[논문리뷰] ALTER: All-in-One Layer Pruning and Temporal Expert Routing for Efficient Diffusion Generation
NeurIPS 2025. [Paper] [Github]
Xiaomeng Yang, Lei Lu, Qihui Fan, Changdi Yang, Juyi Lin, Yanzhi Wang, Xuan Zhang, Shangqian Gao
CASIA | UCAS | ByteDance
27 May 2025
Introduction
본 논문에서는 diffusion model의 layer pruning을 temporal expert routing 및 모델 fine-tuning과 매끄럽게 통합하는 최적화 접근 방식인 ALTER (All-in-One Layer Pruning and Temporal Expert Routing) 프레임워크를 소개한다. 이 프레임워크는 diffusion model을 효율적인 temporal expert들의 혼합으로 효과적으로 변환하며, 각 expert는 생성 프로세스의 각 단계에 맞춰 특화된 원래 모델의 pruning된 sub-network이다. 이러한 동적 구성은 각 expert sub-network에 대한 최적의 하위 구조를 식별하고 fine-tuning 단계 전체에 걸쳐 denoising timestep을 지능적으로 라우팅함으로써 구현된다.
구체적으로, 본 논문에서는 hypernetwork를 사용하여 업데이트된 모델 가중치를 기반으로 layer pruning 결정을 지속적으로 생성하는 동시에 적절한 expert에게 timestep을 라우팅하는 것을 관리한다. 이러한 pruning 및 routing 결정의 영향은 forward pass에서 layer skipping 메커니즘을 통해 학습 중에 시뮬레이션된다. Inference 시, 최종적으로 완성된 hypernetwork는 각 timestep에 대해 가장 적합한 expert를 선택하고 지정된 layer를 건너뛸 수 있도록 함으로써 시간적 계산 중복을 최소화한다.
Method
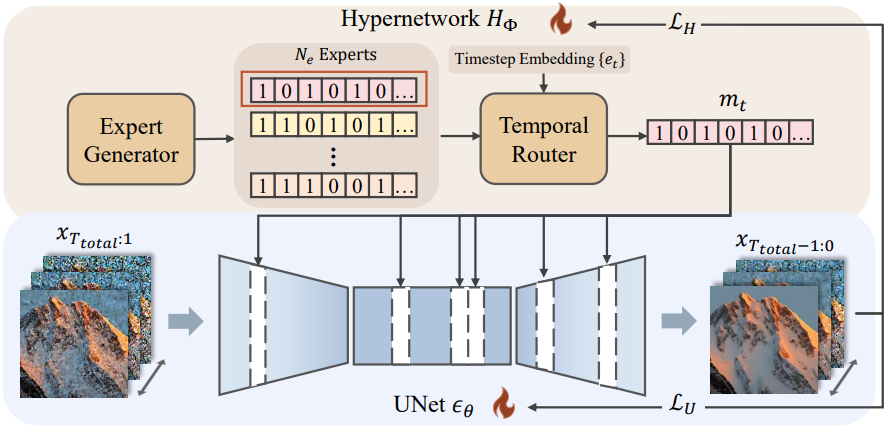
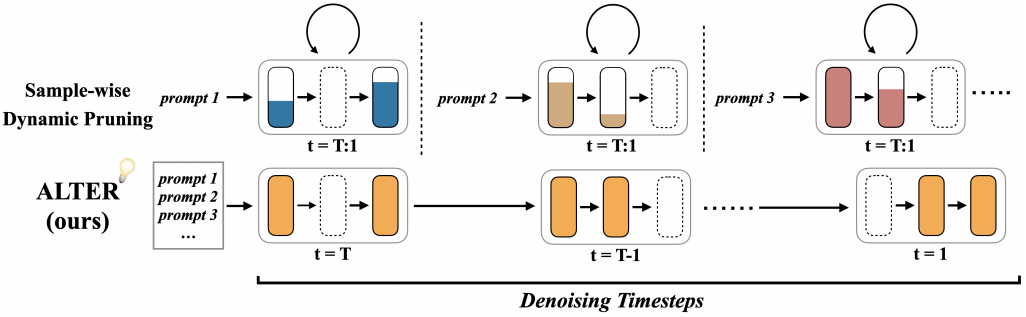
ALTER는 표준 diffusion UNet을 temporal expert의 동적 앙상블로 재구성하며, 각 expert는 공유 backbone에 적용된 layer-wise pruning 구성에 따라 정의된다. Hypernetwork는 이러한 binary pruning mask를 생성하고, router는 각 denoising timestep을 적절한 expert에게 할당한다. 모든 구성 요소는 학습 과정에서 함께 최적화된다. Inference에서 router는 timestep에 따라 expert별 sub-network들을 동적으로 활성화한다.
1. Temporal Expert Construction
ALTER는 공유 UNet backbone에 대한 layer-wise pruning mask를 생성하기 위해 학습 가능한 hypernetwork \(H_\Phi\)를 사용한다. 이러한 마스크는 $N_e$개의 expert 구성을 정의하며, 각 expert는 layer-wise pruning된 sub-network들과 동일하다. \(H_\Phi\)는 두 개의 학습 가능한 구성 요소로 구성된다.
- Expert Generator $\textbf{G}$
- Temporal Router $\textbf{R}$
Expert Generator
$N_e$개의 expert 구성을 생성하기 위해 expert generator $\textbf{G}$를 사용하여 pruning mask 집합 \(\{m_i\} \in [0, 1]^{N_e \times N_L}\)을 생성한다. 여기서 각 \(m_i \in [0, 1]^{N_L}\)은 $i$번째 expert의 구성을 나타낸다. Generator는 orthogonal vector들로 초기화된 고정 임베딩 집합 \(Z \in \mathbb{R}^{N_e \times N_L \times D_\textrm{input}}\)을 입력으로 받아 여러 MLP를 통해 처리하여 expert layer logit \(L_\textrm{experts} \in \mathbb{R}^{N_e \times N_L}\)을 생성한다. 학습 중 미분 가능성을 유지하면서 이항 분포를 근사화하기 위해 \(L_\textrm{experts}\)의 최종 layer에 Gumbel-Sigmoid function과 Straight-Through Estimator (ST-GS)를 결합하여 \(\{m_i\}\)를 얻는다.
Temporal Router
Diffusion process에서 $t$번째 timestep에 적합한 expert를 선택하기 위해, expert generator와 유사한 네트워크 구조를 가진 temporal router $\textbf{R}$을 사용한다. Temporal router는 타겟 UNet의 timestep 임베딩 메커니즘에서 정의된 해당 timestep 임베딩 \(e_t \in \mathbb{R}^{D_\textrm{emb}}\)를 입력으로 받아, $N_e$명의 expert 후보에 대한 routing logit \(L_t^\textrm{routing} \in \mathbb{R}^{N_e}\)로 매핑한다. Expert generator와 마찬가지로, routing logit에 Gumbel-Softmax function과 Straight-Through Estimator를 적용하여 최종 선택 벡터 \(\{s_t\}\)를 얻는다.
서로 다른 timestep 임베딩에 기반한 routing을 통해 router는 denoising process의 여러 timestep에 걸쳐 expert 수준의 전문화를 가능하게 하며, 모델이 각 timestep에서 가장 적합한 sub-network에 계산을 적응적으로 할당할 수 있도록 한다.
Layer-wise Pruning의 미분 가능한 시뮬레이션
학습 중 diffusion UNet에 대한 timestep별 layer-wise pruning의 효과를 시뮬레이션하기 위해, pruning이 가능한 각 layer \(l \in \{1, \ldots, N_L\}\)의 forward 계산을 다음과 같이 수정한다.
\[\begin{equation} x_\textrm{out} = (1- (m_t)_l) \cdot x_\textrm{in} + (m_t)_l \cdot f_l (x_\textrm{in}) \end{equation}\](\(x_\textrm{in}\)은 layer $l$의 입력, $f_l$은 원래 layer 계산, $(m_t)_l \in [0, 1]$은 timestep $t$에서의 layer $l$에 대한 pruning 결정)
$(m_t)_l = 0$일 때 해당 layer는 사실상 건너뛰어지고, $(m_t)_l = 1$일 때 완전히 활성화된 상태로 유지된다. 이 공식은 gradient flow를 유지하면서 pruning 동작을 충실하게 시뮬레이션하여 end-to-end 최적화를 가능하게 한다. Gumbel-Sigmoid 및 Gumbel-Softmax와 함께 Straight-Through Estimator (STE)를 사용함으로써 pruning mask와 routing 선택 벡터 모두에 대해 미분 가능한 샘플링을 보장한다. Inference에서 $(m_t)_l = 0$일 때마다 실제 layer skipping을 수행하여 hard pruning을 적용함으로써 expert별 sub-network 실행을 통해 계산을 효율적으로 할 수 있다.
2. Optimization Strategy
ALTER는 공유 UNet \(\epsilon_\theta\)와 hypernetwork \(H_\Phi\)로 구성되며, 교대 학습 방식을 통해 공동으로 최적화된다. 각 학습 단계는 다음 두 가지 최적화 단계를 번갈아 수행한다.
공유 UNet Backbone 최적화
현재 hypernetwork \(H_\Phi\)에서 생성된 $N_e$개의 expert 구성 $\mathcal{M}$이 주어졌을 때, 공유 UNet 최적화의 목표는 각 expert sub-network가 할당된 timestep 그룹에서 강력한 denoising 성능을 달성하도록 하는 것이다. 따라서 주요 학습 loss는 각 diffusion timestep에서 활성화된 expert를 시뮬레이션하는 마스킹된 sub-network들에 대해 계산되는 표준 denoising loss \(\mathcal{L}_\textrm{denoise}\)이다.
성능을 더욱 향상시키고 layer-wise pruning 하에서 학습을 안정화하기 위해, 고정된 사전 학습된 teacher 모델 \(\epsilon_T\)에서 knowledge distillation을 선택적으로 사용한다. 구체적으로, student UNet \(\epsilon_S = \epsilon_\theta\)가 teacher와 유사한 denoising 출력을 생성하도록 유도하는 output-level distillation loss \(\mathcal{L}_\textrm{outKD}\)와, teacher와 student 간의 중간 표현을 정렬하는 feature-level distillation loss \(\mathcal{L}_\textrm{featKD}\)를 도입한다.
\[\begin{aligned} \mathcal{L}_\textrm{outKD} &= \mathbb{E} \left[ \| \epsilon_T (x_t, t, c) - \epsilon_S (x_t, t, c) \|_2^2 \right] \\ \mathcal{L}_\textrm{featKD} &= \mathbb{E} \left[ \sum_k \| f_T^k (x_t, t, c) - f_S^k (x_t, t, c) \|_2^2 \right] \end{aligned}\]($f_T^k$와 $f_S^k$는 각각 teacher 모델과 student 모델의 $k$번째 block feature activation 값)
전체 UNet loss는 denoising loss와 knowledge distillation 항을 결합한 것이다.
\[\begin{equation} \mathcal{L}_U = \lambda_\textrm{denoise} \mathcal{L}_\textrm{denoise} + \lambda_\textrm{outKD} \mathcal{L}_\textrm{outKD} + \lambda_\textrm{featKD} \mathcal{L}_\textrm{featKD} \end{equation}\]Hypernetwork 최적화
현재 공유되는 UNet backbone을 기반으로 업데이트된 hypernetwork는 다음 세 가지 원칙을 만족해야 한다.
(1) 성능 유지
주어진 denoising timestep에 대해 선택된 temporal expert는 denoising 능력을 유지해야 하며, denoising 능력은 UNet loss $L_U$를 반영하는 performance loss \(\mathcal{L}_\textrm{perf}\)로 나타낸다. 이는 고정된 UNet에 적용된 학습 가능한 \(H_\Phi\)의 마스크 \(m_t^\prime\)을 사용하여 평가되며, \(H_\Phi\)가 좋은 생성 성능을 유지하면서 효과적인 마스크를 생성하는지 확인한다.
(2) 구조적 sparsity
Diffusion 궤적 전체에 걸친 temporal sparsity는 사용자가 정의한 계산량 감소 목표에 근접해야 한다. Sparsity regularization loss \(\mathcal{L}_\textrm{ratio}(m_t^\prime)\)는 \(H_\Phi\)가 목표 전체 pruning 비율 $p$를 달성하도록 가이드한다. 이 항은 log-ratio matching loss를 사용하여 현재 유효 sparsity $S(m_t^\prime)$가 $p$에서 벗어나는 정도에 페널티를 부여한다. $S(m_t^\prime)$는 layer 비용과 마스크 활성화를 기반으로 계산되며, 마스크 $m_t^\prime$에서 네트워크의 FLOPs 중 활성 부분의 척도이다.
Loss는 다음과 같이 정의된다.
\[\begin{equation} \mathcal{L}_\textrm{ratio} (m_t^\prime) = \log \left( \frac{\max (S(m_t^\prime), p)}{\min (S(m_t^\prime), p) + \epsilon} \right) \end{equation}\](3) Expert 다양성
Router는 mode collapse를 방지하기 위해 timestep 전반에 걸쳐 다양한 expert 선택을 촉진해야 한다. Router balance loss \(\mathcal{L}_\textrm{balance}\)는 다양한 expert 활용을 장려한다.
\[\begin{aligned} \mathcal{L}_\textrm{balance} &= N_e \sum_{i=1}^{N_e} F_i P_i \\ \textrm{where} \; F_i &= \frac{1}{\vert \mathcal{B} \vert} \sum_{s_b \in \mathcal{B}} \mathbb{I} (\underset{j}{\arg \max} (L_{s_b}^\textrm{routing})_j = i) \\ P_i &= \frac{1}{\vert \mathcal{B} \vert} \sum_{s_b \in \mathcal{B}} (\textrm{Softmax} (L_{s_b}^\textrm{routing}))_i \end{aligned}\]전체 loss는 다음과 같다.
\[\begin{equation} \mathcal{L}_H = \mathcal{L}_\textrm{perf} + \lambda_\textrm{ratio} \mathcal{L}_\textrm{ratio} + \lambda_\textrm{balance} \mathcal{L}_\textrm{balance} \end{equation}\]\(m_t^\prime\)의 미분 가능성은 ST-GS와 ST-GSmax를 통해 구현된다. Hypernetwork 업데이트 후, 후속 UNet 학습 단계를 위한 마스크 구성 \(\mathcal{M}_U\)는 업데이트된 \(H_\Phi\)를 사용하여 갱신된다. 이러한 교대 최적화 전략을 통해 UNet은 \(H_\Phi\)의 동적 아키텍처에 적응할 수 있으며, \(H_\Phi\)는 효율적이고 효과적인 구성을 생성하는 방법을 학습한다.
이러한 교대 학습 전략을 통해 ALTER 내에서 상호 적응이 가능해진다. UNet은 layer-wise sparsity의 다양한 구성에서 점진적으로 denoising 성능을 회복하는 반면, hypernetwork는 diffusion process에 맞춰 특화된 expert 구성 및 routing을 지속적으로 개선한다.

Experiments
- 데이터셋: LAION-Aestheics V2 (6.5+)에서 30만 개를 랜덤 샘플링
- 구현 디테일
- base model: 사전 학습된 SDv2.1
- 전체 pruning 비율: 0.65
- temporal export 개수: 10
- global batch size: 64
- step: 3.2만
- hypernetwork는 처음 2 epoch에서만 학습
- GPU: NVIDIA A100 2개
1. Comparison Results
다음은 BK-SDM-v2, APTP와의 비교 결과이다.

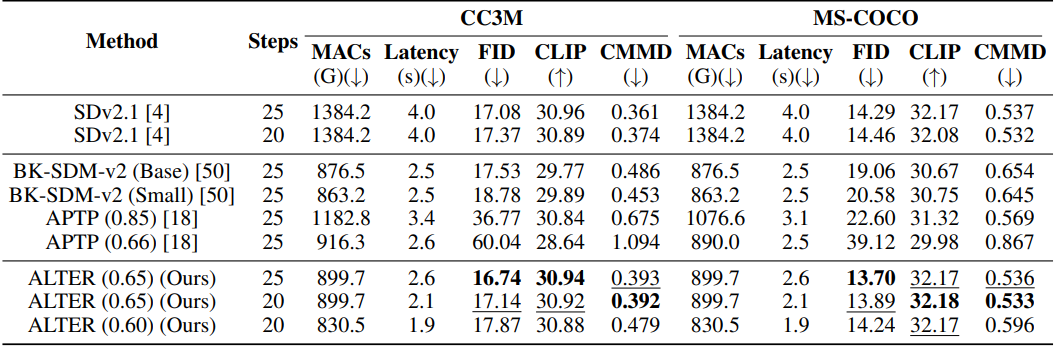
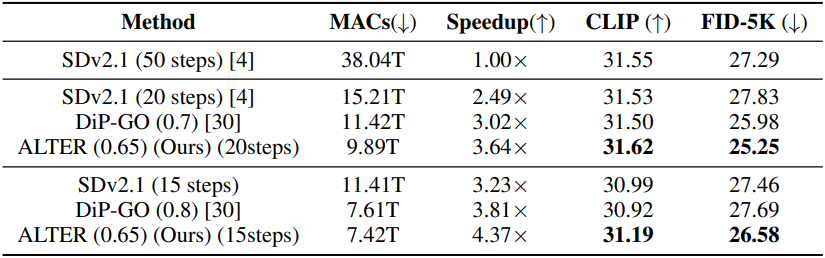
다음은 DiP-GO와 MS-COCO 2017 validation set에서 비교한 결과이다.
2. Ablation Study
다음은 주요 구성 요소에 대한 ablation study 결과이다.

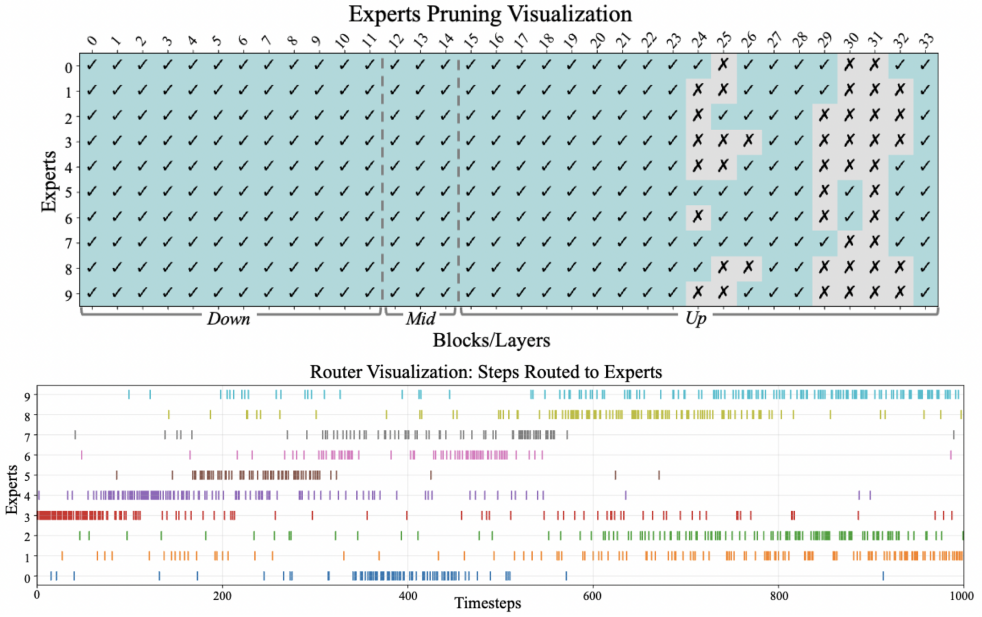
다음은 ALTER (0.65)의 temporal expert들과 router 동작을 시각화한 것이다.
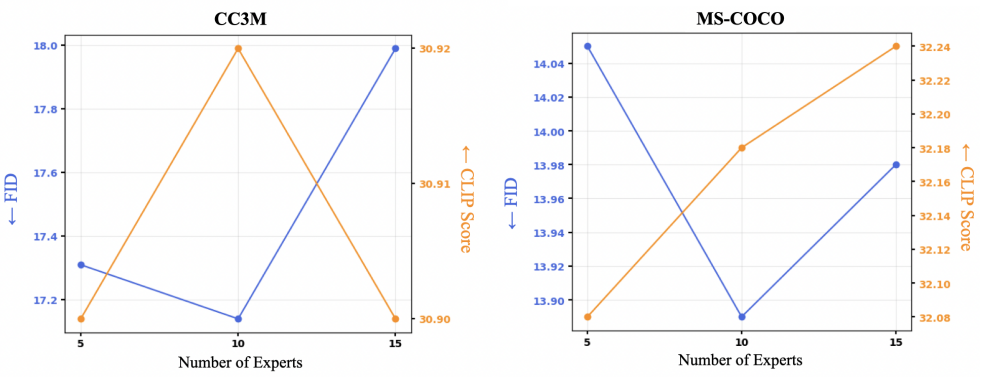
다음은 expert 수에 대한 ablation study 결과이다.