[논문리뷰] Alpha-CLIP: A CLIP Model Focusing on Wherever You Want
CVPR 2024. [Paper] [Page] [Github]
Zeyi Sun, Ye Fang, Tong Wu, Pan Zhang, Yuhang Zang, Shu Kong, Yuanjun Xiong, Dahua Lin, Jiaqi Wang
Shanghai Jiao Tong University | Fudan University | The Chinese University of Hong Kong | Shanghai AI Laboratory | University of Macau | MThreads, Inc.
6 Dec 2023
Introduction
CLIP의 최근 발전으로 이미지와 텍스트 모두에서 semantic하게 일관된 feature를 추출하기 위한 강력한 프레임워크가 확립되었다. 이러한 feature들은 이미지 내의 모든 semantic 디테일을 캡처하고 강력한 표현 능력과 탁월한 일반화 가능성을 보여주었다.
CLIP은 전체 이미지의 내용을 캡처하지만, 보다 정밀한 이해와 제어 가능한 콘텐츠 생성을 위해서는 관심 영역에 초점을 맞추는 것도 중요하다. 관심 영역은 인간 상호작용 또는 인식 모델을 통해 점, 마스크 또는 상자로 지정할 수 있다.

기존 방법들은 두 가지 기본 전략을 사용하여 영역 중심의 CLIP feature를 획득하려고 시도했다. 첫 번째 방법은 관심 영역을 별개의 패치로 자르거나 이미지, feature, attention mask의 관련 없는 부분에 마스킹하여 관련 없는 영역을 제외하는 것이다. 그러나 이 방식은 정확한 이미지 이해 및 추론에 중요한 글로벌 정보를 방해하고 생략한다. 두 번째 방법은 CLIP에 공급된 이미지에서 원이나 마스크 윤곽으로 관심 영역을 강조하는 것이다. 사용자 친화적이지만 이미지의 원본 내용을 변경하므로 바람직하지 않은 결과가 발생한다.
본 논문은 원본 이미지를 손상시키지 않고 관심 영역을 얻기 위해 추가 알파 채널 입력을 통해 관심 영역을 통합하여 CLIP을 향상시키는 Alpha-CLIP을 제안하였다. 알파 채널을 통해 Alpha-CLIP은 글로벌 정보에 대한 인식을 유지하면서 지정된 영역에 집중할 수 있다. Alpha-CLIP 학습에는 대규모 영역-텍스트 쌍 데이터셋이 필요하다. 따라서 저자들은 SAM과 BLIP-2와 같은 이미지 캡션을 위한 모델을 활용하여 수백만 개의 RGBA 영역-텍스트 쌍을 생성하는 효과적인 파이프라인을 개발하였다. 영역-텍스트 쌍과 이미지-텍스트 쌍을 혼합하여 학습한 후 Alpha-CLIP은 CLIP의 시각적 인식 정확도를 유지하면서 특정 영역에 집중할 수 있다.
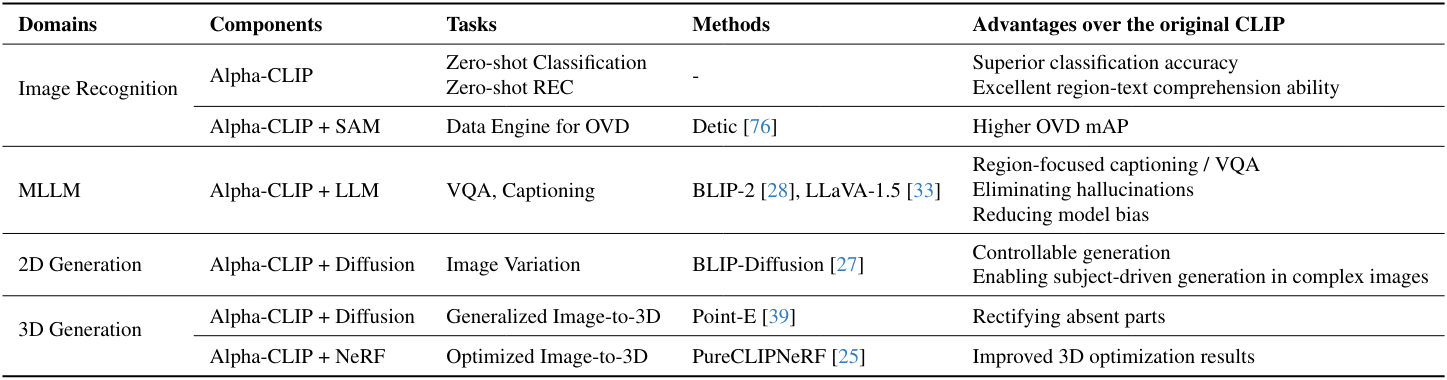
Alpha-CLIP은 2D 및 3D 인식부터 생성까지 다양한 도메인에 plug-and-play 방법론을 적용하여 다양한 다운스트림 task에서 CLIP을 향상시킬 수 있다.
- 이미지 인식: Alpha-CLIP은 기존 CLIP의 인식 능력을 유지할 뿐만 아니라 영역 기반 인식 능력도 향상시킨다. 구체적으로, 초점을 맞출 GT 영역이 제공되면 Alpha-CLIP은 zero-shot ImageNet classification task에서 top-1 정확도가 4.1% 향상된다. 이 우수한 영역 기반 인식 능력은 Referring Expression Comprehension (REC)와 같은 다운스트림 task를 돕거나 Open Vocabulary Detection (OVD)를 위한 데이터 엔진 역할을 한다.
- LMM의 비전 백본: Alpha-CLIP은 LMM 프레임워크 내에서 영역 수준 captioning 및 VQA를 촉진할 수 있다. 이러한 통합은 환각 발생을 크게 완화하고 모델의 편향을 줄인다.
- 2D 생성: Alpha-CLIP은 dffusion model과 통합되면 image variation task에서 BLIP-Diffusion의 제어 가능성을 향상시킨다. 또한, 피사체 중심 생성을 위해 복잡한 이미지에서 피사체를 추출할 수 있다.
- 3D 생성: Alpha-CLIP은 3D 생성에도 능숙하다. Point-E와 함께 사용하여 3D 생성 품질을 향상시킬 수 있다. 또한 PureCLIPNeRF와 함께 활용하여 우수한 3D 생성을 최적화할 수 있다.
Method
1. RGBA Region-Text Pair Generation
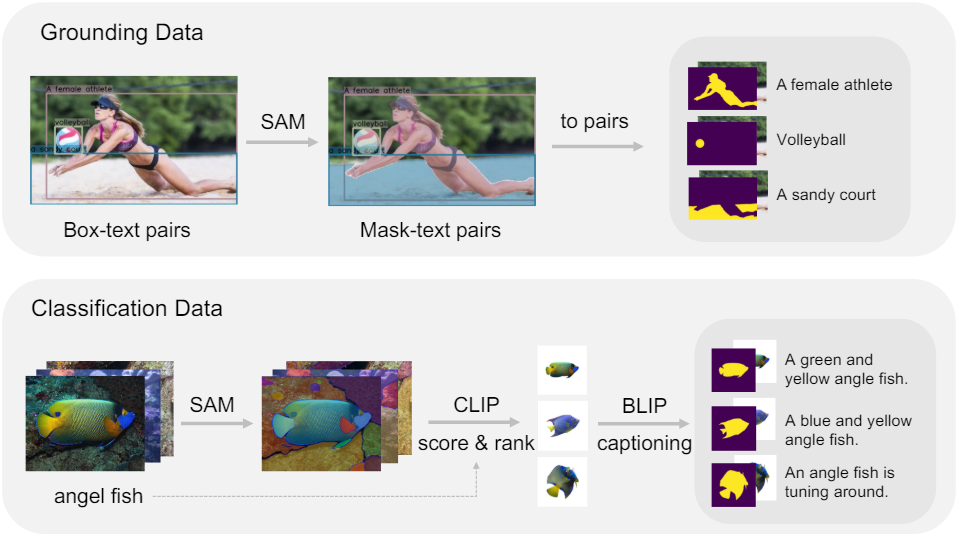
저자들은 추가 알파 채널 입력으로 CLIP 모델을 fine-tuning하기 위해 먼저 수백만 개의 RGBA 영역-텍스트 쌍을 생성하는 데이터 생성 파이프라인을 설계하였다. 파이프라인은 grounding data 파이프라인과 classification data 파이프라인으로 구성된다.
Grounding data pipeline
이 branch는 전경 알파 채널이 있는 이미지와 특정 영역에 대한 해당 참조 표현을 포함하는 영역-텍스트 쌍을 생성하는 데 전념한다. 이미지는 GLIP과 CLIP을 사용하여 박스 형식의 영역-텍스트 쌍의 레이블을 자동으로 추출한 GRIT 데이터셋에서 가져온 것이다. GRIT을 기반으로 SAM을 사용하여 각 박스 영역에 대해 고품질 pseudo-mask를 자동으로 생성한다.
Classification data pipeline
이 branch는 배경이 제거되고 전경 물체가 강조되는 영역-텍스트 쌍을 생성하는 데 사용된다. 저자들은 ImageNet 데이터셋을 사용하였다.
- SAM을 사용하여 ImageNet의 각 이미지에 대해 여러 마스크를 자동으로 생성한다.
- 각 마스크의 전경 물체를 자르고 중앙에 배치한 다음 확대한다.
- CLIP을 사용하여 각 마스크가 속한 이미지의 해당 클래스 레이블로 점수를 계산한다.
- 점수에 따라 클래스별로 마스크를 정렬하고 점수가 가장 높은 최상위 마스크를 선택한다.
- 각 마스크의 캡션이 단순히 ImageNet 클래스 레이블이 아닌지 확인하기 위해 전경 물체를 하얀색 배경에 배치한다.
- BLIP-2를 사용하여 이러한 마스크에 캡션을 추가한다.
- 세분화된 ImageNet 클래스 레이블을 BLIP-2에서 생성된 이미지별 캡션과 병합하여 수백만 개의 RGBA 영역-텍스트 쌍을 생성한다.
2. Alpha-CLIP
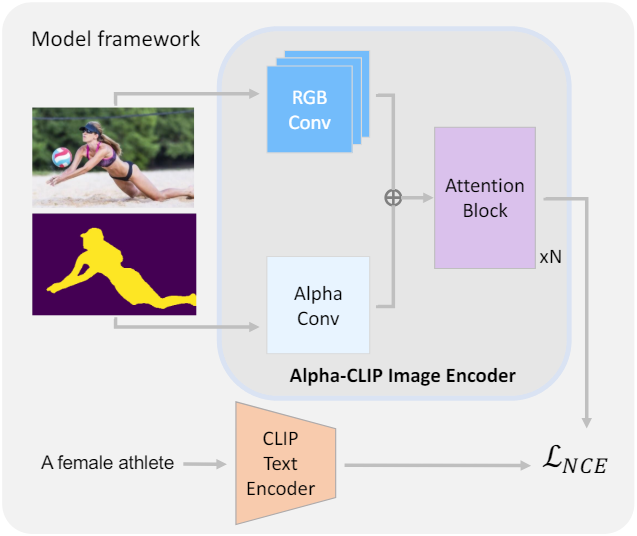
모델 구조
저자들은 Alpha-CLIP은 CLIP의 사전 지식을 보존하기 위해 CLIP 이미지 인코더를 세밀하게 수정하였다. CLIP 이미지 인코더의 ViT 구조에서는 첫 번째 레이어의 이미지에 RGB 컨볼루션이 적용된다. RGB Conv layer와 평행한 추가 Alpha Conv layer를 도입하여 CLIP 이미지 인코더가 추가 알파 채널을 입력으로 받아들일 수 있도록 한다. 알파 채널 입력의 범위는 $[0, 1]$로 설정되며, 1은 전경을 나타내고 0은 배경을 나타낸다. Alpha Conv 커널 가중치를 0으로 초기화하여 학습 초기에는 Alpha-CLIP이 알파 채널을 입력으로 무시하도록 한다.
학습 방법
학습 시에는 CLIP 텍스트 인코더를 고정된 상태로 유지하고 Alpha-CLIP 이미지 인코더를 완전히 학습시킨다. 알파 채널 입력을 처리하는 첫 번째 convolution layer보다 후속 transformer 블록에 더 낮은 learning rate를 적용한다. 전체 이미지에 대한 CLIP의 글로벌 인식 능력을 유지하기 위해 학습 중에 $r_s = 0.1$의 샘플링 비율로 알파 채널을 전체 1로 설정하여 RGBA-텍스트 쌍을 원본 이미지-텍스트 쌍으로 대체한다.
Experiments
1. Alpha-CLIP in Image Recognition
다음은 ImageNet-S에서 zero-shot classification 성능을 비교한 표이다.
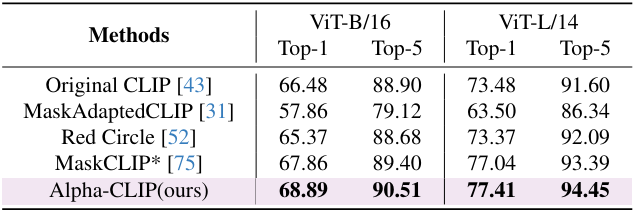
다음은 다양한 알파 맵을 사용하였을 때의 zero-shot classification 성능을 비교한 표이다. (ImageNet-S)

다음은 zero-shot REC 성능을 SOTA 방법들과 비교한 표이다.
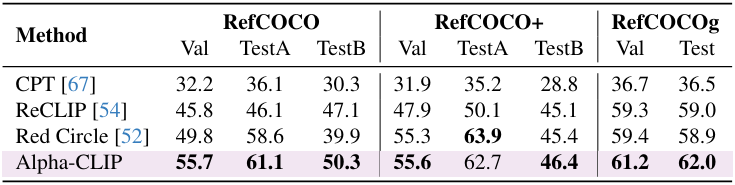
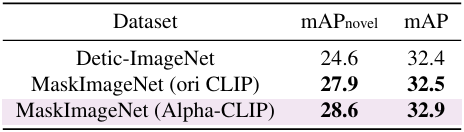
다음은 OV-LVIS에서 open-vocabulary detection 성능을 비교한 표이다.
2. Alpha-CLIP in LMM
다음은 BLIP-2에 Alpha-CLIP을 적용한 결과이다. 왼쪽은 CLIP의 결과이고 가운데와 오른쪽은 Alpha-CLIP의 결과이다.

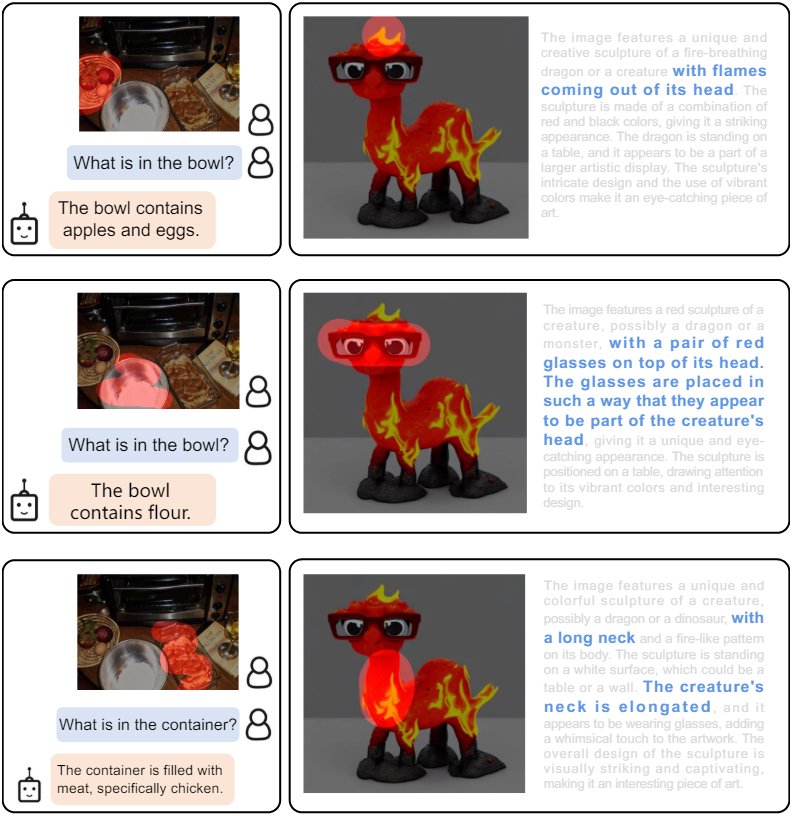
다음은 LLaVA-1.5에 Alpha-CLIP을 적용한 결과이다.
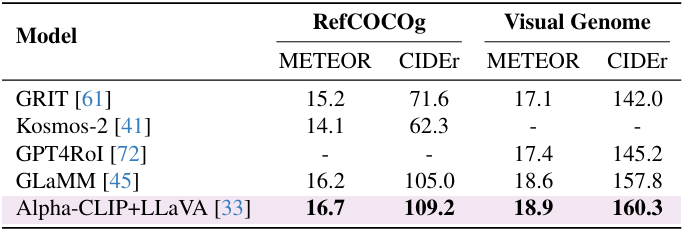
다음은 Alpha-CLIP을 적용한 LLaVA의 영역 수준 captioning 성능을 기존 방법들과 비교한 표이다.
3. Alpha-CLIP in 3D Object Generation.
다음은 Point-E와 PureCLIPNeRF에 Alpha-CLIP을 적용한 결과이다. BackAug는 background augmentation이다.

Limitation
- 여러 물체에 집중하거나 서로 다른 물체 간의 관계를 모델링하는 능력을 제한되어 있다.
- 현재 학습 방법은 알파 채널이 0과 1의 바이너리 값을 제외하고 중간 값으로 일반화되는 것을 제한한다.
- 원본 CLIP과 마찬가지로 낮은 해상도로 인해 작은 물체를 인식하는 데 방해가 된다.