이를 생성하지 못하고 그릇 생성에만 집중하는 catastrophic neglect의 예가 나와 있다. 오른쪽에서는 “노란색” 색상이 벤치에 잘못 바인딩된 잘못된 속성 바인딩 문제를 보여준다.
이러한 semantic 문제를 완화하기 위해 Generative Semantic Nursing (GSN)이라는 개념을 도입한다. GSN 프로세스에서는 denoising process의 각 step에서 latent code를 약간 이동하여 latent code가 입력 텍스트 프롬프트에서 전달된 semantic 정보를 더 잘 고려하도록 권장한다.
본 논문은 사전 학습된 diffusion model의 강력한 cross-attention map을 활용하는 Attend-and-Excite라는 GSN 형식을 제안한다. Attention map은 각 이미지 패치의 텍스트 토큰에 대한 확률 분포를 정의하며, 이는 패치에서 지배적인 토큰을 결정한다. 저자들은 이 텍스트-이미지 상호 작용이 무시되기 쉽다는 것을 관찰했다. 각 패치는 모든 텍스트 토큰에 자유롭게 attend할 수 있지만 이미지의 일부 패치가 모든 토큰에 attend하도록 보장하는 메커니즘은 없다. 피사체 토큰이 처리되지 않은 경우 해당 피사체는 출력 이미지에 나타나지 않는다.
따라서 직관적으로 생성된 이미지에 피사체가 존재하려면 모델은 피사체의 토큰에 적어도 하나의 이미지 패치를 할당해야 한다. Attend-and-Excite는 각 피사체 토큰이 이미지의 일부 패치에서 지배적임을 요구함으로써 이러한 직관을 구현한다. 각 denoising timestep에서 latent를 조심스럽게 가이드하고 모델이 모든 대상 토큰에 attend하고 activation을 강화하거나 자극하도록 권장한다. 중요한 것은 본 논문의 접근 방식이 inference 시간 동안 즉시 적용되며 추가 학습이나 fine-tuning이 필요하지 않다는 것이다. 대신 사전 학습된 생성 모델과 텍스트 인코더를 통해 이미 학습된 강력한 semantic을 보존한다.
Attend-and-Excite는 명시적으로 catastrophic neglect 문제만 다루지만, 속성과 해당 피사체 간의 올바른 바인딩을 암시적으로 장려한다. 이는 catastrophic neglect와 속성 바인딩이라는 두 가지 문제 사이의 연결에 기인할 수 있다. 사전 학습된 텍스트 인코더를 통해 얻은 텍스트 임베딩은 각 피사체와 해당 속성 간의 정보를 연결한다. 예를 들어, “a yellow Bowl and a blue cat”이라는 프롬프트에서 “cat” 토큰은 텍스트 인코딩 프로세스 중에 “blue” 토큰으로부터 정보를 받는다. 따라서 고양이에 대한 catastrophic neglect를 완화하면 이상적으로는 색상 속성이 향상된다 (ex. “cat”과 “blue” 간의 올바른 바인딩 허용).
Attend-and-Excite
본 논문의 방법의 핵심은 generative semantic nursing 아이디어로, 각 timestep에서 noised latent code를 점진적으로 더 의미론적으로 충실한 생성으로 이동한다. 각 denoising timestep $t$에서 프롬프트 $\mathcal{P}$의 피사체 토큰의 attention map을 고려한다. 직관적으로, 합성 이미지에 피사체가 존재하려면 이미지의 일부 패치에 높은 영향을 주어야 한다. 따라서 각 대상 토큰의 attention 값을 최대화하려는 목적 함수를 정의한다. 그런 다음 계산된 loss의 기울기에 따라 시간 $t$의 noised latent를 업데이트한다. 이는 다음 timestep의 latent가 모든 대상 토큰을 표현에 더 잘 통합하도록 장려한다. 이 조작은 inference 중에 즉석에서 발생한다. 즉, 추가 학습이 수행되지 않는다.

Attend-and-Excite의 개요는 위 그림과 같으며, 전체 알고리즘은 Algorithm 1과 같다.

Cross-attention map 추출
입력 프롬프트 $\mathcal{P}$가 주어지면 $\mathcal{P}$에 존재하는 모든 피사체 토큰 (ex. 명사)의 집합 \(\mathcal{S} = \{s_1, \ldots, s_k\}\)을 고려하자. 각 토큰 $s \in \mathcal{S}$에 대한 공간 attention map을 추출하는 것이 목표이며, attention map은 각 이미지 패치에 대한 $s$의 영향을 나타낸다. 현재 timestep에서 noised latent $z_t$를 고려하여 $z_t$와 $\mathcal{P}$를 사용하여 사전 학습된 UNet 네트워크를 통해 forward pass를 수행한다. 그런 다음 모든 16$\times$16 attention layer와 head를 평균한 후 얻은 cross-attention map을 고려한다. 집계된 map $A_t$에는 $\mathcal{P}$의 각 토큰에 대해 하나씩 $N$개의 공간 attention map이 포함된다.
\[\begin{equation} A_t \in \mathbb{R}^{16 \times 16 \times N} \end{equation}\]사전 학습된 CLIP 텍스트 인코더는 텍스트의 시작을 나타내는 특수 토큰 $\langle \textrm{sot} \rangle$를 $\mathcal{P}$ 앞에 추가한다. Stable Diffusion은 $A_t$에 정의된 토큰 분포에서 $\langle \textrm{sot} \rangle$을 $\mathcal{P}$ 토큰에 지속적으로 높은 attention 값을 할당하는 방법을 학습한다. 실제 프롬프트 토큰을 향상시키는 데 관심이 있으므로 $\langle \textrm{sot} \rangle$를 $\mathcal{P}$의 attention을 무시하고 나머지 토큰에 대해 softmax 연산을 수행하여 attention 값을 다시 평가한다. Softmax 연산 후 결과 행렬 $A_t$의 $(i, j)$번째 원소는 해당 이미지 패치에 각 텍스트 토큰이 존재할 확률을 나타낸다. 그런 다음 각 피사체 토큰 $s$에 대해 16$\times$16의 정규화된 attention map을 추출한다.
부드러운 attention map 얻기
위에서 계산한 attention 값 $A_t^s$는 결과 이미지에 객체가 생성되었는지 여부를 완전히 반영하지 못할 수도 있다. 특히 attention 값이 높은 단일 패치는 토큰 $s$에서 부분적인 정보가 전달되는 데서 비롯될 수 있다. 이는 모델이 전체 피사체를 생성하지 않고 오히려 피사체의 일부 부분과 유사한 패치를 생성할 때 발생할 수 있다.
이러한 결과를 피하기 위해 $A_t^s$에 가우시안 필터를 적용한다. 그렇게 하면 최대로 활성화된 패치의 attention 값은 인접 패치에 따라 달라진다. 이 연산 후 각 패치는 원본 맵에서 인접한 패치의 선형 결합이다.
실시간 최적화 수행
직관적으로, 성공적으로 생성된 피사체에는 해당 토큰에 크게 attned하는 이미지 패치가 있어야 한다. 최적화 목적 함수는 이러한 직관을 직접적으로 구현한다.
$S$의 각 피사체 토큰에 대해 activation 값이 높은 $A_t^s$의 패치가 하나 이상 존재하도록 권장해야 한다. 따라서 이 원하는 동작을 정량화하는 loss를 다음과 같이 정의한다.
\[\begin{equation} \mathcal{L} = \max_{s \in \mathcal{S}} \mathcal{L}_s \quad \textrm{where} \quad \mathcal{L}_s = 1 - \max (A_t^s) \end{equation}\]즉, loss는 현재 timestep $t$에서 가장 소홀히 여겨지는 대상 토큰의 activation을 강화하려고 시도한다. 서로 다른 timestep은 서로 다른 토큰을 강화할 수 있으며, 무시된 모든 대상 토큰이 특정 step에서 강화되도록 장려할 수 있다.
Loss $\mathcal{L}$을 계산한 후 현재 latent $z_t$를 다음과 같이 이동한다.
\[\begin{equation} z_t^\prime = z_t - \alpha_t \cdot \nabla_{z_t} \mathcal{L} \end{equation}\]여기서 $\alpha_t$는 기울기 업데이트의 step 크기를 정의하는 스칼라이다. 마지막으로, 다음 denoising step에 대한 $z_{t-1}$을 계산하기 위해 $z_t^\prime$을 사용하여 Stable Diffusion을 통해 또 다른 forward pass를 수행한다. 위의 업데이트 프로세스는 timestep의 하위 집합 $t = T, T-1, \ldots, t_\textrm{end}$에 대해 반복된다. 여기서 Stable Diffusion에 따라 $T = 50$으로 설정하고 $t_\textrm{end}$로 설정한다. 이는 최종 timestep이 생성된 이미지에서 객체의 공간적 위치를 변경하지 않는다는 관찰에 기반한다.
반복적인 latent 개선
지금까지 각 denoising timestep에서 한 번의 latent 업데이트를 수행했다. 그러나 초기 denoising 단계에서 토큰의 attention 값이 일정 값에 도달하지 못하는 경우 해당 객체가 생성되지 않는다. 따라서 모든 대상 토큰에 대해 미리 정의된 최소 attention 값이 달성될 때까지 $z_t$를 반복적으로 업데이트한다. 그러나 $z_t$의 많은 업데이트로 인해 latent가 분포 범위에서 벗어나 일관되지 않은 이미지가 생성될 수 있다. 따라서 이 개선은 timestep의 작은 하위 집합에 걸쳐 점진적으로 수행된다.
구체적으로 각 대상 토큰이 최소 0.8의 최대 attention 값에 도달하도록 한다. 점진적으로 이를 수행하기 위해 다양한 denoising step에서 반복 업데이트를 수행한다. 저자들은 iteration을 $t_1 = 0$, $t_2 = 10$, $t_3 = 20$으로 설정하고 최소 필수 activation 값을 $T_1 = 0.05$, $T_2 = 0.5$, $T_3 = 0.8$으로 설정하였다. 이러한 점진적인 개선을 통해 $z_t$가 분포 범위에서 벗어나는 것을 방지하는 동시에 더 충실한 생성을 장려할 수 있다.
설명 가능한 이미지 generator 얻기
Attention이 설명으로 사용될 수 있는 정도는 광범위하게 연구되었다. 텍스트 기반 이미지 생성의 맥락에서 cross-attention map은 모델에 대한 자연스러운 설명으로 간주되었다.

그러나 catastrophic neglect의 직접적인 결과는 위 그림의 왼쪽에서 볼 수 있듯이 무시된 대상에 해당하는 attention map이 더 이상 생성된 이미지에서 대상의 localization을 충실하게 나타내지 않는다는 것이다. 고양이가 올바르게 localize되면 개구리가 없기 때문에 개구리에 해당하는 map이 관련 없는 영역을 강조 표시한다. 따라서 cross-attention map은 오해의 소지가 있고 부정확하므로 실행 가능한 설명을 구성하지 않는다. 반대로, 위 그림의 오른쪽에서 볼 수 있듯이 Attend-and-Excite를 사용하여 무시를 완화함으로써 고양이와 개구리 모두 attention map에서 정확하게 localize되며 이제 이 map은 충실한 설명으로 간주될 수 있다.
Results
현재 텍스트 기반 이미지 생성의 semantic 문제를 분석하는 공개적으로 사용 가능한 데이터셋이 없기 때문에 저자들은 모든 방법을 평가하기 위한 새로운 벤치마크를 구성하였다. 저자들은 catastrophic neglect의 존재를 분석하기 위해 두 피사체를 포함하는 프롬프트를 구성하였다. 또한 올바른 속성 바인딩을 테스트하려면 프롬프트에 제목 토큰과 일치하는 다양한 속성이 포함되어야 한다.
저자들은 구체적으로 세 가지 유형의 텍스트 프롬프트를 고려하였다.
- “a [animalA] and a [animalB]”
- “a [animal] and a [color][object]”
- “a [colorA][objectA] and a [colorB ][objectB]”
프롬프트를 구성하기 위해 저자들은 12마리의 동물과 11가지 색상의 12개 물체를 고려하였다. 피사체-색상 쌍을 포함하는 각 프롬프트에 대해 피사체에 대한 색상을 무작위로 선택한다. 그 결과 66개의 동물-동물 및 물체-물체 쌍과 144개의 동물-물체 쌍이 생성되었다.
1. Qualitative Comparisons
다음은 본 논문이 사용한 데이터셋의 프롬프트를 사용한 정성적 비교 결과이다.

다음은 복잡한 장면과 여러 피사체 토큰을 설명하는 프롬프트를 사용하여 Stable Diffusion과 추가 비교한 결과이다.

다음은 StructureDiffusion의 프롬프트로 비교한 결과이다.

2. Quantitative Analysis
Text-Image Similarities
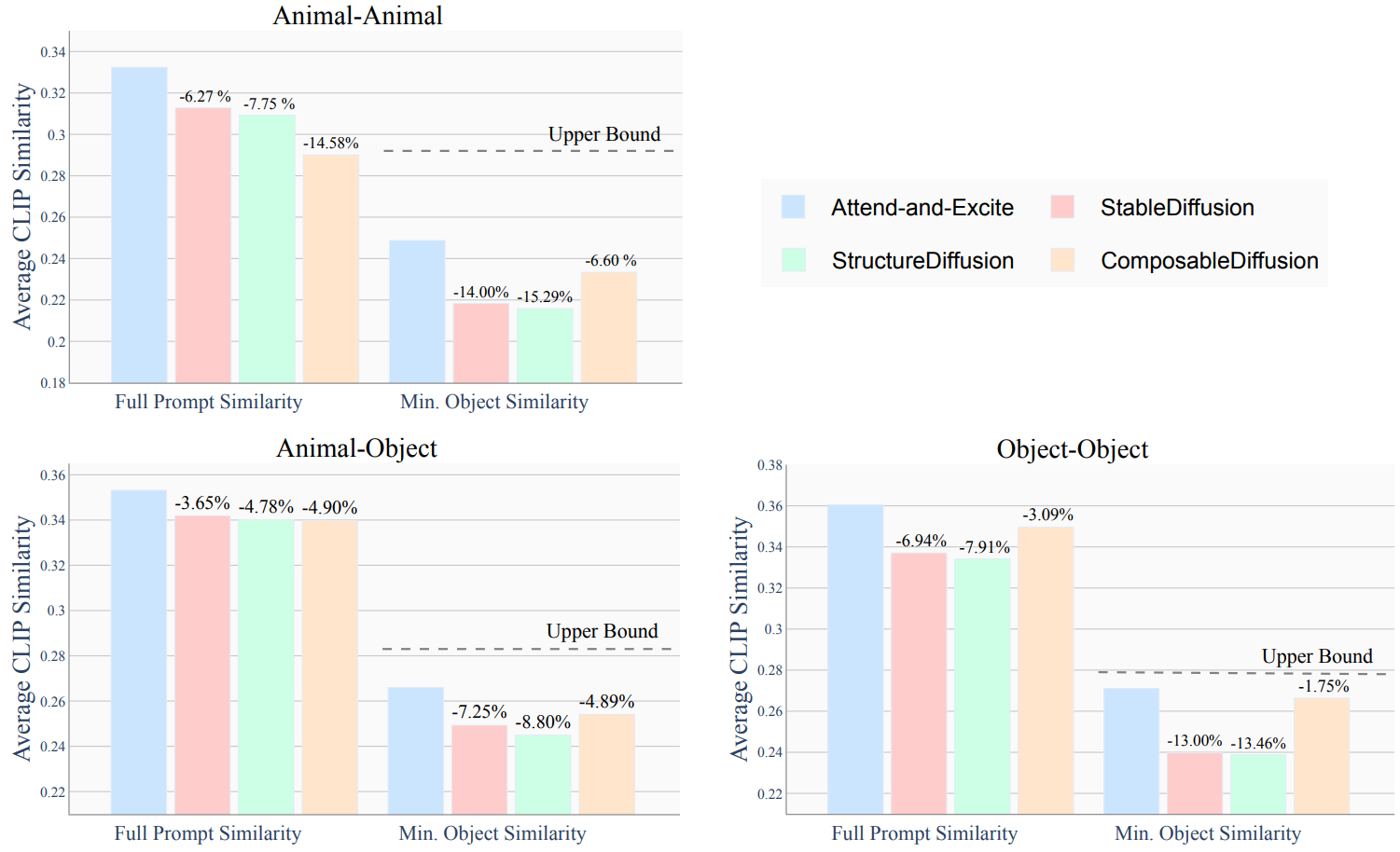
다음은 텍스트 프롬프트와 각 방법으로 생성된 이미지 사이의 평균 CLIP 이미지-텍스트 유사도를 비교한 그래프이다.
Text-Text Similarities
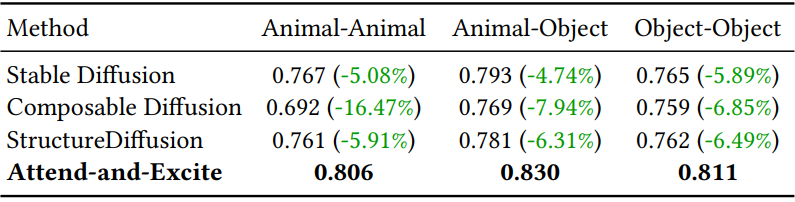
다음은 텍스트 프롬프트와 생성된 이미지에 대해 BLIP이 생성한 캡션 사이의 평균 CLIP 텍스트-텍스트 유사도를 비교한 표이다.
User Study
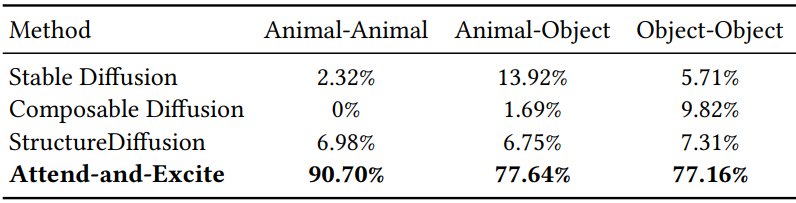
다음은 65명의 응답자를 대상으로 실시한 user study 결과이다.
Limitations

- 추가 학습을 적용하지 않기 때문에 생성 모델의 표현력에 의해 제한된다. 프롬프트가 모델이 학습한 텍스트 설명의 분포 밖에 있는 경우, 본 논문의 방법은 분포를 벗어난 latent를 만들어 텍스트 프롬프트와 일치하지 않는 이미지를 생성할 수 있다.
- 자연적으로 함께 나타나지 않는 피사체를 합성할 때 생성된 이미지는 덜 사실적일 수 있다. 이러한 조합은 Stable Diffusion이 실제 이미지에 대해 학습한 분포 밖에 존재하는 경향이 있다.
- 두 가지 핵심 semantic 문제를 해결하는 동안 의미론적으로 정확한 생성을 달성하기 위한 경로는 여전히 길고 복잡한 객체 합성 (ex. “riding on”, “in front of”, “beneath”)과 같은 해결해야 할 추가 과제가 있다.
- 부정 (ex. “not”)에 대해 Attend-and-Excite를 적용하는 방법을 연구하지는 않았다.