[논문리뷰] Approximately Aligned Decoding
NeurIPS 2025. [Paper] [Github]
Daniel Melcer, Sujan Gonugondla, Pramuditha Perera, Haifeng Qian, Wen-Hao Chiang, Yanjun Wang, Nihal Jain, Pranav Garg, Xiaofei Ma, Anoop Deoras
Northeastern University | Meta Superintelligence Labs | AWS NGDE | NVIDIA
1 Oct 2024
Introduction
LLM 출력에는 코드 문법 오류, 개인 정보 유출, 욕설, 잘못된 API 호출 등의 에러 혹은 제약 위반(constraint violation)이 발생할 수 있다. 이를 해결하는 기존 방법들은 두 가지 문제가 있다.
- Constrained Generation: 출력 분포를 심하게 왜곡
- Rejection Sampling, ASAp: 출력 분포는 정확하지만 계산 비용이 큼
본 논문에서는 추가적인 학습이나 fine-tuning 없이 계산 효율성과 출력 분포 유지 사이의 적절한 균형점을 찾는 Approximately Aligned Decoding (AprAD)을 제시하였다. AprAD는 본질적으로 speculative sampling 활용하여 에러 발생 후 백트래킹 동작을 결정한다.
Problem Statement
Error Set $\mathcal{B} \subset \mathcal{V}^\ast$을 에러를 포함하는 문자열의 집합으로 정의한다. $\mathcal{B}$는 종종 크기가 무한하며, black-box indicator function으로 취급한다. \(x_{1 \ldots n} \in \mathcal{B}\)이면, \(x_{1 \ldots n}\)을 prefix로 갖는 모든 문자열도 $\mathcal{B}$에 속한다 (에러는 텍스트를 더 붙여도 사라지지 않음).
주어진 언어 모델 $P$와 error set $\mathcal{B}$에 대해, 본 논문의 목표는 에러 시퀀스를 제외하고 정규화한 분포 \(\hat{P}^\mathcal{B}\)에서 효율적으로 샘플링하는 것이다.
\[\begin{equation} \hat{P}^\mathcal{B} (w) = \begin{cases} w \in \mathcal{B} & \quad 0 \\ w \notin \mathcal{B} & \quad \frac{P(w)}{\sum_{w \notin \mathcal{B}} P(w)} \end{cases} \end{equation}\]Rejection sampling은 \(\hat{P}^\mathcal{B}\)에서 샘플링하는 가장 간단한 방법이지만, \(\sum_{w \in \mathcal{B}} P(w)\)가 1에 가까워질수록 많은 평가 횟수가 필요할 수 있다.
Existing Approach
저자들은 여러 디코딩 방법들을 설명하기 위해 간단한 running example을 도입하였다. 가능한 토큰은 A와 B 두 가지이며, 목표는 길이가 2인 시퀀스를 생성하는 것이다. 모든 토큰의 확률은 1/2이므로, 처음에 제시된 네 가지 시퀀스 각각을 생성할 확률은 1/4이다. 시퀀스 AA는 에러이고, 에러가 아닌 시퀀스는 세 가지가 가능하다. 따라서 이상적인 정규화된 확률은 나머지 각 시퀀스에 대해 1/3이다.
Constrained Generation
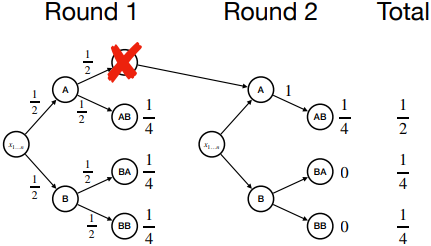
Constrained Generation은 에러를 유발하는 토큰을 즉시 마스킹하여 생성 시점에서 차단한다. Running example에서 첫 번째 토큰으로 A가 선택된 경우, 다음 토큰 후보에서 즉시 A가 마스킹되어 B가 샘플링된다.
문제는 이 과정을 통해 확률이 낮은 샘플이 크게 증폭되는 경우가 있다는 것이다. Running example에서 AB가 샘플링될 확률은 1/2이기 때문에 이상적인 확률인 1/3보다 1.5배 증폭된다.
| 이러한 왜곡은 엔트로피가 낮은 시나리오에서 더욱 심각하다. $P(B | A)$가 0.0001로 낮아지더라도 AB를 샘플링할 확률은 여전히 1/2이다. 이러한 증폭 효과는 시퀀스 길이가 길어질수록 기하급수적으로 증가한다. |
Adaptive Sampling with Approximate Expected Futures (ASAp)
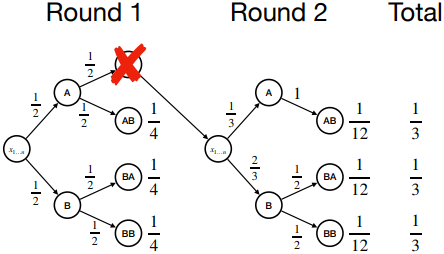
ASAp는 생성한 샘플 $x$가 에러이면, observed error set $B \subset \mathcal{B}$를 \(B \cup \{x\}\)로 업데이트하고, $\hat{P}^B$에서 다시 처음부터 샘플링한다. 문제는 error set에서 에러를 하나씩 발견해야 하므로, 에러가 많으면 샘플링이 기하급수적으로 느려진다는 것이다.
Posterior Estimation
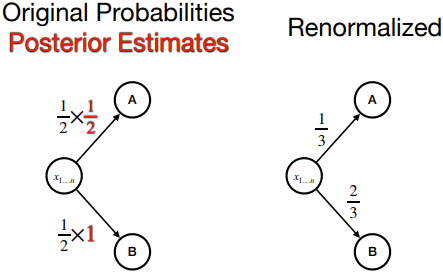
Posterior estimation 방법들은 주어진 prefix에 대하여 posterior를 추정하여 사전에 확률을 보정한다. 정확한 posterior estimator에 의존하며, 에러가 prefix와 무관한 경우 (ex. 특정 글자 회피) 추정이 어렵다.
Method
Constrained generation은 에러 발견 시 마지막 토큰만 교체하고 나머지 토큰은 재사용하며, ASAp는 모든 토큰을 버리고 처음부터 다시 생성한다. AprAD의 핵심 아이디어는 일부만 재사용하는 것이다. 얼마나 재사용할지를 speculative sampling을 통해 결정한다.
1. Speculative Sampling as a Prefix Selection Algorithm
ASAp에서 $\hat{P}^B$와 \(\hat{P}^{B \cup \{x\}}\)는 거의 항상 유사한 분포이며, $B$보다 \(B \cup \{x\}\)가 더 많은 에러 샘플을 가지고 있기 때문에 \(\hat{P}^{B \cup \{x\}}\)가 일반적으로 더 정확하다.
AprAD은 speculative decoding이 SSM에서 추출한 샘플을 LLM에서 추출한 샘플을 근사화하는 방식과 유사하게, 샘플 $x \sim \hat{P}^B$를 사용하여 샘플 \(x^\prime \sim \hat{P}^{B \cup \{x\}}\)를 근사한다. 즉, 확률 분포가 두 개의 별개 모델에서 생성되는 것이 아니라, 위반 샘플을 보정하기 전후에 동일한 모델에서 모두 생성된다. AprAD는 샘플링을 다시 시작하는 출발점으로 사용할 수 있는 $x$의 prefix를 speculative sampling으로 얻는다. $\hat{P}^B$와 \(\hat{P}^{B \cup \{x\}}\)의 분포가 매우 유사하기 때문에, 특히 언어 모델의 엔트로피가 상대적으로 높을 경우, 이 prefix는 일반적으로 $x$의 길이의 대부분을 차지한다.
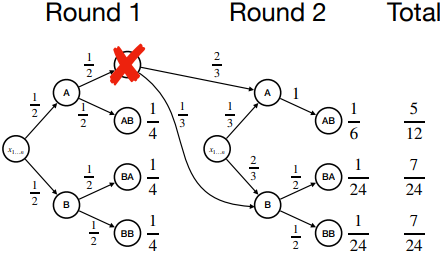
Running example에서 \(\frac{P^{\{AA\}} (A)}{P^{\{\}} (A)} = \frac{1/3}{1/2} = 2/3\)이므로, AprAD는 A를 2/3의 확률로 유지한다. 나머지 1/3은 다른 토큰들에 분배되며, 이 경우 나머지 토큰이 B 밖에 없으므로 B가 1/3의 확률로 선택된다.
전체 알고리즘은 아래와 같다.

AprAD는 에러를 발견한 후에만 SpecSample을 호출하기 때문에 일부 시퀀스 확률을 여전히 증폭시킨다. Speculative decoding의 경우, AB가 SSM에 의해 직접 생성된 경우에도 SpecSample이 호출된다. 그러나 AprAD는 AB를 즉시 수용한다. 알고리즘이 모든 가능한 prefix 문자열을 순회할 수 없기 때문에, AA가 실제로 샘플링된 경우를 제외하고는 AA에 에러가 있는지 여부를 확인하지 않는다. 이로 인해 출력 확률 분포에서 AB가 약간 증폭되는 결과가 나타난다 (1/3 $\rightarrow$ 5/12).
| 결과적으로 증폭은 constraint generation에 비해 현저히 적은데, 이는 확률 질량의 일부가 바로 인접한 시퀀스 외부로 전달되기 때문이다. 중요한 것은 AprAD가 확률 증폭의 극단적인 경우, 즉 \(\frac{\hat{P}^{B \cup \{x\}} (A)}{\hat{P}^B (A)}\)가 매우 낮은 경우 (ex. $P(B | A) \ll 0.5$)를 대부분 피한다는 점이다. 이러한 경우 백트래킹 후 A를 다시 선택할 가능성이 낮다. 이는 $P(B | A)$ 값에 관계없이 2라운드에서 항상 AB를 선택하는 constraint generation과 대조적이다. |
Experiments
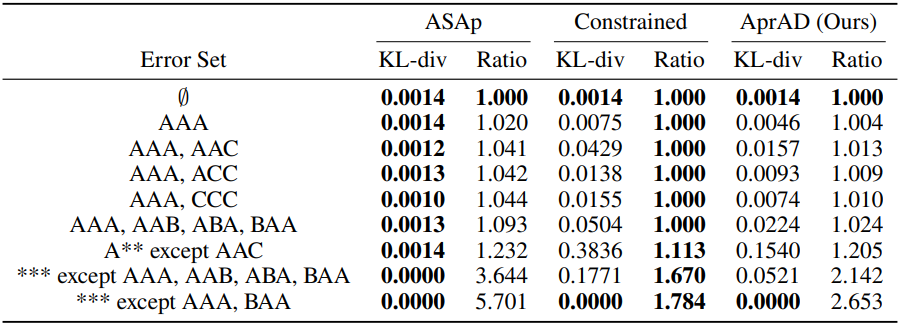
1. Simulated Model with Known Ideal Distribution
저자들은 세 가지 토큰 A, B, C 중 하나를 동일한 확률로 반환하는 모의 언어 모델을 사용하여 testbench를 구축하였다. 길이가 3인 시퀀스 $$k$개를 에러로 정의하고, 각 샘플링 방법을 사용하여 길이가 3인 시퀀스 10,000개를 샘플링하였다. 이상적인 분포는 에러가 아닌 시퀀스가 나올 확률이 모두 $\frac{1}{27-k}$이다.
다음은 관찰된 분포와 이상적인 분포 사이의 KL-divergence (KL-div)와 출력 길이 대비 모델을 평가해야 하는 횟수 (Ratio)를 비교한 결과이다.
2. Lipograms (Excluded Vowels)
다음은 Lipogram 평가 결과이다.

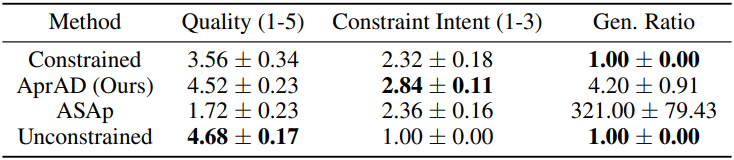
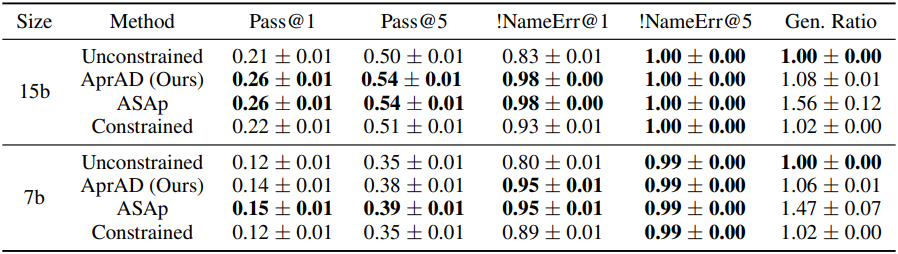
3. BigCodeBench Hallucination Avoidance
다음은 잘못된 API 호출을 잘 피하는 지에 대한 BigCodeBench v0.1에서의 평가 결과이다.