[논문리뷰] Animate Anyone 2: High-Fidelity Character Image Animation with Environment Affordance
arXiv 2025. [Paper] [Page]
Li Hu, Guangyuan Wang, Zhen Shen, Xin Gao, Dechao Meng, Lian Zhuo, Peng Zhang, Bang Zhang, Liefeng Bo
Alibaba Group
10 Feb 2025

Introduction
캐릭터 이미지 애니메이션의 목적은 레퍼런스 캐릭터 이미지와 모션 신호 시퀀스를 활용하여 애니메이션 동영상 시퀀스를 합성하는 것이다. 최근에는 주로 diffusion 기반 프레임워크를 채택하여 외관 일관성, 모션 안정성, 캐릭터 일반화에서 눈에 띄는 향상을 달성했다.
최근 모델들에서 모션 신호는 일반적으로 서로 다른 동영상에서 추출되는 반면 캐릭터의 주변 환경은 정적 이미지에서 파생된다. 이러한 설정은 중요한 한계를 도입한다. 애니메이션 캐릭터와 환경 간의 공간적 관계는 종종 진정성이 부족하고 본질적인 인간-물체 상호작용이 중단된다. 결과적으로 대부분의 기존 방법은 캐릭터와 주변 환경 간의 복잡한 공간적 및 상호작용적 관계를 적절히 포착하지 못한 채 단순한 모션을 애니메이션화하는 데 주로 제한된다.
본 논문에서는 환경을 갖춘 캐릭터 이미지 애니메이션을 도입하여 캐릭터 애니메이션의 범위를 확장하고자 한다. 구체적으로, 캐릭터 이미지와 소스 동영상이 주어졌을 때, 생성된 캐릭터 애니메이션은 다음과 같아야 한다.
- 소스 동영상에서 원하는 캐릭터 모션을 상속한다.
- 소스 동영상과 일치하는 캐릭터-환경 관계를 정확하게 보여준다.
이 설정은 애니메이션 프로세스 전반에 걸쳐 캐릭터와 환경 간의 정확한 상호작용을 보장하는 동시에, 모델이 다양하고 복잡한 캐릭터 모션을 효과적으로 처리해야 하기 때문에 캐릭터 애니메이션에 새로운 과제를 제시한다.
이를 위해 본 논문은 새로운 프레임워크인 Animate Anyone 2를 소개한다. 모션 신호만을 활용하는 기존의 캐릭터 애니메이션 방법과 달리, Animate Anyone 2는 소스 동영상에서 환경 표현을 조건부 입력으로 추가로 캡처하여, 모델이 캐릭터와 환경 간의 본질적인 관계를 end-to-end 방식으로 학습할 수 있도록 한다.
저자들은 캐릭터 영역을 제거하여 환경을 정의하고, 모델이 이 영역을 채우도록 캐릭터를 생성하면서도 환경적 맥락과의 일관성을 유지하도록 한다. 또한, 캐릭터와 주변 장면 간의 경계 관계를 더 잘 표현하는 형태에 구애받지 않는 마스크 전략을 개발하였다. 이 전략은 형태 누출 문제를 완화하는 동시에 캐릭터-환경 통합을 위한 효과적인 학습을 가능하게 한다.
저자들은 물체 상호작용의 충실도를 높이기 위해, 상호작용하는 물체 영역을 추가로 처리하였다. 가벼운 object guider를 통해 상호작용하는 물체의 feature를 추출하고, feature를 생성 프로세스에 주입하기 위해 spatial blending 메커니즘을 제안하였다. 이를 통해, 소스 동영상에서 복잡한 상호작용 역학을 보존하는 것을 용이하게 한다.
마지막으로, 캐릭터 모션 모델링을 위해 depth-wise pose modulation 방식을 제안하여 더욱 다양하고 복잡한 캐릭터 포즈를 더욱 견고하게 처리할 수 있는 모델을 구축하였다.
Animate Anyone 2는 크게 세 가지 주요 장점을 가진다.
- 원활한 장면 통합
- 일관된 물체 상호작용
- 다양하고 복잡한 모션의 견고한 처리
Method
1. Framework
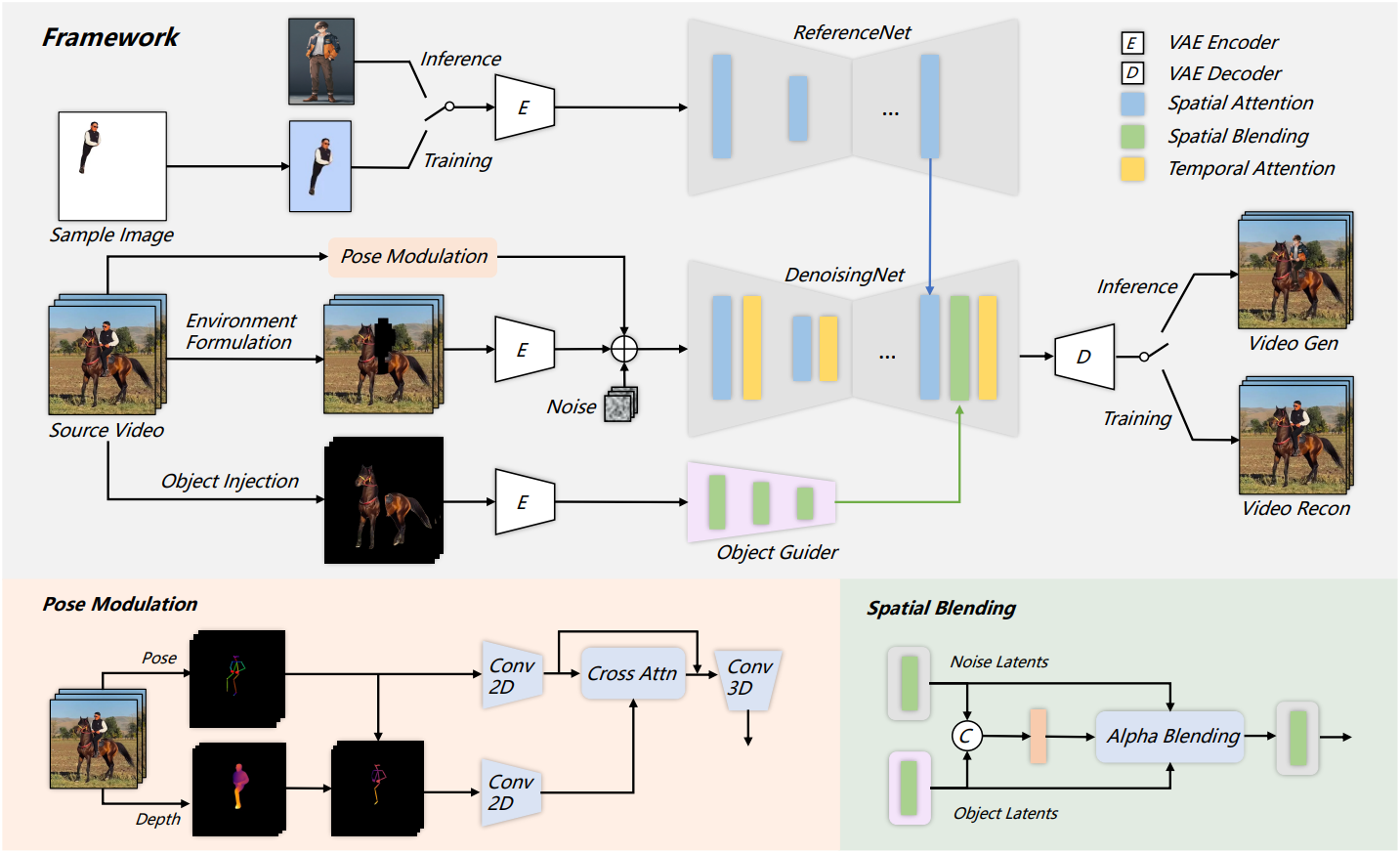
System Setting
학습하는 동안 self-supervised learning 전략을 사용한다. 프레임이 $N$개인 레퍼런스 동영상 $I^{1:N}$이 주어지면, 구성한 마스크를 통해 캐릭터와 환경을 분리하여 별도의 캐릭터 시퀀스 $I_c^{1:N}$와 환경 시퀀스 $I_e^{1:N}$를 얻는다. 더욱 충실한 물체 상호작용을 위해, 물체 시퀀스 $I_o^{1:N}$를 추가로 추출한다. 또한, 모션 시퀀스 $I_m^{1:N}$이 구동 신호로 추출된다. $I_c^{1:N}$에서 무작위로 샘플링한 후 center crop하고 랜덤한 배경에 합성하여 캐릭터 이미지 $I_c$를 얻는다.
캐릭터 이미지 $I_c$, 모션 시퀀스 $I_m^{1:N}$, 환경 시퀀스 $I_e^{1:N}$, 물체 시퀀스 $I_o^{1:N}$를 입력으로 받으면 모델은 레퍼런스 동영상 $I^{1:N}$을 재구성한다. Inference 시에는, 대상 캐릭터 이미지와 임의의 동영상이 주어지면 동영상에 해당하는 일관된 모션과 환경 관계로 캐릭터를 애니메이션화할 수 있다.
Diffusion Model
Animate Anyone 2는 LDM을 기반으로 개발되었다. 사전 학습된 VAE를 사용하여 이미지를 픽셀 공간에서 latent space로 변환한다.
\[\begin{equation} \textbf{z} = \mathcal{E}(\textbf{x}) \end{equation}\]학습하는 동안, 랜덤 Gaussian noise $\epsilon$이 다양한 timestep에서 이미지 latent \(\textbf{z}_t\)에 점진적으로 추가된다. 학습 loss는 다음과 같다.
\[\begin{equation} \textbf{L} = \mathbb{E}_{\textbf{z}_t, c, \epsilon, t} [\| \epsilon - \epsilon_\theta (\textbf{z}_t, c, t) \|_2^2] \end{equation}\](\(\epsilon_\theta\)는 DenoisingNet, $c$는 조건부 입력)
Inference하는 동안, noise latent는 반복적으로 denoising되고 VAE의 디코더를 통해 이미지로 재구성된다.
\[\begin{equation} \textbf{x}_\textrm{recon} = \mathcal{D}(\textbf{z}) \end{equation}\]DenoisingNet의 네트워크 디자인은 Stable Diffusion에서 파생되며, 사전 학습된 가중치를 상속한다. 저자들은 원래의 2D UNet 아키텍처를 3D UNet으로 확장하여 AnimateDiff의 temporal layer 디자인을 통합하였다.
Conditional Generation
저자들은 캐릭터 이미지 $I_c$의 외관 feature를 추출하기 위해 Animate Anyone의 ReferenceNet 아키텍처를 채택하였다. 본 논문의 프레임워크에서는 spatial attention을 통해 DenoisingNet 디코더의 중간 블록과 위쪽 블록에서만 이러한 feature를 병합하여 계산 복잡도를 낮춘다.
또한, 소스 동영상에서 세 가지 조건부 임베딩, 환경 시퀀스 $I_e^{1:N}$, 모션 시퀀스 $I_m^{1:N}$, 물체 시퀀스 $I_o^{1:N}$을 추출한다. 각 조건부 임베딩은 다음과 같이 처리된다.
- 환경 시퀀스: VAE 인코더를 사용하여 임베딩을 인코딩한 다음 noise latent와 병합
- 모션 시퀀스: pose modulation 전략을 사용하고, 모션 정보도 noise latent에 병합
- 물체 시퀀스: VAE 인코더를 통해 인코딩한 후 object guider에서 멀티스케일 feature를 추출하고 spatial blending을 통해 DenoisingNet에 주입
2. Environment Formulation
Motivation
본 논문의 프레임워크에서 환경은 캐릭터를 제외한 영역으로 정의한다. 학습 과정에서 모델은 이 영역을 채울 캐릭터를 생성하며, 동시에 환경적 맥락과의 일관성을 유지해야 한다.
캐릭터와 환경 간의 경계 관계는 매우 중요하다. 적절한 경계 guidance는 캐릭터 형태의 일관성과 환경 정보의 무결성을 유지하면서 모델이 캐릭터-환경 통합을 보다 효과적으로 학습하는 데 도움이 될 수 있다. Bounding box를 이용하여 생성 영역을 표현하면, 복잡한 장면을 다룰 때 컨디셔닝이 충분하지 않아 소스 동영상에 아티팩트나 불일치가 관찰된다. 반대로 정확한 마스크를 직접 사용하면 형태 누출이 발생할 가능성이 있다.
Self-supervised learning 전략으로 인해, 캐릭터 윤곽선과 마스크 경계 사이에 강한 상관 관계가 있다. 결과적으로 모델은 이 정보를 캐릭터 애니메이션을 위한 추가 guidance로 사용하는 경향이 있다. 그러나 inference 과정에서 타겟 캐릭터의 체형이나 의상이 소스 캐릭터와 다를 경우, 모델이 마스크 경계에 강제로 맞추려고 하면서 아티팩트가 발생할 수 있다.
Shape-agnostic Mask
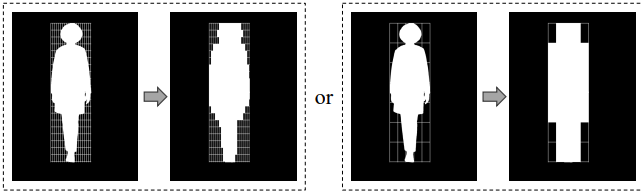
저자들의 핵심 아이디어는 학습 중에 마스크 영역과 캐릭터 윤곽선 사이의 대응 관계를 방해하는 것이다. 이를 위해 형태와 무관한 마스크 (shape-agnostic mask) 전략을 제안하였다.
구체적으로, $h \times w$ 크기의 bounding box에 있는 캐릭터 마스크 $M_c$에 대해, 두 개의 계수 $k_h$와 $k_w$를 정의하고 캐릭터 마스크 $M_c$를 $k_h \times k_w$개의 겹치지 않는 블록으로 나눈다. 패치별 최대값을 전파하여 마스크 $M_c$를 새로운 마스크 $M_f$로 재구성한다.
\[\begin{equation} M_f (i,j) = \max_{(i,j) \in P_c^{(k)}} P_c^{(k)} (i,j) \end{equation}\]($P_c^{(k)}$는 $k$번째 분할된 패치)
이 전략을 사용하면 마스크가 캐릭터 경계에서 벗어나는 다양한 모양을 동적으로 생성하여 네트워크가 사전 정의된 경계 제약 없이 컨텍스트 통합을 보다 효과적으로 학습하도록 한다. Inference 시에는 $k_h = h/10$, $k_w = w/10$으로 설정한다.
Random Scale Augmentation
새로운 마스크 $M_f$는 본래 마스크 $M_c$보다 본질적으로 크기 때문에, 생성된 캐릭터가 주어진 마스크보다 반드시 작아야 하는 불가피한 편향이 발생한다. 이 편향을 완화하기 위해 소스 동영상에 random scale augmentation을 적용한다. 구체적으로, 마스크를 기반으로 상호작용하는 물체와 함께 캐릭터를 추출하고 random scaling 연산을 적용한다. 그런 다음, 이러한 scaling된 콘텐츠를 다시 소스 동영상으로 재구성한다. 이 접근 방식은 마스크 $M_f$가 실제 캐릭터 영역보다 작을 확률이 있음을 보장한다. Inference하는 동안 모델은 마스크의 크기에 제약받지 않고 유연하게 캐릭터를 애니메이션화할 수 있다.
3. Object Injection
Object Guider
위와 같은 환경 형성 전략은 잠재적으로 물체 영역의 왜곡으로 이어질 수 있다. 저자들은 물체 상호작용의 보존을 강화하기 위해 추가로 object-level feature를 주입하는 것을 제안하였다. 상호작용 물체는 두 가지 방법을 통해 추출할 수 있다.
- VLM을 활용하여 물체 위치를 얻는다.
- 수동 주석을 통해 물체 위치를 인터랙티브하게 확인한다.
그런 다음 SAM2로 물체 마스크를 추출하여 해당 물체 이미지를 얻고, VAE 인코더를 통해 object latent들로 인코딩한다.
Object feature들을 병합하는 단순한 방법은 네트워크에 공급하기 전에 장면과 object feature를 직접 concat하는 것이다. 그러나 캐릭터와 물체 사이의 복잡한 관계로 인해 이러한 방법은 복잡한 인간-물체 상호작용을 처리하는 데 어려움을 겪고, 종종 인간과 물체의 디테일을 모두 포착하는 데 부족하다.
따라서 저자들은 object-level feature를 추출하기 위한 object guider를 설계하였다. 복잡한 모델링이 필요한 캐릭터 feature와 달리 물체는 본질적으로 소스 동영상의 시각적 특성을 보존한다. 따라서 가벼운 fully convolutional 아키텍처를 사용하여 object guider를 구현하였다.
구체적으로, object latent들을 3$\times$3 Conv2D를 통해 4번 다운샘플링하여 멀티스케일 feature를 얻는다. 이러한 feature들의 채널 크기는 DenoisingNet의 중간 블록과 위쪽 블록의 크기와 일치하여 이후의 feature 융합을 용이하게 한다.
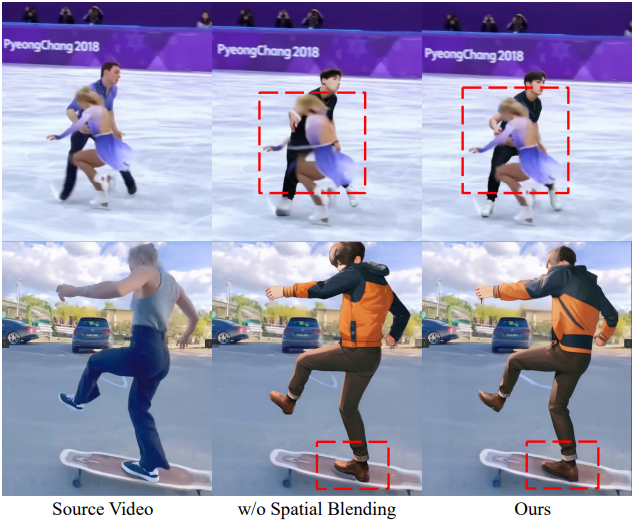
Spatial Blending
인간-물체 상호작용의 공간적 관계를 복구하기 위해, spatial blending을 사용하여 object guider가 추출한 feature들을 DenoisingNet에 주입한다. 구체적으로, denoising process 동안 spatial blending layer는 spatial attention layer 다음에 수행된다. Noise latent \(\textbf{z}_\textrm{noise}\)와 object latent \(\textbf{z}_\textrm{object}\)를 concat하고 Conv2D-Sigmoid layer를 통해 알파 가중치 $\alpha$를 계산한다.
\[\begin{equation} \alpha = F(\textrm{cat}(\textbf{z}_\textrm{noise}, \textbf{z}_\textrm{object})) \\ \textbf{z}_\textrm{blend} = \alpha \cdot \textbf{z}_\textrm{object} + (1 - \alpha) \cdot \textbf{z}_\textrm{noise} \end{equation}\]($F$는 zero convolution을 통해 초기화되는 Conv2D-Sigmoid layer, \(\textbf{z}_\textrm{blend}\)는 spatial blending 후의 새로운 noise latent)
DenoisingNet 디코더의 각 단계에서 캐릭터 feature에 대한 spatial attention과 object feature의 spatial blending을 번갈아가며 적용한다.
4. Pose Modulation
Motivation
Animate Anyone은 캐릭터 모션을 포착하기 위해 스켈레톤 표현을 사용하고, feature 모델링을 위해 pose guider를 활용하였다. 그러나 스켈레톤 표현은 팔다리 간의 공간 관계와 계층적 종속성을 명시적으로 모델링하지 못한다. 일부 기존 방법은 SMPL과 같은 3D 메쉬 표현을 사용하였지만, 이는 캐릭터 전체에 대한 일반화를 손상시키는 경향이 있으며, dense한 표현으로 인해 형태 누출이 발생할 가능성이 있다.
Depth-wise Pose Modulation
저자들은 스켈레톤 신호를 유지하면서, 구조화된 깊이(structured depth)를 추가하여 팔다리 사이의 공간적 관계 표현을 강화하였다. 이 접근 방식을 depth-wise pose modulation이라고 한다.
모션 신호의 경우 Sapien을 활용하여 소스 동영상에서 스켈레톤과 깊이 정보를 추출한다. 원본 depth map에는 형태 누출의 발생할 가능성이 있으므로, 이를 완화하기 위해 스켈레톤을 활용하여 다음과 같이 깊이 정보를 구조화한다.
- 스켈레톤 이미지를 이진화하여 스켈레톤 마스크를 얻은 다음, 이 마스크 영역 내에서 깊이 정보를 추출한다.
- Pose guider와 동일한 아키텍처의 Conv2D를 사용하여 스켈레톤 맵과 구조화된 depth map을 처리한다.
- Cross-attention 메커니즘을 통해 구조화된 깊이 정보를 스켈레톤 feature에 병합한다.
이 접근 방식의 핵심은 각 팔다리가 다른 팔다리의 공간적 특성을 통합하여 팔다리 상호작용 관계를 보다 섬세하게 이해할 수 있도록 하는 것이다. 실제 영상에서 추출한 포즈 정보에는 오차가 있을 수 있으므로 Conv3D를 사용하여 시간적 모션 정보를 모델링하고, 이를 통해 프레임 간 연결을 향상시키고 개별 프레임에 대한 오차 신호의 영향을 완화한다.
Experiments
- 데이터: 인터넷에서 수집한 다양한 종류의 캐릭터 동영상 10만 개
- 구현 디테일
- GPU: NVIDIA A100 8개
- step: 10만
- batch size: 8
- 동영상 길이: 각 batch마다 16
- 레퍼런스 이미지는 전체 동영상 시퀀스에서 랜덤하게 샘플링됨
1. Qualitative Results
다음은 Animate Anyone 2이 생성한 동영상의 예시들이다.

2. Comparisons
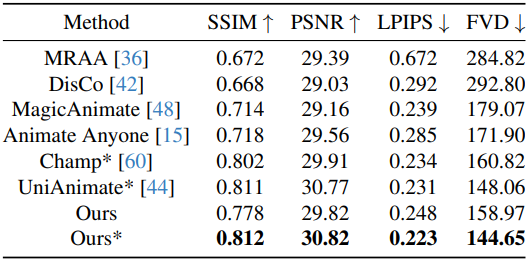
다음은 Tiktok 벤치마크에서 성능을 비교한 결과이다. ($\vphantom{1}^\ast$는 다른 동영상 데이터로 사전 학습)
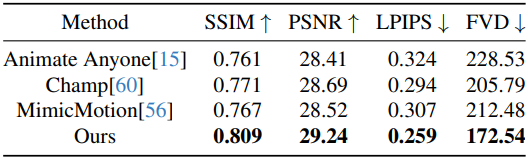
다음은 캐릭터 애니메이션에 대한 비교 결과이다.

다음은 환경 통합과 물체 상호작용에 대한 비교 결과이다.

3. Ablation Study
다음은 환경 정의에 대한 ablation 결과이다.

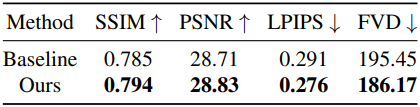
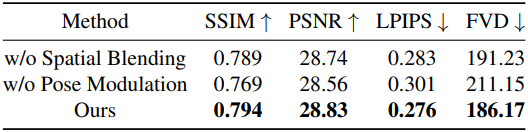
다음은 물체 모델링과 pose modulation에 대한 ablation 결과이다.

Limitations
- 비교적 작은 픽셀 영역을 차지하는 복잡한 손-사물 상호작용을 처리할 때 아티팩트가 나타날 수 있다.
- 복잡한 인간-사물 상호작용에서 소스와 타겟 캐릭터가 상당한 형태 불일치를 보일 때 아티팩트가 나타날 수 있다.
- 물체 상호작용의 성능은 SAM의 분할 능력에 의해 영향을 받는다.