[논문리뷰] AltCLIP: Altering the Language Encoder in CLIP for Extended Language Capabilities
arXiv 2022. [Paper] [Github]
Zhongzhi Chen, Guang Liu, Bo-Wen Zhang, Fulong Ye, Qinghong Yang, Ledell Wu
Beijing Academy of Artificial Intelligence | Beihang University | Beijing University of Posts and Telecommunications
12 Nov 2022
Introduction
시각과 언어를 위한 공동 공간에서 좋은 표현을 배우는 것은 AI 연구에서 오랫동안 추구해 왔다. 최근 OpenAI의 CLIP은 ImageNet의 이미지 분류, Flicker-30k와 MSCOCO의 image-to-text와 text-to-image 검색과 같은 여러 작업에서 인상적인 zero-shot 성능을 보여주었다. 이탈리아어, 한국어, 중국어와 같은 다른 언어 또는 교차 언어 및 다국어 설정에서 대조되는 언어-이미지 모델을 구축하려는 노력이 있었다.
좋은 언어-이미지 표현 모델을 학습시키려면 엄청난 양의 텍스트-이미지 쌍과 방대한 계산 리소스가 필요한 경우가 많다. 예를 들어 CLIP은 4억 개의 텍스트-이미지 쌍을 사용했고 최근에 제안된 중국어 모델인 Taiyi는 1.23억 개의 텍스트-이미지 쌍을 사용했다. 이 문제를 완화하기 위해 기존의 사전 학습된 모델을 활용하고 네트워크의 일부만 사전 학습하려는 여러 연구들이 있었다. 최근에 Multilingual-CLIP은 다국어 텍스트-이미지 표현 모델을 학습하기 위해 CLIP 모델의 텍스트 인코더에서 Teacher Learning (일명 Knowledge Distillation)을 사용할 것을 제안했다. 이 방법은 텍스트-이미지 쌍 없이 영어에서 다른 언어로 기계 번역된 데이터만 사용한다.
그러나 교차 언어 또는 다국어 설정의 기존 연구들은 주로 모델의 검색 성능에 초점을 맞추고 일반화 능력을 무시한다. 검색 성능을 평가하기 위한 데이터셋은 종종 작다. 검색 성능은 학습 데이터 분포의 변화에 따라 급격하게 변동한다. 현재 방법은 검색에서 좋은 성능을 달성하지만 이러한 방법은 종종 ImageNet 분류 task에서 잘 수행되지 않는다. 1,000개 클래스가 넘는 이미지를 정확하게 예측하는 능력은 종종 모델의 일반화 능력이 더 우수함을 나타낸다.
앞서 언급한 문제를 해결하기 위해 본 논문은 영어와 중국어 모두에서 ImageNet과 멀티모달 검색 task에서 강력한 성능을 달성한 Alter ego CLIP (AltCLIP)이라는 이중 언어 모델을 제안하였다. AltCLIP은 2단계 프레임워크에서 강력한 이중 언어 이미지 표현을 학습한다. 첫 번째 단계에서는 Teacher Learning을 사용하여 CLIP에서 배운 지식을 추출한다. 두 번째 단계에서는 상대적으로 적은 양의 중국어 및 영어 텍스트-이미지 쌍에 대해 Contrastive Learning을 통해 모델을 학습시킨다.
Methodology

본 논문은 좋은 이중 언어 및 다국어 언어-이미지 표현 모델을 학습하기 위한 2단계 방법을 제안하였다. 첫 번째 단계에서는 Multilingual-CLIP을 따라 Teacher Learning을 사용하여 CLIP 텍스트 인코더에서 다국어 텍스트 인코더를 학습한다. 이 단계에서는 학습에 이미지가 필요하지 않으며 언어 병렬 데이터만 사용된다. 두 번째 단계에서는 텍스트-이미지 쌍을 사용하여 contrastive learning에서 모델을 더욱 fine-tuning한다. 전체 학습 절차는 위 그림에 요약되어 있다.
1. Teacher Learning Stage
이 단계에서는 텍스트 인코더에서 Teacher Learning을 수행한다. Teacher 텍스트 인코더로 CLIP의 텍스트 인코더를 사용하고 student 인코더로 다국어 데이터로 사전 학습된 XLM-R 모델을 사용한다. XLMR 모델의 출력을 teacher 인코더와 동일한 출력 차원으로 변환하기 위해 fully-connected layer가 추가되었다. 텍스트-이미지 정렬에 대한 지식을 추출하기 위해 영어와 중국어 모두에서 병렬 텍스트 데이터를 사용한다.
병렬 텍스트 입력 \((\textrm{sent}_1, \textrm{sent}_2)\)가 주어지면 teacher 텍스트 인코더는 [TOS] 토큰 $x_\textrm{tos}^t$의 임베딩인 입력 \(\textrm{sent}_1\)에서 학습 타겟을 생성한다. Student 텍스트 인코더는 입력 \(\textrm{sent}_2\)에서 임베딩 $x_\textrm{cls}^s$를 생성한다. $x_\textrm{tos}^t$와 $x_\textrm{cls}^s$ 사이의 평균 제곱 오차 (MSE)를 최소화한다. 이러한 학습을 받은 후 student 텍스트 인코더는 대부분의 다국어 능력을 유지하고 두 언어 모두에서 텍스트-이미지 정렬 능력을 얻을 수 있다. Teacher 인코더는 학습 시에만 사용된다. Inference 시 학생 인코더만 텍스트 인코더로 사용된다.
본 논문의 방법이 더 많은 언어를 포함하도록 확장 가능하다는 것을 보여주기 위해 저자들은 9개의 다른 언어를 지원하는 다국어 버전을 구축하였다.
영어(En), 중국어(Zh), 스페인어(Es), 프랑스어(Fr), 러시아어(Ru), 아랍어(Ar), 일본어(Ja), 한국어(Ko), 이탈리아어(It)
다국어 버전의 경우 이중 언어 버전과 동일한 개념 및 아키텍처를 사용하여 더 많은 언어를 영어와 일치시킨다.
2. Contrastive Learning Stage
이 학습 단계는 다국어 텍스트-이미지 쌍에 대한 contrastive learning을 통해 텍스트-이미지 정렬을 더욱 개선하는 것을 목표로 한다. Vision Transformer (ViT)를 기반으로 하는 CLIP의 이미지 인코더를 이미지 인코더로 사용하고 Teacher Learning 단계에서 학습한 student 텍스트 인코더를 텍스트 인코더로 사용한다.
이미지 인코더와 텍스트 인코더의 출력 projection 사이에 Contrastive Loss를 사용한다. LiT를 따라 학습 시에 이미지 인코더를 고정하고 텍스트 인코더의 파라미터만 업데이트한다.
Experiments
- 데이터셋
- Teacher Learning: CC3M, TSL2019
- Contrastive Learning: Wudao MM, LAION 5B, LAION Multilingual 2B
1. Zero-shot performance
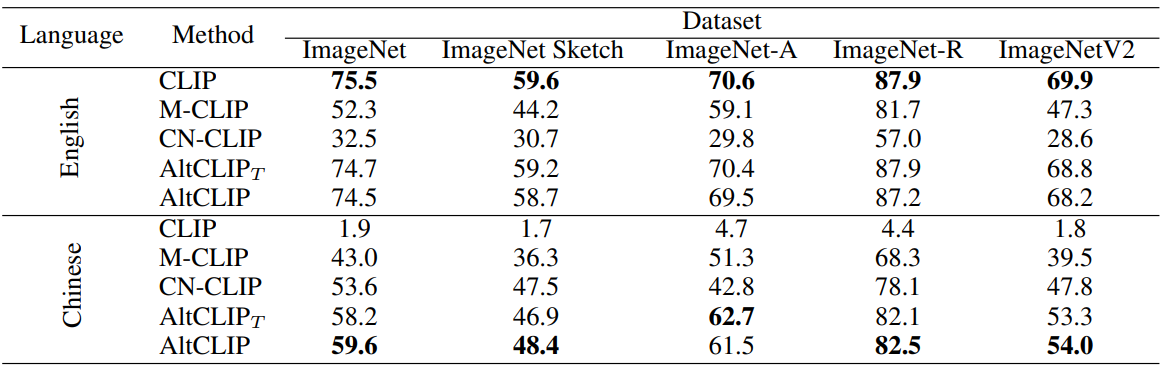
다음은 ImageNet과 그 변형에서 AltCLIP과 baseline 모델을 비교한 결과이다.
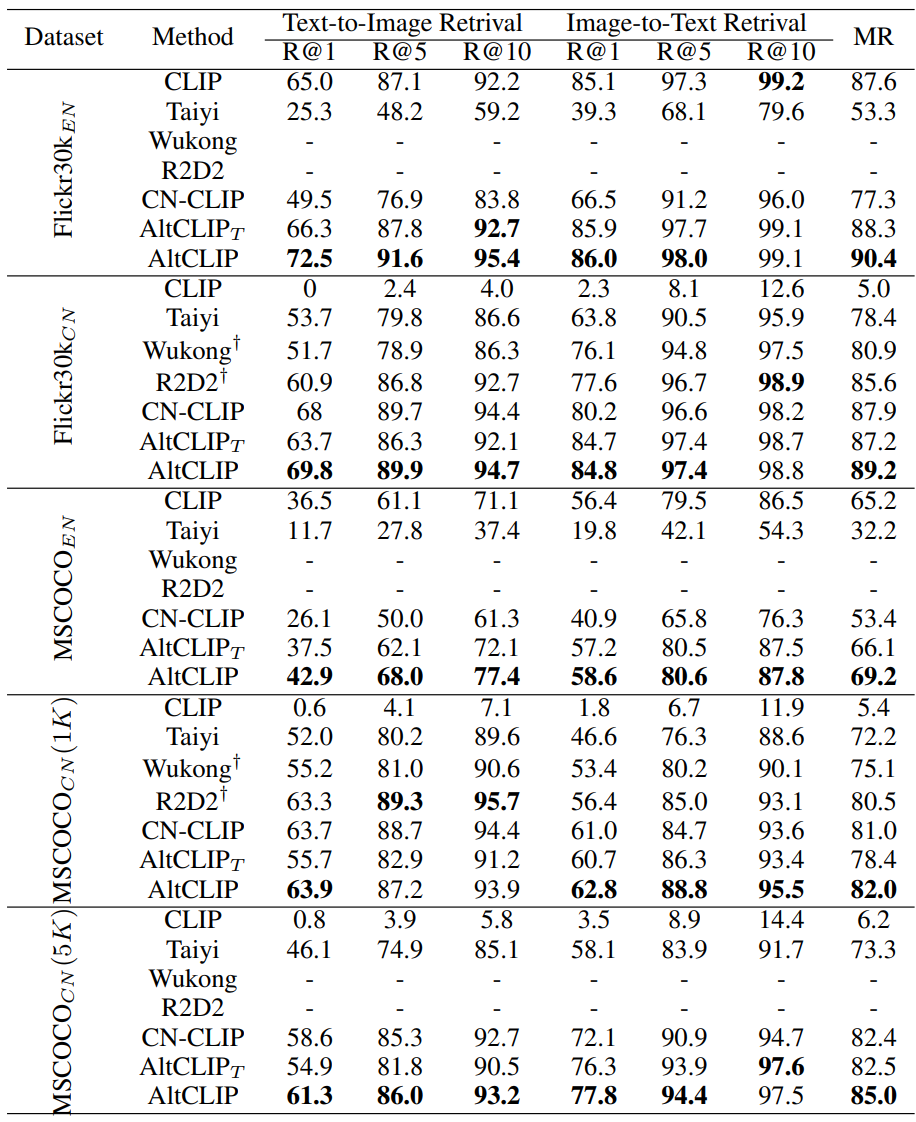
다음은 Flickr30k과 MSCOCO에서의 이미지 검색 결과이다.
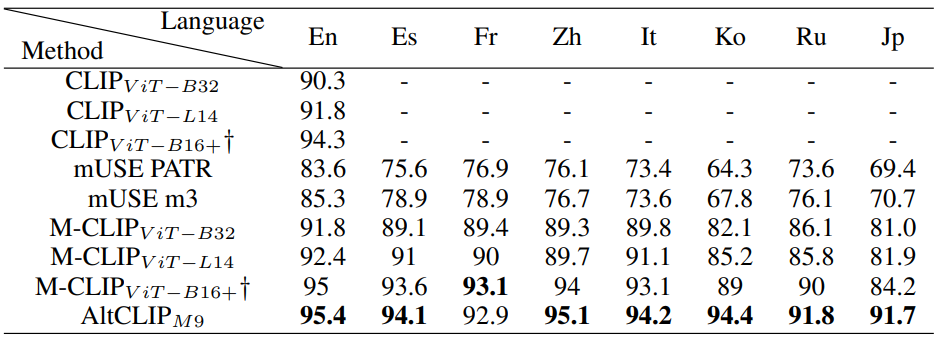
다음은 다국어 cross-modal 검색 데이터셋인 XTD에서의 비교 결과이다.
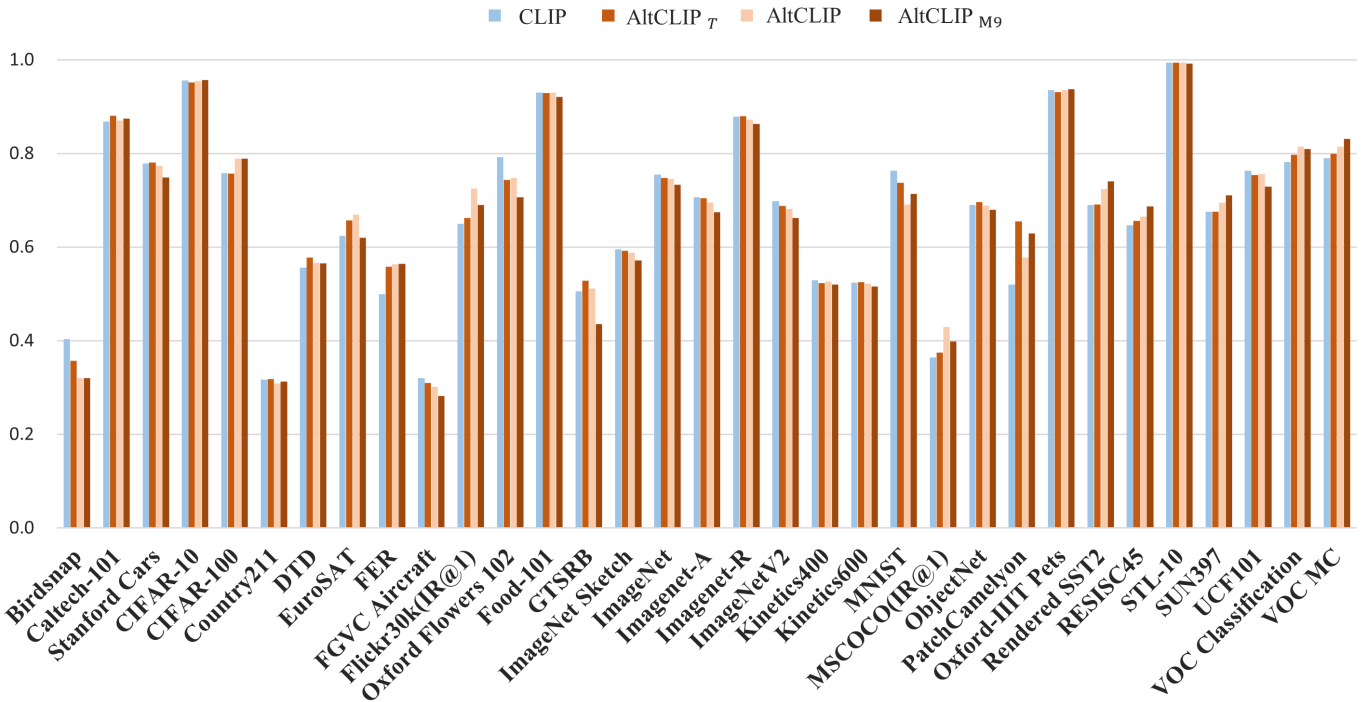
다음은 AltCLIP과 CLIP의 성능을 비교한 그래프이다.
2. Ablation study
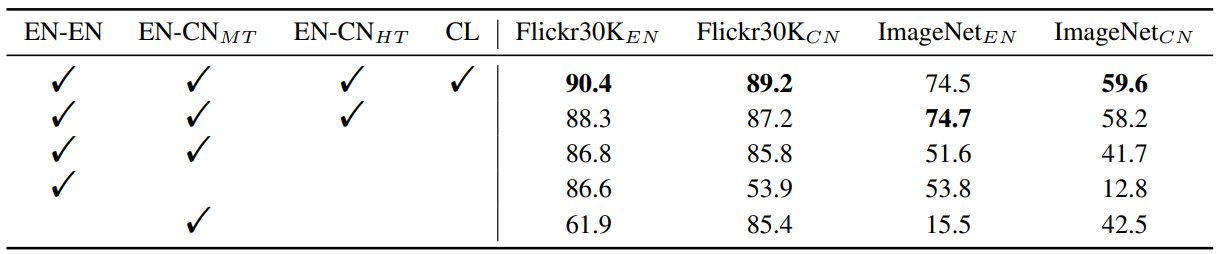
다음은 ablation study 결과이다.
3. Examples of text-to-image generation
다음은 text-to-image 생성 결과를 비교한 것이다.
프롬프트: “a pretty female druid surrounded by forest animals, digital painting, photorealistic, in the style of greg rutkowski, highly detailed, realistic”

다음은 다양한 언어에 대한 생성 결과이다.
