[논문리뷰] AnimateDiff: Animate Your Personalized Text-to-Image Diffusion Models without Specific Tuning
ICLR 2024. [Paper] [Page] [Github]
Yuwei Guo, Ceyuan Yang, Anyi Rao, Yaohui Wang, Yu Qiao, Dahua Lin, Bo Dai
Shanghai AI Laboratory | The Chinese University of Hong Kong | Stanford University
10 Jul 2023
Introduction
최근 몇 년 동안 text-to-image (T2I) 생성 모델은 높은 시각적 품질과 텍스트 기반 제어 가능성을 제공하기 때문에 연구 커뮤니티 내외에서 전례 없는 주목을 받았다. 기존 T2I 생성 모델의 창의성을 더욱 자극하기 위해 DreamBooth와 LoRA와 같은 몇 가지 가벼운 개인화 방법이 제안되었으며 RTX3080을 탑재한 노트북과 같은 장치를 사용하여 소규모 데이터셋에서 맞춤형 fine-tuning이 가능하고 품질이 크게 향상된 맞춤형 콘텐츠를 생성할 수 있다. 이러한 방식으로 사용자는 사전 학습된 T2I 모델에 매우 저렴한 비용으로 새로운 개념이나 스타일을 도입할 수 있으며, 결과적으로 CivitAI나 Huggingface와 같은 모델 공유 플랫폼에서 예술가와 아마추어가 기여한 수많은 개인화된 모델이 생성되었다.
DreamBooth 또는 LoRA로 학습된 개인화된 T2I 모델은 탁월한 시각적 품질로 성공적으로 주목을 받았지만 출력은 정적인 이미지이다. 즉, 시간적 자유도가 부족하다. 애니메이션의 광범위한 응용을 고려하여 기존의 개인화된 T2I 모델 대부분을 원래의 시각적 품질을 유지하면서 애니메이션 이미지를 생성하는 모델로 전환하는 것이 본 논문의 목표이다. 최근의 일반적인 text-to-video 생성 접근 방식은 시간 모델링을 원래 T2I 모델에 통합하고 동영상 데이터셋에서 모델을 튜닝하는 것을 제안하였다. 그러나 사용자는 일반적으로 민감한 hyperparameter 튜닝, 개인화된 동영상 수집, 엄청난 계산 리소스를 감당할 수 없기 때문에 개인화된 T2I 모델을 사용하는 것은 어렵다.
본 논문에서는 개인화된 T2I 모델에 대한 애니메이션 이미지를 생성할 수 있는 일반적인 방법인 AnimateDiff를 제시한다. 이를 통해 모델별 튜닝이 필요하지 않고 시간이 지남에 따라 매력적인 콘텐츠 일관성을 달성할 수 있다. 대부분의 개인화된 T2I 모델이 동일한 기본 모델(예: Stable Diffusion)에서 파생되고 모든 개인화된 도메인에 대해 해당 동영상을 수집하는 것이 완전히 불가능하다는 점을 고려하여 저자들은 대부분의 개인화된 T2I 모델을 한 번에 애니메이션화할 수 있는 모션 모델링 모듈을 설계하였다. 구체적으로 모션 모델링 모듈을 기본 T2I 모델에 도입한 다음 대규모 동영상 클립으로 fine-tuning하여 합리적인 모션 사전 학습을 수행한다. 기본 모델의 파라미터는 그대로 유지된다. Fine-tuning 후에는 개인화된 T2I가 잘 학습된 모션 prior를 활용하여 부드럽고 매력적인 애니메이션을 생성할 수 있다. 즉, 모션 모델링 모듈은 추가 데이터 수집이나 맞춤형 학습에 대한 추가 노력 없이 해당하는 모든 개인화된 T2I 모델을 애니메이션화하도록 관리한다.
Method
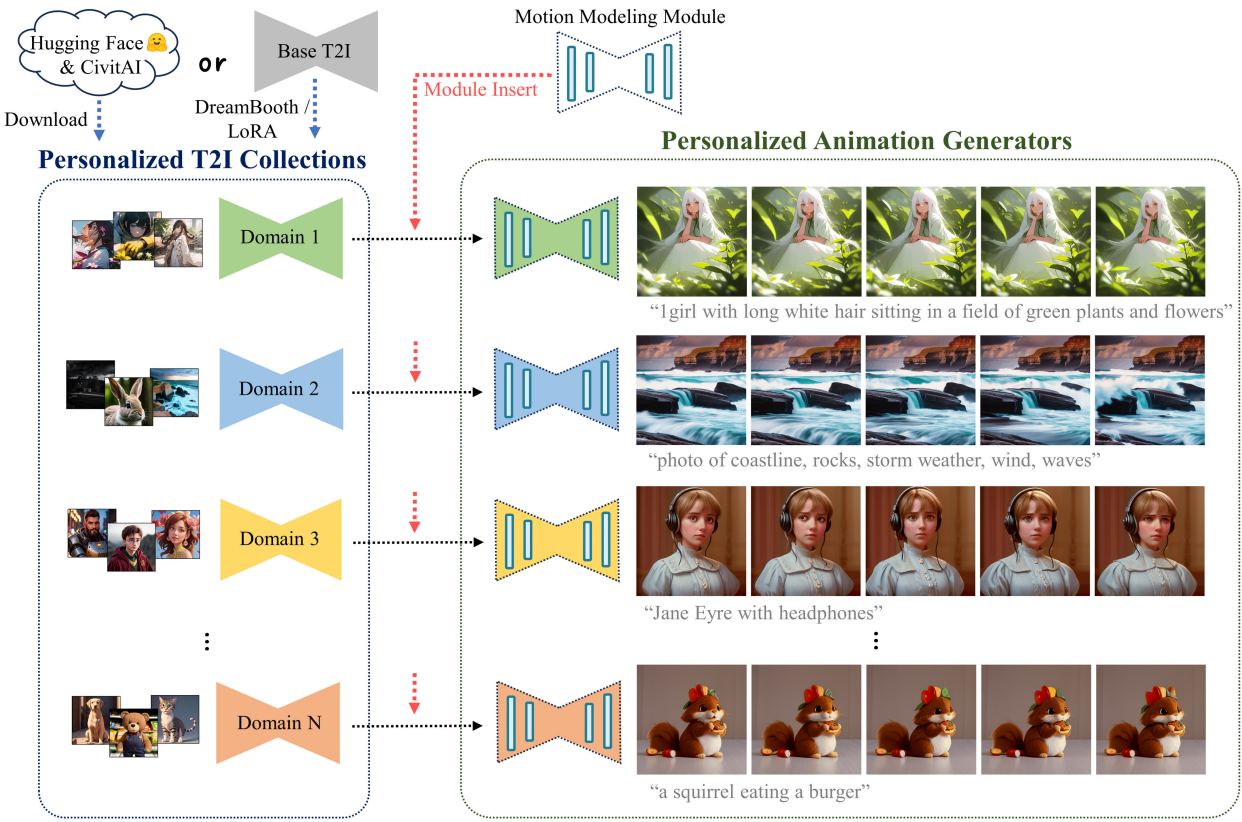
1. Personalized Animation
개인화된 이미지 모델을 애니메이션화하려면 일반적으로 해당 동영상 컬렉션으로 추가로 fine-tuning해야 하므로 훨씬 더 어려워진다. 본 논문은 사용자가 학습하거나 CivitAI 또는 Huggingface에서 다운로드한 DreamBooth 또는 LoRA 체크포인트와 같이 개인화된 T2I 모델이 주어지면 이를 애니메이션 생성기로 변환하는 것이 목표이다. 원래의 도메인 지식과 품질을 유지하면서 학습 비용이 거의 또는 전혀 들지 않는다. 예를 들어, T2I 모델이 특정 2D 애니메이션 스타일에 맞게 개인화되었다고 가정해 보자. 이 경우 해당 애니메이션 생성기는 전경/배경 분할, 캐릭터 신체 움직임 등과 같은 적절한 동작으로 해당 스타일의 애니메이션 클립을 생성할 수 있어야 한다.
한 가지 단순한 접근 방식은 temporal-aware 구조를 추가하고 대규모 동영상 데이터셋에서 합리적인 모션 사전 학습을 통해 T2I 모델을 확장하는 것이다. 그러나 개인화된 도메인의 경우 충분한 개인화된 동영상을 수집하는 데 비용이 많이 든다. 한편, 제한된 데이터는 원본 도메인의 지식 손실로 이어질 수 있다. 따라서 일반화 가능한 모션 모델링 모듈을 별도로 학습시키고 inference 시 이를 개인화된 T2I에 연결한다. 이를 통해 각 개인화된 모델에 대한 튜닝을 피하고 사전 학습된 가중치를 변경하지 않고 유지하여 지식을 유지한다. 이러한 접근 방식의 또 다른 중요한 이점은 모듈이 학습되면 특정 튜닝이 필요 없이 동일한 기본 모델의 모든 개인화된 T2I에 삽입될 수 있다는 것이다. 이는 개인화 프로세스가 기본 T2I 모델의 feature space를 거의 수정하지 않기 때문이다.
2. Motion Modeling Module
Network Inflation
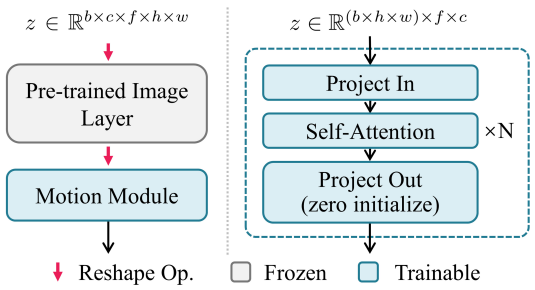
원본 Stable Diffusion은 이미지 데이터 batch만 처리할 수 있기 때문에 batch $\times$ 채널 $\times$ 프레임 $\times$ 높이 $\times$ 너비 형태의 5차원 동영상 텐서를 입력으로 사용하는 모션 모델링 모듈과 호환되도록 모델 인플레이션이 필요하다. 이를 위해 Video Diffusion Model과 유사한 솔루션을 채택한다. 구체적으로, 프레임 축을 batch 축으로 재형성하고 네트워크가 각 프레임을 독립적으로 처리할 수 있도록 하여 원본 이미지 모델의 각 2D convolution layer와 attention layer를 spatial-only pseudo-3D layer로 변환한다. 새로 삽입된 모션 모듈은 각 batch의 프레임 전체에서 작동하여 애니메이션 클립의 부드러운 모션과 콘텐츠 일관성을 달성한다. 자세한 내용은 위 그림 3에 설명되어 있다.
Module Design
모션 모델링 모듈의 네트워크 디자인의 경우 프레임 간 효율적인 정보 교환을 목표로 한다. 이를 위해 저자들은 모션 모듈의 디자인으로 temporal transformer를 선택했다. 저자들은 모션 모듈에 대한 다른 네트워크 디자인도 실험했으며 temporal transformer가 모션 사전 모델링에 적합하다는 사실을 발견했다.
Temporal transformer는 시간 축을 따라 작동하는 여러 self-attention 블록으로 구성된다. 모션 모듈을 통과할 때 feature map $z$의 높이와 너비는 먼저 batch 차원으로 재구성되어 프레임 길이에서 batch $\times$ 높이 $\times$ 너비 시퀀스가 생성된다. 그런 다음 재구성된 feature map이 project되고 여러 self-attention 블록을 거치게 된다.
\[\begin{equation} z = \textrm{Attention} (Q, K, V) = \textrm{Softmax} (\frac{QK^\top}{\sqrt{d}}) \cdot V \\ \textrm{where} \; Q = W^Q z, \; K = W^K z \; V = W^V z \end{equation}\]이 연산을 통해 모듈은 시간 축에서 동일한 위치에 있는 feature 간의 시간적 의존성을 캡처할 수 있다. 모션 모듈의 receptive field를 확대하기 위해 U자형 diffusion network의 모든 해상도 레벨에 이를 삽입한다. 또한 네트워크가 애니메이션 클립에서 현재 프레임의 시간적 위치를 인식할 수 있도록 self-attention 블록에 sinusoidal position encoding을 추가한다. 학습 중에 유해한 영향 없이 모듈을 삽입하기 위해 temporal transformer의 출력 projection layer를 0으로 초기화한다.
Training Objective
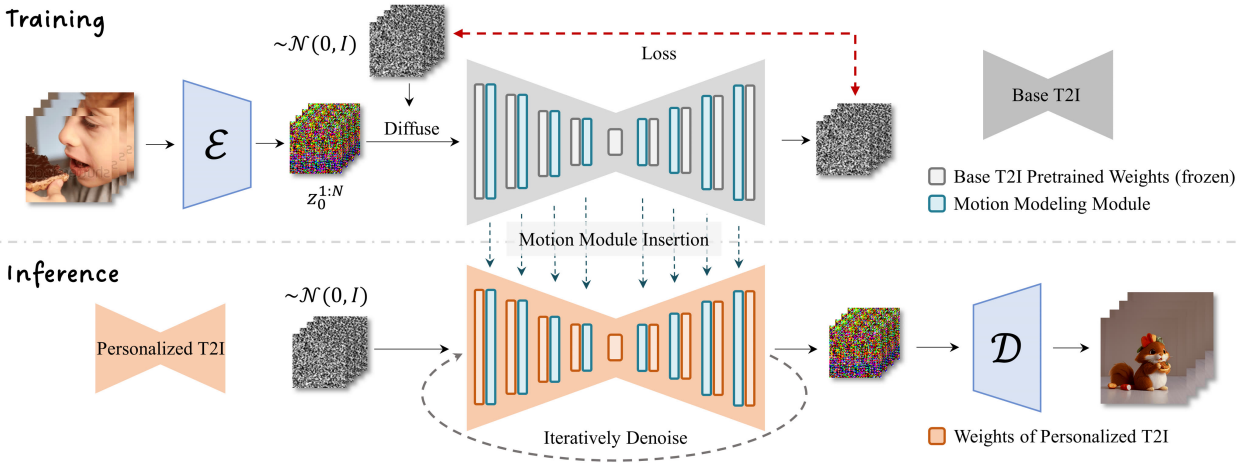
모션 모델링 모듈의 학습 과정은 Latent Diffusion Model과 유사하다. 샘플링된 동영상 데이터 $x_0^{1:N}$은 먼저 사전 학습된 오토인코더를 통해 프레임별로 latent code $z_0^{1:N}$으로 인코딩된다. 그런 다음 정의된 forward diffusion schedule을 사용하여 latent code에 noise가 추가된다. 모션 모듈로 확장된 diffusion network는 noisy한 latent code와 텍스트 프롬프트를 입력으로 사용하고 L2 loss 항에 의해 latent code에 추가되는 noise 강도를 예측한다. 모션 모델링 모듈의 최종 목적 함수는 다음과 같다.
\[\begin{equation} \mathcal{L} = \mathbb{E}_{\mathcal{E}(x_0^{1:N}, y, \epsilon \sim \mathcal{N}(0, I, t))} [\| \epsilon - \epsilon_\theta (z_t^{1:N}, t, \tau_\theta (y)) \|_2^2] \end{equation}\]최적화 중에 기본 T2I 모델의 사전 학습된 가중치는 feature space를 변경하지 않고 유지하기 위해 고정된다.
Experiments
- 데이터셋: WebVid-10M
- Base model: Stable Diffusion v1
- 학습 해상도: 256$\times$256
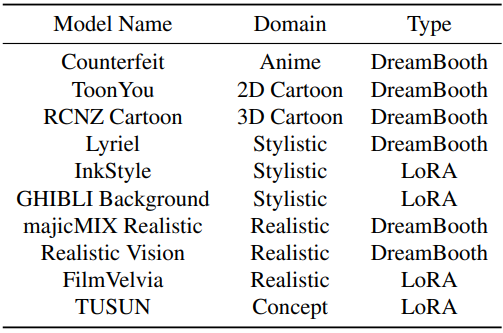
사용된 개인화된 모델들은 다음과 같다.
1. Qualitative Results
다음은 여러 모델들에 대한 정성적 결과이다.
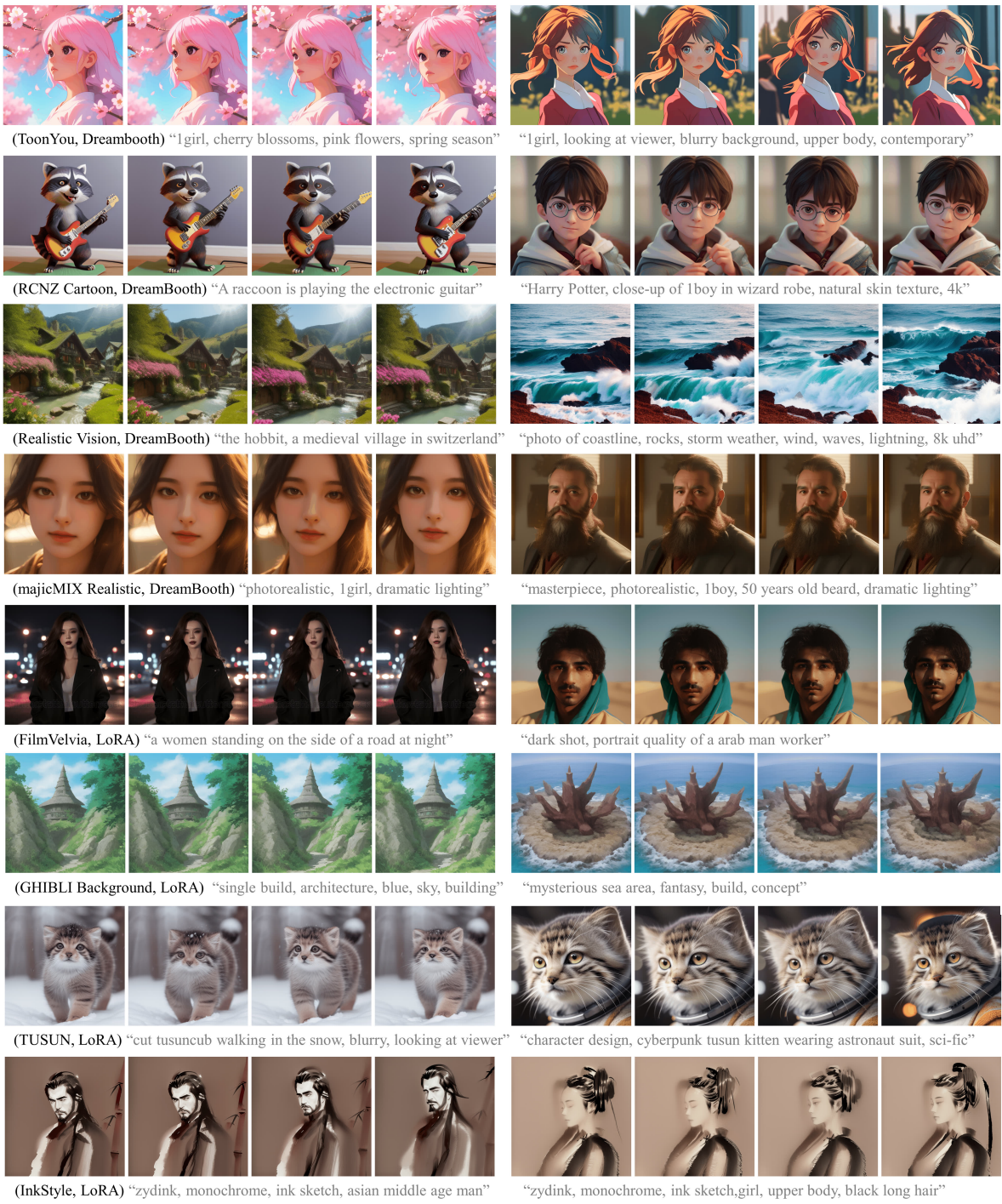
2. Comparison with Baselines
다음은 Text2Video-Zero와 AnimateDiff 사이의 프레임 간 콘텐츠 일관성을 정성적으로 비교한 것이다.

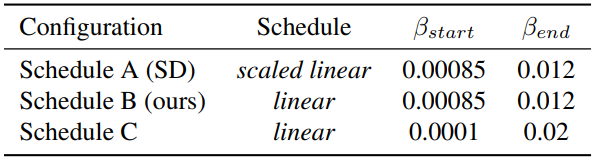
3. Ablative Study
다음은 3가지 diffusion schedule에 대한 ablation study 결과이다.

Limitations

개인화된 T2I 모델의 도메인이 2D 디즈니 만화와 같이 현실적이지 않을 때 대부분의 실패 사례가 나타난다. 이러한 경우 애니메이션 결과에 명백한 아티팩트가 있어 적절한 동작을 생성할 수 없다. 저자들은 이것이 학습 동영상과 개인화된 모델 사이의 큰 분포 격차 때문이라고 가정하였다.